1차 테스트를 진행했습니다.
우선, 순수 자바로만 구성하여 간단하게 광고인지 판별하는 로직을 작성했습니다.
- 블로그 원문에서 특정 단어를 검색하고
- 있으면 바로 광고로 판정
- 없으면 마지막 이미지를 OCR 진행
- OCR 결과에서 특정 단어가 있으면 광고로 판정
이런 흐름으로 작성하였습니다. 그 결과

거의 11초가 걸리는 대참사가 벌어집니다. HTML을 파싱으로 처리해도 결국은 Google Cloud로 OCR 요청을 보내서 받는 과정이 최대 10개가 걸리면 답이 없는 응답시간이 나오는 .... 대참사가 .. 10초는 절대 안됩니다.
3초 이상은 서비스가 불가능하기 때문에 무슨 수를 써서라도 3초 안으로 떙겨야 했고, 가장 문제가 되는 부분인 OCR 요청 보내는 코드를 손봐야겠다고 생각했습니다. 그래서 코드를 뜯어보았는데,
코드를 보면 ....
구글 문서에 나온 코드를 보면,
List<AnnotateImageRequest> requests = new ArrayList<>();요청을 리스트로 보냅니다! 그리고 응답도
List<AnnotateImageResponse> responses = response.getResponsesList();이렇게 리스트 형태로 받습니다. 즉, 요청을 한번에 여러개를 보낼 수 있다 !! 그래서 바로 요청 코드를 수정합니다.
요청 -> 네이버 검색 API -> HTML 파싱 -> OCR -> 결과 반환
이런 구조에서 OCR 부분에서만 batch 를 적용해봅니다.
요청을 보낼 때 ....
크롤링한 모든 포스트들에서 OCR을 진행할 것이 아니기 때문에 파싱 결과와 OCR 진행 여부를 저장할 DTO를 우선 생성합니다.
public record BatchImageParsingRequest(
TextExtractResponse response,
boolean parse,
String imageUrl
) {
}HTMl 파싱 결과와 parse는 OCR 진행 여부를 나타내고, imageUrl은 파싱할 이미지의 url 입니다.
OCR using batch
parsingRequests.stream().parallel().forEach(parsingRequest -> {
if (parsingRequest.parse()) {
AnnotateImageRequest request = createParsingRequest(parsingRequest.imageUrl());
requests.add(request);
}
});이렇게 입력으로 들어온 요청 리스트에서 파싱을 해야할 경우는 OCR 요청을 생성한다. 그리고 응답을 받을 때 주의해야 하는데, 모든 요청에 대해서 OCR을 진행한 것이 아니기 때문에 OCR 파싱을 진행한 경우에만 OCR 결과를 가져와야 한다. 이를 위해서 OCR 결과를 큐에 저장하고, 요청을 순회하면서 파싱해야하는 경우였다면, 큐에서 결과를 하나씩 빼오는 로직을 작성하였다.
BatchAnnotateImagesResponse response = client.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = response.getResponsesList();
List<String> result = parseResponseData(responses);
if (result.isEmpty()) return null;
Queue<String> resultQueue = new LinkedList<>(result);완료! 이제 마지막으로 성능 테스트의 시간이다.
성능
DB에 추가할 때도, batch를 활용하면 속도가 굉장히 빨라진다. 과연 이번에는 얼마나 빨라질까??
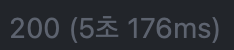
무려 절반 !!! 아직 5초대가 나오기는 하지만, 그래도 2배 빨라졌습니다. OCR을 매번 하는 것도 아니고, 프로젝트를 시작하면 파싱 결과를 다 저장해둘 것이기 때문에 이보다 시간은 덜 걸릴 것 같습니다.
하지만 그래도 여전히 오래 걸리고, 수정이 필요합니다. HTML 파싱과 OCR 둘 다 줄여야 하는데, HTML은 우선 파이썬으로 대체해볼 예정이며 OCR은 .... 좀 더 찾아봐야 할 듯 ... 한데 ...
TODO List
1. 자바 병렬처리
2. 파이썬 라이브러리 속도 측정
3. Go 언어 HTML 파싱 라이브러리 탐색
4. 필터링 로직 구현
5. 필터링 전체 시간 테스트
6. 프론트 디자인 구상
7. 엔티티 설계 및 ERD 작성
8. OCR 모델 탐색
후하 많이도 했는데 더 많이 남았다 ...^0^
