데이터 이행을 진행할 때 오라클 골든 게이트를 사용하지 않는다면 테이블 스페이스 레벨의 데이터 이행이 가장 빠르고 전부 옮겨진다. 그래서 tablespace level 이행으로 진행해도 괜찮은지 확인하는것이 우선이고, 스키마 레벨로 진행해야한다면 일반 스키마레벨로 데이터 이행하면 안된다. 작은 회사는 상관없지만 데이터가 많은 큰 회사에서는 시간이 너무 오래걸리고 UNDO, TEMP가 full이 날 수 있다.
❗️ 차이점은, 테이블, 인덱스 , 제약 등을 한번에 해주지 않는것이다. 따로따로 생성한다!
효율적 이행
1. as - is DB 에서 테이블 생성 스크립트만 뽑아내서 to- be DB에 빌드한다.
2. 데이터 덤프를 뽑아내서 import 한다.
3. 인덱스 생성 스크립트를 뽑아내서 to - be DB에 병렬도를 지정해서 인덱스를 생성한다.
4. 제약 생성 스크립트를 뽑아내서 to - be DB에 제약을 생성
5. 시너님, 프로시저, 함수 생성 스크립트 뽑아내서 to - be DB에 생성
6. as - is와 to - be 간의 테이블 갯수와 데이터 건수, 인덱스 건수, 시너님, 프로시저, 함수의 갯수, 권한이 일치하는지 확인✏️ DB간 스키마 레벨로 데이터 이행하는 기술
데이터 이행 : table, index 생성 스크립트를 추출하여 따로따로 생성해준다.
orcl2 ---------------------------> orcl3
scott scott_dev2💡 scott이 소유한 모든 테이블, 인덱스, 데이터를 모두 이행한다!
순서
1. (orcl2) 테이블 생성 스크립트와 인덱스 생성 스크립트를 추출하기
2. (orcl2) 스키마 레벨로 export 한다.
3. (orcl3) 테이블 생성 스크립트로 테이블 생성
4. (orcl3) 스키마 레벨로 import를 한다.
5. (orcl3) 병렬도를 주고 인덱스 생성
6. (orcl3) 병렬도를 다시 1로 변경해준다.
7. (orcl3) orcl2, orcl3 간의 테이블 갯수, 데이터 건수, 인덱스 갯수를 확인한다.
실습과정
✔️ 실습을 위해 orcl2 scott의 emp테이블 초기화, 인덱스 생성을 했다.
SCOTT @ orcl2 > @demo SCOTT @ orcl2 > create index emp_index1 on emp(empno,ename); Index created. SCOTT @ orcl2 > create index emp_index2 on emp(sal); Index created.1. (orcl2) 테이블 생성 스크립트와 인덱스 생성 스크립트를 추출하기
- sqldevelper 에서 도구 > 데이터베이스 익스포트 아래 이미지 처럼 하면 테이블 생성하는 스크립트, 인덱스 생성하는 스크립트가 따로 저장이 된다.
2. (orcl2) 스키마 레벨로 export 한다.[orcl2:~]$ exp scott/tiger tables=emp file=emp.dmp3. (orcl3) 테이블 생성 스크립트로 테이블 생성
4. (orcl3) 스키마 레벨로 import를 한다.
5. (orcl3) 병렬도를 주고 인덱스 생성
6. (orcl3) 병렬도를 다시 1로 변경해준다.
7. (orcl3) orcl2, orcl3 간의 테이블 갯수, 데이터 건수, 인덱스 갯수를 확인한다.
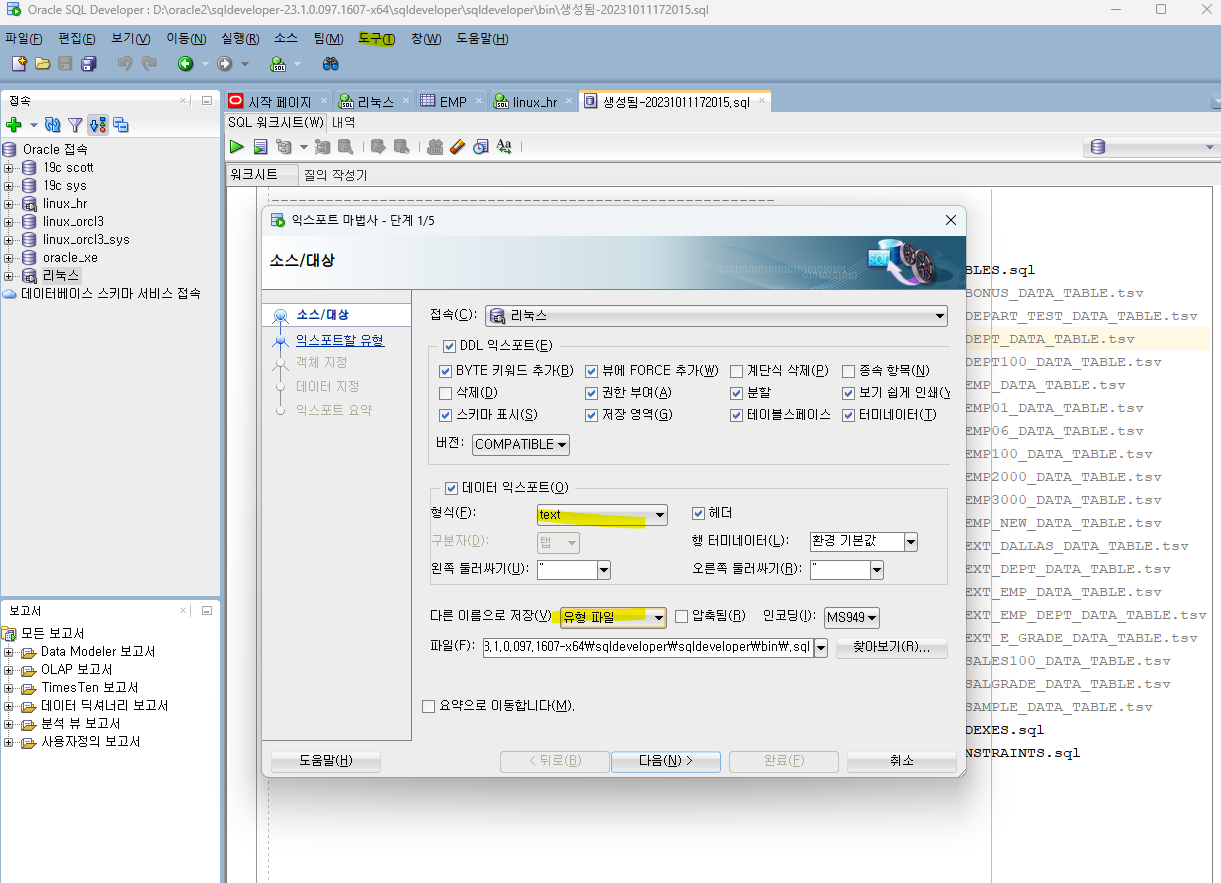
1. table, index 생성 스크립트를 sqldeveloper에서 추출
orcl2 ------------------> orcl3
1. dept --------------------> dept
2. 인덱스 -------------------> 인덱스1. (orcl2) demo 스크립트로 emp와 dept를 초기화 합니다.
SCOTT @ orcl2 > @demo2. (orcl2) dept테이블에 결합 컬럼 인덱스 등 여러 인덱스를 생성합니다. -> dept에 인덱스가 없어서 실습을 위해 만들어준것임!
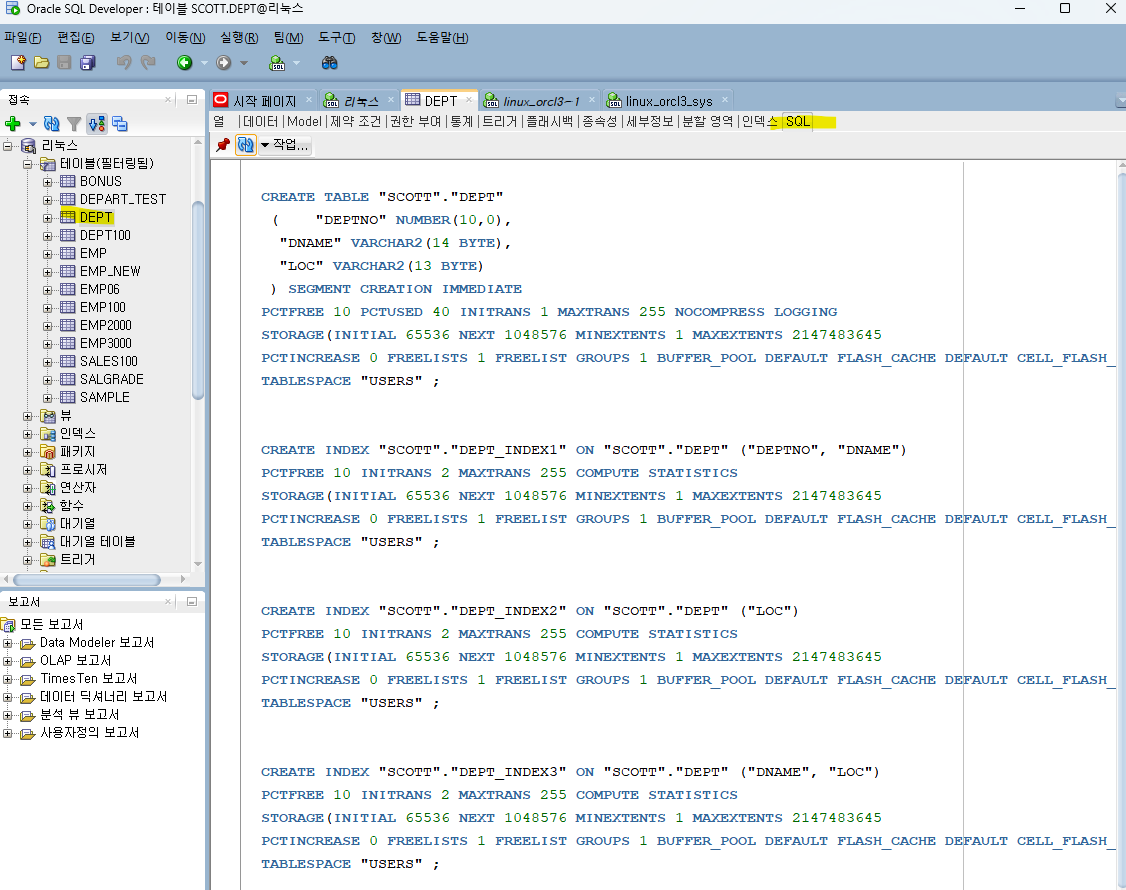
SCOTT @ orcl2 > create index dept_index1 on dept(deptno,dname); SCOTT @ orcl2 > create index dept_index2 on dept(loc); SCOTT @ orcl2 > create index dept_index3 on dept(dname,loc);3. (orcl2) sqldeveloper 로 dept테이블의 생성 스크립트와 인덱스 스크립트를 추출합니다.
4. (orcl2) dept테이블을 export 합니다.[orcl2:~]$ exp scott/tiger tables=dept file=dept.dmp5. (orcl3) scott_dev라는 계정을 생성합니다.
SYS @ orcl3 > create user scott_dev identified by tiger; SYS @ orcl3 > grant resource , connect to scott_dev;6. (orcl3) scott_dev에서 위 3번에서 생성한 테이블 생성 스크립트를 생성합니다.
: 3번에서 추출한거 돌림! scott -> scott_dev라고 변경해야하고, table space가 orcl3에도 있는지 확인해야 한다.
7. (orcl3) 4번에서 생성한 덤프파일을 임포트 합니다.$ imp scott_dev/tiger file=dept.dmp tables=dept ignore=y indexes=no SCOTT_DEV @ orcl3> select count(*) from dept;8. (orcl3) 3번에서 생성한 인덱스 생성 스크립트를 병렬도를 지정해서 돌립니다.
parallel 4쓰기CREATE INDEX "SCOTT_DEV"."DEPT_INDEX1" ON "SCOTT_DEV"."DEPT" ("DEPTNO", "DNAME") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."DEPT_INDEX2" ON "SCOTT_DEV"."DEPT" ("LOC") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."DEPT_INDEX3" ON "SCOTT_DEV"."DEPT" ("DNAME", "LOC") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4;
✅ 위 스크립트는 orcl2에서 뽑아낸 스크립트라서scott_dev라고 이름 바꾸었다.테이블스페이스가 users로 되어있는데 이 ts가 orcl3에도 있어야 생성이 된다.9. (orcl3) index의 병렬도를 1로 변경해줍니다.
alter index dept_index1 parallel 1; alter index dept_index2 parallel 1; alter index dept_index3 parallel 1;✅ 병렬도를 지정해서 인덱스를 생성한 이유는 인덱스를 빠르게 생성하려고 이다. 병렬도를 다시 1로 변경해주어야 하는데 그렇지 않으면
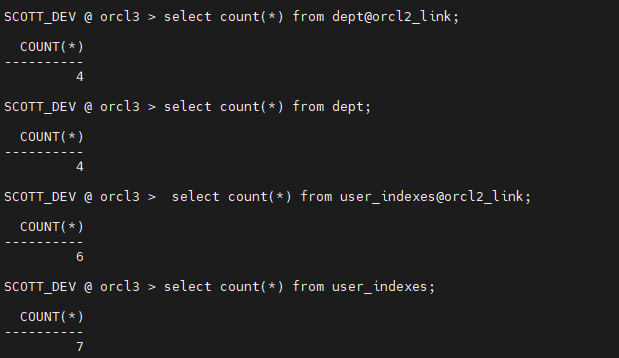
옵티마이저가 full table scan 보다는 무조건 인덱스 스캔을하려고 하는 실행계획이 나온다.-- 잘 바뀌었는지 확인하는 방법 select index_name, degree from user_indexes;10. 양쪽의 데이터와 인덱스의 갯수가 같은지 확인합니다. (db link 만들기)
orcl3 $ lsnrclt status--리스너 상태 확인 SYS @ orcl3> grant create database link to scott_dev;--진행했음 SCOTT_DEV @ orcl3 > create database link orcl2_link connect to scott identified by tiger using 'edydr1p0.us.oracle.com:1521/orcl2'; SCOTT_DEV @ orcl3 > select count(*) from dept@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from dept; SCOTT_DEV @ orcl3 > select count(*) from user_indexes@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from user_indexes;

2. contraint=n / indexes=y 옵션을 사용해서 스크립트 생성
✔️ 0, 1번은 orcl2, 나머지는 orcl3에서 진행
0. hr 계정의 데이터를 스키마 단위로 export합니다.
1. hr의 테이블 생성스크립트를 뽑아냅니다. (contraint=n)
2. hr3에서 1번에서 생성한 스크립트를 돌립니다.
3. hr의 dump 파일을 hr3로 import 합니다.
4. hr3에서 인덱스를 생성합니다.
5. hr3에 제약을 생성합니다.
➡️ 그냥 export / import와 어떤 차이가 있냐면, 인덱스와 제약을 나중에 생성하는것을 확인할 수 있다.
✔️ 0번은 orcl2, 나머지는 orcl3에서 진행
0. hr 계정의 데이터를 스키마 단위로 export합니다.$ exp system/oracle file=hr.dmp owner=hr1. hr의 테이블 생성스크립트를 뽑아냅니다. (contraint=n)
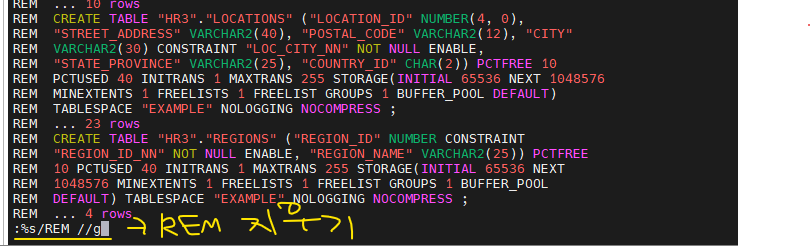
SYS @ orcl3> create user hr3 identified by tiger; SYS @ orcl3> grant connect, resource to hr3; SYS @ orcl3> create user oe identified by oe; SYS @ orcl3> grant connect, resource to oe; $ imp system/oracle file=hr.dmp fromuser=hr touser=hr3 indexes=n constraints=n indexfile=hr_table.sql✅ 위 명령어는 진짜 임포트를 하는게 아니라 테이블 생성 스크립트를 만드는 것이다! indexes=n contraints=n 으로 했기때문에 index 생성 스크립트나, contraints 생성 스크립트를 생성하지 않고 테이블 생성 스크립트만 만드는 것이다.
:%s/REM //g
2. hr3에서 1번에서 생성한 스크립트를 돌립니다.
$ vi hr_table.sql -- 안에 내용 위처럼 편집 HR3 @ orcl3 > @/home/oracle/hr_table.sql HR3 @ orcl3 > select index_name from user_indexes; INDEX_NAME ------------------------------ COUNTRY_C_ID_PK --하나만 있다. no 했는데도 만들어진거보면 중요한 애 일듯! 이정도는 괜찮다.3. hr의 dump 파일을 hr3로 import 합니다.
$ imp system/oracle file=hr.dmp ignore=y indexes=n fromuser=hr touser=hr3 HR3 @ orcl3 > exec dbms_stats.gather_schema_stats('HR3'); HR3 @ orcl3 > select table_name from user_tables;⭐
ignore=y는 데이터를 임포트 할 때 기존에 테이블이 이미 존재하면 무시하고 data만 입력하겠다!라는 것이다. 테이블 없으면 임포트하고 있으면 데이터만 입력..4. hr3에서 인덱스를 생성합니다. -> vi로 열면 주석처리(REM)되어있는건 아까 만든거라서 이번에는 안지워도 된다.
NOLOGGING;뒤에 parallel 4 를 붙여줘야한다.:%s/NOLOGGING /NOLOGGING parallel 4 /g
: ⭐️ 아래 보면indexes=y이거 있음!$ imp system/oracle file=hr.dmp indexes=y constraints=n fromuser=hr touser=hr3 indexfile=hr_index.sql $ vi hr_index.sql --편집 HR3 @ orcl3 > @/home/oracle/hr_index.sql HR3 @ orcl3 > select index_name from user_indexes; --orcl3(19개)5. hr3에 제약을 생성합니다.
select constraint_name from user_constraints; --orcl3(34개)6. 다시 인덱스의 병렬도를 4에서 1로 변경
HR3 @ orcl3 > select ' alter index ' || index_name || ' parallel 1; ' from user_indexes; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index REG_ID_PK parallel 1; alter index LOC_ID_PK parallel 1; alter index LOC_CITY_IX parallel 1; alter index LOC_STATE_PROVINCE_IX parallel 1; alter index LOC_COUNTRY_IX parallel 1; alter index JHIST_EMP_ID_ST_DATE_PK parallel 1; alter index JHIST_JOB_IX parallel 1; alter index JHIST_EMPLOYEE_IX parallel 1; alter index JHIST_DEPARTMENT_IX parallel 1; alter index JOB_ID_PK parallel 1; alter index EMP_EMAIL_UK parallel 1; 'ALTERINDEX'||INDEX_NAME||'PARALLEL1;' -------------------------------------------------------- alter index EMP_EMP_ID_PK parallel 1; alter index EMP_DEPARTMENT_IX parallel 1; alter index EMP_JOB_IX parallel 1; alter index EMP_MANAGER_IX parallel 1; alter index EMP_NAME_IX parallel 1; alter index DEPT_ID_PK parallel 1; alter index DEPT_LOCATION_IX parallel 1; alter index COUNTRY_C_ID_PK parallel 1; 19 rows selected. SQL> select index_name, degree from user_indexes;⭐ orcl2, orcl3간의 3가지 데이터의 일치성을 확인해야 한다.
- orcl2, orcl3간의 hr 계정의 테이블 갯수와 건수 확인 - 일치했다!
HR @ orcl2 > select table_name from user_tables; TABLE_NAME ------------------------------ COUNTRIES JOB_HISTORY EMPLOYEES JOBS DEPARTMENTS LOCATIONS REGIONS 7 rows selected.
- orcl2, orcl3간의 hr 계정의 인덱스 갯수 확인 - 일치했다.
- orcl2, orcl3간의 hr 계정의 제약 갯수 확인 - 일치했다.
❗️참고 (테이블 생성 스크립트 생성 쿼리)
실습중에 테이블이 생성이 안된것을 확인했는데 안에 데이터가 없으면 orcl3쪽으로 넘어오지 않는것을 확인했다. 이럴 경우 그냥 해당 테이블만 만들어주었다.
✅ 테이블 생성 스크립트 뽑아내는 쿼리
: 이 쿼리는 orcl2에서 돌리기때문에 유저네임과 테이블스페이스가 orcl2꺼로 나온다. 그래서 orcl3에서 받을 유저이름, 테이블 스페이스로 변경해주어야 한다. ts는 orcl3에 있는걸로 ? orcl2, orcl3과 같은거?? 로 해주었음
select dbms_metadata.get_ddl('TABLE', table_name) || ';'
from dba_tables
where owner='SH';
select dbms_metadata.get_ddl('SALES_TRANSACTIONS_EXT', table_name) || ';'
from dba_tables
where owner='SH';
✅ 위처럼 변경해준 후에 orcl3에서 테이블만 생성해줌.
