5.6
- 오늘 수강한 분량: 범죄 4~6
5.7
- 오늘 수강한 분량: 웹데이터1
Chapter 04. 웹데이터 분석
[html]
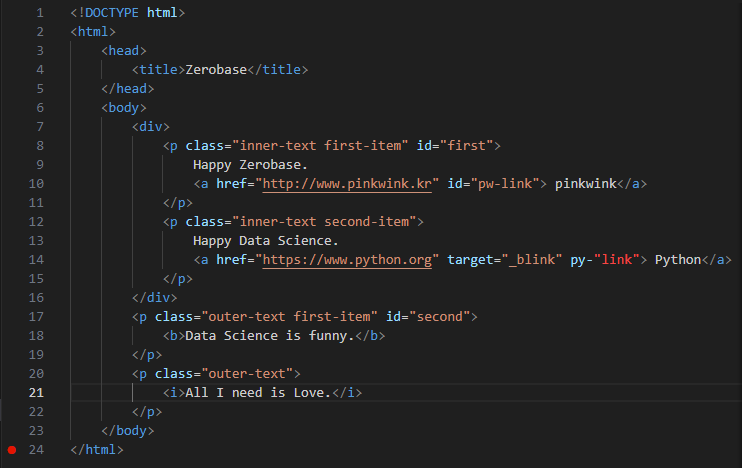
- html은 꼭 형식으로 끝내줘야 한다.
- title: 페이지 맨 위 상단에 들어갈 이름
- body: 페이지 안에 들어갈 내용
- a href: 주소 적을 때 사용
- b: 볼드체, i: 기울임체
- target = "_blink": 링크 클릭 시 새 페이지에서 링크 실행
- .prettify(): 코드를 들여쓰기 형태로 보여줘서 더 편하게 볼 수 있음
1. BeautifulSoup for web data
[찾기]
- soup.head
- soup.body
- soup.p: 가장 처음 발견 된 p 값 찾음
[find]
- soup.find("p", class_="inner-text second-item")
- soup.find("p", {"class": "outer-text first-item"})
- 특정 값을 찾아서 코드를 반환해줌
cf. class 언더바를 쓰는 이유: python class랑 겹치기 때문에 사용함
soup.find("p", {"class": "outer-text first-item"}).text.strip()
- 특정 값의 text 값만 반환해줌
- strip()을 쓰면 불필요한 것들을 날려서 더 편하게 text를 볼 수 있음
다중 조건
soup.find("p", {"class": "inner-text first-item", "id":"first"})
여러 개 찾을 때: find_all()
-
list 형태로 반환
-
list 형태로 반환하기 때문에 find_all에서 특정 태그 찾을 땐 [0]을 붙여 같이 사용해 줘야 함(ex. [0]을 하면 찾은 값 중 첫 번째 값의 text값 반환)
soup.find_all(id= "pw-link")[0].text
-
p 태그 리스트에서 텍스트 속성만 출력
each_tag in soup.find_all("p"):
print("-" * 50)
print(each_tag.text)
그 외 text 보는 method
- print(soup.find_all("p")[0].text)
- print(soup.find_all("p")[1].string)
- print(soup.find_all("p")[1].get_text())
a 태그에서 href 속성값에 있는 값 추출
- links = soup.find_all("a")
- links[0].get("href"), links[1]["href"]
for each in links:
href = each.get("href") #each["href"]
text = each.get_text()
print(text + "=>" + href)
5.8
- 오늘 수강한 분량: 웹데이터 2~3
BeautifulSoup 예제 1-1. 네이버 금융
네이버 금융
- 홈페이지: https://finance.naver.com/marketindex/
- 개발자 도구 들어가는 법: 새로운 Chrome 사용가능 : 클릭 -> 도구 더보기 -> 개발자 도구 클릭
- 또는 화면 오른쪽 마우스 클릭 -> 검사 클릭
- pip install requests
- find, find_all
- select, select_one
- find, select_one: 단일 선택
- select, find_all: 다중 선택
웹페이지 가져오기 전 import 실행
from urllib.request import urlopen
from bs4 import BeautifulSoup
웹페이지 가져오는 방법
주소넣기: url = "https://finance.naver.com/marketindex/"
주소 변수에 넣기: page = urlopen(url) 또는 response = urlopen(url) 사용
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
response 변수 사용했을 때 http 상태코드 알 수 있는 법
response.status

http 상태코드 알 수 있는 법
requests.get(), requests.post()
select 사용
- find_all 사용할 때: soup.find_all("li", "on")
- exchangeList = soup.select("#exchangeList > li")
len(exchangeList)
- class를 찾을 땐 '.' ,id면 # 사용
- soup.select("#exchangeList > li"): id값이 li인 값만 찾음,
- '>' 을 하면 li 바로 밑의 하위값 출력
- len(exchangeList): 찾은 값이 몇 개인지 반환
4개 데이터 수집
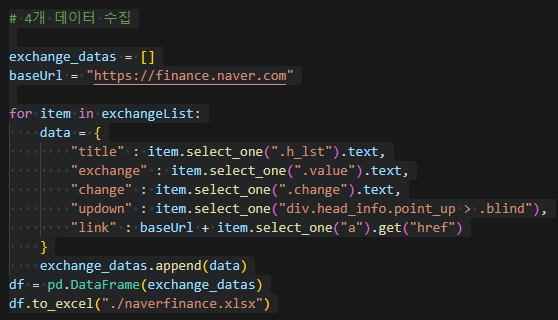
데이터를 엑셀로 저장하는 법
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx")
BeautifulSoup 예제 1-2. 위키백과 문서 정보 가져오기
url 변환하기
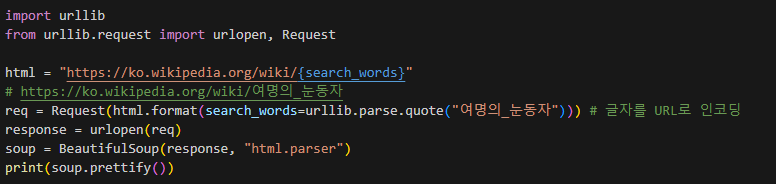
- 처음 링크를 복사했을 때 이상하게 뜨는 건 urldecoder 들어가서 변환 후 복사하기
- 한글 부분은 {search_words}로 넣어주기
- req = Request(html.format(searchwords=urllib.parse.quote("여명의눈동자"))) 를 통해 글자를 url로 인코딩 해주기
- 그 뒤로는 사진 참고하며 따라하면 됨
값이 몇번째 줄인지 찾는 법
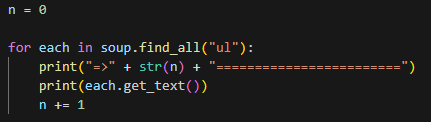
찾은 값 정리

- strip(): 공백을 붙여줌(사용하면 /n 사라짐)
- replace("a", "b"): a를 b로 변환해줌
2. python List 데이터형
-
list형은 대괄호로 생성
colors = ["red", "blue", "green"]
-
append: list 제일 뒤에 추가
-
extend: 제일 뒤에 자료 추가
-
insert: 원하는 위치에 자료를 삽입
-
pop: 리스트 제일 뒤부터 자료를 하나씩 삭제
-
remove: 자료를 삭제
-
isinstance: 자료형 True/False
5.9
- 오늘 수강한 분량: 웹데이터 4~5, 유가분석 1
3. 시카고 맛집 데이터 분석
1) url 가져오기
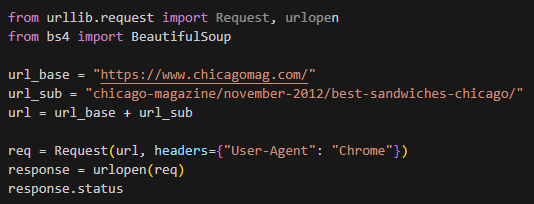
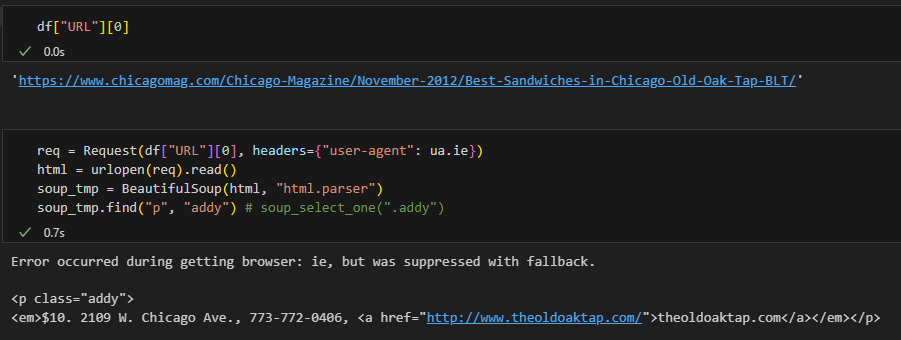
- req = Request(url, headers={"User-Agent": "Chrome"}): 내가 어떤 웹브라우저로 접속하고 있는지 header값을 준 것, 처음에 그냥 url을 가져와보고, 오류가 뜨면 지금 한 것 처럼 header값 주기
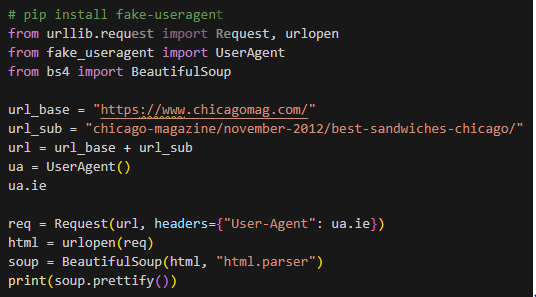
- 또는 fake-useragent를 이용해서 User-Agent에 값을 입력해줄 수도 있음!
2) 데이터 가져오기

- find_all 또는 select를 이용하여 찾기
- 위 사진에서 둘 중 하나만 쓰면 됨!

- 데이터 안의 순위 가져오기(둘 중 하나만 쓰기)

- 데이터 안의 메뉴이름 가져오기

-데이터 안의 링크 가져오기

- 'BLT\nOld Oak Tap\nRead more '
=> ['BLT', 'Old Oak Tap', 'Read more '] 로 바꿔줌
-re.split(("\n|\r\n")): \n 또는 \r\n 기준으로 나눠줘라 라는 뜻
3) for 구문을 사용하여 전체 데이터 추출하기
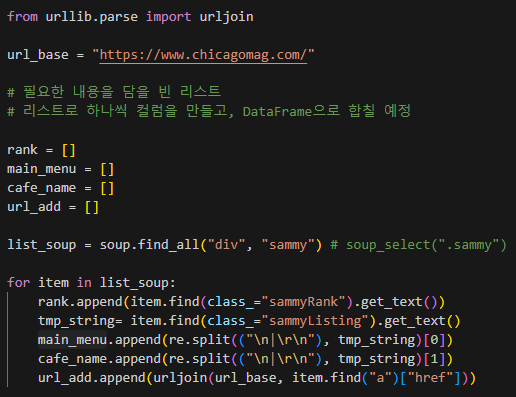
- urljoin: 앞에 www.chicagomag가 url에 없으면 추가, 있으면 추가하지 않는 함수
4) DataFrame 만들기
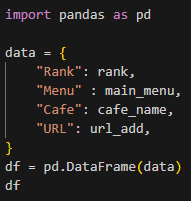
5) 컬럼 순서 변경
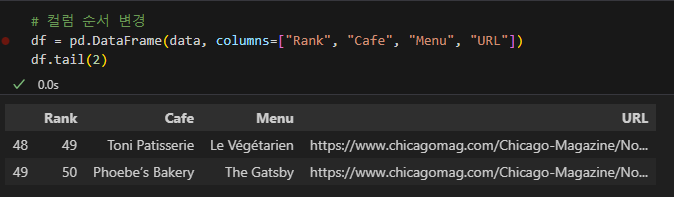
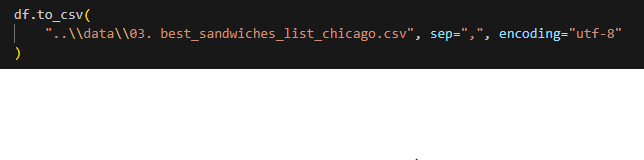
6) 저장
4. 시카고 맛집 데이터 분석 - 하위페이지
1) 기본 모듈 실행 및 데이터 가져오기
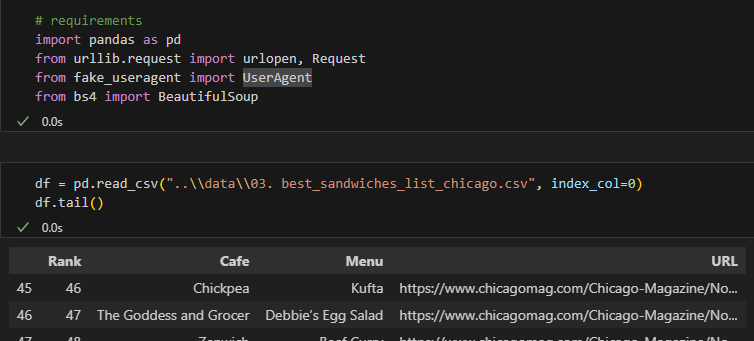
- index_col = 0: 0번째 열을 index로 사용한다는 뜻!
2) 데이터 가져오기
3) 특정 값 변수에 넣고 구분 짓기
4) 특정 값만 가져오기

5) for 구문 사용하여 DF 만들 값 가져오기
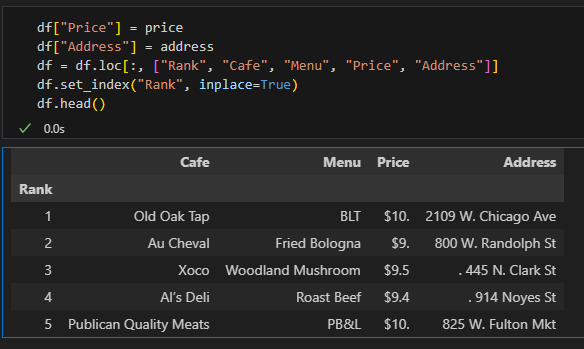
6) DataFrame 만들기
7) 저장하기
df.to_csv(경로, sep=",", encoding="UTF-8")
5. 시카고 맛집 데이터 지도 시각화
1) 모듈 실행 및 파일 불러오기
2) google key 넣기
gmaps_key = "사용자 google key"
gmaps = googlemaps.Client(key=gmaps_key)
3) 시카고 맛집 주소 형식 만들고 위도, 경도 정보 가져오기
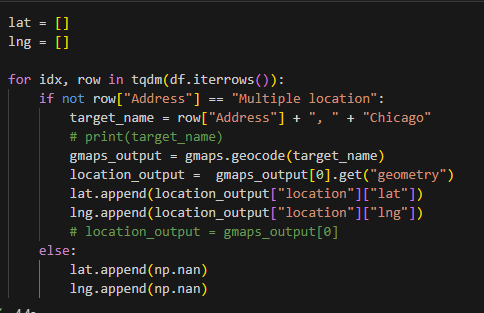
4) df에 위도, 경도 추가
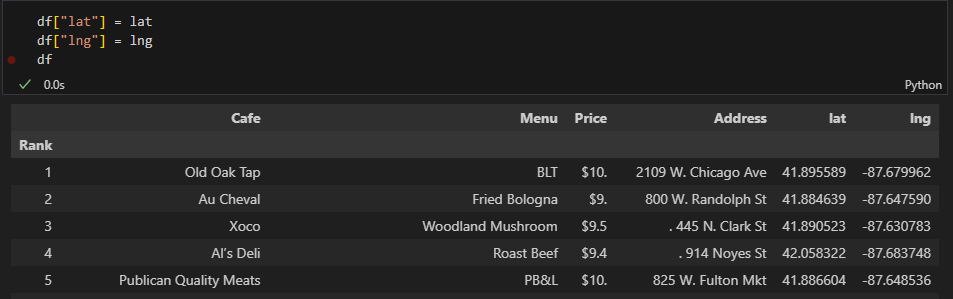
5) 시카고 지도 실행 및 맛집 마커 찍기
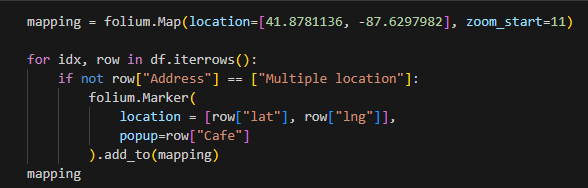
근데 나는 이거로 코드가 실행이 안된다(folium 라이브러리에서 위치 정보로 사용하는 NaN 값이 지원되지 않는다고 chat GPT가 그랬음 ,, )
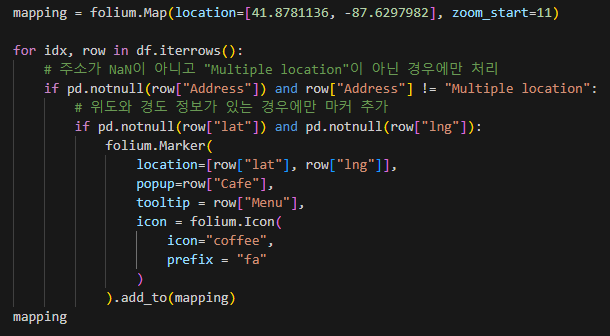
그래서 수정해서 코드를 짰다!(chat GPT 이용^_^)
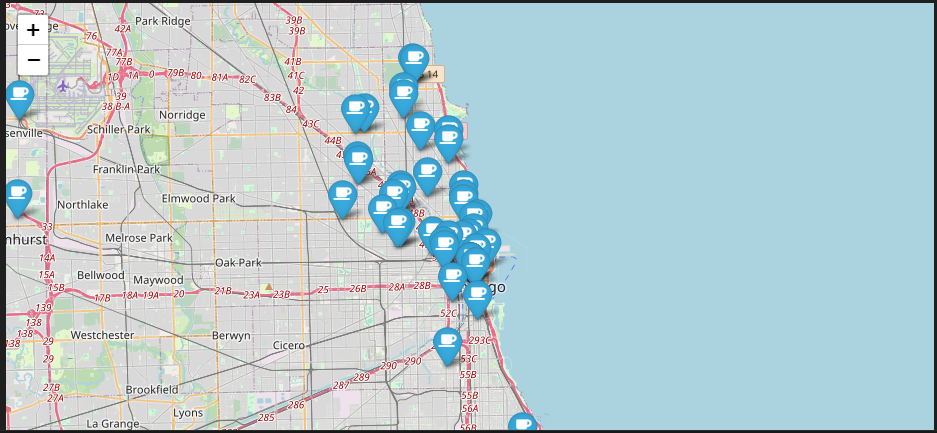
완성~~~!
05. 유가분석
Self Oil Station Price Analysis
유의사항
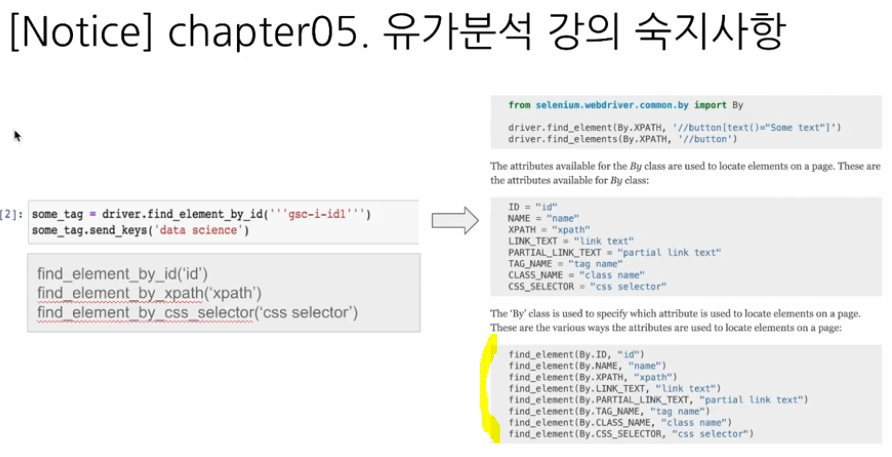
코드가 변경되었으니 실행이 안되면 꼭 저 형태로 만들고 다시 실행해보기!
Chrome Web Driver
Chrome 버전 확인하기
우측 상단 ``` > 도움말 > CHrome 정보 > 버전 확인
Chrome Web Driver 설치하기
최신버전은 여기!
https://github.com/GoogleChromeLabs/chrome-for-testing/blob/main/data/latest-versions-per-milestone-with-downloads.json
밑으로 내려서 운영체제에 맞는 "chromedriver" 써있는 주소를 따옴표 제외해서 복사 후 붙여넣기 하면 자동 다운로드 된다.
0. 셀레니움 설치
- pip install selenium
- chromedriver
반드시 pip 명령어로 설치해야 하고, 만약 conda로 설치했으면 삭제 후 재설치 진행하기!
pip uninstall selenium 으로 삭제 후 재설치
selenium
- 웹 브라우저를 원격 조작하는 도구
- 자동으로 URL을 열고 클릭 등이 가능
- 스크롤, 문자의 입력, 화면 캡처 등
- 링크: https://www.selenium.dev/documentation/
1. selenium webdriver 사용하기
창 열기
실행한 창 코드로 닫기(리소스 낭비하지 않고 안전하게 끌 수 있음)
driver.quit()
화면 최대 크기 설정
driver.maximize_window()
화면 최소 크기 설정
driver.minimize_window()
화면 크기 설정
driver.set_window_size(600, 600)
새로 고침
driver.refresh()
뒤로 가기
driver.back()
앞으로 가기
driver.forward()
클릭

새로운 탭 생성
driver.execute_script("window.open('https://www.naver.com')")
탭 이동(내가 다루고 싶은 탭 번호를 []에 넣어주기)
driver.switch_to.window(driver.window_handles[2])
현재 탭 닫기
driver.close()
전체 탭 닫기
driver.quit()
2. 화면 스크롤
- 스크롤 가능한 높이(길이) 출력해줌
- 자바스크립트 코드 실행
driver.execute_script("return document.body.scrollHeight")
-> 출력하면 5732와 같은 숫자 출력
화면 스크롤 하단 이동
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
현재 보이는 화면 스크린샷 저장
driver.save_screenshot("./last_height.png")
화면 스크롤 상단 이동
driver.execute_script("window.scrollTo(0,0)")
특정 태그 지점까지 스크롤 이동
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR, '#content > div.cover-list > div > ul > li:nth-child(1)')
action = ActionChains(driver)
action.move_to_element(some_tag).perform()
selenium python document
https://selenium-python.readthedocs.io/
5.11
- 오늘 수강한 분량: 유가분석 3~5
3. 검색어 입력
1) CSS_SELECTOR 이용
셀레니움 및 common.by 실행
from selenium import webdriver
from selenium.webdriver.common.by import By
검색 사이트 실행하기
driver = webdriver.Chrome()
driver.get("https://www.naver.com")
검색창에 글씨 입력하기
keyword = driver.find_element(By.CSS_SELECTOR, "#query")
keyword.clear()
keyword.send_keys("파이썬")
검색 버튼 누르기
search_btn = driver.find_element(By.CSS_SELECTOR, "#sform > fieldset > button")
search_btn.click()
2) XPATH 이용
기본 설명
- '//': 최상위
- '*': 자손 태그(일반 태그가 있다면, 그 밑에 하위 태그가 자식 태그, 그 밑의 밑의 태그(자식 태그의 자식태그)를 자손태그라고 함)
- '/': 자식 태그
- 'div[1]': div 중에서 1번째 태그
- XPATH를 이용할 때는 링크를 작은 따옴표로 감싸주기(내부 주소에서 큰 따옴표를 이용하기 때문에 오류가 뜸)
검색창에 글씨 입력하기
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys("xpath")
검색 버튼 누르기
driver.find_element(By.XPATH, '//*[@id="sform"]/fieldset/button').click()
참고 사항
XPATH를 사용할 때는 복사 -> xpath로 복사해서 링크 입력하기
3) ActionChains(동적 페이지 기능)
- 검색 버튼의 주소를 넣고 코드를 실행했을 때 오류가 뜨면, 검색 버튼에 동적 페이지 기능이 들어갔을 수도 있다
- 동적 페이지 기능은 버튼을 눌렀을 때 class명이 바뀌는 것을 말한다
1. 돋보기 버튼을 선택
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
2. 검색어를 입력
keyword = driver.find_element(By.CSS_SELECTOR, "#header > div.search > input[type=text]").send_keys('딥러닝')
3. 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, '#header > div.search > button').click()
4. selenium + beautifulsoup
현재 화면의 html 코드 가져오기
driver.page_source
beautifulsoup에 page_sourse 넣어주기
from bs4 import BeautifulSoup
- req = driver.page_source
- soup = BeautifulSoup(req, 'html.parser')
콘텐츠 가져오기
soup.select('.post-item')
- class가 post-item인 것들을 가져옴
필요한 콘텐츠만 가져오고 싶을 때
contents = soup.select('.post-item')
- 가져온 콘텐츠 리스트들을 리스트 변수로 선언
contents[2]
- 3번째 콘텐츠만 가져와준다
5. Self Oil Station Price Analysis
1. 셀레니움 설치 및 실행
- pip install selenium
- from selenium import webdriver
2. 셀프 주유소가 정말 저렴하나요? - 데이터 확보하기 위한 작업
- https://www.opinet.co.kr/searRgSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
3. 셀레니움으로 접근
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- url = "https://www.opinet.co.kr/searRgSelect.do"
- driver = webdriver.Chrome()
- driver.get(url)
만약 위의 경우로 했는데 메인 화면으로 실행되고 팝업창이 나오는 경우
import time
def main_get():# 페이지 접근 url = "https://www.opinet.co.kr/searRgSelect.do" driver = webdriver.Chrome() driver.get(url) time.sleep(3) # 팝업창으로 전환 driver.switch_to_window(driver.window_handles[-1]) # 팝업창 닫아주기 driver.close() time.sleep(3) # 메인화면 창으로 전환 driver.switch_to_window(driver.window_handles[-1]) # 접근 URL 다시 요청 driver.get(url)main_get()
지역: 시/도 데이터 얻기
시/도 정보가 있는 raw 데이타 얻기
- sido_list_raw = driver.find_element(By.ID, "SIDO_NM0")
- sido_list_raw.text

row 데이타에서 option 태그 이용해 시/도 이름만 얻기
- sido_list = sido_list_raw.find_elements(By.TAG_NAME, "option")
- len(sido_list), sido_list[17].text
실행 결과: (18, '제주')
시/도 이름의 value 값 얻기
sido_list[1].get_attribute("value")
실행 결과: '서울특별시'
위의 한 내용을 바탕으로 모든 시/도 이름의 value 얻기
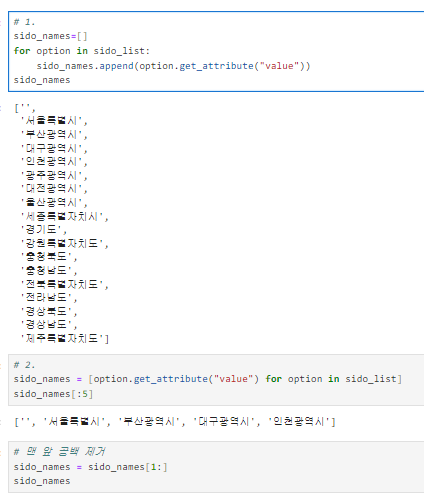
웹페이지에서 지역을 인덱스 번호로 변경하는 코드
sido_list_raw.send_keys(sido_names[0])
구 정보 얻기
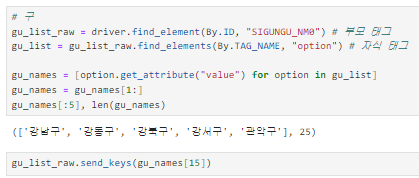
엑셀 저장
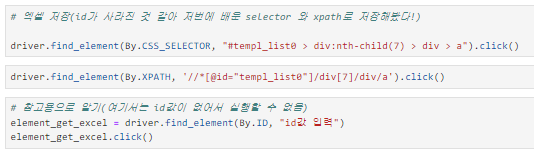
위의 시/도, 구, 엑셀 저장 방법을 이용한 최종적으로 데이터 얻는 법

header 명령어
파일을 불러왔는데 열 이름이 이상하게 뜬다면 header를 사용해 목차가 있는 인덱스 번호를 입력해 준다
사용법: header = 2 이런식으로!
4. 데이터 정리하기
파일 목록 한 번에 가져오기
glob("../data/지역_*.xls")
파일명 저장
- stationsfiles = glob("../data/지역*.xls")
- stations_files[:5]
하나만 읽어보기
- tmp = pd.read_excel(stations_files[0], header = 2)
- tmp.tail(2)
for구문을 사용하여 전체 파일 읽기
- tmp_raw = []
- for file_name in stations_files:
tmp = pd.read_excel(file_name, header = 2)
tmp_raw.append(tmp)
형식이 같은 파일들 합치기(밑에 연달아 추가하는 방식)
- 형식이 동일하고 연달아 붙이기만 하면 될 때는 concat 사용하기
- stations_raw = pd.concat(tmp_raw)
- stations_raw
합친 파일 정보 읽어보기
stations_raw.info()
열 확인하기
stations_raw.columns
데이터 프레임 만들기
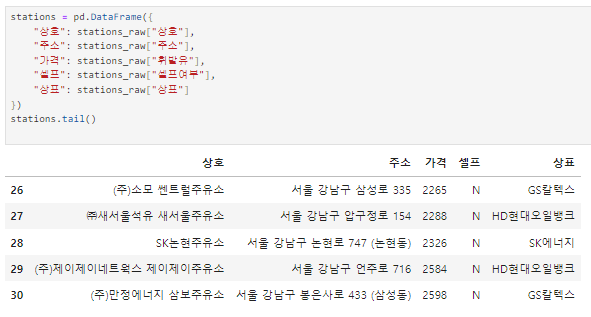
주소의 "구"를 통해 구 열 생성하기
1) 주소를 split을 통해 나누기
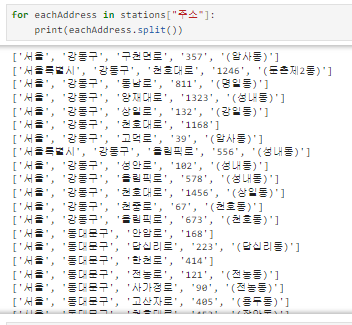
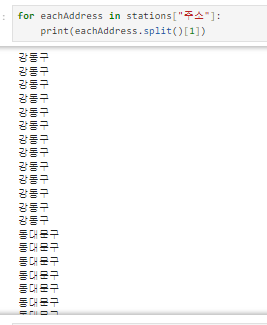
2) 위의 2가지를 활용해서 구 열 만들기
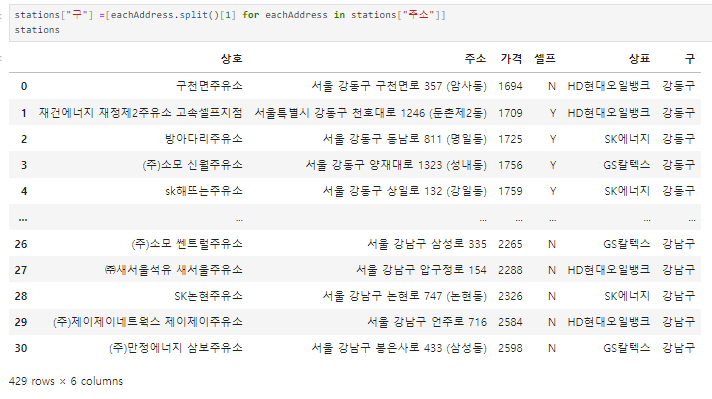
3) 잘 만들어졌는지 unique로 확인하기

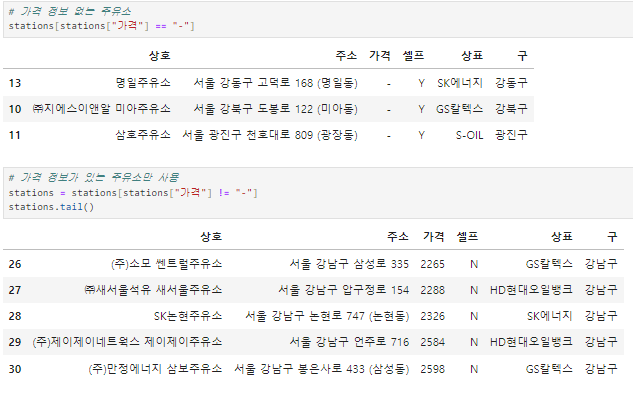
가격 실수형으로 변환하기
1) 가격에 '-' 값 없애기
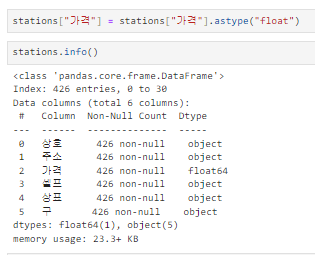
2) 가격 실수형으로 변환 및 확인
인덱스 재정렬
- stations.reset_index(inplace=True)
새로 생긴 index 열 삭제
5. 주유 가격 정보 시각화
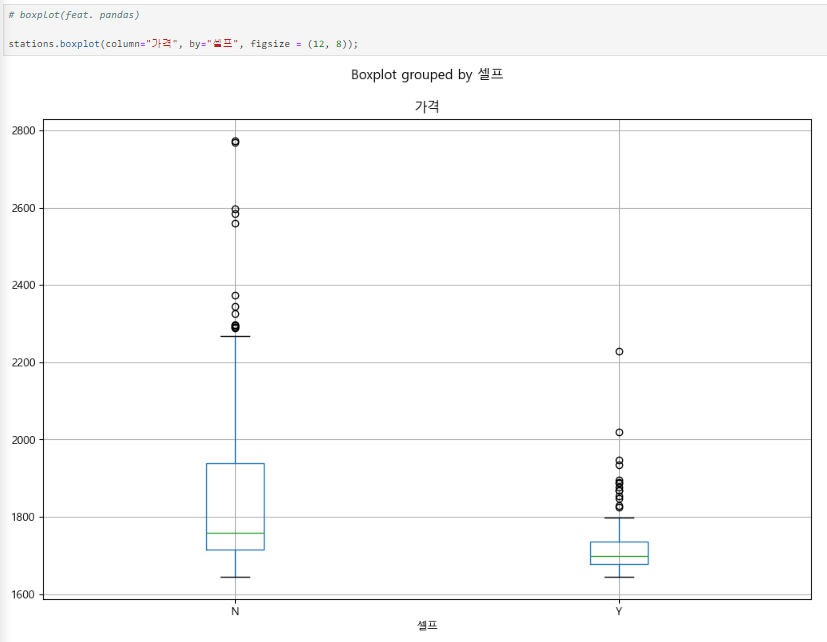
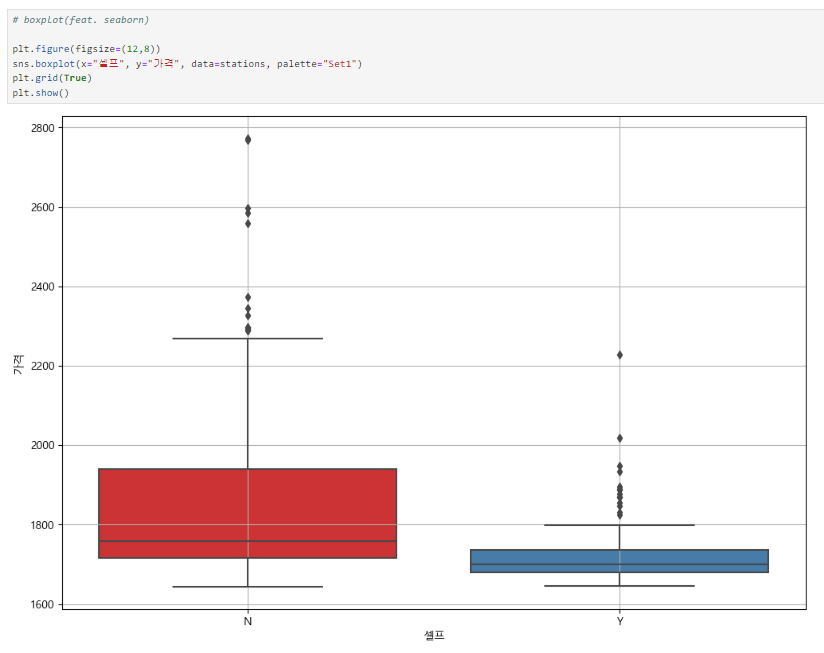
boxplot
모듈 실행
판다스로 boxplot 그리기
seaborn으로 boxplot 그리기
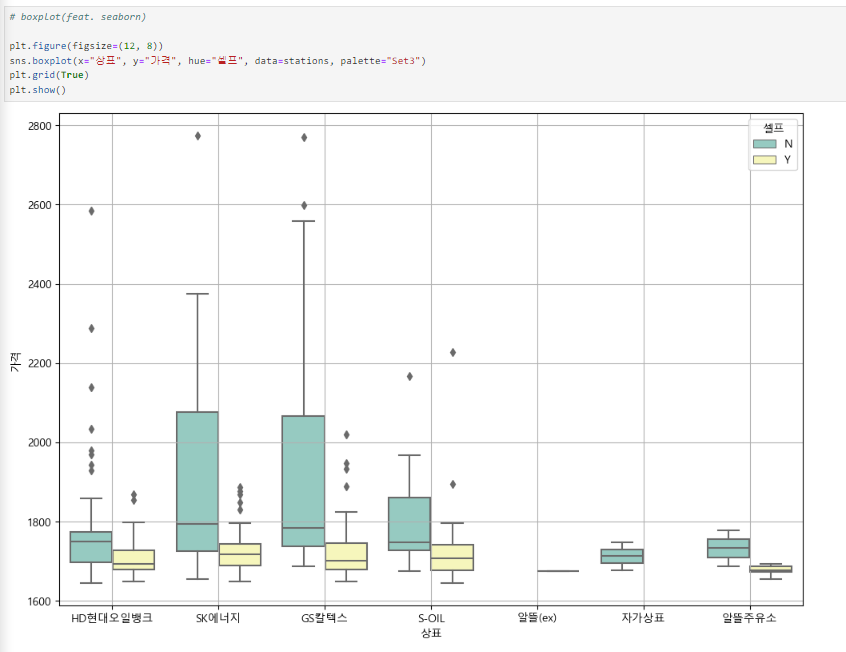
seaborn 이용하여 상표별로 boxplot 그리기
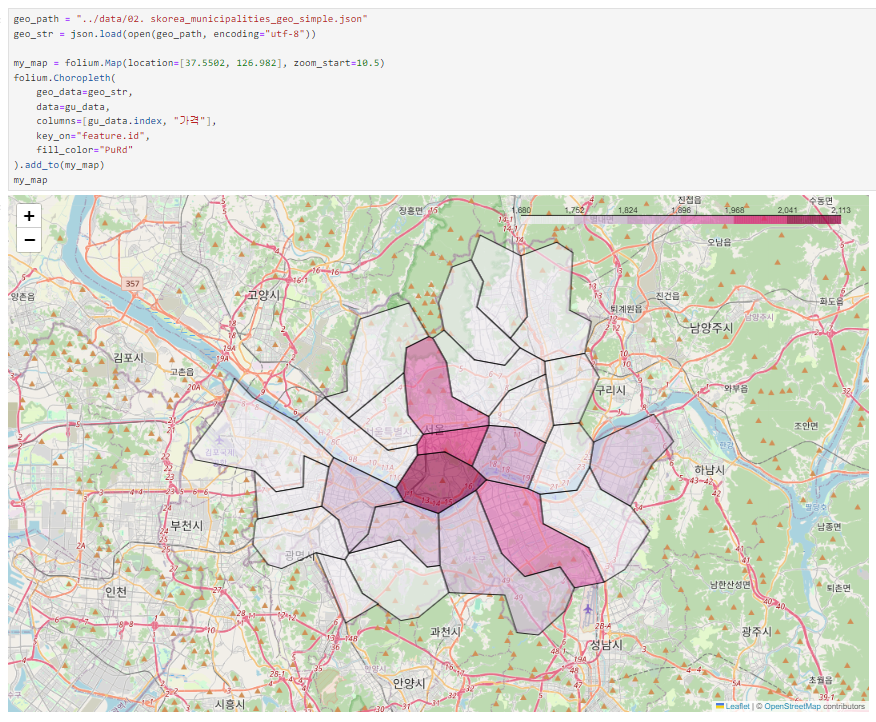
지도 시각화
모듈 실행
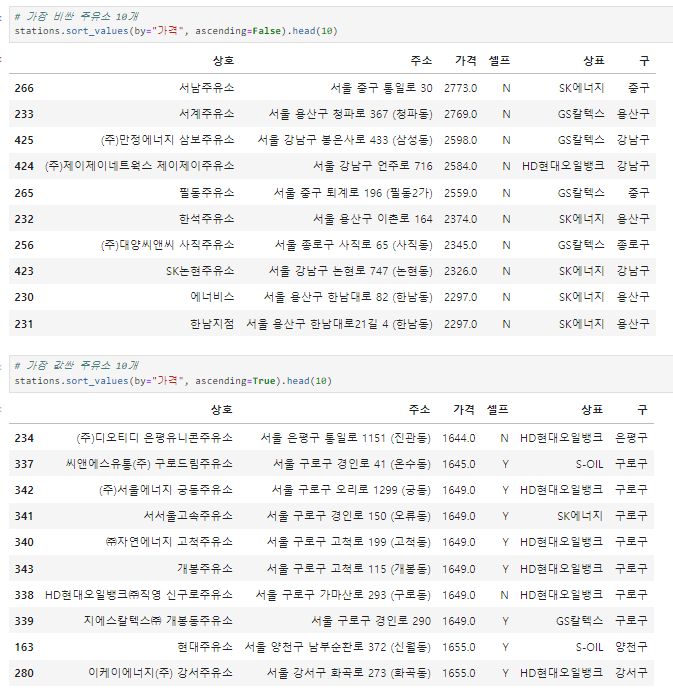
가장 비싼 / 값싼 주유소 10개
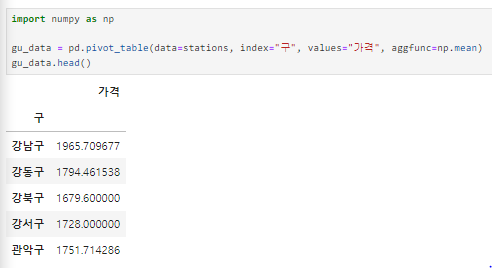
구 별로 가격 평균 내기
지도 시각화
참고
셀레니움 처리 속도를 기다려주는 모듈
- import time
- time.sleep(3)
- 셀레니움 처리 속도가 느리기 때문에, 그냥 코드를 쳐서 실행하면 오류가 뜰 수 있다. 그럴 때 time을 쓰면 오류 안나고 정상 실행 됨
태그가 여러 개일 때
elements 사용해야 함(한개 일 때 element 사용)
