
순차 컨테이너 (Sequential Container)
컨테이너는 종류에 따라 다음 3가지 범주로 나눌 수 있다. 각 범주에서 대표적인 컨테이너를 소개하고 어떤 상황에서 활용할 수 있는지 살펴보자.
순차 컨테이너- 데이터가 순서대로 삽입되는 컨테이너이다.
연관 컨테이너- 데이터가 오름차순/내림차순처럼 미리 정의된 순서로 삽입되는 컨테이너이다. 연관 컨테이너 안에 있는 원소들은 언제나 정렬된 상태를 유지한다.
컨테이너 어댑터- 순차, 연관 컨테이너와 다르게 특별한 자료 구조를 표현한 컨테이너이다.
순차 컨테이너(sequential container) 는 원소들이 선형으로 배열된 데이터 구조를 나타낸다. 순차 컨테이너는 원소들을 순차적으로 저장하며, 각 원소는 위치(index)에 따라 접근할 수 있다.
C++ 표준 템플릿 라이브러리에서 제공하는 대표적인 순차 컨테이너는 다음과 같다.
컨테이너 | 헤더 | 설명 |
|---|---|---|
| array | <array> | 표준 C 언어 스타일 배열 (정적 배열) |
| vector | <vector> | 활용도가 높은 기본 컨테이너 (동적 배열) |
| list | <list> | 연결 리스트(linked list) |
| deque | <deque> | 양방향 큐(queue) |
각 컨테이너는 특정한 작업에 더 적합한 성능을 제공하므로 상황과 요구 사항에 따라 선택해서 활용할 수 있다.
예를 들어 원소를 추가하고 삭제하는 일이 빈번할 때에는 list나 deque를 사용할 수 있으며, 원소에 빠르게 접근해야 할 때에는 vector나 array를 선택할 수 있다.
그러면 각 컨테이너를 어떻게 사용하는지 살펴보자.
배열 (std::array)
C++11에서 소개된 array는 고정된 크기의 배열을 담는 컨테이너이다. 이 컨테이너를 이용하면 일반 배열 변수가 포인터로 변환되었을 때, 배열 길이 정보를 알 수 없다는 문제와 동적 배열의 메모리 할당/해제 문제에서 벗어날 수 있는 장점이 있다. 즉, array는 안전한 배열이라고 생각하면 된다.
array의 기본 사용법을 알아보자. 먼저 array는 <array> 헤더의 std 네임스페이스에 정의되어 있다. <array> 헤더를 포함하고 array 컨테이너를 선언하는 방법은 다음과 같다. 이때 지정하는 원소의 데이터 형식은 기본 외에 개발자가 직접 만든 클래스도 지정할 수 있다.
#include <array>
std::array<데이터_형식, 크기> 객체_이름;array 컨테이너를 초기화하는 방법은 일반 배열과 같다. 만약 원소를 5개 가지는 배열 컨테이너를 선언했는데, 이보다 더 많은 값을 넣으려고 시도하면 컴파일 단계에서 오류가 발생한다.
array<int, 5> myArray {1, 2, 3, 4, 5}; // 크기가 5인 배열 생성과 초기값 5개 할당
myArray = {1, 2, 3, 4, 5, 6}; // 6개 원소 할당으로 컴파일 오류!또한 일반 배열처럼 [ ] 연산자로 각 원소에 접근할 수 있다. 다만 배열의 유효 범위 밖의 인덱스로 접근을 시도하면 런타임 오류가 발생한다.
cout << myArray[3]; // 정상 동작(유효 인덱스 범위 0 ~ 4)
cout << myArray[5]; // 유효 범위 밖 인덱스 접근 시도. 런타임 오류!잘못된 접근으로 인한 런타임 오류를 막으려면 array 클래스가 제공하는 at 함수를 사용한다. at 함수에 배열의 인덱스를 전달하면 해당 원소에 안전하게 접근할 수 있다.
예를 들어 다음 코드처럼 배열의 유효 범위를 벗어나는 접근을 시도하면 at 함수가 std::out_of_range 라는 예외를 던진다. at 함수는 유요 범위를 검사하므로 [ ] 연산자보다 느리지만 안전한 코드를 작성할 수 있다.
array<int, 5> myArray {1, 2, 3, 4, 5};
myArray.at(10) = 0; // 유효 범위 밖 접근 시도. 예외 발생!array 컨테이너에서 배열의 크기를 알 수 있는 size 함수도 유용한 멤버 함수이다. size함수는 컨테이너가 메모리에서 차지하는 크기가 아닌 원소를 저장할 수 있는 개수(=배열의 길이)를 반환한다.
참고로 size 함수는 C 언어에서 자료형의 크기를 바이트 단위로 구하는 sizeof 연산자와 다르다. sizeof 연산자는 배열_원소_자료형의_크기 X 배열_길이를 반환하므로 array 컨테이너에서 제공하는 size 함수와는 확연히 다르다.
array<int, 5> myArray {1, 2, 3, 4, 5};
cout << myArray.size() << endl; // 5 출력.
array컨테이너는 크기가 고정된 배열을 다룰 때에 주로 사용되며, 인덱스를 이용해 원소에 빠르게 접근할 수 있다는 장점이 있다.
#include <iostream>
#include <array>
using std::cout;
using std::endl;
int main()
{
// 크기가 5인 std::array 생성
std::array<int, 5> myArray;
// 배열 초기화
myArray = { 1, 2, 3, 4, 5 };
// 배열 출력
cout << "배열 출력: ";
for (const int& element : myArray) {
cout << element << " ";
}
cout << endl;
// 배열 크기 출력
cout << "배열 크기: " << myArray.size() << endl;
// 배열의 첫 번째 원소 출력
cout << "첫 번째 원소: " << myArray[0] << endl;
// 배열의 두 번째 원소 변경. myArray[1] = 55; 와 같음
myArray.at(1) = 55;
// 변경된 배열 출력
cout << "변경된 배열 출력: ";
for (const int& element : myArray) {
cout << element << " ";
}
cout << endl;
return 0;
}실행 결과
배열 출력: 1 2 3 4 5
배열 크기: 5
첫 번째 원소: 1
변경된 배열 출력: 1 55 3 4 5벡터 (std::vector)
위의 std::array가 고정된 길이의 배열 컨테이너였다면, std::vector는 동적 길이의 배열 컨테이너이다. 즉, 배열의 길이가 가변적이다.
vector 컨테이너는 임의의 위치에 저장된 원소에 빠르게 접근할 수 있고, 동적 배열 관리를 안전하게 수행해 주는 덕분에 표준 컨테이너 가운데 가장 많이 활용된다.
vector 컨테이너는 <vector> 헤더의 std 네임스페이스에 정되어 있으며 다음처럼 선언해 사용한다.
#include <vector>
std::vector<데이터_형식> 객체_이름;
std::vector<데이터_형식> 객체_이름(크기);
std::vector<데이터_형식> 객체_이름(크기, 초기값);
std::vector<데이터_형식> 객체_이름 = {값1, 값2, 값3, ...};vector 컨테이너를 선언할 때 크기를 지정하지 않을 수도 있고, 지정할 수도 있다. 그리고 크기와 초기값을 함께 지정할 수도 있으며, 중괄호를 이용한 유니폼 초기화도 할 수 있다.
유니폼 초기화는 초기값을 중괄호 안에 나열하는 방법으로, 다양한 컨테이너나 배열, 객체 등에도 적용할 수 있다. 이 방식은 코드의 가독성을 높이고, 초기화 과정에서 발생할 수 있는 오류를 방지하는 데 도움이 된다.
vector<int> vec1; // 벡터 크기 미지정
vector<int> vec2(5); // 크기(원소 개수)가 5인 벡터 선언
vector<int> vec3(5, 1); // 크기가 5인 벡터를 1로 초기화
vector<int> vec4 = {1, 2, 3, 4, 5}; // 유니폼 초기화vector 컨테이너의 원소에는 배열처럼 [ ] 연산자로 접근할 수 있으며, array 컨테이너에서 보았던 at 함수도 사용할 수 있다.
vector<int> vec = {1, 2, 3, 4, 5};
vec[0] = 10; // 첫번째 원소를 10으로 변경
vec.at(1) = 20; // 두 번째 원소를 20으로 변경(at 함수 사용)벡터의 크기는 동적이므로 힙 메모리 (heap memory)가 허용하는 한 계속 늘릴 수 있다. 따라서 push_back이라는 멤버 함수로 벡터의 끝에 원소를 계속 추가할 수 있다.
#include <iostream>
#include <vector>
using std::cout;
using std::endl;
int main()
{
std::vector<int> vec;
vec.push_back(0);
vec.push_back(1);
vec.push_back(2);
for (int i = 0; i < 3; i++) {
cout << "vec의 값: " << i + 1 << "번째 원소 -> " << vec[i] << endl;
}
return 0;
}실행 결과
vec의 값: 1번째 원소 -> 0
vec의 값: 2번째 원소 -> 1
vec의 값: 3번째 원소 -> 2push_back 함수를 호출할 때마다 전달한 값이 벡터의 마지막 원소 다음에 추가된다. 만약 빈 벡터에 push_back 함수를 호출하면 첫 번째 인덱스에 채워진다. 따라서 앞의 코드에서 vec에는 정수 0, 1, 2가 차례로 저장된다.
vector container 의 메모리 운영 방식
벡터 컨테이너는 배열의 길이보다 항상 여유분을 포함해 메모리를 운영한다. 벡터 맨 뒤에 원소를 추가하거나 빼는 것은 매우 빠르지만, 배열의 특성상 임의의 위치에 원소를 추가하거나 제거하는 것은 매우 느리다. 또한 기존에 할당된 공간이 다 차서 더 큰 새로운 공간으로 이동할 때는 원소들을 복사해야 한다. 따라서 원소의 개수가 n개 일 때 시간 복잡도는
O(n)만큼 걸린다.이처럼 컨테이너는 동작 원리에 따라 같은 동작도
속도 차이가 발생할 수 있다. 따라서 각 컨테이너를 잘 이해하고 용도에 맞는 최적의 컨테이너를 골라서 사용해야 한다.
벡터 컨테이너의 insert와 erase 함수에 반복자를 전달하면 중간에 새로운 원소를 넣거나 지울 수도 있다.
#include <iostream>
#include <vector>
using std::cout;
using std::endl;
template <typename T>
void print_vector_all(std::vector<T>& vec) {
cout << "벡터 내 원소 개수: " << vec.size() << endl;
for (typename std::vector<T>::iterator it = vec.begin(); it != vec.end(); it++) {
cout << *it << " ";
}
cout << endl << "-------------------" << endl;
}
int main()
{
std::vector<int> vec;
vec.push_back(0);
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
cout << "original" << endl;
print_vector_all(vec);
// 벡터에 원소 삽입 -> vec[3] 앞에 25 삽입
vec.insert(vec.begin() + 3, 25);
cout << "after insert" << endl;
print_vector_all(vec);
// 벡터에서 원소 삭제 -> vec[3] 삭제
vec.erase(vec.begin() + 3);
cout << "after erase" << endl;
print_vector_all(vec);
return 0;
}실행 결과
original
벡터 내 원소 개수: 5
0 10 20 30 40
-------------------
after insert
벡터 내 원소 개수: 6
0 10 20 25 30 40
-------------------
after erase
벡터 내 원소 개수: 5
0 10 20 30 40
-------------------벡터 컨테이너에서 insert 함수로 원소가 삽입된 결과를 보면 30이 저장된 위치에 25가 들어가면서 30을 포함해 그 뒤에 있는 원소 40까지 한 칸씩 뒤로 밀리도록 복사 저장되는 것을 확인할 수 있다. 이러한 특성 때문에 벡터 컨테이너는 삽입되는 위치에 따라 처리 속도 면에서 불리할 수 있다는 점을 기억해야 한다.
erase 함수도 insert와 유사하게 동작한다. 지정한 위치의 원소를 제거한다. erase 함수에 전달한 인자는 제거할 원소의 위치이다. begin() + 3을 지정하면 벡터의 시작 위치에서 +3 만큼 이동한 곳의 원소를 제거한다.
그런데 원소를 제거한 후 그 빈자리는 어떻게 될까? 제거한 원소 다음부터 벡터의 끝까지 모든 원소가 앞으로 한 칸씩 당겨지도록 복사 저장한다.
즉, insert 함수는 한 칸씩 뒤로 밀리도록 복사 저장하고, erase 함수는 한 칸씩 앞으로 당겨지도록 복사 저장한다. 만약 많은 원소가 저장된 벡터의 앞부분에서 insert나 erase 함수가 수행된다면 그 속도가 더욱 느려진다. 따라서 삽입이나 제거가 빈번하게 발생한다면 벡터 대신 다른 컨테이너를 사용하는 것이 좋다.
❗ 삽입이나 제거가 빈번하게 발생한다면
vector container대신 다른 컨테이너를 사용하는 것이 좋다!
함수 템플릿 활용
표준 템플릿 라이브러리에서 제공하는 컨테이너는 모두 클래스 템플릿 형태이다. 따라서 특정 타입의 객체를 저장할 수 있는 전용 컨테이너를 선언할 수 있다. 즉, 같은 벡터 컨테이너라도 저장할 수 있는 데이터 형식을 각각 다르게 선언할 수 있다.
만약 직접 만든 구조체나 클래스 형식의 데이터를 저장하려면 해당 구조체나 클래스의 이름을 넣어주면 된다.
vector<int>- 정수 형식의 데이터를 저장할 수 있는 벡터 컨테이너
vector<float>- 부동 소수점 형식의 데이터를 저장할 수 있는 벡터 컨테이너
vector<string>- 문자열 형식의 데이터를 저장할 수 있는 벡터 컨테이너
vector<MyClass>- 사용자 정의 형식(MyClass)의 데이터를 저장할 수 있는 벡터 컨테이너
이처럼 다양한 형식의 벡터 컨테이너를 하나의 함수로 모두 처리하고 싶다면 어떻게 해야 할까?
클래스 템플릿 형태인 표준 템플릿 라이브러리의 컨테이너를 이용하다 보면 실제로 이러한 요구가 자주 발생한다. 이때는 함수 템플릿을 이용하면 된다.
template <typename T>
void print_vector_all(vector<T> &vec)함수 템플릿을 이용하면 템플릿 매개변수(T)를 이용해 다양한 형식을 전달받아 처리할 수 있다. 즉, 위의 print_vector_all 함수는 다양한 형식의 벡터 컨테이너를 전달받아 모든 원소를 출력하도록 범용으로 만든 것이다.
값을 변경할 수 없는 정적 반복자
반복자를 다룰 때, 반복자는 포인터처럼 동작한다라고 했다. std::vector에서 지원하는 반복자 가운데 const_iterator가 있다.
const_iterator는 정적 포인터처럼 생각하면 쉽다. 즉, 반복자가 가리키는 원소값을 변경할 수 없다.
vector<int>::const_iterator const_it_begin = vec.cbegin();
vector<int>::const_iterator const_it_end = vec.cend();const_iterator는 cbegin()과 cend() 함수로 얻을 수 있다. 반복자로 지정한 값을 변경하지 않고 참조만 할 때 const_iterator를 활용할 수 있다.
#include <iostream>
#include <vector>
using std::cout;
using std::endl;
int main()
{
std::vector<int> vec;
vec.push_back(0);
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
std::vector<int>::const_iterator const_it = vec.cbegin();
cout << *const_it << endl;
const_it++;
cout << *const_it << endl;
const_it = vec.cend();
const_it--;
cout << *const_it << endl;
return 0;
}실행 결과
0
10
40const_iterator 형식으로 선언한 반복자 const_it는 일반 반복자처럼 역참조 연산자로 값을 참조하거나 증감 연산 등으로 가리키는 대상을 자유롭게 변경할 수 있다. 하지만 다음 코드처럼 반복자가 가리키는 원소값을 변경할 수는 없다. 이는 const 키워드의 특성을 그대로 따르기 때문이다.
*const_it = 100; // 컴파일 오류거꾸로 동작하는 리버스 반복자 (Reverse Iterator)
std::vector에서 지원하는 반복자 중에 거꾸로 동작하는 리버스 반복자(reverse iterator)도 있다.
리버스 반복자는 벡터 컨테이너의 뒤부터 앞으로 움직이는 특성이 있다. 리버스 반복자를 활용하는 예를 살펴보자.
#include <iostream>
#include <vector>
using std::cout;
using std::endl;
int main()
{
std::vector<int> vec;
for (int i = 0; i < 3; i++) {
vec.push_back(i);
}
for (std::vector<int>::reverse_iterator it = vec.rbegin(); it != vec.rend(); it++) {
cout << *it << endl;
}
return 0;
}실행 결과
2
1
0for문에 있는 vec.rbegin 함수는 벡터 컨테이너의 가장 마지막에 저장된 위치를 가리키는 리버스 반복자를 반환한다.
리버스 반복자를 대상으로 증가(++) 연산을 수행하면 다음 위치가 아닌 이전 위치를 가리킨다. 그리고 rend() 함수는 벡터 컨테이너의 가장 앞에 저장된 원소에서 바로 이전 위치를 가리키는 리버스 반복자를 반환한다. 즉, 벡터 컨테이너의 시작 위치와 마지막 위치를 반환하는 begin(), end() 함수와 반대이며, 연산 결과도 반대이다.
리스트 (std::list)
C++의 std::list는 연결 리스트(linded list)라는 데이터 구조를 구현한 컨테이너이다.
연결 리스트는 데이터가 노드(node)라 불리는 개별 객체로 구성되며, 각 노드는 다음 노드를 가리키는 포인터를 포함한다. 이러한 특성 때문에 리스트는 데이터를 삽입하고 삭제하는 데 효율적이며 순서를 유지할 수 있다.
list 컨테이너를 사용하여 값을 추가, 삭제하고 리스트의 크기와 리스트가 비었는지를 확인하는 간단한 예를 살펴보자.
#include <iostream>
#include <list>
using std::cout;
using std::endl;
int main()
{
std::list<int> myList;
// 리스트 뒤쪽에 값 추가
myList.push_back(2);
myList.push_back(3);
myList.push_back(4);
// 리스트 앞쪽에 값 추가
myList.push_front(1);
myList.push_front(0);
// 리스트 출력
cout << "리스트 출력: ";
for (const int& value : myList) {
cout << value << " ";
}
cout << endl;
myList.pop_front(); // 첫번째 원소 제거
myList.pop_back(); // 마지막 원소 제거
// 삭제 후 리스트 출력
cout << "삭제 후 리스트 출력: ";
for (const int& value : myList) {
cout << value << " ";
}
cout << endl;
// 리스트 크기 확인
cout << "리스트 크기: " << myList.size() << endl;
// 리스트가 비었는지 확인
cout << "리스트가 비었는지 확인: " << (myList.empty() ? "비었음" : "비어있지 않음") << endl;
return 0;
}실행 결과
리스트 출력: 0 1 2 3 4
삭제 후 리스트 출력: 1 2 3
리스트 크기: 3
리스트가 비었는지 확인: 비어있지 않음리스트에 값을 추가할 때는 push_back과 push_front 함수를 사용한다. 이름에서 알 수 있듯이 push_back은 리스트의 뒤쪽에, push_front는 리스트의 앞쪽에 값을 추가하는 함수이다.
값을 제거할 때오 방향에 따라 pop_front와 pop_back 함수를 사용한다. 각각 첫 번째 값과 마지막 값을 제거한다.
리스트의 크기는 size 함수로 알 수 있으며 반환값을 원소의 개수이다. empty 함수는 리스트가 비었는지 확인할 때 사용한다.
리스트 컨테이너도 벡터 컨테이너처럼 삽입된 순서를 유지하는 순차 컨테이너이다. 활용법도 vector와 매우 유사하다. 그러나 vector와 list는 내부 구현 방식이 다르다.
vector container는동적 배열로 구현되어, 원소들을연속된 메모리 공간에 저장한다.list container는이중 연결 리스트로 구현되어, 각 원소에는 다음 원소와 이전 원소를 가리키는포인터가 있다.
이러한 차이점 때문에 벡터는 임의 접근이 가능하며 원소를 상수 시간에 접근할 수 있지만, 리스트는 임의 접근이 불가능하며 원소에 접근하려면 이전 원소들을 차례로 따라가야 한다. 따라서 벡터는 원소에 자주 접근하고 수정해야 할 때에 주로 사용하고, 리스트는 삽입과 삭제가 빈번할 때에 유용하다.
상수 시간 (constant time) 이란?
알고리즘이나 연산이 실행되는 데 필요한 시간이 입력 크기에 무관하게 일정한 시간만큼 소요되는 것을 의미한다. 즉, 연산에 필요한 시간이 상수로 고정되어 있어서 입력 크기가 증가하더라도 실행 시간이 변하지 않는 것을 의미한다.
덱 (std::deque)
deque (double-ended queue) 역시 배열 기반의 컨테이너이며 벡터 컨테이너와 유사하다. 멤버 함수도 벡터 컨테이너와 비슷하다.
벡터는 하나의 메모리 블록에 원소들을 저장하는 구조이다. 따라서 새로운 원소를 추가할 때 공간이 부족하면, 메모리를 재할당한 후에 이전 원소들을 모두 복사한다.
반면에 deque 컨테이너는 여러 개의 메모리 블록을 나눠서 저장하는 것이 특징이다. 저장할 공간이 부족하면 일정한 크기의 새로운 메모리 블록을 만들어서 연결한다. 따라서 벡터 컨테이너에서 일어나는 복사 저장이 발생하지 않는다.
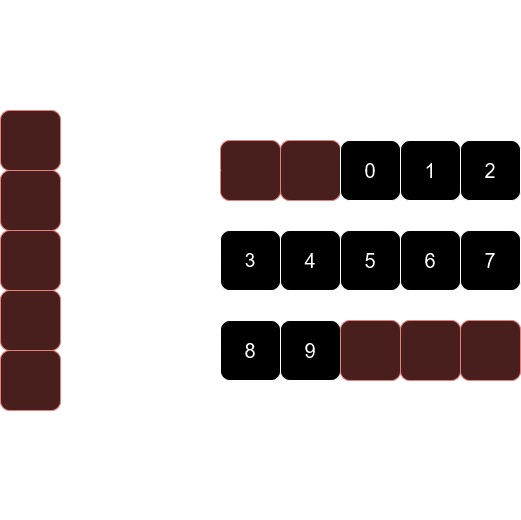
즉, deque은 벡터의 단점을 보완하는 컨테이너이다. deque과 벡터의 특징을 비교하면 다음과 같다.
특징 | std::deque | std::vector |
|---|---|---|
| 메모리 할당 방식 | 메모리의 재할당이 자주 발생하지 않음 | 메모리의 재할당이 발생할 수 있음 |
| 원소 삽입과 삭제 | 양쪽 끝에서 O(1)의 시간 복잡도로 수행 | 끝에서 O(1)의 시간 복잡도로 수행 중간에서 O(n)의 시간 복잡도로 수행 |
| 원소 접근 | O(1)의 시간 복잡도로 수행 | O(1)의 시간 복잡도로 수행 |
deque 컨테이너는 원소의 삽입과 삭제가 빈번하게 일어나는 상황에서 사용하기에 좋다.
특히 원소의 삽입과 삭제가 양쪽 끝에서 빈번하게 일어나는 상황에서는 deque이 리스트보다 더 효율적이다. 😀
다음은 deque을 사용하는 예제 코드이다.
#include <iostream>
#include <deque>
using std::cout;
using std::endl;
int main()
{
std::deque<int> myDeque;
// 덱 뒤쪽에 값 추가
myDeque.push_back(2);
myDeque.push_back(3);
myDeque.push_back(4);
// 덱 앞쪽에 값 추가
myDeque.push_front(1);
myDeque.push_front(0);
// 덱 출력
cout << "myDeque: ";
for (const int& value : myDeque)
{
cout << value << " ";
}
cout << endl;
myDeque.pop_front(); // 첫 번째 원소 제거
myDeque.pop_back(); // 마지막 원소 제거
// 삭제 후 덱 출력
cout << "삭제 후 deque 출력: ";
for (const int& value : myDeque) {
cout << value << " ";
}
cout << endl;
// 덱 크기 확인
cout << "deque size: " << myDeque.size() << endl;
// 덱이 비었는지 확인
cout << "deque empty: " << (myDeque.empty() ? "true" : "false") << endl;
// 덱의 첫 번째와 마지막 원소 출력
cout << "deque front: " << myDeque.front() << endl;
cout << "deque back: " << myDeque.back() << endl;
return 0;
}실행 결과
myDeque: 0 1 2 3 4
삭제 후 deque 출력: 1 2 3
deque size: 3
deque empty: false
deque front: 1
deque back: 3deque에 원소를 추가하고 삭제하는 방법과 크기를 구하고 비었는지 확인하는 방법 등 모두 리스트와 똑같다.
deque은 큐(Queue) 자료 구조와 벡터의 특성을 모두 가진 C++ 표준 템플릿 라이브러리의 컨테이너 중 하나로, 데이터를 양쪽 끝에서 효율적으로 추가하고 제거할 수 있다.
벡터는 원소의 삽입과 삭제가 배열의 끝에서만 이뤄지지만, deque은 양쪽 끝에서 삽입과 삭제가 효율적으로 이루저지며 중간 부분에서도 상수 시간에 원소를 삽입하거나 삭제할 수 있다.
시간 복잡도 (Time Complexity)
시간 복잡도(time complexity)는 알고리즘이나 프로그램의 실행 시간이 어느 정도인지 나타내는 용어이다. 알고리즘의 성능을 이야기할 때 항상 등장하는 용어이다.
시간복잡도는 대개 빅 오(Big O) 표기법을 사용해 입력 크기에 대한 함수로 나타낸다. 여기서 빅 오는 최악의 경우에 대한 성능을 의미하며, 이는 곧 알고리즘 성능의 상한과 같은 의미이다. 시간 복잡도를 간단한 표로 정리하면 다음과 같다.
시간 복잡도 | 설명 | 예시 |
|---|---|---|
| O(1) | 상수 시간 | 배열에서 특정 원소 접근 |
| O(log n) | 로그 시간 | 이진 탐색 |
| O(n) | 선형 시간 | 배열 순회 |
| O(n log n) | 선형 로그 시간 | 퀵 정렬, 병합 정렬 |
| O(n2), O(n3), ... | 다항 시간 | 이중 반복문 정렬 알고리즘 |
| O(2n) | 지수 시간 | 효율적이지 않은 재귀 알고리즘 |
일반적으로 최대한 O(n log n) 이하의 시간 복잡도를 가지는 알고리즘을 선택하는 것이 좋다. 시간 복잡도를 고려한 효율적인 방법을 선택하고 문제를 해결하는 습관을 가질 수 있도록 노력해야 한다.
