
🧶 컬렉션 프레임워크란?
많은 데이터를 효과적으로 처리하기 위한 표준 방법을 제공하는 클래스의 집합이다.
데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 클래스로 구현한 것으로,
컬렉션 프레임워크를 사용하면 객체 지향적이고 재사용성이 높은 코드를 작성할 수 있다.
이러한 컬렉션 프레임워크는 interface를 사용해 구현된다.
✨ 컬렉션 프레임워크의 장점
객체 지향적이고 재사용성이 높은 코드를 작성할 수 있다.
고정적인 저장 공간을 제공하는 배열에 반해, 컬렉션 프레임워크는 가변적인 저장 공간을 제공한다.
자료구조, 알고리즘을 구현하기 위한 코드를 직접 작성할 필요 없이, 이미 구현된 컬렉션 클래스를 목적에 맞게 선택하여 사용하면 된다.
데이터 삽입, 탐색, 정렬 등 편리한 API를 다수 제공한다.
이러한 장점으로 개발자는 배열보다는 적절한 컬렉션 클래스를 선택해 사용하는 것이 권장된다.
📋 컬렉션 프레임워크의 주요 인터페이스
컬렉션 프레임워크에서는 데이터를 저장하는 자료 구조에 따라 다음과 같은 핵심이 되는 주요 인터페이스를 정의하고 있다.
- List 인터페이스
- Set 인터페이스
- Map 인터페이스
List와 Set 인터페이스는 모두 Collection 인터페이스를 상속받지만, 구조상의 차이로 인해 Map 인터페이스는 별도로 정의된다.
따라서 List 인터페이스와 Set 인터페이스의 공통된 부분을 Collection 인터페이스에서 정의하고 있다.
List 인터페이스
순서가 있는 데이터의 집합으로, 데이터의 중복을 허용한다.
인덱스 순서대로 요소를 저장한다.구현 클래스 :
ArrayList,LinkedList,Vector(+Vecoter를 상속받은 Stack)
-
ArrayList는
Object[]배열을 사용하며 내부 구현을 통해 동적으로 관리한다. -
LinkedList는 데이터와 주소로 이루어진 클래스를 만들어 서로 연결하는 것이다. 즉, 객체끼리 연결한 방식이다.
-
Vector는 ArrayList와 거의 같다고 보면 된다.
Object[]배열을 사용하며 요소 접근에서 빠른 성능을 보인다.
Vector의 경우 항상 동기화를 지원한다. -
Stack은 가장 위에 있는 데이터부터 사용 가능한, 후입선출 방식이다.
Vector 클래스를 상속받고 있으며 Vector와 크게 다를 것은 없다.
List의 대표적 메서드
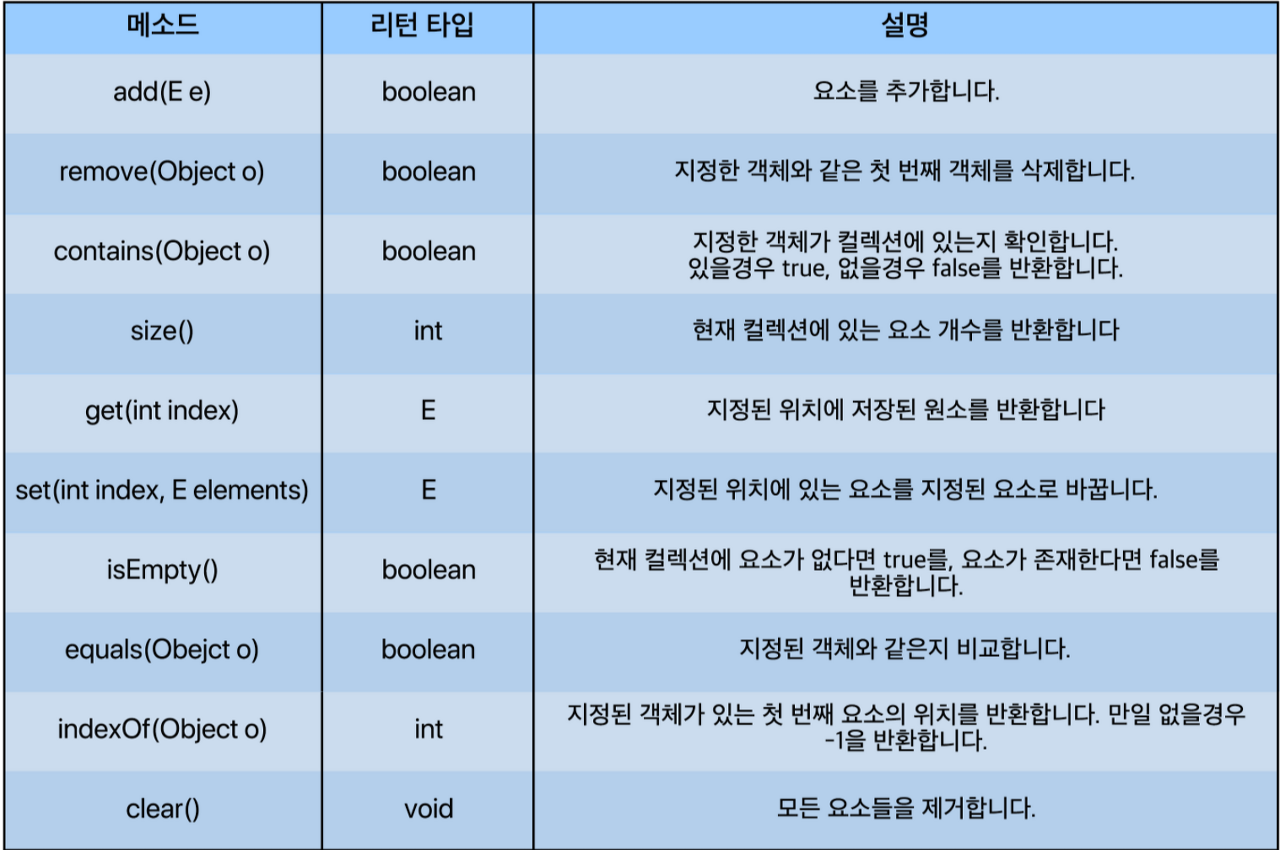
예시
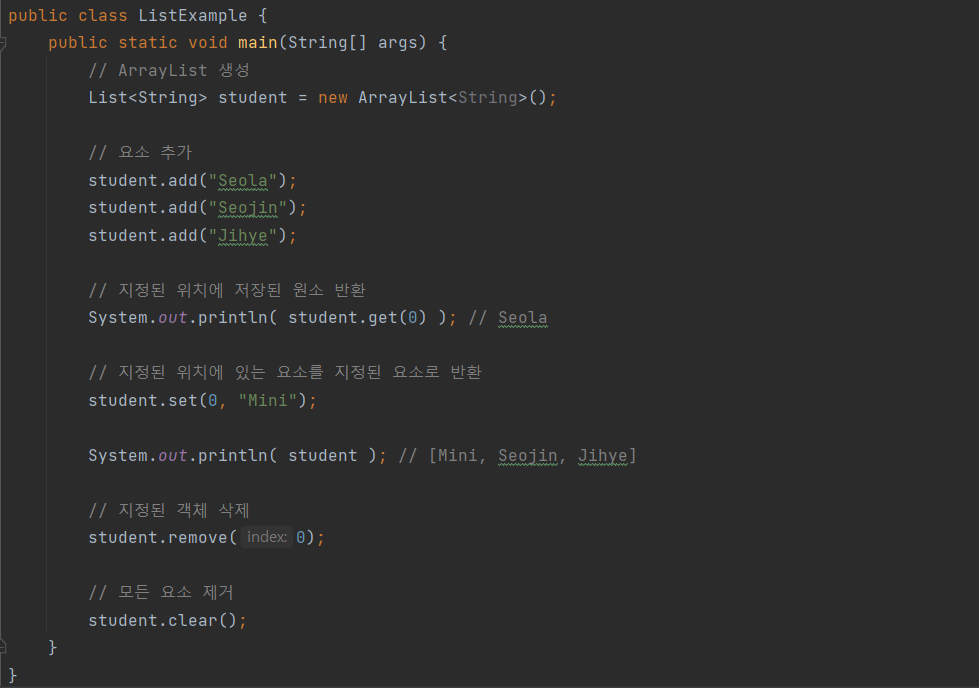
List 인터페이스와 메서드를 활용한 예시이다!
Set 인터페이스
순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않는다.
구현 클래스 :
HashSet,LinkedHashSet,TreeSet
Set의 대표적 메서드
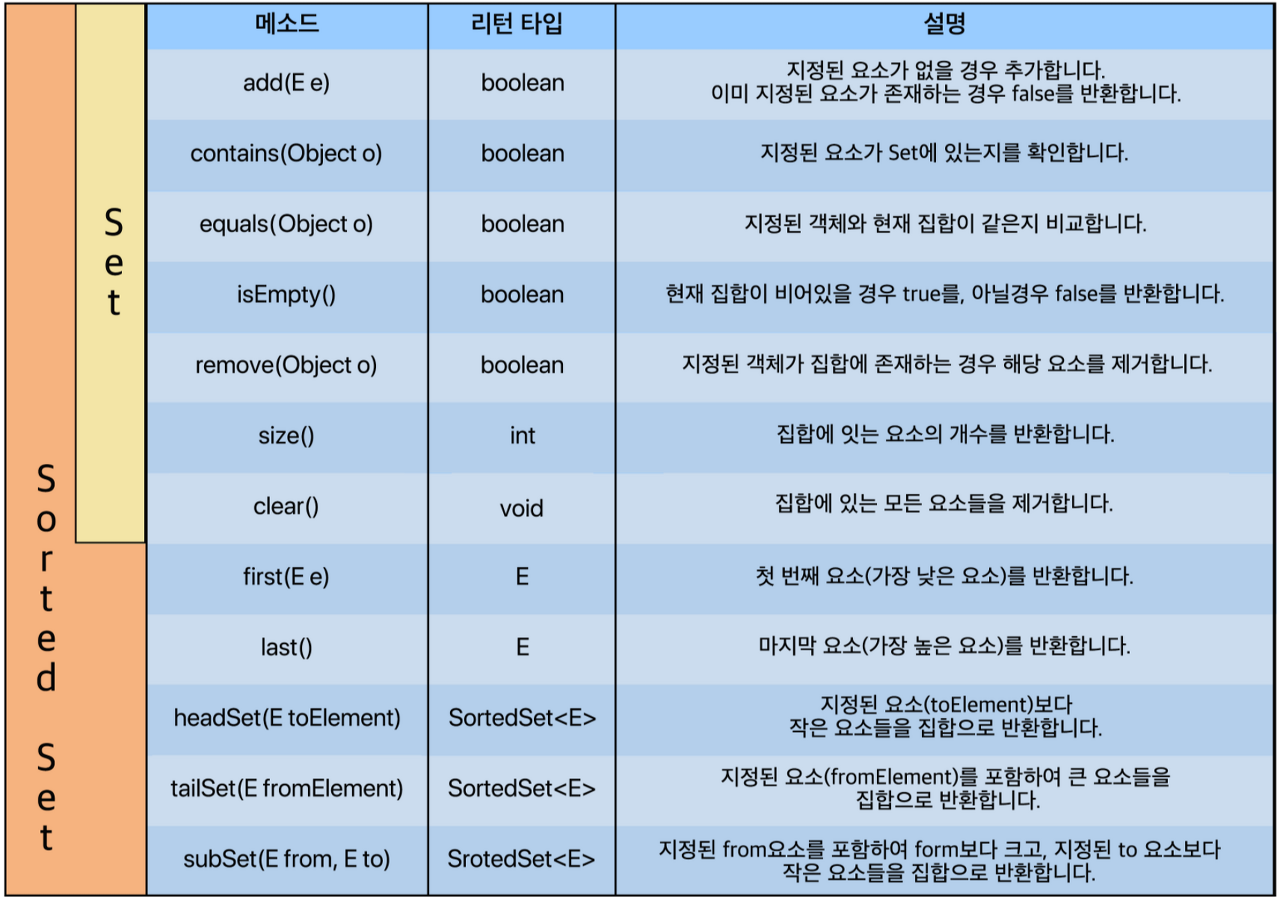
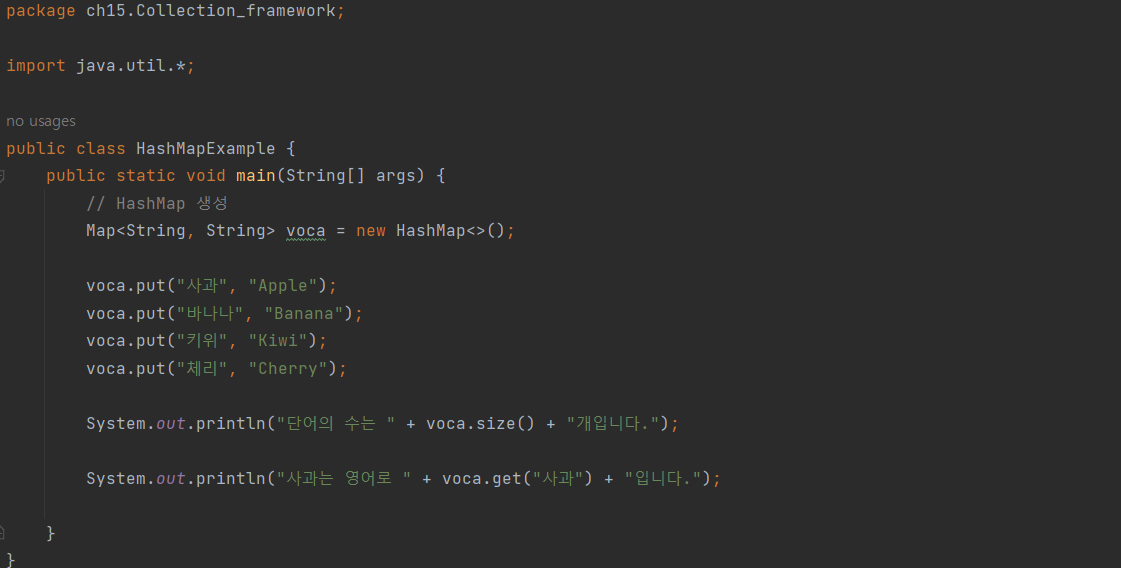
Map 인터페이스
키와 값의 한 쌍으로 이루어지는 데이터의 집합으로, 순서가 없다.
키를 이용해서 값을 찾을 수 있으며, 키는 중복되어서는 안 된다.구현 클래스 :
HashMap,TreeMap,Hashtable,Properties
삽입 / 삭제 / 조회 연산이 굉장히 빠르지만, 순서를 보장하지 않고 정렬이 불가하다는 단점을 가지고 있다.
Map의 대표적 메서드
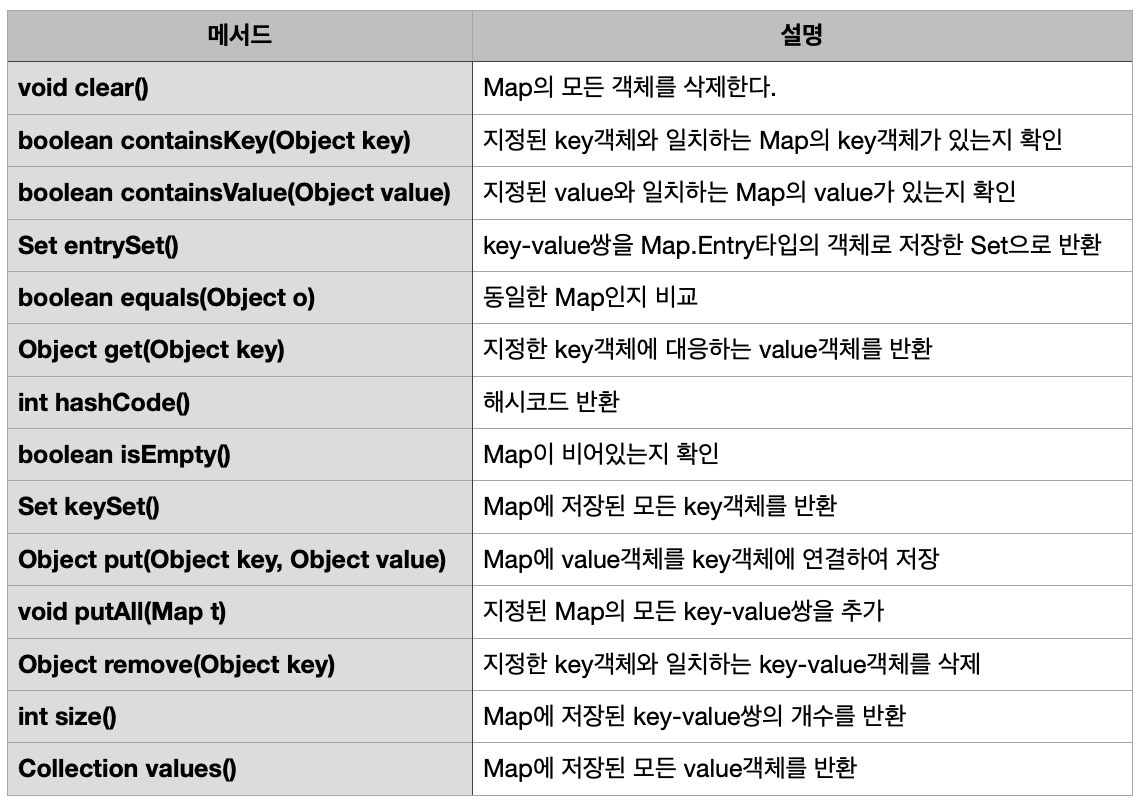
예시
👋 주요 인터페이스 간 상속 관계
컬렉션 프레임워크를 구성하고 있는 인터페이스 간의 관계는 다음과 같다.
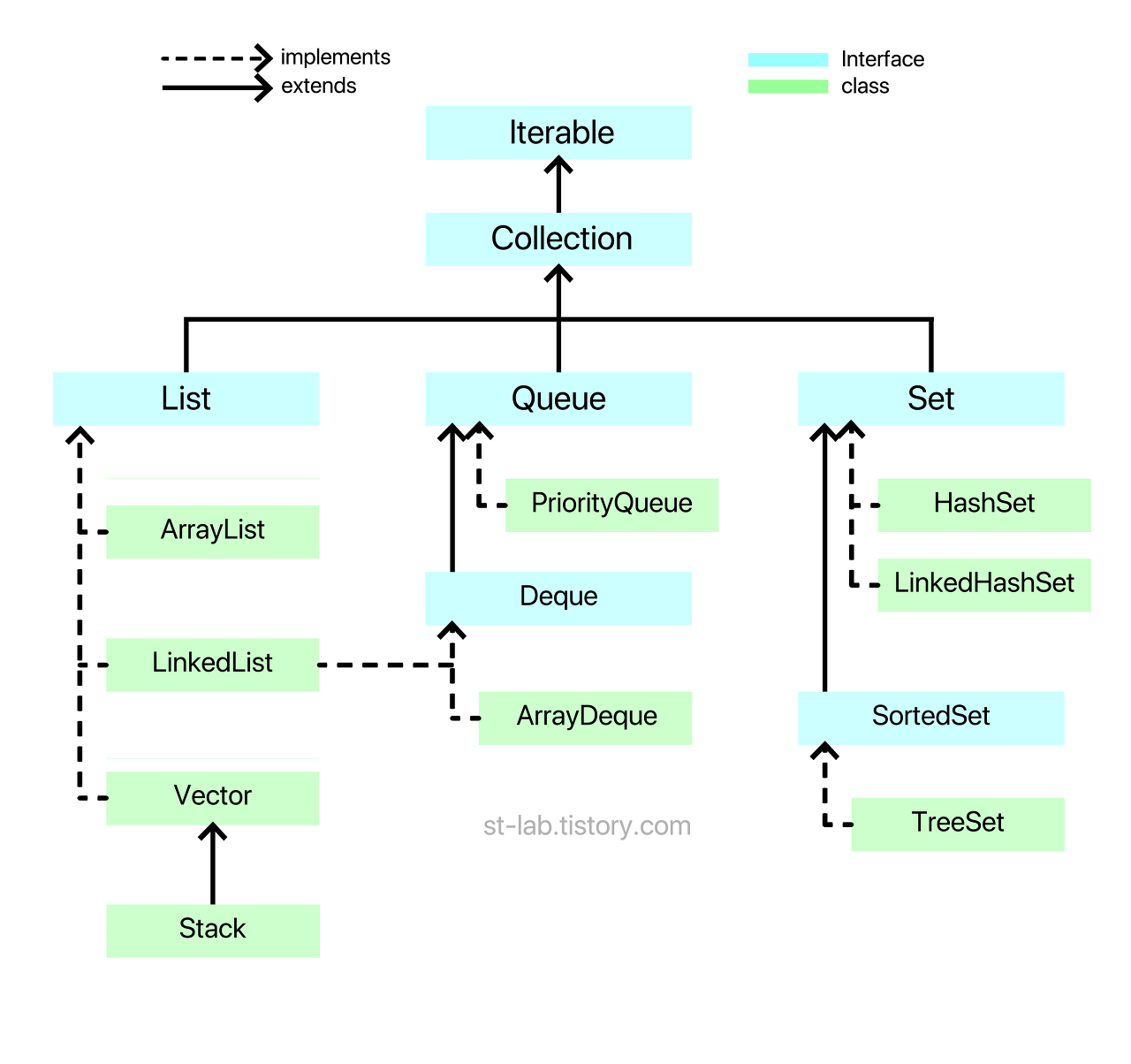
점선은 구현 관계, 실선은 확장 관계다.
Collection을 구현한 클래스 및 인터페이스들은 모두 java.util 패키지에 있다.
자료 출처 : https://ssdragon.tistory.com/70, http://www.tcpschool.com/java/java_collectionFramework_concept, https://st-lab.tistory.com/142
