
오늘의 TIL
- MERGE
- DICTIONARY 사용하기(컬럼명확인, 머지문만들기)
- 락(LOCK) 이해하기
- LOCK HOLDER, WAITER찾는 쿼리문
- KILL 시키기
- SELECT FOR UPDATE절 이해하기
- 서브쿼리를 사용해서 데이터 입력하기
- 서브 쿼리를 사용하여 데이터 수정하기
<7월 7일 점심시간 문제>

hr 계정의 employees 테이블을 다음과 같이 백업합니다.
create table employees_backup
as
select * from employees;그리고 update 문을 이용해서 employees_backup 테이블의 데이터 일부를 수정합니다.
수정은 여러분들이 마음껏 수정하시면 됩니다.

수정할때 not null 걸려있는 애들은 null 로 못바꿈
그리고 짝꿍의 employees_backup 테이블과 나의 employees_backup 테이블의 데이터의 차이를 확인합니다.
차이가 나는 데이터가 무엇인지 확인하세요. 양쪽으로 다 확인하세요 !
(minus 두가지 경우로 다 써서 확인해보기)
복습 (delete, merge)
merge문은 특정 테이블에 insert, update, delete를 한번에 수행하는 명령어입니다.
문제 466.
운영 db와 테스트db가 여러분들 컴퓨터에 하나의 db에 있다고 가정하고 하기 위해서
두개의 테이블을 아래와 같이 생성하세요
- 운영 db 테이블
create table operate_emp as select * from emp;
- 테스트 db 테이블
create table test_emp as select * from emp;
문제 467. test_emp테이블에서 직업이 SALESMAN 과 MANAGER 인 사원들의 데이터를 지우시오
delete from test_emp where job in ('SALESMAN','MANEGER') ;
문제 468. test_emp 테이블에서 직업이 ANALYST 와 CLERK 인 사원들의 월급을 0 으로 변경하시오
update test_emp set sal = 0 where job in ('ANALYST','CLERK');commit;
merge 참고하기
문제 469. (성해보여주기)
operate_emp 테이블로 test_emp 테이블을 merge 하는데,
operate_emp 테이블에는 존재하는 데이터인데 test_emp 테이블에는 존재하지 않는 데이터는 test_emp 테이블에 입력하고,
양쪽 다 존재하는데 데이터가 틀리면 operate_emp 의 데이터로 test_emp 에 업데이트하시오 (?)merge into test_emp t using operate_emp o on ( t.empno = o.empno ) -> 연결고리 (join 조건) when matched then -> 연결고리에 의해서 매치된다면 update set t.sal = o.sal -> 월급을 업데이트해라 t.comm = o.comm (이런식으로 여러개도 쓸 수 있음!) when not matched then -> empno가 매치되지 않는건, insert (t.empno, t.ename, t.job, t.sal, t.comm, t.hiredate, t.mgr, t.deptno ) values (o.empno, o.ename, o.job, o.sal, o.comm, o.hiredate, o.mgr, o.deptno ); -> test 데이터에 operate 데이터를 입력해라
- 다소 문법이 복잡해보이지만 성능이 좋아서 merge 문을 많이 사용한다.
- truncate 시키고 다시 가져오는 것보다는 merge로 몇개씩 바꾸는게 더 낫다.
-
지금은 sal 이 다르다는걸 알아서 t.sal=o.sal 이렇게 쓰는데 만약 어떤 데이터가 다른지 모른다면, 아예 모든 데이터를 다 써줘도 된다. 그러면 자기가 알아서 검색 해본다음에 업데이트 시킨다.
t.sal=o.sal t.comm=o.comm...문제 470.
우리반 테이블을 emp17_backup 으로 백업하세요.create table emp17_backup as select * from emp17;rownum 활용해서 데이터 정리
문제 471.
emp17 테이블의 데이터를 아래와 같이 지우시오delete from emp17 where rownum < 10; commit; -
백업과 본 테이블을 맞춰주려면, 가장 간단한 방법은 truncate 하고 불러오는게 간단하긴 하지만, 데이터가 많다면 너무 오래걸리기 때문에 merge 하는게 좋다.
문제 472. (요거 꼭 확인해보삼삼)
emp17_backup 의 내용으로 emp17의 데이터를 merge 하시오
(같은 데이터라면 update 하고, 없으면 insert 하시오)merge into emp17_ e using emp17_backup s on ( e.empno = s.empno ) when matched then update set e.ename = s.ename, e.gender = s.gender, e.birth = s.birth, e.age = s.age, e.telecom = s.telecom, e.email = s.email, e.major = s.major, e.address = s.address when not matched then insert (e.empno, e.ename, e.gender, e.birth, e.age, e.telecom, e.email, e.major, e.address ) values (s.empno, s.ename, s.gender, s.birth, s.age, s.telecom, s.email, s.major, s.address );
- empno 는 위에 매치조건이기때문에 update 에 안써줌 (이미 매치가 되어야 이게 작동한다는 조건이기 때문에, 매치가 된다는 가정하임!!)
-> on 절에 쓴거는 update 에 쓰면 오류남!
문제 473.
이번에는 emp17 테이블을 truncate 시키고 emp17backup 으로 데이터를 입력하시오
(truncate 는 조심해서 써야함,,,ㅠㅠ)truncate table emp17; insert into emp17 select * from emp17_backup;
- merge 하려는 2개의 테이블 사이의 데이터의 변경의 차이가 심하고
둘다 대용량 테이블이 아니면 위의 방법truncate이 더 간단하긴함!
하지만 truncate 의 부담감이 있음
-> 일반 개발자들은 DBA 한테 truncate 의 권한을 안주는 경우가 많음
문제 474. market_2022 테이블을 백업하세요
create table market_2022_backup as select * from market_2022;
문제 475. market_2022 테이블의 데이터를 일부 지우시오
(대용량 테이블이라 시간 좀 걸릴것)delete from market_2022 where rownum < 156405; commit;
문제 476. market_2022 테이블의 상호명을 전부 null 로 변경하시오
update market_2022 set 상호명 = null ; commit;
문제 477. market_2022 테이블의 데이터를 market_2022_backup 테이블의 데이터로 merge 하시오 (밑에 하는 방법 적어놓음)
merge into market_2022 a using market_2022_backup b on ( a.상가업소번호 = b.상가업소번호 ) when matched then update set a.상호명=b.상호명, a.지점명=b.지점명, a.상권업종대분류코드=b.상권업종대분류코드, a.상권업종대분류명=b.상권업종대분류명, a.상권업종중분류코드=b.상권업종중분류코드, a.상권업종중분류명=b.상권업종중분류명, a.상권업종소분류코드=b.상권업종소분류코드, a.상권업종소분류명=b.상권업종소분류명, a.표준산업분류코드=b.표준산업분류코드, a.표준산업분류명=b.표준산업분류명, a.시도코드=b.시도코드, a.시도명=b.시도명, a.시군구코드=b.시군구코드, a.시군구명=b.시군구명, a.행정동코드=b.행정동코드, a.행정동명=b.행정동명, a.법정동코드=b.법정동코드, a.법정동명=b.법정동명, a.지번코드=b.지번코드, a.대지구분코드=b.대지구분코드, a.대지구분명=b.대지구분명, a.지번본번지=b.지번본번지, a.지번부번지=b.지번부번지, a.지번주소=b.지번주소, a.도로명코드=b.도로명코드, a.도로명=b.도로명, a.건물본번지=b.건물본번지, a.건물부번지=b.건물부번지, a.건물관리번호=b.건물관리번호, a.건물명=b.건물명, a.도로명주소=b.도로명주소, a.구우편번호=b.구우편번호, a.신우편번호=b.신우편번호, a.동정보=b.동정보, a.층정보=b.층정보, a.호정보=b.호정보, a.경도=b.경도, a.위도=b.위도 when not matched then insert (a.상가업소번호,a.상호명,a.지점명,a.상권업종대분류코드,a.상권업종대분류명,a.상권업종중분류코드,a.상권업종중분류명,a.상권업종소분류코드,a.상권업종소분류명,a.표준산업분류코드,a.표준산업분류명,a.시도코드,a.시도명,a.시군구코드,a.시군구명,a.행정동코드,a.행정동명,a.법정동코드,a.법정동명,a.지번코드,a.대지구분코드,a.대지구분명,a.지번본번지,a.지번부번지,a.지번주소,a.도로명코드,a.도로명,a.건물본번지,a.건물부번지,a.건물관리번호,a.건물명,a.도로명주소,a.구우편번호,a.신우편번호,a.동정보,a.층정보,a.호정보,a.경도,a.위도 ) values (b.상가업소번호,b.상호명,b.지점명,b.상권업종대분류코드,b.상권업종대분류명,b.상권업종중분류코드,b.상권업종중분류명,b.상권업종소분류코드,b.상권업종소분류명,b.표준산업분류코드,b.표준산업분류명,b.시도코드,b.시도명,b.시군구코드,b.시군구명,b.행정동코드,b.행정동명,b.법정동코드,b.법정동명,b.지번코드,b.대지구분코드,b.대지구분명,b.지번본번지,b.지번부번지,b.지번주소,b.도로명코드,b.도로명,b.건물본번지,b.건물부번지,b.건물관리번호,b.건물명,b.도로명주소,b.구우편번호,b.신우편번호,b.동정보,b.층정보,b.호정보,b.경도,b.위도 );
많은 merge 문 만드는 방법 (dictionary 사전 활용)☆☆☆
(문제 477 해설)
1. 먼저 column 리스트를 알아야한다. (다 써야하는데 일일히 하나하나 쓰긴 복잡하니까)
select * from dictionary where table_name like '%DBA%TAB%COLUMN%'; (대문자로!!)-> 사전 리스트 중에 column 을 포함하고 있는 사전들을 보여달라는 문법

-> 유저 테이블의 컬럼들을 보여준다는 사전
그 다음,
select column_name
from dba_tab_columns
where table_name='MARKET_2022';위의 사전이름을 from 에 쓰면
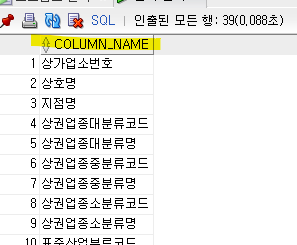
라고 컬럼 이름이 쭉 뜬다.
2. 연결연산자로 update 문법 만들어주기
select 'a.' || column_name || '=' || 'b.' || column_name || ',' from dba_tab_columns where table_name='MARKET_2022';
연결연산자 사용해서, 'update set' 에 들어갈 업데이트 될 컬럼문을 만들어준다.
이중에서 상가업소번호는 빼기~! 맨 마지막 ',' 도 빼기!

3. 연결연산자 + listagg 사용해서 insert 문법 만들어주기
그다음 insert 문 ( , , , ) 만들기
select 'a.' || column_name || ','이렇게 해도 되지만 보기 안좋아서,
listagg사용하기select listagg ('a.' || column_name ,',') from dba_tab_columns where table_name='MARKET_2022';
그다음 b 도 똑같이 만들어줘야함select listagg ('b.' || column_name ,',') from dba_tab_columns where table_name='MARKET_2022';


4. 구한 정보들 입력하기
그리고 merge 문에 하나씩 입력하면 됨!
merge into test_emp t using operate_emp o on ( t.empno = o.empno ) -> 연결고리 (join 조건) when matched then -> 연결고리에 의해서 매치된다면 update set t.sal = o.sal -> 월급을 업데이트해라 t.comm = o.comm (이런식으로 여러개도 쓸 수 있음!) when not matched then -> empno가 매치되지 않는건, insert (t.empno, t.ename, t.job, t.sal, t.comm, t.hiredate, t.mgr, t.deptno ) values (o.empno, o.ename, o.job, o.sal, o.comm, o.hiredate, o.mgr, o.deptno ); -> test 데이터에 operate 데이터를 입력해라

※ 위와 같이 dba_ 로 시작하는 테이블들이 바로 데이터 사전 관련한 테이블들 입니다.
문제 478. c##scott 유저가 소유하고 있는 테이블 리스트를 확인하시오
select * from user_tables;
3가지 사전 활용법
user_tables: c##scott 유저가 소유하고 있는 테이블 리스트를 확인all_tables: c##scott 유저가 소유하고 있는 테이블 + 엑세스 권한 받은 테이블들 확인dba_tables: db에 있는 모든 테이블 리스트를 다 확인 (only dba 의 사전)
-
뒤에 tables 를 붙인곳에 다른거 넣어서 다르게 활용할 수 있음!!
ex) dbatab_columns, user어쩌구
1) user_tab_columns : c##scott 유저가 소유하고 있는 테이블들의 컬럼정보를 확인하는 사전
2) all_tab_columns : c##scott 유저가 소유하고 있는 테이블 + 엑세스 권한 받은 테이블들의 컬럼정보를 확인하는 사전
3) dba_tab_columns : db에 있는 모든 테이블들의 컬럼정보 확인하는 사전
-
위의 데이터 사전들이 뭐가 있는지 외울 필요는 없고!!
아래의 쿼리를 조회해서 필요한 사전들을 찾아냅니다.select * from dictionary where table_name like '%보고싶은키워드를 대문자로%'ex. 컬럼정보가 보고싶다면,
select * from dictionary where table_name like '%COLUMN%'ex2. db를 포함하고, tab을 포함하고, column 을 포함하는 데이터 사전을 보여줘!
->select * from dictionary where table_name like '%DB%TAB%COLUMN%' -
% 로 연결해서 쭉쭉 써주면 됨
※ 위와 같이 merge 문을 이용하지 않는다면,
다른 방법으로 두 테이블 사이에 데이터의 일치를 맞춰주는 SQL이 뭐가 있는가?
-> 상호관련 서브쿼리를 사용한 update 문 (악성 sql임, 성능 bad 인데 개발자들이 많이씀)
(오후에 설명해주시기로)
락(LOCK) 이해하기
lock? 세션(유저)이 특정 데이터를 수정하게 되면 commit;하기 전까지 수정한 행(row)에 lock을 겁니다.
특정 세션이 변경한 데이터를 다른 세션이 변경하지 못하도록 막는 기능!
lock이 없다면 데이터의 일관성이 깨집니다.
A session B session
(C##SCOTT) (C##SCOTT)1. update emp set sal = 9000 where ename = 'KING'; -> 2. update emp set sal = 0 where ename = 'KING'; commit; select ename, sal from emp; A세션에서 9000으로 업데이트했는데, B에서 0으로 수정후에 커밋을 해버린다면, A session 에서 sal은 0이 보일것이다. 이런 상황을 대비하여 lock!
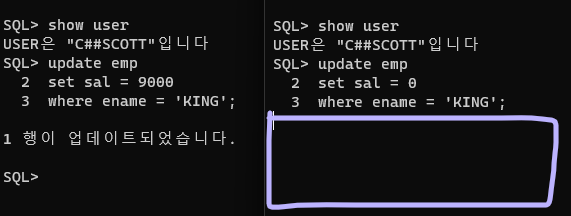
- 오른쪽은 lock이 걸려서 아무것도 안된다.
-> 왼쪽 세션에서 commit;을 하게되면 락이 풀리고 오른쪽에 업데이트 되었다고 나온다.
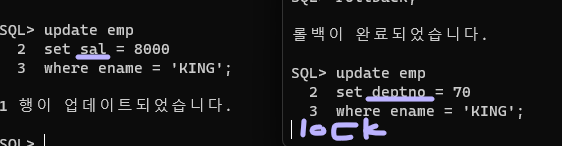
- SAL과 DEPTNO 이렇게 다른 컬럼을 수정하려고 해도 락걸린다. 행이 기준이기 때문 !!
- 만약 왼쪽 세션이 커밋을 계속 안한다? 혹은 프로그램내에서 사용한다면 킬 시킬 수 있음.
LOCK HOLDER, WAITER찾는 쿼리문
select decode(status,'INACTIVE',username || ' ' || sid || ',' || serial#,'lock') as Holder, decode(status,'ACTIVE', username || ' ' || sid || ',' || serial#,'lock') as waiter, sid, serial#, status from( select level as le, NVL(s.username,'(oracle)') AS username, s.osuser, s.sid, s.serial#, s.lockwait, s.module, s.machine, s.status, s.program, to_char(s.logon_TIME, 'DD-MON-YYYY HH24:MI:SS') as logon_time from v$session s where level>1 or EXISTS( select 1 from v$session where blocking_session = s.sid) CONNECT by PRIOR s.sid = s.blocking_session START WITH s.blocking_session is null);
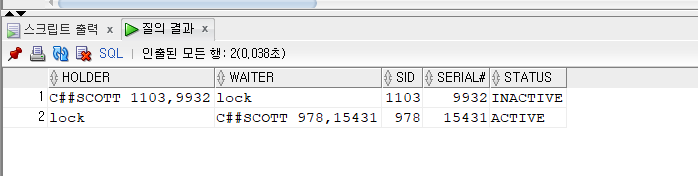
KILL 시키기
ALTER SYSTEM KILL SESSION '1103,9932'; (sid),(시리얼#)
- 죽었슴다..!
정리!
우리가 테이블의 데이터를 update하면, lock이 행단위로 걸린다. 그리고 반드시 db에 수정 작업을 했으면, 꼭 commit을 해서 마무리를 해야한다. 그렇지 않으면 다른 세션들이 lock에 걸리게 됨!
문제 479. 아래와 같이 c##scott 세션을 2개를 열고 update를 수행하세요!
c##scott(A session) c##scott(B session)
>
1. update emp
set sal = 9000
where job = 'SALESMAN' 2. update emp
set sal = 0
where ename = 'MARTIN';문제 480. 이번에는 holder 말고 waiter 죽이기
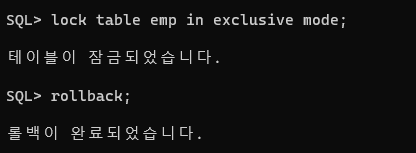
문제 481. 테이블 전체에 lock 걸기
lock table emp in exclusive mode;
- rollback 하면 풀린다!
문제 482. c##scott 유저로 3개의 세션을 열고 다음과 같이 update 하시오
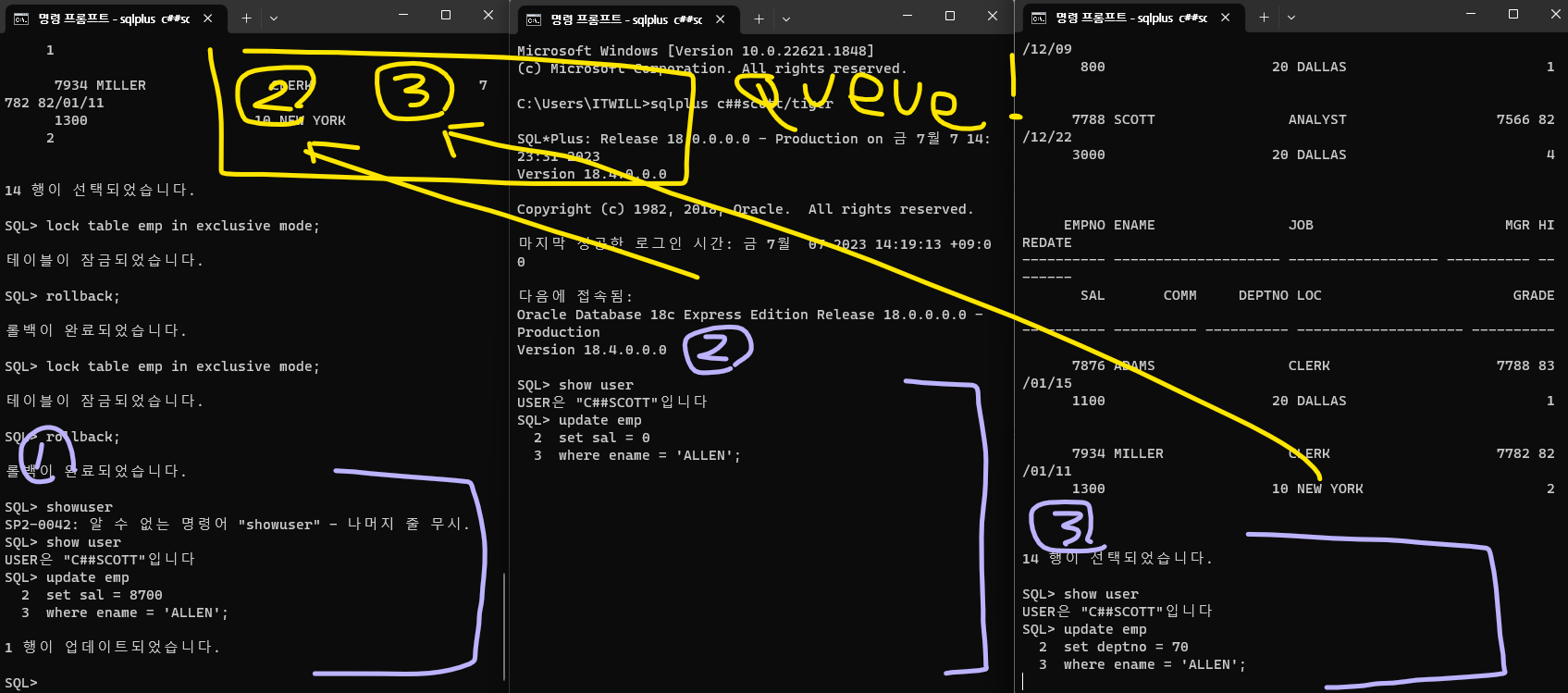
- 1번 세션에서 update하면서 락이걸리고 2,3번이 인큐(큐에 들어감)
- 커밋을 하는순간 2번 세션이 디큐 (큐에서나옴)되고, 3번은 대기!
SELECT FOR UPDATE절 이해하기
lock은 update문을 수행할 때 update를 하려는 행들에 자동으로 lock이 걸리게 되는데, select를 할 때도 lock을 걸 수 있다.
보통은 select할 때는 lock이 걸리지 않는다!
근데, 지금 당장 이시점에 특정 테이블의 데이터를 집계해야해서 그 누구도 내가 select 한 데이터를 수정하지 못하게 해야한다면????????????????? 쓰면 됩니다. SELECT FOR UPDATE
A B 1. select ename, sal 2. update emp from emp set sal = 0 where job = 'SALESMAN' where ename = 'MARTIN'; for update;
- 1번이 update가 아니고 select 일때도 락을 할 수 있고, commit을 해주어야 풀린다.
문제 483. 위의 작업을 다시한번 수행하고, sql디벨로퍼 창에서 락홀더와 웨이터를 확인하기
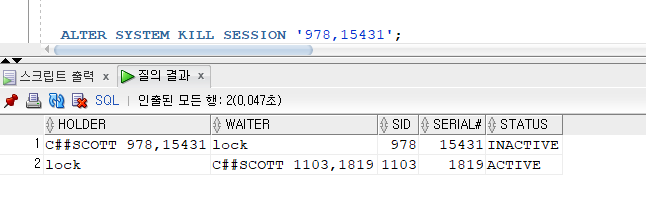
도구 > 세션모니터 들어가도 확인가능. 여기서도 킬 가능!
inactive가 홀더라서 이넥티브에서 오른쪽 마우스 누르면 세션종료가 나온다.
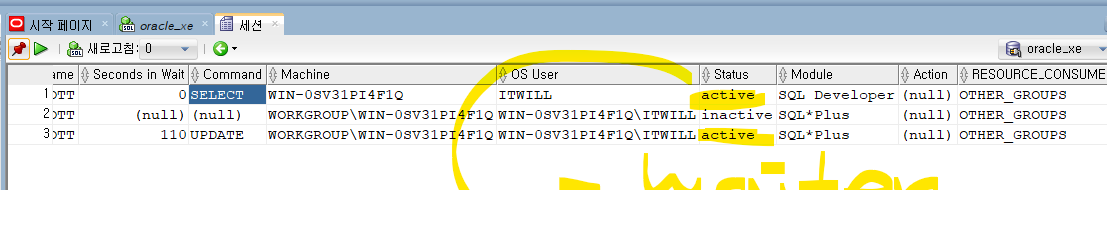
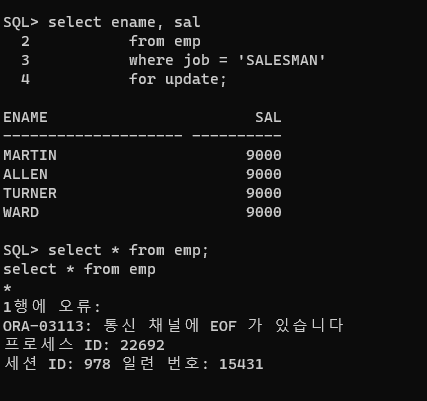
- 확인해보면 , holder가 죽었습니다!
서브쿼리를 사용해서 더이터 입력하기
서브쿼리를 사용한 insert문은 data이행(데이터 마이그레이션)할 때 사용하는 SQL입니다.
예제1. 아래의 테이블을 생성하세요
create table emp900 (empno number(10), ename varchar2(10), sal number(10) );
예제2. emp900 테이블에 아래의 데이터를 입력하시오!
사원번호 : 9384
사원이름 : JACK
월급 : 3000INSERT INTO EMP900(empno, ename, sal) values(9384,'JACK',3000);
예제3. 서브쿼리를 사용한 insert문으로 사원 테이블의 직업이 SALESMAN인 사원들의 사원번호, 이름, 월급을 emp900에 입력하시오!
insert into emp900(empno,ename,sal) select empno,ename,sal from emp where job ='SALESMAN'; select * from emp900;
- values가 없는것이 특징!
※ 위의 서브쿼리를 사용한 insert문은 data이행(데이터 마이그레이션)할 때 사용하는 SQL입니다.
문제 484. 짝꿍의 data를 나의 db에 이행합니다.
짝꿍의 sales를 나의 db에 이행하기 위해, 먼저 sales 테이블의 구조를 생성합니다.
create table my_sales as select * from sales where 1 = 2;
- where 절에 1=2때문에 데이터는 못가져오고 테이블 구조만 생성한다.
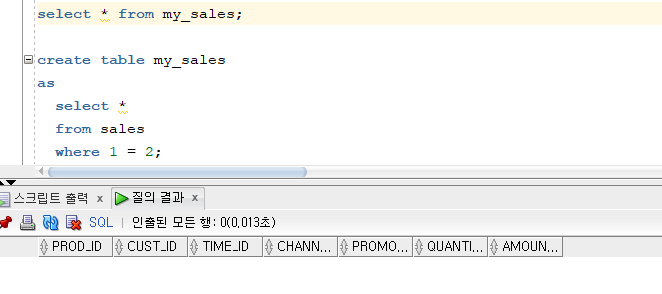
문제 485. 짝꿍의 sales 테이블의 데이터를 나의 my_sales테이블로 이행
insert into my_sales select * from sh.sales@dblinkjh;
- 지금은 예제라서 그냥 다 똑같이 받아왔는데, 실무에서는 아래처럼 암호화해서 받아오거나 수정을 좀 해서 가져오는 경우가 많다.
insert into my_sales select empno, ename,regexp_replace(jumin,'[0-9]','*'), ..... // 주민번호 *표처리 한것. from sh.sales@dblinkjh;

서브 쿼리를 사용하여 데이터 수정하기
※ update문에서 서브쿼리를 쓸 수 있는 절
update ---> 서브쿼리 가능
set ---> 서브쿼리 가능
where ---> 서브쿼리 가능
1. update문의 where절 서브쿼리
문제 486. 사원테이블에 ALLEN보다 늦게 입사한 사원들의 월급을 9000으로 변경하시오!
update emp set sal = 9000 where hiredate > (select hiredate from emp where ename='ALLEN');
문제 487. SCOTT과 같은 부서번호에서 일하는 사원들의 월급을 8000으로 수정
update emp set sal = 8000 where deptno = (select deptno from emp where ename = 'SCOTT');
문제 488. KING의 월급을ALLEN의 월급으로 변경
update emp set sal = (select sal from emp where ename = 'ALLEN') where ename = 'KING';
문제 489. king의 부서번호를 james의 부서번호로 변경
update emp set deptno = (select deptno from emp where ename = 'JAMES') where ename = 'KING';
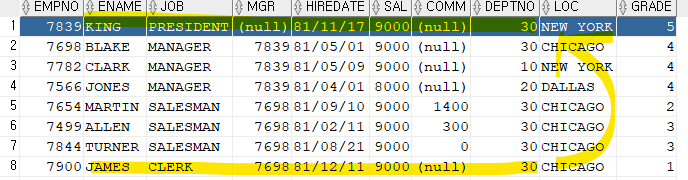
문제 490. emp테이블에 loc 컬럼을 추가하세요
alter table emp add loc varchar2(10);
상호관련 서브쿼리 update문
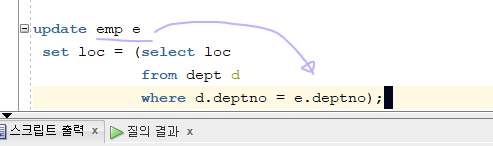
문제 491. 지금 추가한 loc컬럼에 해당 사원의 부서위치로 값을 생성하기(어제 merge로 수행했던 것 말고 상호관련 서브쿼리를 이용한 update문으로 수행 )
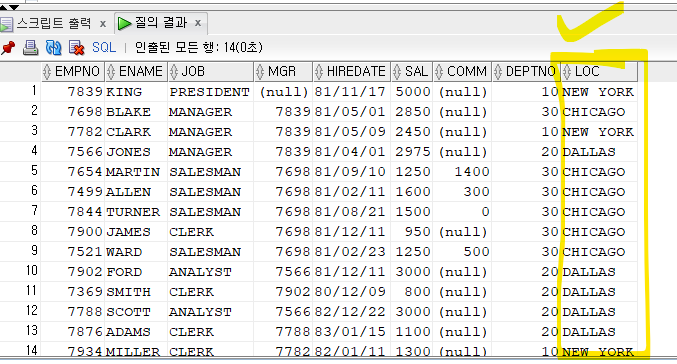
update emp e set loc = (select loc from dept d where d.deptno = e.deptno);
- 킹의 부서번호 10번이 들어가면, 킹부서번호(10번)에 대한 부서위치가 갱신되고, 20번이 들어가면 DALLAS가 갱신되고....... 14건
- 다시 설명하면 emp테이블의 부서번호가 set 절의 서브쿼리에 하나씩 들어가면서 하나씩 갱신하기 때문에 시간이 많이 걸린다 !
※ 컬럼 드롭하기
alter table emp
drop column loc; -> 부서위치 컬럼 없어짐문제 492. 사원 테이블에 deptavg라는 컬럼 추가
alter table emp add deptavg number(10,2);
문제 493. deptavg 컬럼에 값을 갱신하는데, 해당 사원이 속한 부서번호의 평균월급으로 값을 갱신!
update emp e set deptavg = (select avg(sal) from emp s where s.deptno = e.deptno);
- 이거 악성SQL임! 튜닝해야함.
문제 494. 위 SQL을 MERGE를 사용하여 튜닝합시다! (상호관련 서브쿼리 -> merge)
merge into emp e using (select deptno, avg(sal) as 부서평균 from emp group by deptno ) v // table명 대신 쿼리문 씀 on (e.deptno = v.deptno) when matched then // matched가 된다면, update set e.deptavg = v.부서평균; // v.부서평균을 e.deptavg 로 가져온다.
- using절 테이블명 자리에 sql을 테이블처럼 쓰고, 테이블명을 v라고 한것.
문제 495. emp 테이블에 grade 컬럼을 추가하기
alter table emp add grade number(10);
문제 496. salgrade테이블을 사용하여 emp테이블의 grade 컬럼을 merge 하는데, 해당 사원의 급여등급으로 값을 merge 하세요
튜닝 후
merge into emp e using salgrade s on ( e.sal between s.losal and s.hisal) when matched then update set e.grade = s.grade;
문제 497. 위 merge문을 상호관련 서브쿼리를 사용한 update문으로 작성(악성SQL)
튜닝 전
update emp e set grade = (select grade from salgrade s where e.sal between s.losal and s.hisal);내 실수
update emp e set grade = (select grade from salgrade s where e.grade = s.grade); // 여기 조인조건 잘못 씀
문제 498. merge문이 튜닝후SQL임을 증명하기 위해서 대용량 테스트 테이블을 다음과 같이 생성하세요
create table sales100 as select rownum as num, amount_sold from sales;
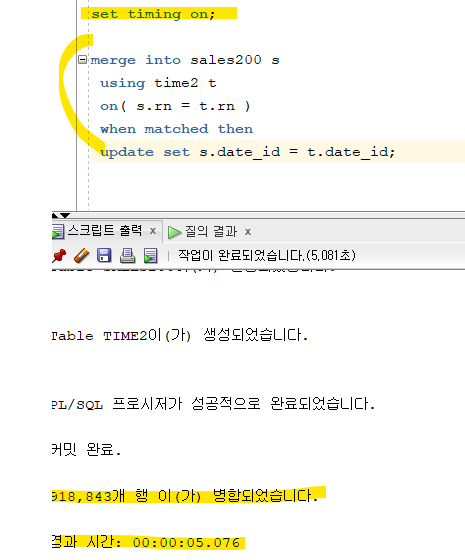
문제 499. time2테이블을 사용하여 sales200테이블의 date_id로 갱신하기.
튜닝후 (merge) 먼저하기 (더 빠름)
-- 실습 환경만들기 create table sales100 as select * from sh.sales; create table sales200 as select rownum rn, prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold from sales100; alter table sales200 add date_id date; create table time2 ( rn number(10), date_id date ); begin for i in 1 .. 918843 loop insert into time2 values( i , to_date('1961/01/02','YYYY/MM/DD')+ i ); end loop; end; / commit;
- sales200테이블에 date_id 가 비어있다.
merge into sales200 s using time2 t on( s.rn = t.rn ) when matched then update set s.date_id = t.date_id;
문제 500. 위 튜닝 후 코드를 튜닝전 SQL을 작성하기(상호관련 서브쿼리 업데이트문)
update sales200 s set date_id = (select date_id from time2 t where s.rn = t.rn);
