
모든 개념을 하나부터 열까지 세세하게 적진 않았고,
프로그래머스 SQL 문제를 풀면서 알아둬야 할 것 같은 개념만 모아두었다.
1. LIMIT
LIMIT은 SQL에서 결과 행(Row)의 수를 제한할 때 사용하는 구문입니다.
특히 MySQL, PostgreSQL, SQLite등에서 사용되며, 결과가 너무 많을 때 일부만 보고 싶을 때 유용합니다.
LIMIT N→ 최대 n개 행만 가져오기
-- USERS 테이블에서 상위 3개 행만 조회
SELECT * FROM USERS LIMIT 3;
LIMIT+ORDER BY
-- 가장 최근에 가입한 사용자 1명만 조회
SELECT *
FROM USERS
ORDER BY CREATED_AT DESC
LIMIT 1;LIMIT [OFFSET], [개수]
ROW_NUMBER()에서는 사람이 읽기 좋게 시작 번호가 1이지만, OFFSET에서는 0부터 시작한다.
-- 1번 ~ 10번 행 가져오기
SELECT *
FROM USERS
LIMIT 0, 10;-- 11번 ~ 20번 행 가져오기
SELECT *
FROM USERS
LIMIT 10, 10;2. NTILE(n)
NTILE(n)은 정렬된 데이터를 n개의 그룹으로 나눠, 각 행에 1부터 n까지의 그룹 번호를 부여하는 함수다.
OVER (ORDER BY ...)구문을 사용해서 정렬 기준을 명시해야 한다.- 전체 행 수가 균등하게 n개 그룹으로 나뉘도록 시도한다.
- 행 수가 나누어떨어지지 않으면, 앞쪽 그룹부터 한 개씩 더 많은 행을 가진다.
[예시1] 예시 테이블: students
| id | name | score |
|---|---|---|
| 1 | 철수 | 98 |
| 2 | 영희 | 85 |
| 3 | 민수 | 77 |
| 4 | 지수 | 74 |
| 5 | 준호 | 68 |
| 6 | 현우 | 60 |
| 7 | 세영 | 52 |
| 8 | 나리 | 49 |
SELECT
id,
name,
score,
NTILE(4) OVER (ORDER BY score DESC) AS score_group
FROM students;이건 그냥 나 혼자 외우는 방식인데...
N개의 타일(TILE) 그룹으로 나눈다고 생각했다! ㅎㅎ
✔️ 결과 테이블
| id | name | score | score_group |
|---|---|---|---|
| 1 | 철수 | 98 | 1 |
| 2 | 영희 | 85 | 1 |
| 3 | 민수 | 77 | 2 |
| 4 | 지수 | 74 | 2 |
| 5 | 준호 | 68 | 3 |
| 6 | 현우 | 60 | 3 |
| 7 | 세영 | 52 | 4 |
| 8 | 나리 | 49 | 4 |
NTILE(4)는 데이터를 4등분해 그룹 번호(1~4)를 부여한다.ORDER BY score DESC→ 점수가 높은 사람부터group 1에 배정된다.- 총 8명 → 그룹당 정확히 2명씩 배정된다.
[예시2] 예시 테이블: students
| id | name | score |
|---|---|---|
| 1 | 철수 | 98 |
| 2 | 영희 | 91 |
| 3 | 민수 | 85 |
| 4 | 지수 | 76 |
| 5 | 준호 | 70 |
| 6 | 현우 | 65 |
| 7 | 나리 | 60 |
SELECT
id,
name,
score,
NTILE(4) OVER (ORDER BY score DESC) AS score_group
FROM students;✔️ 결과 테이블
| id | name | score | score_group |
|---|---|---|---|
| 1 | 철수 | 98 | 1 |
| 2 | 영희 | 91 | 1 |
| 3 | 민수 | 85 | 2 |
| 4 | 지수 | 76 | 2 |
| 5 | 준호 | 70 | 3 |
| 6 | 현우 | 65 | 3 |
| 7 | 나리 | 60 | 4 |
- 총 7명, 4그룹으로 나누려고 하면:
- 7 ÷ 4 = 1.75 → 한 그룹당 기본적으로 1명씩 + 앞에서부터 3개의 그룹은 한 명 더 받음
- 그래서 앞에서부터 차례로 2, 2, 2, 1명씩 배정됨
3. PERCENT_RANK()
PERCENT_RANK()는 정렬된 데이터의 상대적인 순위를 0.0부터 1.0사이의 비율로 표현하는 윈도우 함수다.
즉, 이 값이 이 행이 전체 데이터 중 상위 몇 퍼센트인지를 알려준다.
✔️ 공식
PERCENT_RANK = (순위 - 1) / (전체 행 수 - 1)- 가장 높은 값 → 0.0 (첫 번째 순위)
- 가장 낮은 값 → 1.0 (마지막 순위)
✔️ 기본 문법
PERCENT_RANK() OVER (ORDER BY 컬럼명 ASC|DESC)[예시1] 예시 테이블: students
| id | name | score |
|---|---|---|
| 1 | 철수 | 90 |
| 2 | 영희 | 85 |
| 3 | 민수 | 75 |
| 4 | 지수 | 70 |
| 5 | 나리 | 60 |
SELECT
id,
name,
score,
PERCENT_RANK() OVER (ORDER BY score DESC) AS percent_rank
FROM students;이때, 공식에 의해서
- 총 행 수: 5
- 공식:
(순위 - 1) / (총 행 수 - 1)→(순위 - 1) / 4
참고로, PERCENT_RANK()의 실제 값은 고정 자릿수가 아니며, 출력 자릿수는 환경에 따라 다르다.
| 이름 | 순위 | 계산식 | 결과 |
|---|---|---|---|
| 철수 | 1 | (1 - 1) / 4 | 0.000 |
| 영희 | 2 | (2 - 1) / 4 | 0.250 |
| 민수 | 3 | (3 - 1) / 4 | 0.500 |
| 지수 | 4 | (4 - 1) / 4 | 0.750 |
| 나리 | 5 | (5 - 1) / 4 | 1.000 |
✔️ 결과 테이블
| id | name | score | percent_rank |
|---|---|---|---|
| 1 | 철수 | 90 | 0.000 |
| 2 | 영희 | 85 | 0.250 |
| 3 | 민수 | 75 | 0.500 |
| 4 | 지수 | 70 | 0.750 |
| 5 | 나리 | 60 | 1.000 |
4. DATE/DATETIME에 MAX(), MIN() 적용
MySQL에서는 DATE, DATETIME 모두 내부적으로 시간순 정렬이 가능하게 설계되어 있어서 MAX(date_column)처럼 사용하면 가장 나중의 날짜, MIN()은 가장 이른 날짜를 반환한다.
MAX()나 MIN()함수는 숫자뿐 아니라 날짜(datetime)에도 사용할 수 있다.
실제로 날짜는 내부적으로 숫자(타임스탬프)로 저장되기 때문에 비교가 가능하다.
✔️ 어떻게 비교할까?
DATETIME은 YYYY-MM-DD HH:MM:SS 형식인데,
이 형식은 문자열로 봐도, 앞에서부터 순차적으로 비교하면 크고 작음을 판단할 수 있게 설계되어 있다.
2013-11-18>2013-10-23→ 연도, 월, 일이 앞에서부터 비교됨
그래서 MAX, MIN이 자연스럽게 동작한다.
| 함수 | 의미 | 설명 |
|---|---|---|
MAX(DATETIME) | 가장 늦은 시각 | 가장 최근 날짜와 시간 |
MIN(DATETIME) | 가장 이른 시각 | 가장 오래된 날짜와 시간 |
5. CONCAT()
CONCAT()함수는,
두 개 이상의 문자열을 하나로 연결할 때 사용하는 SQL 함수다.
✔️ 기본 문법
CONCAT(string1, string2, ..., stringN)- 각 문자열을 순서대로 이어 붙인 결과를 반환된다.
- 숫자도 문자열처럼 자동으로 변환되어 연결된다.
SELECT CONCAT(NAME, '(', ANIMAL_TYPE, ')') AS 동물정보
FROM ANIMAL_INS
LIMIT 1;
-- 예: 'Jack(Dog)'⚠️ 주의
NULL이 포함되면 결과도 NULL이다.
SELECT CONCAT('Hello', NULL, 'World'); → 결과: NULL6. COUNT(*) VS COUNT(컬럼)
| 함수 | NULL 포함 여부 | 설명 |
|---|---|---|
COUNT(*) | ✅ 포함 | 전체 행 개수 (NULL 상관없이 모두 셈) |
COUNT(EMAIL) | ❌ 제외 | EMAIL 값이 NULL이 아닌 행만 셈 |
7. DISTINCT
DISTINCT는 함수가 아니라 키워드다.
중복이 제거된 값을 조회하기 위해 사용된다.
SELECT COUNT(DISTINCT NAME) AS count
FROM ANIMAL_INS;DISTINCT NAME은 SQL에서 중복을 제거한 NAME 값만 선택하라는 뜻이다.
SELECT DISTINCT A, B
FROM 테이블명;이 구문은 A "하나만" 보고 중복 제거하는 게 아니라, A와 B 두 컬럼을 묶은 "한 쌍"이 완전히 같을 때만 중복으로 판단해서 제거한다.
✔️ 참고
사실 DISTINCT NAME를 키워드가 아니라 DISTINCT(NAME)이렇게 함수처럼 적어도 정답으로 인정된다.
이렇게 함수처럼 쓰는 건, MySQL 등 일부 DBMS에서 허용은 되지만 비표준이다. 따라서 PostgreSQL, Oracle 등에서는 문법 오류가 날 수도 있다.
DISTINCT는 함수가 아니라 키워드이기 때문에, 괄호 없이 표준 형태로 사용하는 것이 가장 안전하고 권장되는 방법이다.
8. CAST
CAST는 값의 자료형(Data Type)을 다른 형으로 바꿔주는 형변환 함수다.
| 원래 값 예시 | 사용 예시 | 변환 후 결과 예시 | 설명 |
|---|---|---|---|
'2020' | CAST('2020' AS UNSIGNED) | 2020 (숫자) | 문자열 → 정수 (연도 정렬 등에 사용) |
123 | CAST(123 AS CHAR) | '123' (문자열) | 숫자 → 문자열 (CONCAT 등에 사용) |
'3.14159' | CAST('3.14159' AS DECIMAL(5,2)) | 3.14 (소수) | 문자열 → 소수 (소수점 제한) |
'2024-01-01' | CAST('2024-01-01' AS DATE) | 2024-01-01 (날짜형) | 문자열 → 날짜 |
'123ABC' | CAST('123ABC' AS UNSIGNED) | 123 | 문자+숫자 → 숫자 (숫자 앞부분만 사용) |
'2024-05-05 10:00:00' | CAST('2024-05-05 10:00:00' AS DATE) | 2024-05-05 (날짜만) | 문자열 날짜+시간 → 날짜 |
| '123.456' | CAST('123.456' AS DECIMAL) | 123.456 | 문자열 → 소수 (DECIMAL 기본 사용) |
| 789.01 | CAST(789.01 AS DECIMAL) | 789.01 | 실수 → 고정소수 (FLOAT보다 정확) |
| '42' | CAST('42' AS DECIMAL) | 42 | 문자열 → 정수 (DECIMAL도 가능) |
| '3.14159265' | CAST('3.14159265' AS DECIMAL) | 3.14159265 | 긴 소수도 보존 (자릿수 제한 없음) |
✔️ DECIMAL(5, 2)의 의미
DECIMAL(5,2)은 숫자를 정밀하게 저장하기 위한 데이터 타입으로, 총 5자리 중 소수점 아래 2자리까지 저장할 수 있도록 정의한 자료형이다. 주로 금액, 정밀 측정값, 평균 점수 등 정확도가 중요한 수치에 사용된다.
| 입력값 | 저장 가능 여부 | 설명 |
|---|---|---|
| 123.45 | ✅ 가능 | 정수부 3자리 + 소수부 2자리 |
| 0.99 | ✅ 가능 | 정수부 1자리 + 소수부 2자리 |
| 999.99 | ✅ 가능 | 최대 표현 가능 값 |
| 12.3 | ✅ 가능 | 정수부 2자리 + 소수부 1자리 |
| 1.00 | ✅ 가능 | 정수부 1자리 + 소수부 2자리 |
| 1234.56 | ❌ 불가능 | 정수부가 4자리로 초과됨 |
| 1000.00 | ❌ 불가능 | 정수부가 4자리로 초과됨 |
| 12.345 | ❌ 불가능 | 소수부가 3자리로 초과됨 |
| 0.123 | ❌ 불가능 | 소수부가 3자리로 초과됨 |
| 표현 | 의미 | 결과 |
|---|---|---|
CAST('3.14159' AS DECIMAL(5,2)) | 소수 둘째 자리까지 반올림 | 3.14 |
CAST('123.456' AS DECIMAL(5,2)) | 정수 3자리 + 소수 2자리 | 123.46 |
CAST('12345.678' AS DECIMAL(5,2)) | 정수 부분이 5자리라 불가능 (오류) | ❌ |
9. PARTITION BY
PARTITION BY는 데이터를 그룹별로 나눠서 각 그룹 내에서 집계함수(AVG, MAX, COUNT 등)를 행마다 계산해주는 기능이다.
✔️ 구조
SELECT
컬럼1, 컬럼2, ...
집계함수(...) OVER (PARTITION BY 그룹컬럼) AS 새컬럼명
FROM 테이블명;✔️ 예시
| 이름 | 도시 | 점수 |
|---|---|---|
| 철수 | 서울 | 80 |
| 영희 | 서울 | 90 |
| 민수 | 부산 | 70 |
| 수지 | 부산 | 85 |
👩💻 각 사람 옆에 자신이 속한 도시에서의 최고 점수를 붙이고 싶다고 하자!
SELECT
이름,
도시,
점수,
MAX(점수) OVER (PARTITION BY 도시) AS 도시별_최고점수
FROM 학생;위의 코드를 실행시키면 다음의 결과 테이블이 나온다.
| 이름 | 도시 | 점수 | 도시별_최고점수 |
|---|---|---|---|
| 철수 | 서울 | 80 | 90 |
| 영희 | 서울 | 90 | 90 |
| 민수 | 부산 | 70 | 85 |
| 수지 | 부산 | 85 | 85 |
✔️ GROUP BY 와의 차이
GROUP BY는 그룹별로 한 줄만 출력하지만,
PARTITION BY는 그룹별 집계 결과를 각 행마다 보여준다!
만약에 GROUP BY를 사용한다면, 다음과 같이 나온다.
SELECT 도시, MAX(점수) AS 최고점수
FROM 학생
GROUP BY 도시;| 도시 | 최고점수 |
|---|---|
| 서울 | 90 |
| 부산 | 85 |
✔️ [참고] Window Function 이란?
윈도우 함수(Window Function)는 행(row)을 유지한 채로,
그 행과 관련된 여러 행들의 계산 결과(누적합, 순위, 최대값 등)를 같이 보여주는 함수다.
쉽게 말하자면, GROUP BY와 같은 건, 그룹을 묶고 한 줄만 보여준다면, 윈도우 함수는 행을 유지하면서, 관련된 그룹 값도 함께 붙여준다.
해당 문제에서는 PARTITION BY 이런게 윈도우 함수다.
10. REGEXP (정규표현식)
✔️ 형태
컬럼명 REGEXP '정규표현식'| 패턴 | 의미 설명 | 예시 패턴 → 매칭 결과 (✅: 옳은 예시 ❌: 틀린 예시) |
|---|---|---|
. | 아무 문자 1개 | a.b → acb ✅, a_b ✅, ab ❌ |
^ | 문자열 시작 | ^Hi → Hi there ✅, Say Hi ❌ |
$ | 문자열 끝 | end$ → The end ✅, ending ❌ |
* | 앞 문자가 0번 이상 반복 | ab*c → ac ✅, abc ✅, abbc ✅, abbbc ✅ |
+ | 앞 문자가 1번 이상 반복 | ab+c → abc ✅, abbc ✅, ac ❌ |
? | 앞 문자가 0번 또는 1번 | colou?r → color ✅, colour ✅, colouur ❌ |
{n} | 정확히 n번 반복 | a{3} → aaa ✅, aa ❌, aaaa ❌ |
{n,} | 최소 n번 이상 반복 | a{2,} → aa ✅, aaa ✅, a ❌ |
{n,m} | n ~ m번 반복 | a{2,4} → aa ✅, aaa ✅, aaaa ✅, aaaaa ❌ |
[abc] | a, b, c 중 하나 | [abc] → a ✅, b ✅, d ❌ |
[^abc] | a, b, c를 제외한 문자 | [^abc] → d ✅, e ✅, a ❌, b ❌ |
[a-z] | 소문자 하나 | [a-z] → a ✅, m ✅, Z ❌, 3 ❌ |
[A-Z] | 대문자 하나 | [A-Z] → A ✅, Z ✅, a ❌ |
[0-9] | 숫자 하나 | [0-9] → 1 ✅, 5 ✅, a ❌ |
| | | OR 연산자 | cat | dog → cat ✅, dog ✅, catt ✅, doghouse ✅, rat ❌, cow ❌ |
✔️ 예제1
문자열 내부에 '통풍 시트', '열선 시트', '가죽 시트' 중 하나라도 포함되어 있으면 매칭된다.
SELECT CAR_TYPE, COUNT(CAR_ID) AS CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS REGEXP '통풍 시트|열선 시트|가죽 시트'
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE ASC;-- ❌ 이렇게 쓰면 오류 나거나 잘못된 결과
WHERE OPTIONS REGEXP "'통풍 시트'|'열선 시트'|'가죽 시트'"정규표현식 안의 각 문자열 단어를 ''로 감싸야 하는 것 아닌가 궁금증이 들 수 있다.
그치만, REGEXP에서 문자열을 패턴안에 쓸 때, 내부 문자열들은 따옴표 없이 써도 된다.
'통풍 시트|열선 시트|가죽 시트' 전체가 하나의 정규표현식 문자열로 인식된다.
✔️ 예제2
SELECT *
FROM products
WHERE name REGEXP 'colou?r';11. 별칭(alias)이나 속성명은 홑따옴표(' ')를 쓰지 않는다.
-- 띄어쓰기 없을 땐 그냥 사용 가능
SELECT MCDP_CD AS 진료과코드
-- 띄어쓰기 포함된 별칭은 큰따옴표 또는 백틱(`) 사용
SELECT MCDP_CD AS "진료과 코드"
-- 또는
SELECT MCDP_CD AS `진료과 코드`⚠️ 홑따옴표 '진료과 코드'는 절대 쓰면 안 된다.
→ 이건 문자열 리터럴(상수)로 인식된다.
12. GROUP BY
⚠️ 주의
GROUP BY는 NULL도 하나의 그룹으로 보기 때문에, NULL도 그룹으로 카운팅된다.
13. 몫, 나머지 연산
진짜 나눗셈을 하려고 하면 다음과 같이 작성하면 된다.
SELECT 10 / 4; -- 결과: 2 (정수 나눗셈, 몫만 나옴 ❌)
SELECT 10 / 4.0; -- 결과: 2.5 ✅
SELECT 10 / CAST(4 AS DECIMAL); -- 결과: 2.5 ✅
SELECT 10 / 4.00; -- 결과: 2.5 ✅그러나, 어떤 경우에는 몫 또는 나머지만 구하고 싶을때도 있다.
어떻게 해야할까?
| 연산자/함수 | 용도 | 예시 | 결과 | 설명 |
|---|---|---|---|---|
DIV | 몫 구하기 | 10 DIV 3 | 3 | 정수 나눗셈의 몫 (floor) |
% | 나머지 구하기 | 10 % 3 | 1 | 나머지를 반환 |
MOD(a, b) | 나머지 구하기 | MOD(10, 3) | 1 | 나머지를 반환 (함수 방식) |
MOD(-10, 3) | 나머지 구하기 | MOD(-10, 3) | 2 | 부호에 따라 결과 다를 수 있음 |
MOD(10, -3) | 나머지 구하기 | MOD(10, -3) | -2 | 나눌 수(b)의 부호 유지 |
MOD(-10, -3) | 나머지 구하기 | MOD(-10, -3) | -1 | 부호 규칙 유지 |
✔️ FLOOR()
FLOOR()는 소수점 아래로 내림이기 때문에
-3.3 → -4로 처리된다.
✔️ 음수 계산 처리
MOD(a, b) = a - b * FLOOR(a / b)14. TRUNCATE(숫자, 버릴 자릿수)
TRUNCATE()함수는 숫자의 일정 자리 이하를 잘라내는 함수다.
반올림 없이 그냥 자른다. 그래서 '절삭'함수라고도 불린다.
반환값은 정수 또는 소수다.
| 함수 | 설명 | 예시 | 결과 |
|---|---|---|---|
TRUNCATE(number, 0) | 소수점 없앰 | TRUNCATE(123.456, 0) | 123 |
TRUNCATE(number, 2) | 소수점 둘째자리까지 남김 | TRUNCATE(123.456, 2) | 123.45 |
TRUNCATE(number, -2) | 10 단위 버림 | TRUNCATE(1234, -2) | 1200 |
TRUNCATE(number, -4) | 10000 단위 버림 | TRUNCATE(123456, -4) | 120000 |
15. ROUND()
어떤 DB를 사용하는지에 따라 약간씩 다를 수 있지만, MySQL, PostgreSQL, Oracle등 모두 ROUND()는 지원한다.
기본 문법
ROUND(숫자_또는_칼럼명, 1)예제
SELECT ROUND(3.46, 1); -- 결과: 3.5
SELECT ROUND(3.44, 1); -- 결과: 3.4ROUND는 어디에 위치할까?
보통은 SELECT절에서 사용되며, 가끔은 ORDER BY절에서도 쓴다.
-- SELECT 절
SELECT ROUND(DAILY_FEE, 1) FROM CAR_RENTAL_COMPANY_CAR;
-- ORDER BY 절
SELECT *
FROM CAR_RENTAL_COMPANY_CAR
ORDER BY ROUND(DAILY_FEE, 1) DESC;필요하다면 WHERE, GROUP BY, HAVING절에서도 쓸 수 있습니다.
예를 들어, 반올림한 결과가 특정 값일 때만 조회하고 싶을 때:
SELECT *
FROM PRODUCTS
WHERE ROUND(PRICE, 1) = 123456.8;표로 정리하면 다음과 같다.
| 형식 | 설명 | 예시 | 결과 |
|---|---|---|---|
ROUND(숫자) | 소수점 이하를 반올림하여 정수 반환 | ROUND(123.56) | 124 |
ROUND(숫자, n) | 소수점 아래 n번째 자리까지 반올림 | ROUND(123.4567, 2) | 123.46 |
ROUND(숫자, -n) | 정수부의 n자리까지 반올림 | ROUND(186.4, -2) | 200 |
마지막 예시에 대해 부연설명을 하자면...
ROUND(186.4, -2)는 정수부의 2자리까지 반올림하라는 뜻이다.
-1: 10의 자리-2: 100의 자리
이런식이다..
따라서 정수부의 100의 자리까지 반올림하라는 뜻이다.
즉, 100단위에서 반올림을 한다.
따라서 답이 200이 된다.
ROUND(149.9, -2) = 100 (왜냐면 149는 100에 더 가까움)
ROUND(150.0, -2) = 200 (바로 중간 → 5이상이므로 올림)
ROUND(150.1, -2) = 200 (200에 더 가까움)16. 날짜 비교
✔️ 2022년 8월부터 2022년 10월까지
이걸 어떻게 비교할까?
[방법1]
WHERE START_DATE BETWEEN '2022-08-01' AND '2022-10-31'[방법2]
WHERE START_DATE >= '2022-08-01' AND START_DATE <= '2022-10-31'✔️ START_DATE는 DATE 타입인데, '2022-08-01' 같은 문자열이랑 비교해도 되나?
응 가능해!
SQL에서는 문자열 2022-08-01을 내부적으로 자동으로 DATE로 바꿔서 비교한다.
이걸 암시적 형 변환(implicit type conversion) 이라고 부른다.
마치 CAST를 하는 것과 같은 효과다.
START_DATE = CAST('2022-08-01' AS DATE)[CASE1]
DATE타입과 "YYYY-MM-DD"문자열을 비교
알아서 "YYYY-MM-DD"를 DATE타입으로 바꿔준다.
[CASE2]
DATE타입과 "YYYY-MM-DD HH:MM:SS"문자열을 비교
문자열이 DATE로 암시적 형 변환되며, 시간 정보는 잘려서 무시된다.
-- 문자열이 DATE로 변환되며, 시간은 잘림
WHERE START_DATE = CAST('2022-08-01 23:44:44' AS DATE)
-- 결과적으로는 비교는 아래처럼 된다.
WHERE START_DATE = '2022-08-01'[CASE3]
DATETIME타입과 "YYYY-MM-DD"문자열을 비교
-- 컬럼이 DATETIME일 때
WHERE RENTED_AT = '2022-08-01'이 경우 '2022-08-01'은 내부적으로 → '2022-08-01 00:00:00' 으로 변환됨
즉, 오직 자정(00:00:00)에 시작한 데이터만 매칭된다.
DATETIME과 비교할 땐 BETWEEN으로 범위를 지정하는 게 안전하다.
17. 다중 컬럼 비교
✔️ (A, B) IN (SELECT X, Y FROM ...)형태
SQL에서 이런 형태를 다중 컬럼 비교라고 부른다.
WHERE (FOOD_TYPE, LOCATION, FAVORITES) IN (
SELECT FOOD_TYPE, LOCATION, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE, LOCATION
)이런식의 형태다.
컬럼명이 같을 필요는 없지만, 컬럼의 개수와 순서는 같아야한다.
18. SUM() / AVG() / COUNT() / MAX() / MIN()
col: 컬럼명
| 함수 | NULL 포함 시 동작 |
|---|---|
SUM(col) | NULL 제외하고 합산 |
AVG(col) | NULL 제외하고 합산 및 개수 계산 |
COUNT(col) | NULL 제외하고 개수 셈 |
COUNT(*) | NULL 포함 모든 행을 셈 |
MAX(col), MIN(col) | NULL 제외하고 최댓값/최솟값 비교 |
참고로, 오직 COUNT() 만, *를 사용할 수 있다.
*는 모든 컬럼을 의미하지만, SUM()이나 AVG()는 하나의 수치형 컬럼만 받을 수 있기 때문에 *를 사용할 수 없다.
19. %
%는 "0개 이상의 모든 문자"를 의미하기 때문에, 아무 문자도 앞뒤로 붙지 않아도 된다.
| 패턴 | 설명 | 매칭 예시 |
|---|---|---|
'네비게이션%' | "네비게이션"으로 시작 | '네비게이션''네비게이션 포함 옵션''네비게이션 장착 차량' |
'%네비게이션' | "네비게이션"으로 끝남 | '옵션: 네비게이션''장착된 네비게이션' |
'%네비게이션%' | "네비게이션"을 포함 | '옵션: 네비게이션 포함''차량용 네비게이션 포함''네비게이션' |
20. DATEDIFF()
SQL에서 두 날짜 간의 차이(일 수)를 구할 때 사용하는 아주 유용한 함수이다.
해당 함수는 두 날짜 간의 일(day) 단위 차이를 정수로 반환한다.
DATEDIFF(날짜1, 날짜2)- 결과 =
날짜1 - 날짜2(단위: 일) - 반환값은
정수- 양수 → 날짜1이 더 미래
- 음수 → 날짜1이 더 과거
- 0 → 두 날짜가 동일
SELECT DATEDIFF('2022-01-10', '2022-01-01'); -- 결과: 9
SELECT DATEDIFF('2022-01-01', '2022-01-10'); -- 결과: -9
SELECT DATEDIFF('2022-01-01', '2022-01-01'); -- 결과: 0⚠️ [주의] 상황에 따라 날짜 계산 주의
상황 1: 단순 날짜 차이 (기간 차이)
SELECT DATEDIFF('2022-01-10', '2022-01-01'); -- 결과: 91일~10일→9일차이 (10 - 1)- 즉, "간격"만 계산함
상황 2: 포함일수 계산 (ex. 대여일수, 숙박일수)
예시: 책을 1월 1일에 빌려서 1월 10일에 반납함
- 1일부터 10일까지 실제 며칠 간 보관했나?
1일, 2일, ..., 10일→10일 - DATEDIFF('2022-01-10', '2022-01-01') = 9
- 따라서 여기에 +1 필요
21. IF()
CASE 구문 대신 MySQL에서는 IF()함수를 써서 동일한 조건 분기를 더 간단하게 표현할 수 있다.
IF(조건식, 참일 때 값, 거짓일 때 값)22. 문자열은 작은따옴표를 사용하자.
작은 차이지만 더 안전한 코드 (문법적으로)
MySQL에서 문자열은 큰따옴표(") 대신 작은따옴표(')를 사용하는 것이 표준이라고 한다.
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE LOWER(NAME) LIKE '%el%'
AND ANIMAL_TYPE = 'Dog'
ORDER BY NAME;아까 위에서 별칭이나 속성명은 작은따옴표를 쓰면 안되고 ""나 ``를 써야한다고 했었지?
SQL 문법에서는 문자열과 식별자(컬럼명, 별칭, 테이블명 등...)를 구분한다.
문자열은 작은따옴표로!
식별자는 백틱 또는 큰따옴표로!
명심하자!
23. 대소문자 구분을 하지 않는 MySQL의 기본 문자열 정렬 방식(Collation)
LIKE '%el%'은 실제로 다음과 같은 모든 경우를 포함한다.
'el''El''EL''eL'
즉, 소문자만 써도 대문자 포함한 모든 경우가 자동으로 매칭된다.
만약 collation이 utf8_bin처럼 binary(이진) 방식이라면, 문자 하나하나의 바이트값을 비교하게 되어 대소문자를 철저히 구분한다. 이 경우에는 반드시 LOWER(name) 또는 UPPER(name)처럼 변환을 해줘야 일관된 비교가 가능하다.
MySQL에서는 기본적으로 utf8_general_ci와 같은 대소문자 구분 없는 정렬 방식(collation)을 사용하기 때문에,
문자열 검색 시 LIKE '%el%'처럼 LOWER, UPPER 없이도 대소문자를 구분하지 않고 비교할 수 있다.
그러나! 정확하고 안전한 코드를 원할 때는 LOWER(), UPPER()를 써주는 것이 좋다.
24. SUBSTR()
MySQL에서 SUBSTR() 또는 SUBSTRING() 함수는 문자열의 일부를 추출할 때 사용된다.
✔️ 기본 문법
SUBSTR(string, start_position, length)string: 원본 문자열start_position: 추출 시작 위치 (1부터 시작)length(선택): 추출할 문자 수 (생략하면 끝까지)
SELECT SUBSTR('HelloWorld', 1, 5); -- 결과: 'Hello'
SELECT SUBSTR('HelloWorld', 6); -- 결과: 'World'
SELECT SUBSTR('HelloWorld', -5, 3); -- 결과: 'Wor'start_position은 1부터 시작
SUBSTR() 또는 SUBSTRING() 함수에서 인덱스 시작이 몇부터냐는 DBMS마다 다르지만, MySQL에서는 1부터 시작합니다.
25. QUARTER()
| 항목 | 설명 |
|---|---|
| 함수 이름 | QUARTER(date) |
| 기능 | 입력한 날짜가 몇 번째 분기(1~4)에 속하는지 숫자로 반환 |
| 반환값 | 1, 2, 3, 4 (각각 1분기~4분기 의미) |
| 입력 타입 | DATE, DATETIME, TIMESTAMP, 문자열 날짜도 가능 ('YYYY-MM-DD') |
| 주요 활용 예시 | - 분기별 입소 동물 수 집계 - 분기 기준 필터링 등 |
✔️ 반환값 기준
| 분기 번호 | 해당 월 범위 | 설명 |
|---|---|---|
| 1 | 1월 ~ 3월 | 1분기 |
| 2 | 4월 ~ 6월 | 2분기 |
| 3 | 7월 ~ 9월 | 3분기 |
| 4 | 10월 ~ 12월 | 4분기 |
NULL이 들어가면 QUARTER(NULL)은 NULL을 반환
✔️ 예시
| 쿼리 | 결과 |
|---|---|
SELECT QUARTER('2025-01-15'); | 1 |
SELECT QUARTER('2025-05-01'); | 2 |
SELECT QUARTER('2025-08-20'); | 3 |
SELECT QUARTER('2025-12-31'); | 4 |
26. CONCAT_WS()
CONCAT과 CONCAT_WS의 차이 [출처]
: 문자열을 결합하는 함수
CONCAT- 여러 문자열을 단순히 붙여서 사용
- ex)
CONCAT(CITY, '-', STREET_ADDRESS1, '-', STREET_ADDRESS2)
CONCAT_WS- 구분자를 지정하여 여러 문자열을 결합
- ex)
CONCAT_WS(' ', CITY, STREET_ADDRESS1, STREET_ADDRESS2)
예시처럼 3개 이상의 문자열을 결합할 때는 concat_ws가 더 간편하다.
27. JOIN ... ON ...
JOIN과 ON은 세트처럼 사용된다.
JOIN은 두 테이블을 합치는 명령이고, ON은 어떤 기준으로 합칠지를 지정하는 절이기 때문이다.
FROM절 다음에 위치하는JOIN과ON
SELECT *
FROM A
JOIN B
ON A.id = B.id; -- JOIN의 하위 조건JOIN은 단순히 "두 테이블 A와 B를 합쳐줘"라는 명령이다. 그런데 "뭘 기준으로 합칠까?"라는 질문이 생긴다. 그걸 ON절에서 알려준다.
JOIN만 쓰고 ON을 안쓰면 문법 오류가 난다.
왜냐하면 SQL은 "기준 없이 합치면 안돼!"라고 판단하기 때문이다. 다만, 예외적으로 CROSS JOIN은 ON없이 쓸 수 있다(모든 조합을 다 만드는 카티션 곱이라서).
INNER JOIN
기본적으로 그냥 JOIN이라고 적으면 INNER JOIN이 실행된다.
INNER JOIN은 조건에 서로 일치하는 행만 출력한다.
28. ORDER BY
기본 문법
SELECT 컬럼1, 컬럼2, ...
FROM 테이블명
[WHERE 조건]
ORDER BY 정렬기준1 [ASC|DESC], 정렬기준2 [ASC|DESC], ...;ASC: 오름차순(기본값)DESC: 내림차순
29. DATE의 출력 형식
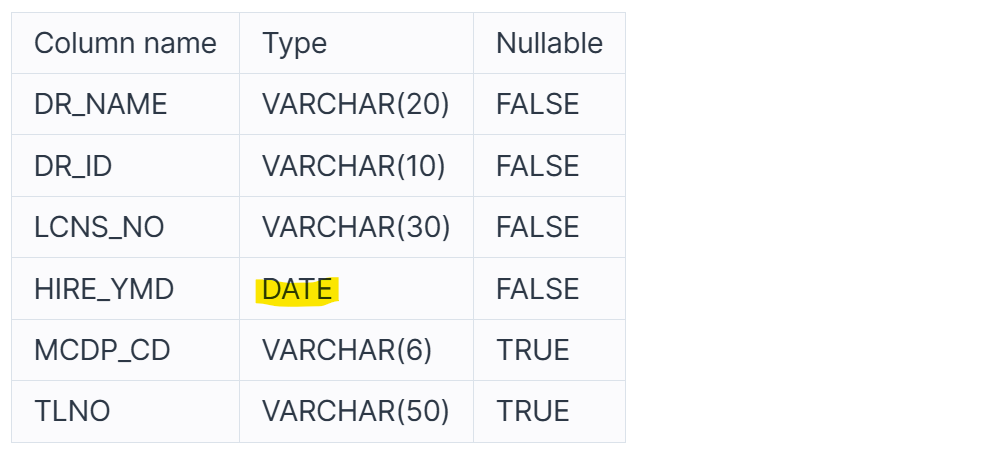
현재, DOCTOR테이블에 HIRE_YMD를 보면 DATE형식으로 되어있다.
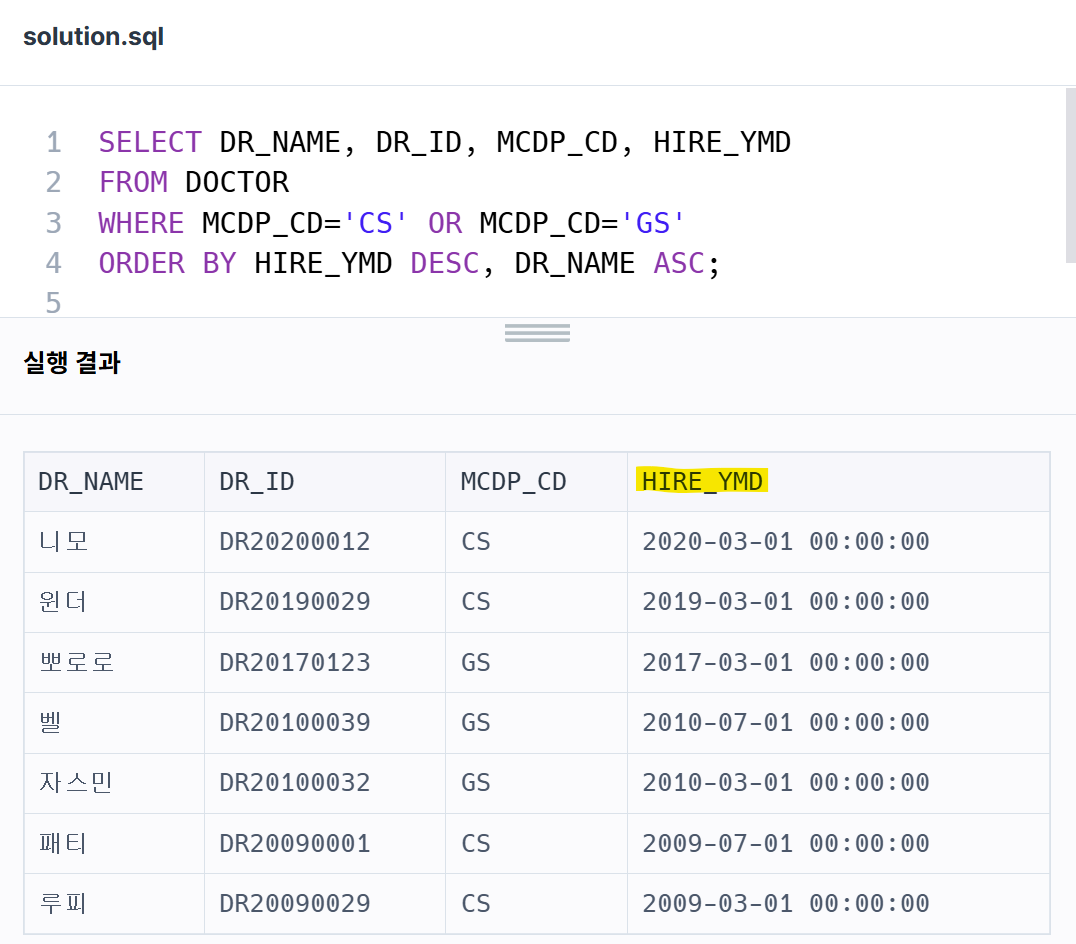
그런데, HIRE_YMD를 출력해보면 연월일 정보만 출력되는게 아니라, 뒤에 00:00:00도 같이 붙는다. 왜 그럴까...? 너무 궁금해졌다.
그 이유는, DATE형식은 오직 DB에 연, 월, 일(YYYY-MM-DD) 정보만 저장하지만, 출력할때는, 친절하게(?) 00:00:00까지 자동으로 붙여서 보여준다.
따라서, 원하는 형식으로 출력하려면 DATE_FORMAT이 필요하다.
✔️ DATE_FORMAT
| 코드 | 의미 | 예시 출력 |
|---|---|---|
| %Y | 연도 (4자리) | 2025 |
| %y | 연도 (2자리) | 25 |
| %m | 월 (2자리, 01~12) | 03 |
| %c | 월 (숫자, 앞자리 0 없음) | 3 |
| %d | 일 (2자리, 01~31) | 01 |
| %e | 일 (앞자리 0 없음, 1~31) | 1 |
참고로 %c는 calendar month에서 유래한거고, %e는 아무 의미 없다고 하다.
-- YYYY-MM-DD 형식으로 출력
SELECT DATE_FORMAT(HIRE_DATE, '%Y-%m-%d') FROM DOCTOR;
-- 2025년 03월 01일처럼 출력
SELECT DATE_FORMAT(HIRE_DATE, '%Y년 %m월 %d일') FROM DOCTOR;30. LIKE
✔️ =하고 LIKE하고 차이점?
=: "완전히 일치"하는 값만 찾음LIKE: "패턴에 일치"하는 값도 허용
| 찾고 싶은 패턴 | SQL 조건 | 설명 |
|---|---|---|
| "강원도"로 시작 | LIKE '강원도%' | '강원도'로 시작하는 모든 문자열 |
| "강원도"가 어디든 포함 | LIKE '%강원도%' | 중간이든 끝이든 포함되면 매칭 |
| "강원도"로 끝남 | LIKE '%강원도' | '강원도'로 끝나는 문자열만 |
31. IFNULL()
기본 문법
IFNULL(컬럼, '대체할 값')- 컬럼 값이
NULL이면 → `대체할 값'이 출력 - 컬럼 값이
NULL이 아니면 → 그대로 출력
32. SQL에서 "같지 않다" 표현
!=와 <> 둘 다 가능하지만, !=이게 더 자주 쓰이고 직관적이여서 보통 많이 쓴다.
SELECT *
FROM USERS
WHERE AGE != 30;
-- 또는
WHERE AGE <> 30;→ AGE가 30이 아닌 사람을 조회합니다.
33. 절댓값 함수: ABS()
SELECT ABS(-10); -- 결과: 10
SELECT ABS(5); -- 결과: 5
SELECT ABS(-3.7); -- 결과: 3.734. AND, OR
AND: 두 조건이 모두 참일 때 결과가 참
SELECT *
FROM employees
WHERE age > 30 AND salary = 50000;OR: 두 조건 중 하나라도 참이면 결과가 참
SELECT *
FROM employees
WHERE age > 30 OR salary > 50000;35. 2021년에 출판된 도서를 찾으려면?
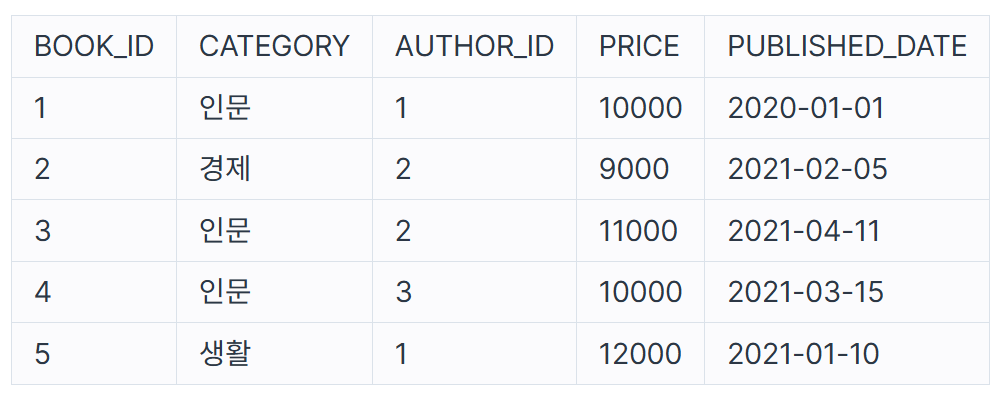
지금 위의 테이블에서 PUBLISHED_DATE가 2021로 시작되는걸 찾으려면, 어떻게 해야할까?
[방법1] LIKE '2021%'
"2021"로 시작하는 문자열 패턴을 찾기
WHERE PUBLISHED_DATE LIKE '2021%'[방법2] DATE_FORMAT(PUBLISHED_DATE, '%Y') = '2021'
날짜에서 연도만 추출해서 '2021'과 비교하기
WHERE DATE_FORMAT(PUBLISHED_DATE, '%Y') = '2021'36. IN, NOT IN
IN()
IN은 어떤 값이 여러 값 중에 포함되어 있는지 확인할 때 사용하는 연산자입니다.
보다 간결하고 가독성 좋은 조건문을 만들 수 있습니다.
WHERE 컬럼명 IN (값1, 값2, 값3, ...)✔️ 예제
SELECT *
FROM USERS
WHERE AGE IN (20, 21, 22);→ 나이가 20세, 21세, 22세 중 하나인 사용자 조회
✔️ 반대 조건: NOT IN
SELECT *
FROM USERS
WHERE AGE NOT IN (30, 40);→ 나이가 30, 40이 아닌 사람만 조회
37. 비트연산
비트 연산자(&, |, ^)
SQL에서 비트 연산자(&, |, ^)를 사용하면, 숫자는 자동으로 2진수(비트 단위)로 변환되어 연산된다.
| 연산자 | 이름 | 의미 | 작동 방식 예시 | 결과 |
|---|---|---|---|---|
| & | AND | 두 비트가 모두 1이면 1 | 0110 & 0010 (6 & 2) | 0010 → 2 |
| | | OR | 하나라도 1이면 1 | 0110 | 0010 (6 | 2) | 0110 → 6 |
| ^ | XOR | 두 비트가 다르면 1, 같으면 0 | 0110 ^ 0010 (6 ^ 2) | 0100 → 4 |
풀이
SELECT COUNT(*) AS COUNT
FROM ECOLI_DATA
WHERE (GENOTYPE & 2) = 0 -- 2번 형질이 없음
AND ((GENOTYPE & 1) > 0 -- 1번 형질이 있거나
OR (GENOTYPE & 4) > 0); -- 3번 형질이 있음이렇게 써도 되지만, 조금 더 정확히 검사하려면, 다음과 같이 써도 된다.
SELECT COUNT(*) AS COUNT
FROM ECOLI_DATA
WHERE (GENOTYPE & 2) = 0 -- 2번 형질이 없음
AND (GENOTYPE & 1 = 1 OR GENOTYPE & 4 = 4);[예시] Python과 C#을 아는 사람을 구하고 싶다면?
비트마스킹은 여러 개의 상태를 숫자 1개로 표현하는 기술이다. 각 상태를 2진수의 비트(0 또는 1)로 저장한다.
예를 들어, 개발자가 어떤 언어를 아는지 저장하고 싶다고 해보자.
| 언어 | 번호 | 비트값 (2의 제곱) |
|---|---|---|
| Java | 1번 | 1 (= 2⁰) |
| Python | 2번 | 2 (= 2¹) |
| C# | 3번 | 4 (= 2²) |
| JavaScript | 4번 | 8 (= 2³) |
- Python = 2
- C# = 4
두 개를 더하면? 2+4=6
즉, 이 사람의 SKILL_CODE는 6이다.
→ 비트 AND 연산자
&사용해서 특정 사람이 어떤 언어를 아는지를 확인할 수 있다!
| A의 상태 | 연산식 | 결과값 | 의미 |
|---|---|---|---|
| A에 B가 있음 | A & B | B | B는 A에 포함되어 있음 |
| A에 B가 없음 | A & B | 0 | B는 A에 포함되어 있지 않음 |
✔️ "이 사람이 Python을 아는지" 확인하려면?
파이썬의 비트값은 2였다.
6 & 2 = 2 → 0이 아니니까 YES! (Python을 앎)✔️ "이 사람이 Java를 아는지" 확인하려면?
6 & 1 = 0 → 0이니까 NO! (Java 모름)✔️ "이 사람이 Python 또는 Java를 아는지" 확인하려면?
Python의 2와 Java의 1을 합하면 3이다.
1 & 3 = 1 → 0이 아니니까 YES! (Java 있음)
2 & 3 = 2 → 0이 아니니까 YES! (Python 있음)
3 & 3 = 3 → 0이 아니니까 YES! (둘 다 있음)
4 & 3 = 0 → 0이니까 NO! (Python도 Java도 없음)38. 날짜에 적용되는 함수
생일이 3월인 사람 찾기
[방법1] DATE_FORMAT 사용
WHERE DATE_FORMAT(DATE_OF_BIRTH, "%m") = '03' [방법2] MONTH() 함수 사용
YEAR(),MONTH(),DAY(),HOUR,MINUTE,SECOND함수는 MySQL에서 날짜(Date/Datetime)에만 적용되는 함수이다.DATE_FORMAT()은 문자열을 반환하지만, 이 함수들은 숫자(정수)를 반환한다.
| 함수 | 설명 | 반환값 예시 | 지원 데이터 타입 | 예시 사용법 |
|---|---|---|---|---|
YEAR() | 연도 추출 | 2023 | DATE, DATETIME, TIMESTAMP | YEAR('2023-08-01 14:30:15') → 2023 |
MONTH() | 월 추출 (1~12) | 8 | DATE, DATETIME, TIMESTAMP | MONTH('2023-08-01 14:30:15') → 8 |
DAY() | 일(day) 추출 (1~31) | 1 | DATE, DATETIME, TIMESTAMP | DAY('2023-08-01 14:30:15') → 1 |
HOUR() | 시간 추출 (0~23) | 14 | DATETIME, TIMESTAMP | HOUR('2023-08-01 14:30:15') → 14 |
MINUTE() | 분 추출 (0~59) | 30 | DATETIME, TIMESTAMP | MINUTE('2023-08-01 14:30:15') → 30 |
SECOND() | 초 추출 (0~59) | 15 | DATETIME, TIMESTAMP | SECOND('2023-08-01 14:30:15') → 15 |
예시
SELECT
MEMBER_ID,
MEMBER_NAME,
GENDER,
DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") AS DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3
AND GENDER = 'W'
AND TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC;39. CASE WHEN문
CASE WHEN은 SQL에서 조건에 따라 다른 값을 반환하고 싶을 때 사용하는 조건 분기문이다.
마치 프로그래밍 언어의 if-else나 switch-case문과 비슷하게 동작한다.
CASE문 형태는 크게 두 가지로 볼 수 있다.
예제를 통해 살펴보자.
[형태1] 조건형 CASE
✔️ 예시 테이블
| id | name | score |
|---|---|---|
| 1 | 철수 | 95 |
| 2 | 영희 | 82 |
| 3 | 민수 | 76 |
| 4 | 지수 | 61 |
| 5 | 현우 | 58 |
SELECT
id,
name,
score,
CASE
WHEN score >= 90 THEN 'A' -- WHEN: 조건 정의, THEN: 해당 족너일 때 반환할 값
WHEN score >= 80 THEN 'B'
WHEN score >= 70 THEN 'C'
ELSE 'F' -- ELSE: 어떤 조건도 만족하지 않을 때 기본값
END AS grade -- END: CASE문 종료, AS: 결과 컬럼의 이름 저장
FROM students
ORDER BY id;✔️ 결과 테이블
| id | name | score | grade |
|---|---|---|---|
| 1 | 철수 | 95 | A |
| 2 | 영희 | 82 | B |
| 3 | 민수 | 76 | C |
| 4 | 지수 | 61 | F |
| 5 | 현우 | 58 | F |
- 이렇게 조건형 CASE(가장 흔한 형태)의 경우, 여러 조건을 직접 써서 분기한다.
- 마치
if-else문 처럼 작동한다. - CASE 옆에 속성명을 쓰지 않는다.
[형태2] 값 비교형 CASE
CASE score
WHEN 100 THEN '만점'
WHEN 90 THEN '우수'
ELSE '기타'
END- 이건 특정 값 자체를 비교할 때 사용한다.
- 마치 switch문 느낌이다.
- 속성명을 CASE 옆에 쓴다.
--
40. 특정 세대의 대장균 찾기
SELECT B.ID
FROM (
SELECT A.ID, A.PARENT_ID
FROM (
SELECT ID, PARENT_ID
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
) FIRST
JOIN ECOLI_DATA A
ON FIRST.ID = A.PARENT_ID
) SECOND
JOIN ECOLI_DATA B
ON SECOND.ID = B.PARENT_ID
ORDER BY ID ASC;