Interprocess Communication
프로세스간 통신입니다! 프로세스는 독립적(independent)일 수도, 협력적(cooperating)일 수도 있습니다. 서로 협력적인 경우에는 데이터 공유가 필요합니다. 이렇게 협력적 프로세스가 있는 이유는
- 정보 공유 : 여러 사용자가 동일한 데이터에 관심을 둘 수 있기 때문에 병렬적 접근 필요
- 처리 속도 향상 : 서브 태스크로 나누어 병렬 실행을 위해 (멀티코어 사용)
- 모듈성 : 시스템 기능을 별도의 프로세스들 또는 스레드들로 구성
- 편의성 : 한 순간에 많은 작업이 가능하도록 (예를 들어 영상 편집 시에 편집, 음악 듣기, 컴파일을 동시에 수행)
프로세스간 통신을 위해서는, interprocess communication (IPC) 가 필요합니다. IPC 에는 2가지 타입이 있습니다.
Shared memory
협력 프로세스 간 공유할 메모리 영역을 설정합니다. 해당 영역을 통해 데이터를 읽고 씁니다. 적은 양의 데이터 교환에 유용합니다.
Message passing
협력 프로세스 간 메시지 교환을 통해 정보를 공유합니다. 시스템 콜을 사용하기 때문에 time-consuming 작업이 필요해서 상대적으로 느립니다.
하지만 최근 멀티코어 시스템으로 공유 메모리 방식보다 빠릅니다. (캐시 일관성 문제 때문에)
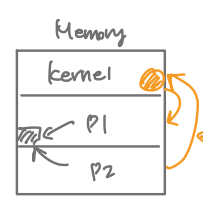
검은색이 shared memory 구조이고, 주황색이 message passing 입니다. 보다 자세히 나타내자면,
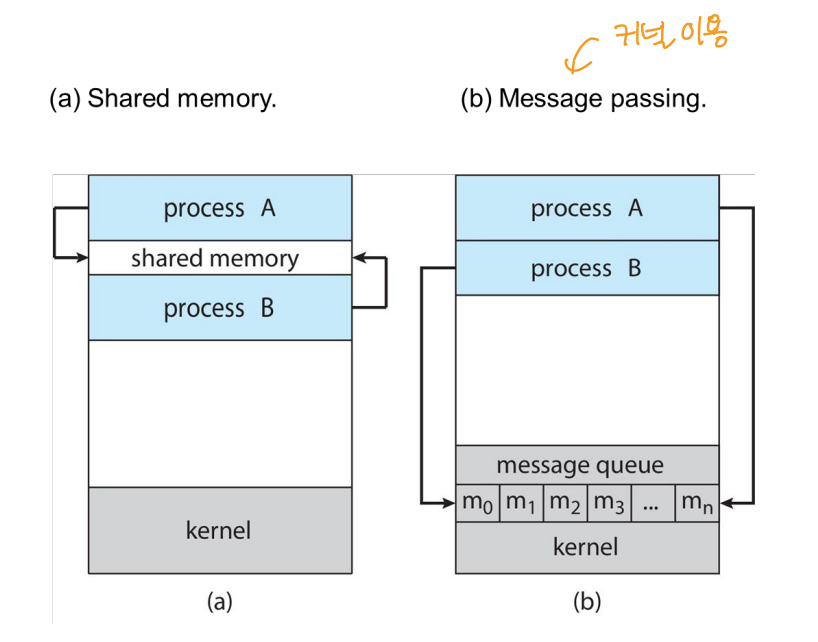
라고 할 수 있습니다.
IPC - shared memory system
unbounded-buffer
- 버퍼 크기에 제한이 없습니다.
- Producer 는 버퍼가 가득 찰 일이 없기 때문에 대기하지 않습니다.
- Consumer 는 버퍼가 비어있을 경우 대기합니다.
bounded-buffer
- 버퍼 크기에 제한이 있습니다.
- Producer 는 버퍼가 가득 차면 대기합니다.
- Consumer 는 버퍼가 비어있을 경우 대기합니다.
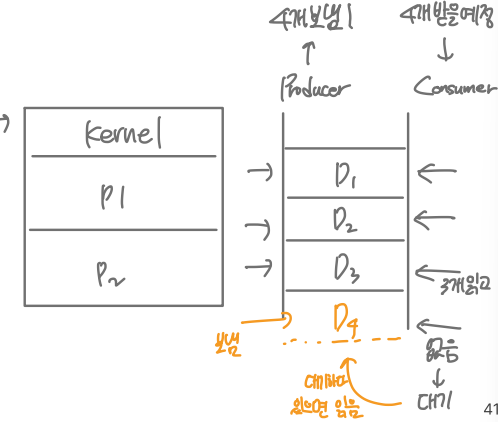
이런 느낌이라고 할 수 있습니다.
IPC - shared memory
- 통신은 유저 프로세스의 제어 하에 있습니다! (운영체제가 아니다 !!)
- 관건은, shared memory에 접근할 때 이벤트를 동기화하는 문제가 있습니다.

이런 구조로 버퍼를 구현합니다. 근데, 오직 BUFFER_SIZE - 1 개의 원소들만 사용할 수 있습니다! 왜 ?!
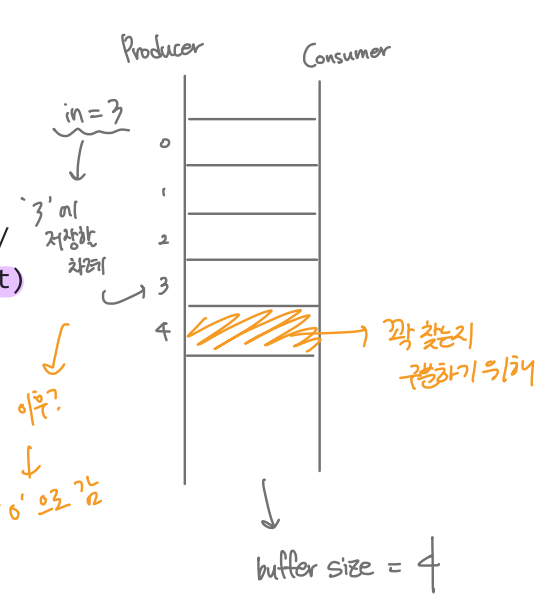
이렇게 해서 꽉 찼는지의 여부를 파악합니다. (왜냐하면 모듈러 연산이 들어가기 때문) Producer 입장의 코드를 살펴보면 대기 조건이 다음 버퍼가 비어있는 경우입니다.

반대로, Consumer 입장을 살펴보면

같으면 대기, 읽을 버퍼가 생기면 읽습니다. 근데, 이렇게 하면 계속해서 버퍼 1개를 사용하지 않습니다!! 이걸 해결하려면, counter을 만들어 버퍼를 전부 채울 수 있습니다.
Producer 코드를 다음과 같이 수정합니다.

그리고 Consumer 코드를 다음과 같이 수정합니다.

근데 counter 방식에도 문제가 있습니다. 카운터 증감을 위한 명령어 구조를 살펴보면,
- 카운터 증가 코드
register1 = counter
register1 = register1 + 1
counter = register1- 카운터 감소 코드
register2 = counter
register2 = register2 - 1
counter = register2문제는, 이 명령어들이 atomic한 작업이 아니라는 점 입니다. 즉, 실행 도중 CPU가 넘어갈 수 있습니다. 이런걸 같은 변수를 두고 Race(경합)이 발생한다 라고 합니다.
예를 들어 counter가 5로 초기화 된 경우를 살펴보면
register1 = counter
register1 = register1 + 1
register2 = counter
register2 = register2 - 1
counter = register1
counter = register2이런 순서로 실행되고, 레지스터과 카운터의 값을 살펴보면
register1 = 5
register1 = 6
register2 = 5
register2 = 4
counter = 6
counter = 4이렇게 원래라면 5 > 6 > 5 가 나와야 하지만, 실제로는 5 > 6 > 4 로 다른 값이 저장됩니다. 근데 왜 N-1개의 버퍼만 사용하는 방식에서는 race condition이 발생하지 않을까요 ??
해당 내용은 추후에 살펴보도록 하겠습니다.
IPC - message passing system
2개의 동작을 지원합니다.
- send(message)
- receive(message)
다른 프로세스로 보내는 것으로 보이지만, 실제 구현은 커널로 보냅니다. 두 프로세스 간 통신을 할 때에는 communication link가 생성됩니다.
communication link 의 구현
Physical
- Shared memory
- Hardware bus
- Network
Logical
- Direct or indirect
- Synchronous or asynchronous
- Automatic or explicit buffering
Direct Communication
- 커널 없이 통신합니다.
- 링크는 자동으로 설정합니다.
- 링크는 정확히 한 쌍의 프로세스 사이에 구성됩니다.
- 각 쌍 사이에는 정확히 하나의 링크가 존재합니다.
- 링크는 단/양방향 둘 다 가능하지만 일반적으로 양방향입니다.
Indirect Communication
일반적으로, 명시적 통신은 하드코딩에 가깝습니다. (즉, 바람직하지 않습니다) 하지만 살펴본다면!
메지시는 mailbox를 통해 주고 받습니다.
- mailbox는 프로세스가 메시지를 입력하거나 제거할 수 있는 추상적인 객체를 의미합니다.
- 각 mailbox는 고유한 id 가 있습니다.
- 프로세스는 mailbox를 공유하는 경우에만 통신할 수 있습니다.
- 통신 링크는 여러 프로세스 사이에 구성될 수 있습니다.
- 각 프로세스 쌍은 여러 링크를 공유할 수 있습니다.
- 링크는 단/양방향 둘 다 가능합니다.
만약, mailbox sharing 중 receiver를 지정하지 않았다면?
- 링크가 최대 두 프로세스와 연결되도록 허용
- 수신 작업을 실행하기 위해 한 번에 하나의 프로세스만 허용
- 시스템이 receiver를 임의로 선택하도록 허용
- sender 에게 receiver 가 누구인지 알리기
Synchronization
message-passing 방식은 blocking 이거나 non-blocking 중 하나입니다. sender와 receiver는 각각의 blocking 여부를 결정할 수 있습니다. 만약 sender, receiver 둘 다 blocking 상태라면, rendezvous 라고 합니다.
Blocking (synchronous)
- Blocking send -- sender는 메시지를 받을 때까지 blocked 됩니다.
- Blocking receive -- receiver는 메시지를 받을 때까지 blocked 됩니다.
즉, 보내거나 받을 때 상대가 없으면 대기합니다.
Non-blocking (asynchronous)
- Non-blocking-send -- sender는 메시지를 보내고 계속 실행합니다.
- Non-blocking-receive -- receiver는 메시지 혹은 null message 를 전달받습니다.
즉, 메시지가 없어도 그냥 NULL 로 사용합니다.
Buffering
메시지 큐를 link에 첨부합니다.
구현
- Zero capacity : 링크에 어떤 메시지도 없는 경우 (sender는 receiver를 위해 기다려야만 합니다. rendezvous)
- Bounded capacity : 메시지 길이가 유한한 경우입니다. (Sender는 링크가 꽉차면 대기해야만 합니다. blocked)
- Unbounded capacity : 길이 제한 없음 (Sender는 기다리지 않습니다.)
