
코드를 작성하다 보면 종종 복잡한 문제에 직면하고 이를 해결하고자 효율적이고 정확한 방법을 찾는다. 이때 C++ 표준 라이브러리의 알고리즘은 신뢰할 수 있는 길잡이 역할을 한다.
알고리즘은 코드의 복잡도를 줄이고 효율성을 높일 수 있으며, 다양한 작업을 단순화하고 최적화할 수 있다.
표준 라이브러리에서 알고리즘은 컨테이너의 멤버 함수가 아닌 일반 함수로 제공되며, 컨테이너의 구조와 상관없이 독립적으로 동작한다.
- 정렬
- 컨테이너의 원소 정렬
- 검색
- 원소의 존재를 확인하거나 특정 원소 검색
- 변환
- 원소를 수정하거나 다른 형식으로 변환
- 반복자
- 컨테이너의 원소를 순회하고 조작
- 집계
- 컨테이너의 원소를 집계하거나 요약
정렬 (Sort)
정렬(sort)이란 어떤 기준으로 가지런하게 줄지어 늘어서게 하는 것을 의미한다. 작은 것부터 큰 것 순으로 나열하는 오름차순 정렬과 반대로 큰 것에서 작은 것 순으로 나열하는 내림차순 정렬을 떠올릴 수 있다. 컨테이너에서 정렬도 같다. 컨테이너에 저장된 원소들을 어떠한 기준에 따라 차례대로 재배열하는 것을 의미한다.
데이터를 정렬하는 가장 큰 이유는 처리 속도를 올리기 위해서이다. 데이터를 저장하고 저장된 데이터를 빠르게 찾으려고 데이터를 정렬한다. 예를 들어 이진 탐색은 컨테이너의 데이터가 정렬된 상태에서만 동작한다.
이처럼 컨테이너에서 정렬은 매우 중요한 작업이라고 할 수 있다.
퀵 정렬 (std::sort)
표준 라이브러리에서 제공하는 기본 정렬 함수인
sort는퀵 정렬(quick sort)기반으로 구현되었다.
퀵 정렬은 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법이다. 퀵 정렬은 n개의 데이터를 정렬한다고 가정했을 때 최악의 경우에는 O(n2)번의 비교를 수행하지만, 평균적으로는 O(n log n)번의 비교를 수행한다.
표준 라이브러리의 sort 함수를 이용하면 따로 퀵 정렬을 구현할 필요 없이 데이터를 편리하게 정렬할 수 있다.
sort 함수는 <algorithm> 헤더에 다음처럼 정의되어 있다. sort 함수는 매개변수로 전달 받은 first부터 last 이전까지 모든 원소를 오름차순으로 정렬한다.
template <class RandomIt>
constexpr void sort(RandomIt first, RandomIt last);first와 last 매개변수의 형식으로 지정된 RandomIt은 임의 접근 반복자(random access iterator)를 의미한다. 임의 접근 반복자는 컨테이너에 원소가 어디에 저장되어 있든 상관없이 한 번에 접근할 수 있다. array[index], vector[index]를 떠올리면 이해가 쉽다.
반면에 리스트는 std::list의 순방향 반복자만 지원하므로 list[index]처럼 임의의 위치에 있는 원소로 한 번에 접근할 수 없다.
따라서 sort함수는 std::array나 std::vector처럼 임의 접근 반복자를 지원하는 컨테이너를 대상으로만 사용할 수 있으며, std::list처럼 원소에 차례로 접근해야 하는 컨테이너에는 sort 함수를 사용할 수 없다.
만약 정렬 순서(비교 기준)를 별도로 지정하고 싶을 때는 다음처럼 오버로딩된 sort 함수를 호출하면서 세 번째 매개변수로 정렬 순서를 지정하는 비교 함수나 함수 객체를 전달하면 된다. 이때 비교 함수는 2개의 값을 받아서 첮 번째 값과 두 번째 값을 비교한 후 true나 false를 반환하도록 만들면 된다.
// C++20 기준
template <class RandomIt, class Compare>
constexpr void sort(RandomIt first, RandomIt last, Compare comp);constexpr 키워드란 무엇일까?
constexpr은 함수, 변수, 상수 표현식의 값이컴파일 타임에 결정됨을 나타내는 키워드이다.
sort함수처럼constexpr키워드로 지정된 함수는런타임에 실행되는 일반 함수와는 달리컴파일 타임에 값을 계산한다. 따라서 실행할 때 더 빠를 수 있다.
오름차순으로 정렬하기
다음의 예제는 vector 컨테이너를 선언하고, 기본 sort 함수에 벡터의 시작과 끝을 전달해 원소를 오름차순으로 정렬하는 예이다.
#include <iostream>
#include <vector>
#include <algorithm>
using std::cout;
using std::endl;
// 벡터의 원소를 순서대로 출력
template <typename T>
void PrintVectorAll(std::vector<T>& vec) {
for (typename std::vector<T>::iterator it = vec.begin(); it != vec.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int main()
{
std::vector<int> vec = { 9, 5, 2, 8, 6, 1, 3, 7, 4 };
// 벡터의 원소를 오름차순으로 정렬
std::sort(vec.begin(), vec.end());
PrintVectorAll(vec);
return 0;
}실행 결과
1 2 3 4 5 6 7 8 9내림차순으로 정렬하기
만약 내림차순으로 정렬하고 싶을 때는 다음처럼 sort 함수에 세 번째 인자로 정렬 기준을 전달한다. 예에서는 greater 함수로 정렬 기준을 지정했다.
greater 함수는 C++ 표준 라이브러리에서 제공하는 함수 객체로, 두 값을 비교할 때 첫 번째 값이 두 번째 값보다 큰지를 비교해 true 혹은 false를 반환한다.
#include <iostream>
#include <vector>
#include <algorithm>
using std::cout;
using std::endl;
// 벡터의 원소를 순서대로 출력
template <typename T>
void PrintVectorAll(std::vector<T>& vec) {
for (typename std::vector<T>::iterator it = vec.begin(); it != vec.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int main()
{
std::vector<int> vec = { 9, 5, 2, 8, 6, 1, 3, 7, 4 };
// 벡터의 원소를 오름차순으로 정렬
std::sort(vec.begin(), vec.end(), std::greater<int>());
PrintVectorAll(vec);
return 0;
}실행 결과
9 8 7 6 5 4 3 2 1사용자 정의 기준으로 정렬하기
만약 별도의 사용자 정의 기준으로 정렬하고 싶을 때는 다음처럼 세 번째 인자로 정렬 기준을 반환하는 함수를 전달한다.
다음의 예는 Person 구조체의 나이를 비교하는 Compare 함수를 만들었다.
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using std::cout;
using std::endl;
struct Person {
std::string name;
int age;
float height;
float weight;
};
// 벡터의 원소를 순서대로 출력
void PrintVectorAll(std::vector<Person>& vec) {
for (std::vector<Person>::iterator it = vec.begin(); it != vec.end(); it++) {
cout << "Name: " << it->name << ", Age: " << it->age << ", Height: " << it->height << ", Weight: " << it->weight << endl;
}
cout << endl;
}
// Person 구조체의 나이 비교
bool Compare(const Person& p1, const Person& p2) {
return p1.age < p2.age;
}
int main()
{
Person p[5] = {
{"Alice", 25, 165.5f, 52.5f},
{"Bob", 30, 175.5f, 70.5f},
{"Charlie", 20, 180.5f, 80.5f},
{"David", 35, 170.5f, 65.5f},
{"Eve", 40, 160.5f, 50.5f}
};
std::vector<Person> vec;
vec.push_back(p[0]);
vec.push_back(p[1]);
vec.push_back(p[2]);
vec.push_back(p[3]);
vec.push_back(p[4]);
cout << "--- Before Sorting ---" << endl;
PrintVectorAll(vec);
cout << endl;
// 사용자 정의 기준으로 정렬
std::sort(vec.begin(), vec.end(), Compare);
cout << "--- After Sorting ---" << endl;
PrintVectorAll(vec);
return 0;
}실행 결과
--- Before Sorting ---
Name: Alice, Age: 25, Height: 165.5, Weight: 52.5
Name: Bob, Age: 30, Height: 175.5, Weight: 70.5
Name: Charlie, Age: 20, Height: 180.5, Weight: 80.5
Name: David, Age: 35, Height: 170.5, Weight: 65.5
Name: Eve, Age: 40, Height: 160.5, Weight: 50.5
--- After Sorting ---
Name: Charlie, Age: 20, Height: 180.5, Weight: 80.5
Name: Alice, Age: 25, Height: 165.5, Weight: 52.5
Name: Bob, Age: 30, Height: 175.5, Weight: 70.5
Name: David, Age: 35, Height: 170.5, Weight: 65.5
Name: Eve, Age: 40, Height: 160.5, Weight: 50.5Compare 함수는 sort 함수의 첫 번째 인자로 전달한 벡터의 나이 정보가 두 번째 인자로 전달한 벡터의 나이 정보보다 작으면 true를 반환한다. 결국, 이 프로그램은 벡터의 원소를 Person 구조체의 나이순으로 정렬해서 출력한다.
안정 정렬 (std::stable_sort)
정렬에는 퀵 정렬 외에도 삽입, 병합, 버블, 선택 정렬 등 여러 가지 종류가 있다. 이러한 정렬은 동작 방법에 따라 다음처럼 구분된다.
- 안정 정렬 (stable sort)
- 같은 원소가 정렬 후에도 원본의 순서와 일치
- 불안정 정렬 (unstable sort)
- 같은 원소가 정렬 후에는 원본의 순서와 일치하지 않음
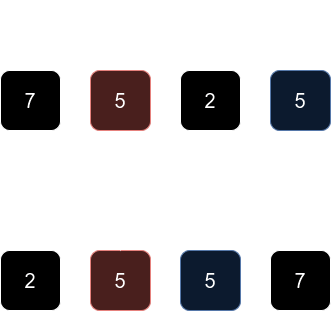
예를 들어 숫자를 기준으로 정렬한다고 생각해보자. 다음 그림에서 붉은색 5와 푸른색 5의 카드 순서가 정렬 후에도 유지되므로 안정 정렬이다.
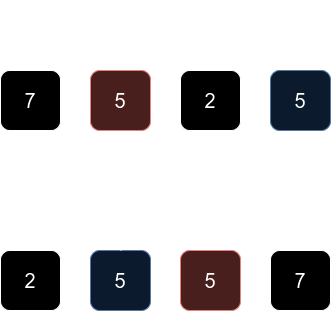
반면, 다음 그림은 정렬 후에 같은 수서로 유지되지 않으므로 불안정 정렬이다.
만약 순서의 안정성이 필요할 때는 안정 정렬을 사용해야 한다. 표준 라이브러리에서 안정 정렬을 사용하려면 stable_sort 함수를 사용한다.
stable_sort 함수를 사용하는 방법은 sort 함수와 같다. 다만 같은 값을 처리하는 내부 동작만 다르다.
// stable_sort 함수 원형
template <class RandomIt, class Compare>
void stable_sort(RandomIt first, RandomIt last, Compare comp);다음 코드는 stable_sort를 사용하여 상대적인 순서를 보장하는 안정 정렬의 예이다.
#include <iostream>
#include <string>
#include <algorithm>
#include <vector>
using std::cout;
using std::endl;
bool compare_pairs(const std::pair<int, std::string>& a, const std::pair<int, std::string>& b) {
return a.first < b.first;
}
int main()
{
std::vector<std::pair<int, std::string>> pairs = {
{5, "apple"},
{2, "orange"},
{5, "banana"},
{3, "grape"}
};
// 안정 정렬
std::stable_sort(pairs.begin(), pairs.end(), compare_pairs);
// 정렬된 결과 출력
for (std::vector<std::pair<int, std::string>>::const_iterator it = pairs.begin(); it != pairs.end(); it++) {
const std::pair<int, std::string>& pair = *it;
cout << pair.first << ": " << pair.second << endl;
}
return 0;
}실행 결과
2: orange
3: grape
5: apple
5: banana참고로 위의 for 문은 다음과 같이 간단하게 가능하다.
for (const auto& pair : pairs) {
cout << pair.first << ": " << pair.second << endl;
}위의 예에서 std::pair를 사용해 숫자와 문자열 묶음을 정의하고, 이를 저장하는 벡터를 생성했다. 그리고 벡터에 저장된 pair를 비교하는 함수 compare_pairs도 정의했다. 이 비교 함수는 pair의 첫 번째 원소인 숫자를 기준으로 정렬되도록 만들었다.
따라서 불안정 정렬하면 벡터에 저장된 {5, "apple"}, {5, "banana"}의 상대적인 순서는 지켜지지 않을 수 있다.
그래서 std::stable_sort 함수를 사용해 언제나 안정 정렬이 수행되도록 하였다. 하지만 시간 복잡도 측면에서는 std::stable_sort가 sort 함수보다 조금 더 느리다.
부분 정렬 (std::partial_sort)
컨테이너의 모든 원소가 아닌 일정 구간만 정렬할 때는 partial_sort 함수를 사용한다.
partial_sort 함수는 지정한 원소까지만 정렬하고 나머지 뒤쪽은 정렬하지 않는다. partial_sort 함수는 <algorithm> 헤더에 다음처럼 정의되어 있다.
template<class RandomIt>
constexpr void partial_sort(RandomIt first, RandomIt middle, RandomIt last);앞에서 설명한 정렬 함수와 형태는 비슷해 보이지만 매개변수 구성이 조금 다르다.
first- 정렬을 시작할 범위의 시작을 가리키는 반복자
middle- 정렬을 원하는 범위의 끝을 가리키는 반복자. 정렬 후에 이 반복자가 가리키는 위치 이전의 원소들은 정렬되지만, 이후의 원소들은 순서가 보장되지 않는다.
last- 정렬을 종료할 범위의 끝을 가리키는 반복자.
만약 오름차순으로 정렬할 때 부분 정렬 함수를 사용하면 어떻게 될까? first ~ last 범위에서 작은 원소들이 오름차순으로 first부터 middle 이전까지 모이게 된다. middle부터 last에는 first부터 middle보다 큰 원소만 모인다. 이때 middle 부터 last까지 원소들은 정렬되지 않는다.
다음은 부분 정렬 예를 보여준다. 실행 결과를 보면 앞에서 3번째까지만 정렬된 것을 확인할 수 있다.
#include <iostream>
#include <algorithm>
#include <vector>
using std::cout;
using std::endl;
int main()
{
std::vector<int> numbers = { 7, 2, 5, 1, 8, 9, 3, 6, 4 };
// 가장 작은 3개 원소만 정렬
std::partial_sort(numbers.begin(), numbers.begin() + 3, numbers.end());
// 정렬된 결과 출력
for (std::vector<int>::const_iterator it = numbers.begin(); it != numbers.end(); it++) {
cout << *it << " ";
}
cout << endl;
return 0;
}실행 결과
1 2 3 7 8 9 5 6 4부분 정렬은 일부분만 정렬하므로 sort보다 속도가 빠르다. 따라서 많은 데이터를 정렬해야 할 때 유용하게 사용할 수 있다.
선형 탐색과 비선형 탐색
선형 탐색 (std::find)
std::find는 순차 컨테이너에서 원하는 값을 찾는 함수이다. find 함수는 <algorithm> 헤더에 다음처럼 정의되어 있다.
template<class InputIt, class T>
constexpr InputIt find(InputIt first, InputIt last, const T& value);find 함수는 first ~ last 범위에서 value와 일치하는 첫 번째 원소를 가리키는 반복자를 반환한다. 만약 일치하는 원소를 찾지 못하면 last를 반환한다.
#include <iostream>
#include <algorithm>
#include <vector>
using std::cout;
using std::endl;
int main()
{
std::vector<int> numbers = { 1,2,3,4,5 };
int target;
cout << "찾고 싶은 숫자 입력: "; std::cin >> target;
// 입력받은 숫자를 찾아서 해당 위치 반환
std::vector<int>::iterator it = std::find(numbers.begin(), numbers.end(), target);
if (it != numbers.end()) {
cout << "찾은 위치: " << std::distance(numbers.begin(), it) << endl;
}
else {
cout << "찾는 숫자가 없습니다." << endl;
}
return 0;
}실행 결과
찾고 싶은 숫자 입력: 5
찾은 위치: 4
std::distance 함수란 무엇일까?위의 예에서
distance는 두 반복자 사이의 거리(원소 개수)를 계산하는 함수이다.distance함수는first에서last까지 원소 개수를 반환한다.
반환 형식은iterator_traits<InputIt>::difference_type으로 정의되어 있다.
// distance 함수 원형
template <class InputIt>
typename iterator_traits<InputIt>::difference_type
distance(InputIt first, InputIt last);find 함수는 두 값이 같은지 판단할 때 operator==를 사용한다. 따라서 찾고자 하는 값과 컨테이너 내의 각 원소를 == 연산자로 비교한다. 만약 사용자 정의 타입의 객체를 비교하려면 해당 객체에 == 연산자를 오버로딩해야 한다.
다음은 특정 조건을 만족하는 객체를 벡터에서 찾고 결과를 출력하는 간단한 예이다.
#include <iostream>
#include <algorithm>
#include <vector>
using std::cout;
using std::endl;
class my_class {
public:
int value;
std::string name;
// == 연산자 오버로딩
bool operator==(const my_class& other) const {
return value == other.value && name == other.name;
}
};
int main()
{
std::vector<my_class> objects = { {1, "one"}, {2, "two"}, {3, "three"}, {4, "four"}, {5, "five"} };
// 모든 멤버 변수까지 같은 객체를 찾음
std::vector<my_class>::iterator it = std::find(objects.begin(), objects.end(), my_class{ 3, "three" });
if (it != objects.end()) {
cout << "found: " << std::distance(objects.begin(), it) << endl;
}
else {
cout << "not found" << endl;
}
return 0;
}실행 결과
found: 2find 함수는 두 값이 같은지 비교할 때, == 연산을 하므로 my_class에 == 연산자를 오버로딩했다. 그리고 find함수에서 my_class의 객체로 구성된 벡터를 대상으로 value가 3이고, name이 "three"인 원소를 찾는다.
비선형 탐색 (std::binary_search)
위에서 살펴본 find 함수는 선형 검색(linear search)을 기반으로 동작한다.
선형 검색은 입력 범위를 처음부터 끝까지 차례로 탐색하면서 원하는 값을 찾는다. 따라서 검색 범위의 크기에 비례하는 시간이 걸리므로 데이터가 많을 때는 효율적이지 않을 수 있다. 이때는 이진 탐색(binary search)과 같은 다른 알고리즘을 사용하는 것이 빠를 수 있다.
std::binary_search 함수는 정렬된 범위에서 특정 값을 이진 탐색으로 찾는 함수이다.
binary_search 함수는 first부터 last 전까지 범위에서 세 번째 매개변수로 전달받은 value가 있는지 이진 탐색으로 확인한다.
binary_search 함수는 <algorithm> 헤더에 다음처럼 정의되어 있다. 첫 번째 함수는 operator < 연산자로 비교를 수행하고, 두 번째 함수는 comp 함수를 이용해서 비교를 수행한다.
// binary_search 함수 원형 (C++20 기준)
template <class ForwardIt, class T>
constexpr bool binary_search(ForwardIt first, ForwardIt last, const T& value);
// 비교 기준 추가
template <class ForwardIt, class T, class Compare>
constexpr bool binary_search(ForwardIt first, ForwardIt last, const T& value, Compare comp);binary_search 함수는 find 함수와 매개변수 구성, 사용법이 같다. 다만 find 는 정렬 여부와 상관없이 선형으로 검색하지만, binary_serach는 정렬된 범위에서 빠른 이진 탐색을 수애한다.
따라서 binary_search 함수를 사용하려면 컨테이너를 정렬해야 한다. 만약 정렬되지 않은 상태에서 binary_serach를 사용하면, 검색 결과를 불확실하거나 검색을 아예 실패할 수 있기 때문이다.
다음 코드는 이진 탐색을 하는 binary_search를 사용한 예이다. 먼저 sort 함수로 벡터를 정렬하는 것을 볼 수 있다.
#include <iostream>
#include <algorithm>
#include <vector>
using std::cout;
using std::endl;
int main()
{
// 정렬되지 않은 벡터
std::vector<int> numbers = { 8,3,1,7,4,5,9,2,6 };
// 정렬 수행
std::sort(numbers.begin(), numbers.end());
// 사용자에게 숫자 입력받기
int target;
cout << "Enter a number to find: ";
std::cin >> target;
// 이진 탐색
bool found = std::binary_search(numbers.begin(), numbers.end(), target);
if (found) {
cout << "The number " << target << " was found." << endl;
}
else {
cout << "The number " << target << " was not found." << endl;
}
return 0;
}실행 결과
Enter a number to find: 5
The number 5 was found.binary_search 함수는 find 함수와 비교해 얼마나 더 빠른가?
find 함수는 범위 내의 모든 원소를 순회하면서 대상 값을 찾는다. 따라서 시간 복잡도는 O(n)이다.
반면에 binary_search 함수는 이진 탐색 알고리즘을 사용하므로 범위의 중간 값과 대상 값을 비교하여 찾을 위치를 추정하고, 추정된 위치에 값이 없으면 중간 값을 기준으로 범위를 반으로 나누어 다시 탐색하는 방식으로 진행한다. 따라서 시간 복잡도는 O(log n)이다.
예를 들어, 범위의 크기가 100일 때, find 함수는 최악의 경우 100번의 비교를 수행하지만, binary_search 함수는 최악의 경우 10번의 비교를 수행한다. 이때 binary_serach는 find보다 10배 빠르다.
따라서 범위가 정렬되어 있을 때는 binary_search를 사용하는 것이 좋다.
정리
C++ 표준 라이브러리에서 제공하는 알고리즘에는 위에서 소개한 알고리즘 외에도 상당히 많은 다양한 알고리즘이 존재한다.
알고리즘은 범용성과 효율성을 고려해 설계되었으며, 특히 템플릿과 반복자로써 다양한 컨테이너를 대상으로 일관된 인터페이스를 제공한다. 표준 라이브러리의 알고리즘을 이용하면 더 효율적이고 안정ㅈ덕인 코드를 작성할 수 있다.
