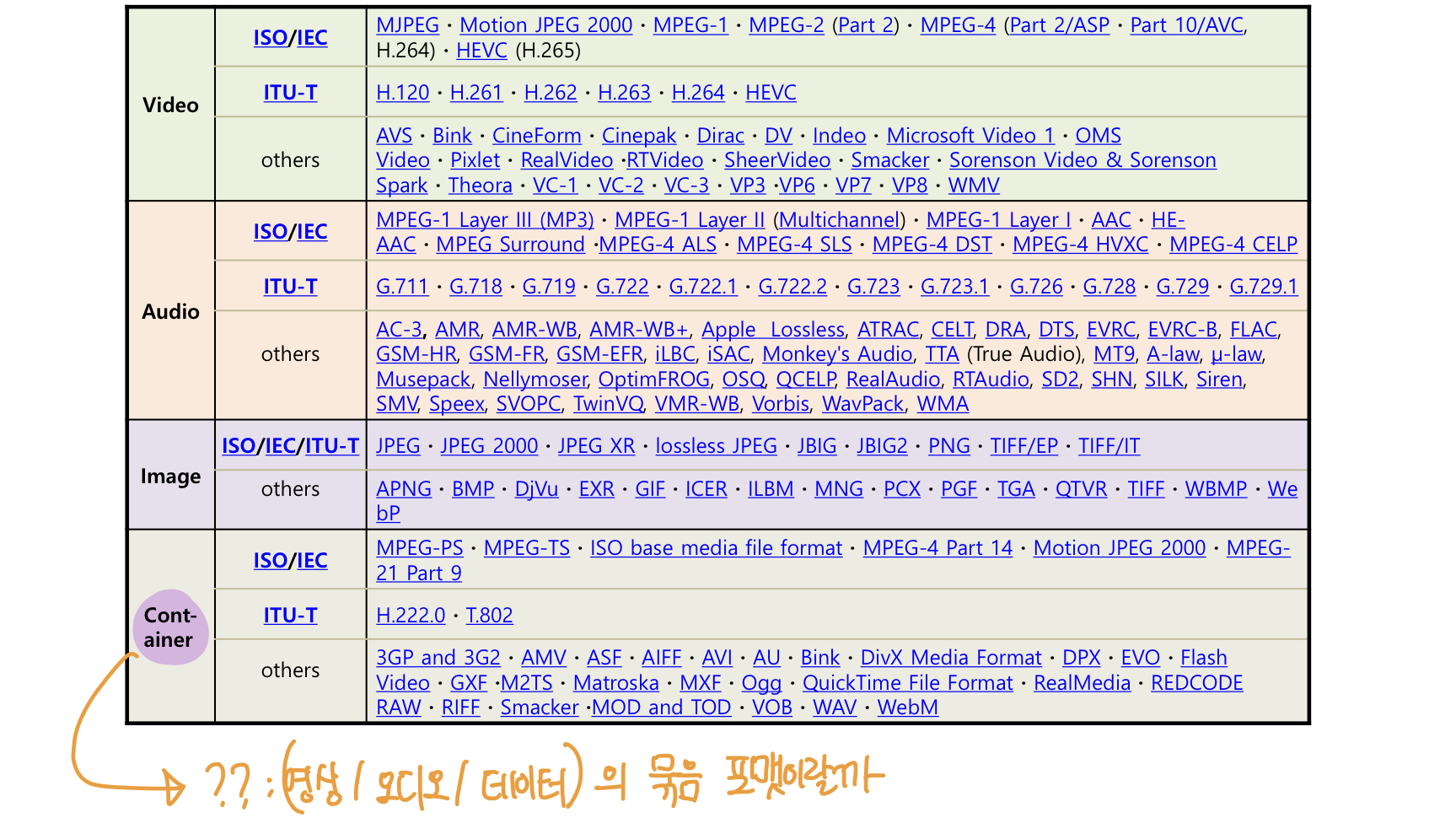
압축 표준에는 여러가지가 있습니다.
영상처리 과정
- Analog / Digital Convert
- RGB-YUV Convert
- Subsampling
- Encoding
위 과정을 거쳐 압축됩니다.
Color space
YUV
명도(휘도)와 채도로 나타낸 색상계 입니다.
- Y : 명도
- U : 채도 (청색 계열, Y - B)
- V : 채도 (적색 계열, Y - R)
RGB와 YUV는 서로 변환이 가능합니다. YUV를 사용하는 이유는 사람의 눈은 색상보다 밝기에 민감하기 때문에 명도에 좀 더 중점을 두기 위해서 입니다. subsmpling은 명도는 유지시키고 색깔 정보의 양을 줄이는 과정입니다.
Subsampling
Y, U, V의 비율을 다르게 해서 추출하는 방식입니다. 명도의 비율은 유지하고 채도의 정보를 압축하여 최종적으로 데이터의 양을 압축합니다.
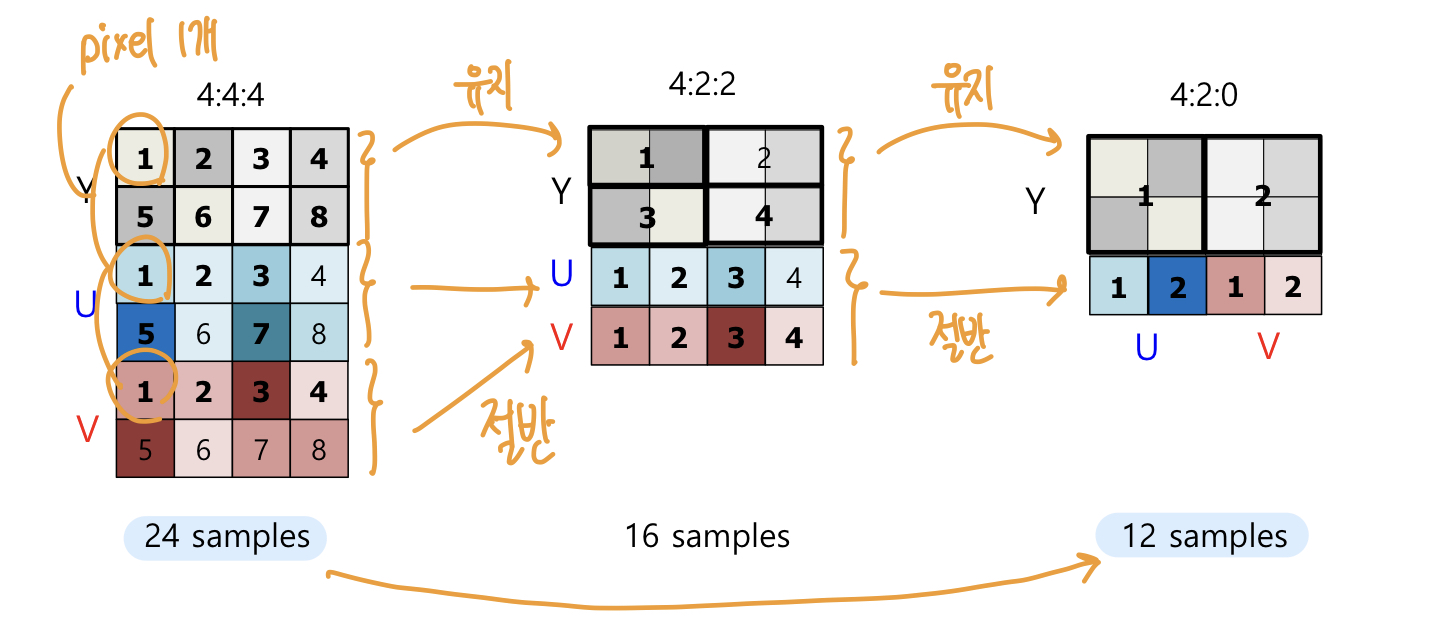
4:4:4는 비손실 압축이고, 4:2:0 으로 압축할 경우 데이터의 양을 50% 압축이 가능합니다.
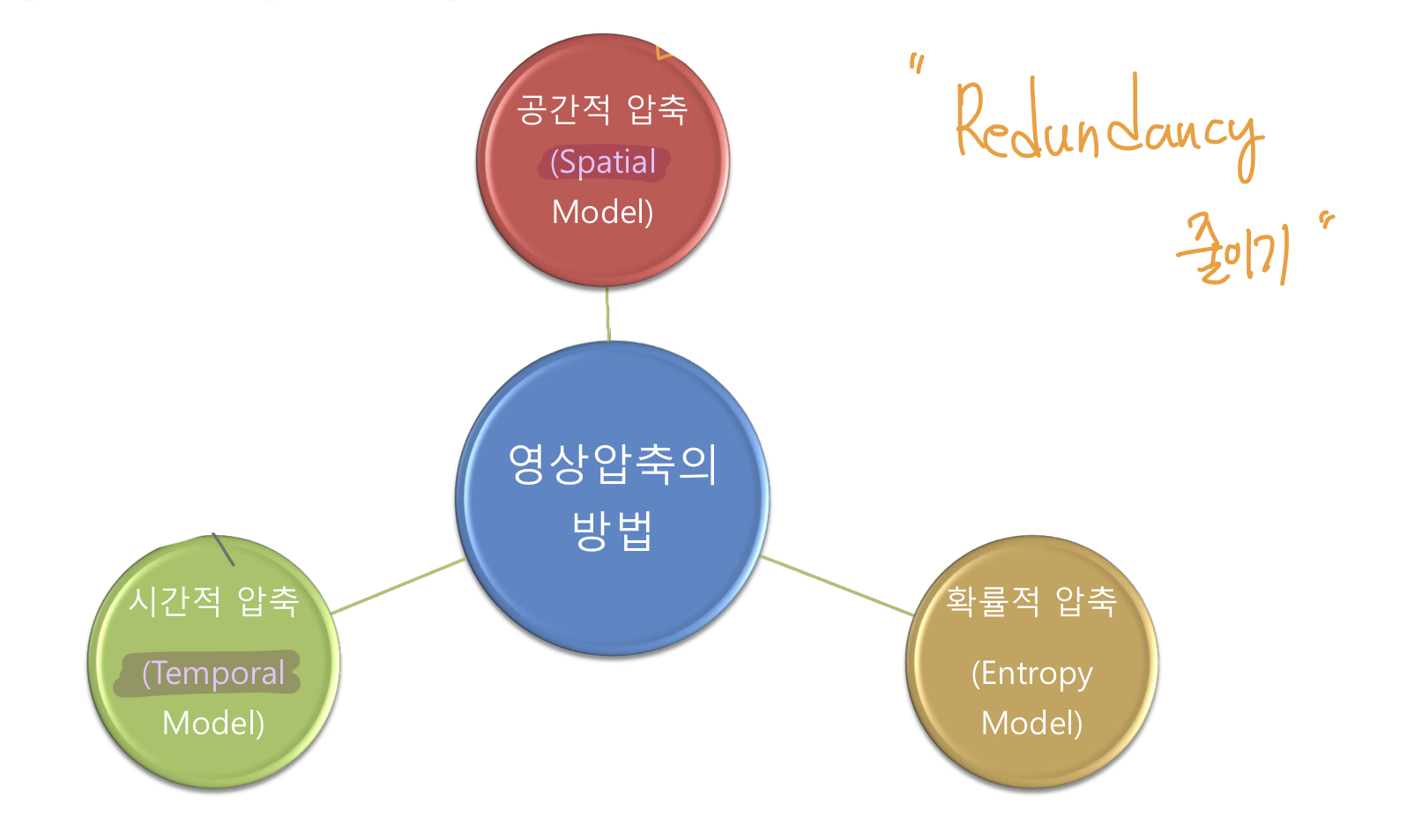
영상 압축의 방법
영상 압축에는 3가지 방법이 있습니다.
- 공간적 압축 (Spatial Model)
- 시간적 압축 (Temporal Model)
- 확률적 압축 (Entropy Model)
압축의 목적은 결국 Redundancy 줄이기 라고 할 수 있습니다.
공간적 압축 (Spatial Model)
공간 주파수를 활용하여 압축합니다. 공간 주파수(spatial frequency)란 공간에서의 색이나 구조의 변화를 주파수의 형태로 표현한 것입니다.

DCT(Discrete Cosine transform) 을 이용하여 화소 값을 공간 주파수로 변환합니다. 푸리에 변환과 유사한 변환입니다. 일반적으로 DCT 값들은 저주파로 몰리는 성질이 있습니다. DCT Coefficient Matrix 에서 저주파는 큰 변화(특성)을 나타냅니다. 따라서 Quantizing을 진행할 때 최대한 값을 보존해야 합니다.
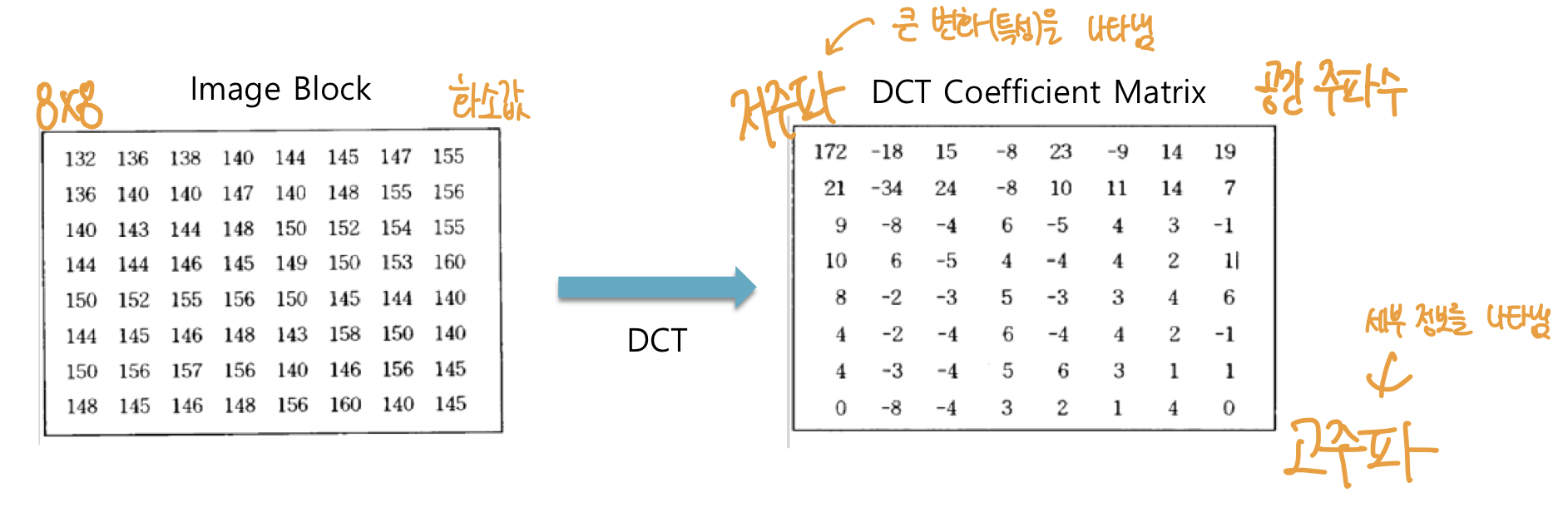
공간적 압축 과정의 예시는 다음과 같습니다.
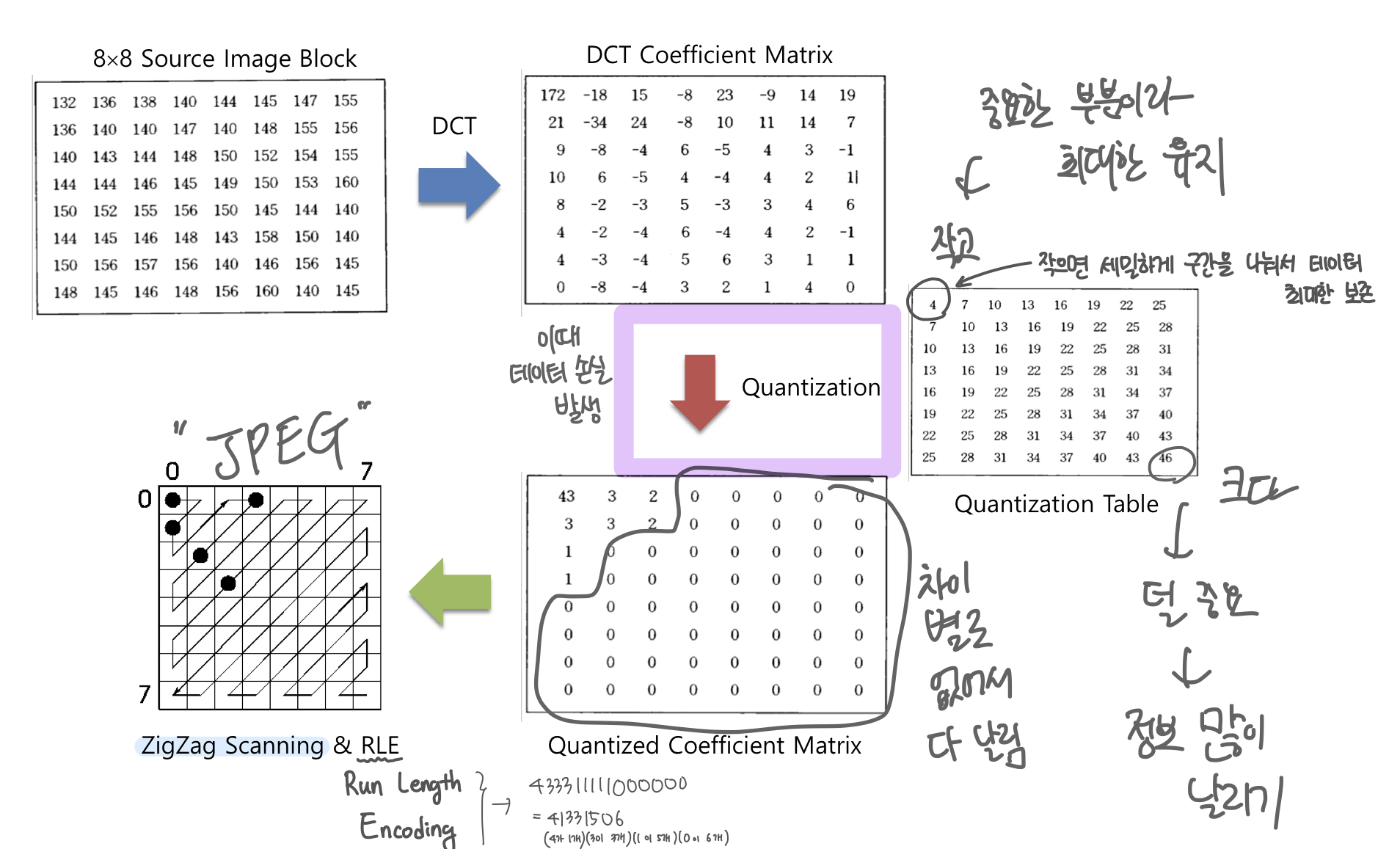
DCT 행렬에서 저주파 부분 (왼쪽 상단) 의 데이터는 Quantizing 과정에서 구간을 세밀하게 나누어 데이터를 최대한 보존합니다. 따라서 나누는 값이 작습니다. 반대로 고주파 부분 (오른쪽 하단) 은 상대적으로 덜 중요한 부분이기에 구간을 크게 나누어 정보의 양을 줄입니다.
RLE (Run Length Encoding)
문자의 개수로 인코딩하는 방법입니다. 예를 들어, 433311111000000 이런 데이터가 있다고 하면, RLE 방식으로 인코딩하면 4개 1개, 3이 3개, 1이 5개, 0이 6개 이기 때문에 41331506 이 됩니다.
시간적 압축 (Temporal Model)
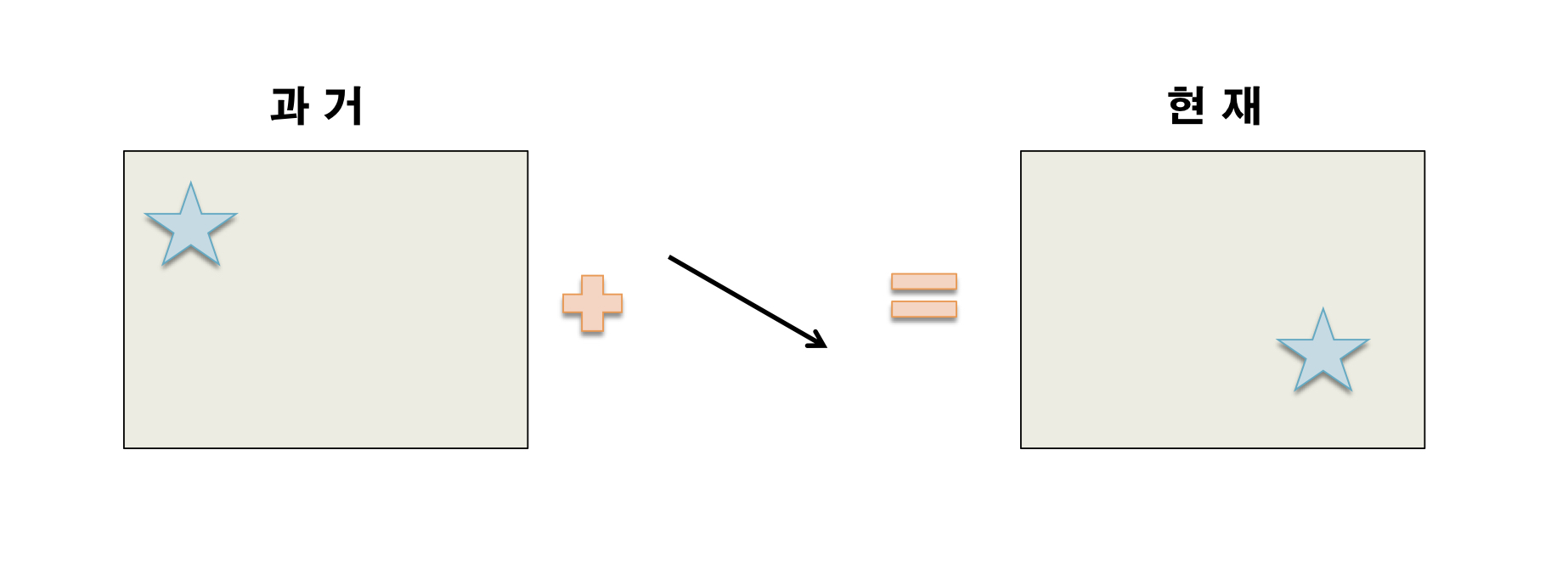
Differential Endocing 이 시간적 압축의 큰 개념입니다. 기준이 되는 프레임에서 변화만 저장하여 다음 프레임의 정보를 생성합니다. 시간적 압축에는 2가지 과정이 있습니다.
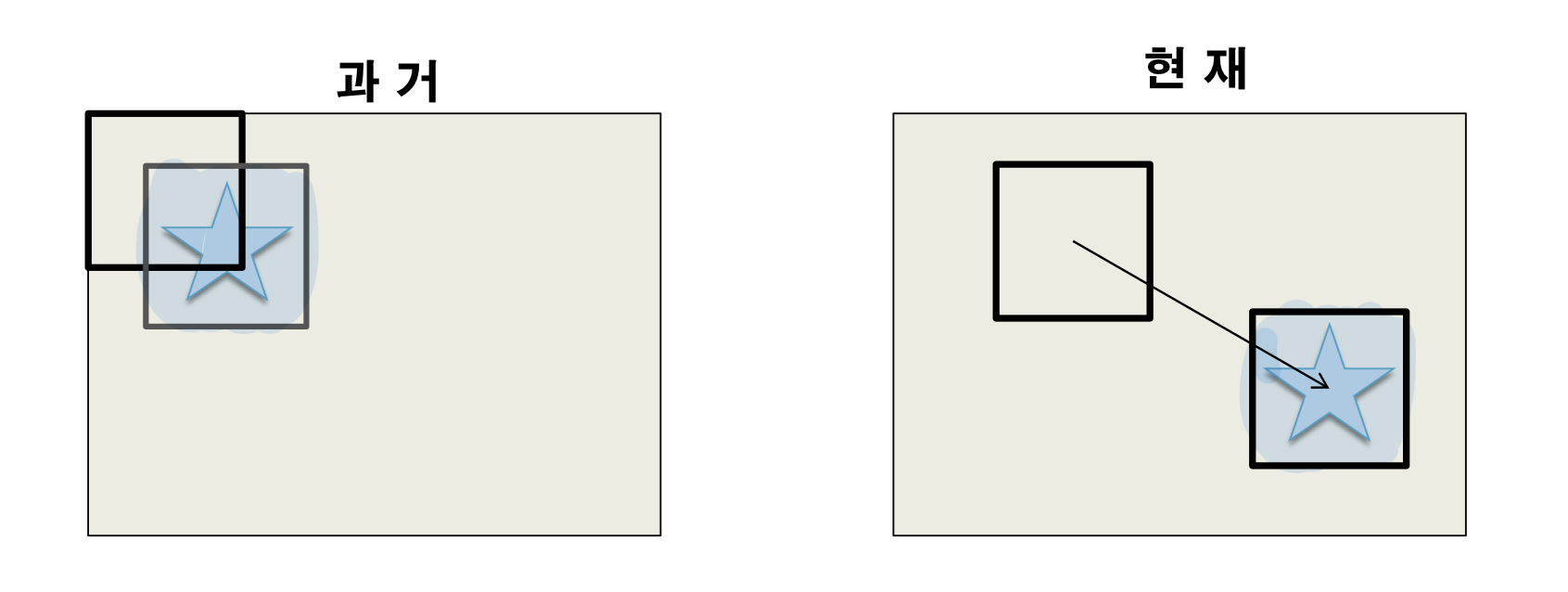
움직임 예측 (Motion Estimation)
현재의 블록을 과거의 프레임에서 찾는 과정입니다.
움직임 보상 (Motion Compensation)
움직임 벡터 (Motion Vector)를 구하는 과정입니다.
이제 압축을 해야 합니다!!
움직임 벡터와 기준 프레임을 사용하여 현재의 프레임을 복구합니다. 바로 아래처럼 말이죠
Group of Pictures (GOP)
시간적 압축에서 프레임들의 집합이라고 볼 수 있습니다. GOP는 I 프레임과 다음 I 프레임 사이의 거리입니다. 예를 들어
I B B P B B I 이 순서로 프레임이 있다고 한다면, GOP 값은 6이 됩니다. (즉, 두개의 I 프레임 사이의 프레임 개수 + 1 입니다)
시간적 압축에서 사용되는 프레임의 종류에는 3가지가 있습니다.
I frame
기준이 되는 프레임입니다. 이후에 오는 프레임 예측에 필요한 기준 프레임입니다.
P frame
이전의 I frame 만 비교하여 생성한 프레임입니다. unidirectional prediction 입니다.
B frame
앞, 뒤 프레임과 비교해서 바뀐 부분의 데이터만 저장하는 프레임 입니다. bidirectional prediction 입니다.
위 프레임들 중, P 와 B 프레임이 differential encoding을 이용하여 생성한 프레임이고 두 프레임에서 변화하기 전 기준 프레임이 I 프레임 입니다.
중요한 점은, 프레임의 재생 순서와 코딩 및 전송 순서가 다릅니다 !!! P 프레임이 존재하기 위해서는 변화의 기준이 되는 I 프레임이 필요하고, B 프레임이 존재하기 위해서는 변화를 반영할 I, P 프레임이 있어야 합니다. 따라서
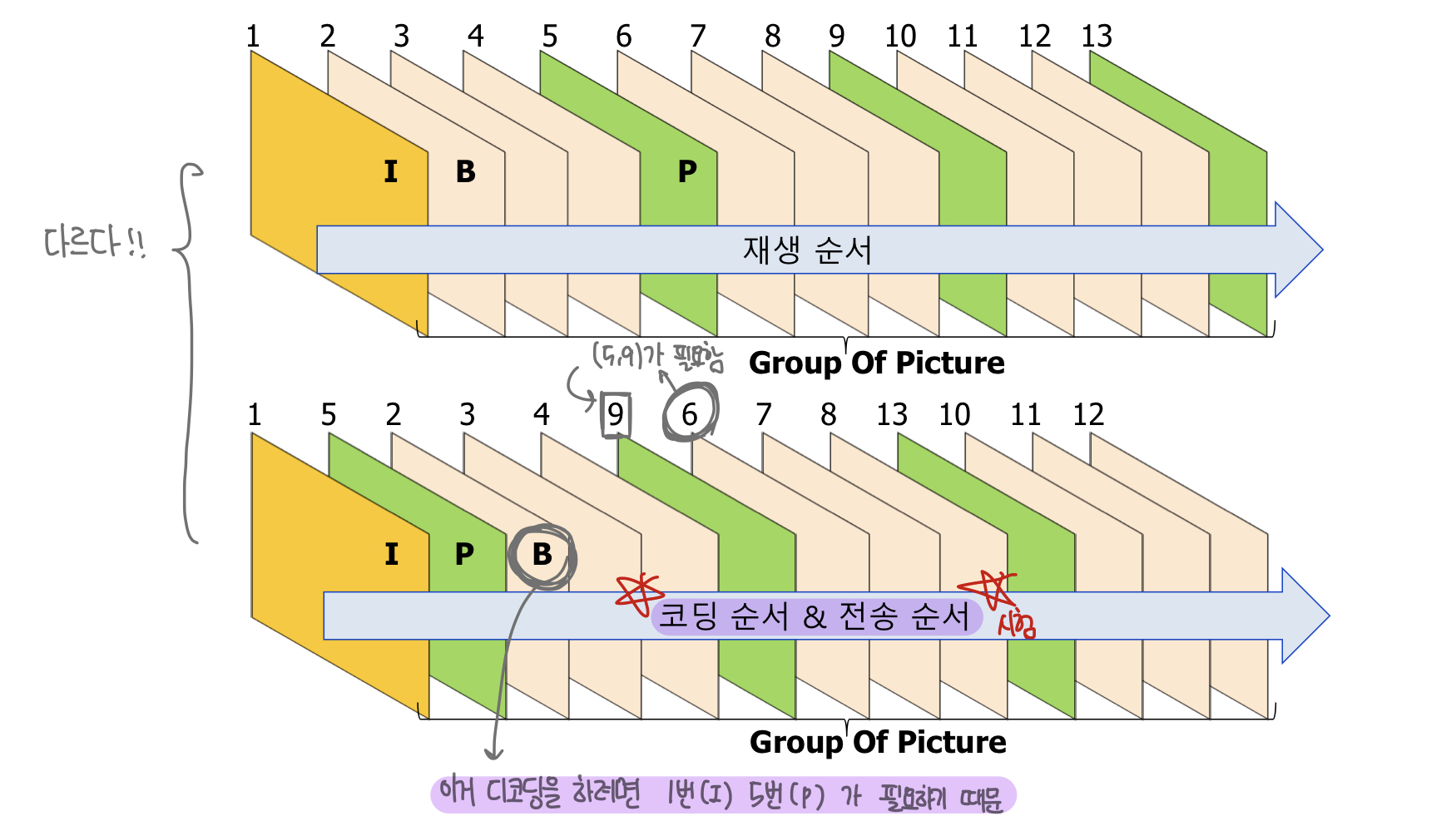
이런식으로 인코딩 및 전송해야 합니다.
확률적 압축 (Entropy Model)
확률적 압축을 위해서는 Information measure 을 구해야 합니다. 이는 해당 데이터의 발생 빈도의 역수에 로그를 취해 구할 수 있습니다.
입니다. 이를 이용하여 Entropy를 계산할 수 있습니다.
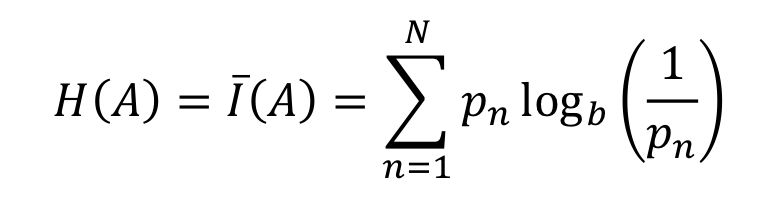
식을 자세히 보면, 발생 확률(빈도) * 값 형태이므로 엔트로피도 일종의 평균 값이라고 볼 수 있습니다.
엔트로피 코딩
자주 등장하는 데이터를 더 작은 코드로 인코딩 합니다.
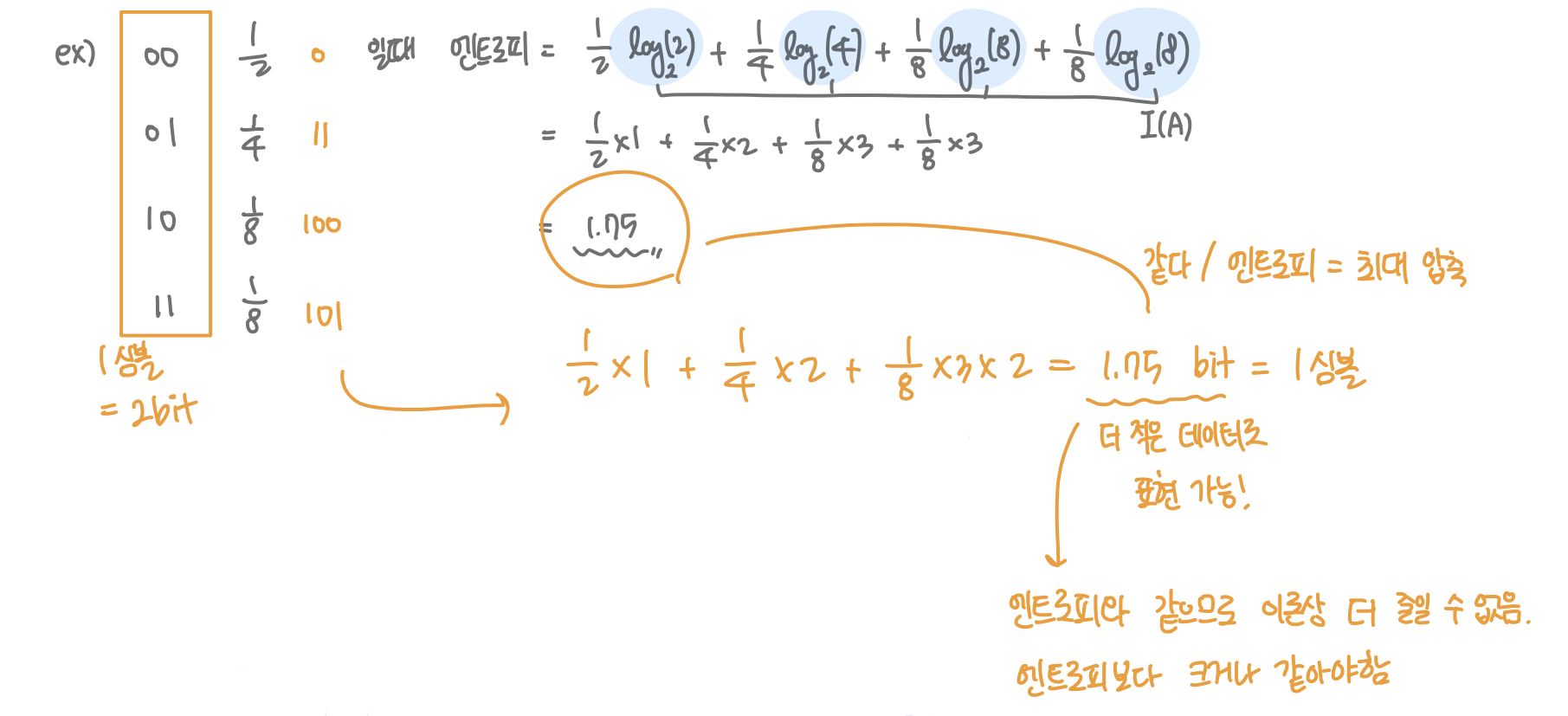
이런식으로 엔트로피를 구합니다. 엔트로피는 이론상 최대로 압축 가능한 비트수 입니다. 위 예시에서는 인코딩에 2비트씩 필요하던 데이터가 평균 1.75 비트만 있으면 인코딩이 가능해집니다. 즉, 더 적은 데이터로 표현할 수 있게 되었습니다. 이 때 필요한 비트 수는 엔트로피보다 항상 크거나 같아야 합니다.
