
kafka spark streaming 을 통한 데이터 파이프라인 구축을 해보기 전에, 기본 예제를 통해 구축해보고자 합니다.
구성
우선 동일한 환경을 주기 위해, docker에 해당 환경을 구축했습니다.
version: '3.7'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ports:
- '22181:2181'
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- '29092:29092'
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
jupyter:
image: jupyter/pyspark-notebook:python-3.8.8
ports:
- '8888:8888'
ZOOKEEPER_SERVER_ID: ZooKeeper 서버의 고유 ID.
ZOOKEEPER_CLIENT_PORT: 클라이언트가 ZooKeeper와 통신하는 데 사용하는 포트.
ZOOKEEPER_TICK_TIME: ZooKeeper의 기본 시간 단위 (밀리초 단위).
ZOOKEEPER_INIT_LIMIT: 초기 연결 시간 제한.
ZOOKEEPER_SYNC_LIMIT: 동기화 시간 제한.
KAFKA_BROKER_ID: kafka 브로커 아이디(유니크).단일 브로커 사용시 없어도 무방.
KAFKA_ZOOKEEPER_CONNECT: kafka가 zookeeper 연결.
KAFKA_ADVERTISED_LISTENERS: 외부에서 접속하기 위한 리스너 설정.
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 보안을 위한 프로토콜 매핑.
KAFKA_INTER_BROKER_LISTENER_NAME: 도커 내부에서 사용할 리스너 이름.
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 토픽 파티션의 복제 개수
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 카프카 그룹이 초기 리밸런싱할때 컨슈머들이 컨슈머 그룹에 조인할때 대기 시간.
실습환경은 쥬피터 노트북으로 구성하였다.
docker-compose exec kafka kafka-topics --create --topic my-topic --bootstrap-server kafka:9092 --replication-factor 1 --partitions 1
my-topic 이라는 이름의 토픽을 하나 생성해주었다.
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(
acks=0,
compression_type='gzip',
bootstrap_servers=['['카프카 서버 ip']:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
try:
for i in range(1000):
data = {'str': 'result' + str(i)}
producer.send('my-topic', value=data)
except Exception as e:
print(f"Error: {e}")
finally:
producer.flush()
producer.close()
1000개의 데이터를 프로듀서에 보냈다.
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'my-topic', # 수신할 토픽 이름
bootstrap_servers=['['카프카 서버 ip']:9092'],
api_version=(2, 9, 0),
auto_offset_reset='earliest', # 컨슈머 그룹이 처음으로 메시지를 가져올 때 가장 초기의 오프셋부터 가져오도록 설정
enable_auto_commit=True, # 자동으로 커밋
group_id='my-group', # 컨슈머 그룹 ID
value_deserializer=lambda x: loads(x.decode('utf-8'))
)
# 메시지를 수신.
for message in consumer:
print(f"Received message: {message.value}")
# 컨슈머를 종료.
consumer.close()
컨슈머를 통해 해당 프로듀서에 쌓여있는 메세지를 받아왔다.
- 문제
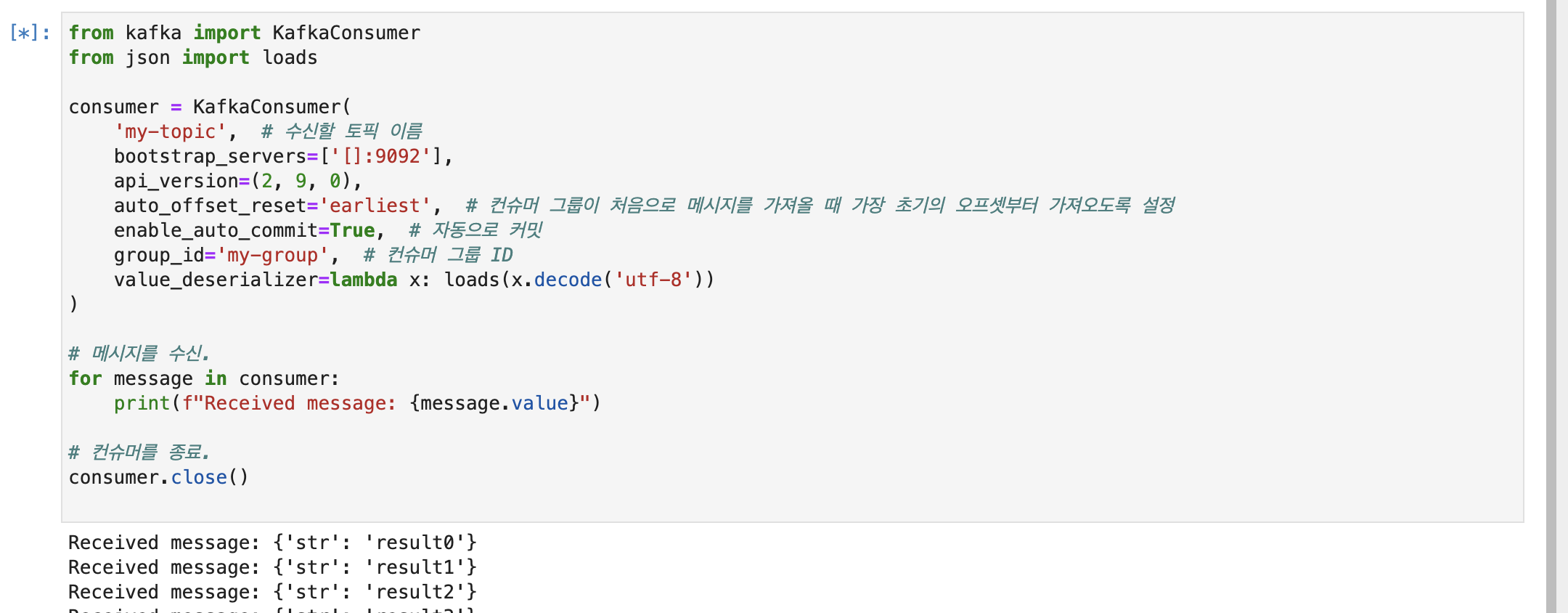
메세지는 총 1000개 잘 받아왔는데, 컨슈머가 끝나지 않는 문제가 발생했다.
chatGpt
컨슈머가 계속 실행되는 이유는 현재 코드에서 블록킹되어 있기 때문입니다.
for message in consumer: 구문은 계속해서 메시지를 기다리고 블록시키기 때문에,
더이상 메시지가 없어도 종료되지 않습니다.
GPT3.5의 답변이다. 블로킹? 카프카에 대한 지식이 전무한 상태이기 때문에, 우선 내가 파악한 것은 consumer가 메세지를 다 출력했음에도, 끝나는 게 아니라, 계속해서 메시지를 대기하는 상황인 것 같다.
Todo
- NIO(Non-blocking I/O) 에 대하여
- 카프카의 통신
- 해당 통신을 위해서 어떻게 코드를 짜야하는가?
레퍼런스
https://devocean.sk.com/blog/techBoardDetail.do?ID=164007
https://yooloo.tistory.com/92
