
✔️ 스케줄러의 종류 2가지?
- time base 스케줄러 : 특정 시간에 특정 작업이 수행되도록
- event base 스케줄러 : 특정 이벤트가 발생하면 특정 작업이 수행되도록
내부 : 오라클 프로시저 또는 쉘을 자동화(예: 매일 밤에 도는 배치 프로그램)
외부 : 엑셀 메크로, 파이썬의 자동화
✅ dba 의 일 중에서 컬럼 추가가 있다.
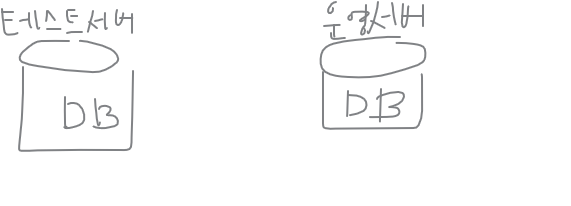
alter table emp
add email varchar2(100);
테스트 서버(개발서버) 운영서버
select *
from emp
where ename='SCOTT';운영서버에서 파싱된 정보가 shared pool 공유 메모리에 올라와있다. 그런데 컬럼 추가를 날리는 순간 shared pool에 있는 메모리들이 없어진다. 그러면 나중에 또 파싱을 해줘야해서 느려지게 되므로 운영중에는 dba들이 낮에 컬럼추가, 변경을 해주면 안된다.
➡️ 밤에 하느냐?? 낮에 스케줄을 만들고 밤에 돌린다.
✔️ 다시 정리!
테이블에 컬럼을 추가하게 되면 해당 테이블을 select하는 많은 select 문장이 공유풀에서 전부 Invalid 되어 버립니다. 그렇게되면 성능이 떨어진다.
✏️ 컬럼추가 스케줄
실습 Time Base Scheduler 입니다!
1. 프로그램을 생성한다.
: begin, end 사이에 넣어준다 ! execute 써서 사용해도 되지만 길어서 사이에 넣어준 것.SCOTT> begin dbms_scheduler.create_program( program_name=>'scott_alter_prog3', program_type=>'PLSQL_BLOCK', program_action=>'begin execute immediate ''alter table emp add email varchar2(50)''; end;'); end; /⭐ Program type이 3가지가 있다.
✔️ 익명pl/sql 이라면PLSQL_BLOCK
✔️ 프로시저 라면STORED_PROCEDURE
✔️ 리눅스 쉘 이라면EXECUTABLE2. email 컬럼을 추가하는 scott_alter_prog 프로그램이 1분후에 작동되게하시오 !
SCOTT> begin dbms_scheduler.create_job( job_name=>'scott_alter_job3', program_name=>'scott_alter_prog3', start_date => sysdate + 1/24/60 ); end; /➡️
sysdate는 오늘 날짜와 현재 시간이 출력되고있다.
sysdate + 1/24는 현재 시간에서1시간 후의 시간이 나오고
stsdate + 1/24/60는 분이 되므로 현재 시간에서1분 후의 시간이다.3. enable 시키기
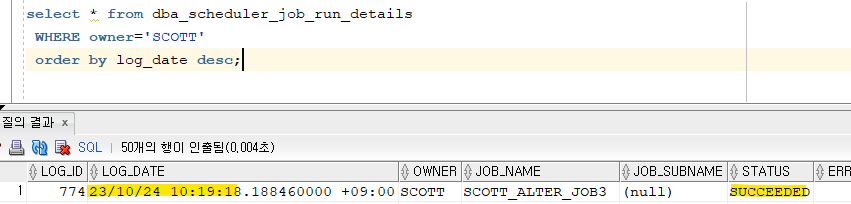
SCOTT> exec dbms_scheduler.enable('scott_alter_prog3'); SCOTT> exec dbms_scheduler.enable('scott_alter_job3');4. 스케줄 작업을 모니터링 합니다.
select * from dba_scheduler_job_run_details WHERE owner='SCOTT' order by log_date desc;
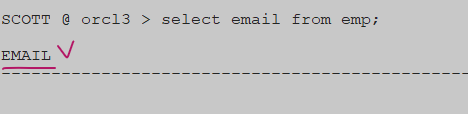
➡️dba_scheduler_job_run_details는 그동안 스케줄이 어떻게 작업이 되었는지 모니터링할 수 있다. 크론탭과 다른점!5. 추가가 잘 되었는지 확인
SCCOT> select email from emp;
문제 직업의 길이를 varchar2(9) 에서 varchar2(20)으로 늘리는 아래의 DDL 문장이 1분 후에 수행되게 하세요!
alter table emp
modify job varchar2(20);1. 프로그램을 생성한다.
: begin, end 사이에 넣어준다 ! execute 써서 사용해도 되지만 길어서 사이에 넣어준 것.SCOTT> begin dbms_scheduler.create_program( program_name=>'scott_alter_prog4', program_type=>'PLSQL_BLOCK', program_action=>'begin execute immediate ''alter table emp modify job varchar2(20)''; end;'); end; /2. job 길이를 varchar2(9) 에서 varchar2(20)으로 늘리는 아래의 DDL 문장이 1분 후에 수행되게 하세요!
SCOTT> begin dbms_scheduler.create_job( job_name=>'scott_alter_job4', program_name=>'scott_alter_prog4', start_date => sysdate + 1/24/60 ); end; /3. enable 시키기
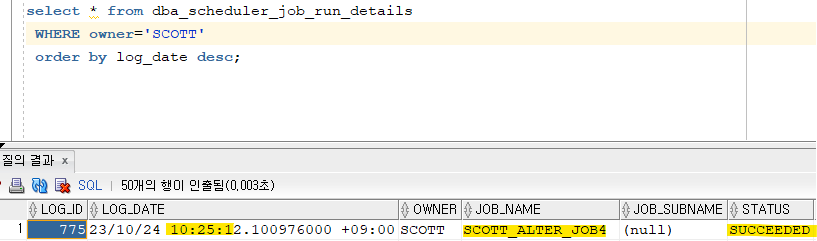
SCOTT> exec dbms_scheduler.enable('scott_alter_prog4'); SCOTT> exec dbms_scheduler.enable('scott_alter_job4');4. 스케줄 작업을 모니터링 합니다.
select * from dba_scheduler_job_run_details WHERE owner='SCOTT' order by log_date desc;
5. emp 테이블에 job 컬럼이 변경되었는지 확인
문제 emp 테이블에 address라는 컬럼을 추가하는 프로시저를 생성하기
create or replace procedure add_address is begin execute immediate 'alter table emp add address varchar2(100)'; end; / exec add_address; desc emp;
문제 다시 emp 테이블의 address 컬럼 삭제
SCOTT @ orcl3 > alter table emp drop column address;
Table altered.문제 아까 만든 add_address 프로시저가 1분 후에 수행될 수 있도록 프로그램과 잡을 만드세요 (job 하면서 스케줄 같이 생성 가능)
1. 프로그램 생성
SCOTT> begin dbms_scheduler.create_program( program_name=>'scott_add_address_prog', program_type=>'STORED_PROCEDURE', program_action=>'add_address'); end; /2. 작업(job) 생성
SCOTT> begin dbms_scheduler.create_job( job_name=>'scott_add_address', program_name=>'scott_add_address_prog', start_date => sysdate + 1/24/60 ); end; /3. 작업, 프로그램 enable 시키기
SCOTT> exec dbms_scheduler.enable('scott_add_address'); SCOTT> exec dbms_scheduler.enable('scott_add_address_prog');4. 결과 확인
SCOTT> desc emp;5. 스케줄이 잘 도는지 확인하시오 !
select * from dba_scheduler_job_run_details WHERE owner='SCOTT';
💡 참고!
exec dbms_scheduler.disable('scott_insert_dept');
exec dbms_scheduler.drop_program('');
exec dbms_scheduler.drop_schedule('');
exec dbms_scheduler.drop_job('');❓ 프로그램 타입 3가지?
- 익명 PL/SQL
PLSQL_BLOCK - 프로시저
STORED_PROCEDURE - 리눅스 쉘 스크립트 (풀백업 등의 쉘 스크립트 가능)
EXECUTABLE
리눅스 쉘 스크립트 실습
선행작ㄱ업!
1. 먼저 $ORACLE_HOME/rdbms/admin/externaljob.ora 파일에 대한 정보를 확인한다. -> ROOT에서 진행
[orcl3:admin]$ su - 암호: [root@edydr1p0 ~]# cd /u01/app/oracle/product/11.2.0/dbhome_1/rdbms/admin [root@edydr1p0 admin]# ls -al externaljob.ora -rw-r----- 1 oracle oinstall 1536 10월 24 11:04 externaljob.ora2. 외부 Shell을 수행하기 위한 권한에 관한 설정을 확인 및 변경해 줌
[root@edydr1p0 admin]# chmod 640 externaljob.ora [root@edydr1p0 admin]# ls -la externaljob.ora -rw-r----- 1 oracle oinstall 1536 10월 24 11:04 externaljob.ora [root@edydr1p0 admin]# cd ../../bin --빈티렉토리로 이동 [root@edydr1p0 bin]# pwd /u01/app/oracle/product/11.2.0/dbhome_1/bin [root@edydr1p0 bin]# chmod 4750 extjob [root@edydr1p0 bin]# ls -la extjob -rwsr-x--- 1 root oinstall 1076051 10월 16 2012 extjob오라클이 oinstall 그룹에 포함되어있다. 그래서 오라클이 엑스익스큐트 한 상태가됨
3. 오라클의 HR 계정에서 테스트를 수행. 이를 위해 권한을 부여해 줌[root@edydr1p0 bin]# su - oracle [orcl3:~]$ sys SQL> grant execute on sys.dbms_scheduler to hr; SQL> grant create job to hr; SQL> grant create external job to hr;4. 사용할 Shell Script의 내용을 확인함
[orcl3:~]$ vi test.sh [orcl3:~]$ vi test.sh #!/usr/bin/ksh CDATE=`date +%Y%m%d` echo $CDATE [orcl3:~]$ sh test.sh 20231024 [orcl3:~]$ ls -l test.sh -rw-r--r-- 1 oracle oinstall 48 10월 24 11:15 test.sh [orcl3:~]$ chmod 777 test.sh -- 실행할 수 있는 권한 줌 [orcl3:~]$ ls -l test.sh -rwxrwxrwx 1 oracle oinstall 48 10월 24 11:15 test.sh5. HR 계정에 스케줄러를 등록함
HR> BEGIN DBMS_SCHEDULER.CREATE_SCHEDULE(SCHEDULE_NAME => 'TEST_SCHED', START_DATE => SYSTIMESTAMP, END_DATE => NULL, REPEAT_INTERVAL => 'FREQ=MINUTELY;INTERVAL=1', COMMENTS => 'External Shell run test' ); END; /6. job만들기
HR> BEGIN DBMS_SCHEDULER.CREATE_JOB(JOB_NAME => 'TEST_JOB_1', JOB_TYPE => 'EXECUTABLE', JOB_ACTION => '/home/oracle/test.sh', SCHEDULE_NAME => 'TEST_SCHED', COMMENTS => 'TEST_EXECUTABLE'); END; /7. enable시키기
HR> BEGIN DBMS_SCHEDULER.ENABLE('TEST_JOB_1'); END; /8. 확인하기
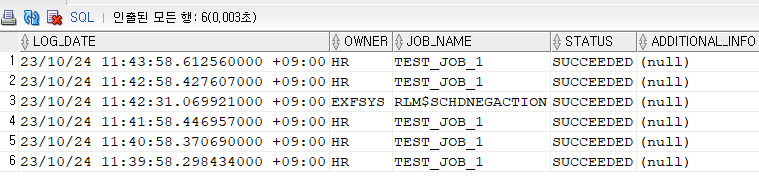
SELECT LOG_DATE ,OWNER ,JOB_NAME ,STATUS ,ADDITIONAL_INFO FROM DBA_SCHEDULER_JOB_RUN_DETAILS WHERE LOG_DATE > SYSDATE - 5/24/60 ORDER BY LOG_DATE DESC;
실패 떴음 다시하기
💡 원인!! 맨 처음에
externaljob.ora내용을 root에서 수정하지 않고 오라클에서 바꿔서 권한이 자동으로 오라클로 바뀌어있었다. root로 바꿔주기[root@edydr1p0 admin]# chown -R root:oinstall externaljob.ora [root@edydr1p0 admin]# [root@edydr1p0 admin]# ls -l externaljob.ora -rw-r----- 1 root oinstall 1536 10월 24 11:04 externaljob.ora [root@edydr1p0 admin]#
문제 TEST_JOB_1 disable, drop 시키기
HR>
BEGIN
DBMS_SCHEDULER.DISABLE('TEST_JOB_1');
END;
/
HR>
BEGIN
DBMS_SCHEDULER.DROP_JOB('TEST_JOB_1');
END;
/문제 orcl2의 데이터 파일들을 cold backup 하는 쉘을 생성하기
full.sh 있음!
cd coldbackup2_orcl2/
[orcl2:coldbackup2_orcl2]$ rm -rf *
sh full.sh -- 잘 되나 확인해보기문제 full.sh가 1분 후에 수행될 수 있도록 하시오
- full.sh의 권한중 소유자가 실행할 수 있는 권한이 있는지 확인하고 없으면 권한을 넣기
[orcl2:~]$ ls -l full.sh
-rw-r--r-- 1 oracle oinstall 725 10월 13 15:28 full.sh
[orcl2:~]$ chmod 755 full.sh -- 소유자는 읽고쓰고, 그룹, 기타 유저들은 읽고 실행 권한!
[orcl2:~]$ ls -l full.sh
-rwxr-xr-x 1 oracle oinstall 725 10월 13 15:28 full.sh1. HR 계정에 스케줄러를 등록함
HR> BEGIN DBMS_SCHEDULER.CREATE_JOB(JOB_NAME => 'full_backup_3', JOB_TYPE => 'EXECUTABLE', JOB_ACTION => '/home/oracle/full.sh', start_date => sysdate + 1/24/60 , COMMENTS => 'TEST_EXECUTABLE'); END; /3. enable시키기
HR> BEGIN DBMS_SCHEDULER.ENABLE('full_backup_3'); END; /
HR>
BEGIN
DBMS_SCHEDULER.DISABLE('full_backup_1');
END;
/
HR>
BEGIN
DBMS_SCHEDULER.DROP_JOB('full_backup_1');
END;
/실패ㅠㅠ
✅ 스케줄의 종류 2가지
1. Time base
2. event base : 이벤트 1 발생 -> 이벤트 2를 일으켜라
✏️ event base 스케줄러 작업 실습
💡 event base 스케줄러
1. emp01 에 insert 가 되면 emp02 에 insert 가 되도록 테스트✔️ 테스트 테이블 생성
CREATE TABLE EMP01 AS SELECT * FROM scott.emp WHERE 1=2; CREATE TABLE EMP02 AS SELECT * FROM scott.emp WHERE 1=2;✔️ 이벤트를 발생시키는 job 생성
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'INSERT_EMP01', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN INSERT INTO scott.emp01 SELECT * FROM scott.emp WHERE sal = 5000; END;', start_date => systimestamp, repeat_interval => 'freq=minutely; interval=1', enabled => TRUE); END; /✔️이벤트 속성 설정
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'INSERT_EMP01', attribute => 'raise_events', VALUE => DBMS_SCHEDULER.JOB_SUCCEEDED); END; /✔️ subscriber 추가
EXEC DBMS_SCHEDULER.ADD_EVENT_QUEUE_SUBSCRIBER('TEST_AGENT'); BEGIN DBMS_AQADM.ENABLE_DB_ACCESS ( agent_name => 'TEST_AGENT', db_username => 'SCOTT'); END; /✔️ SCHEDULER$_EVENT_QTAB 조회 (SYS)
SELECT user_data FROM SCHEDULER$_EVENT_QTAB;✔️ 이벤트 기반 job 생성
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'INSERT_EMP02', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN INSERT INTO scott.emp02 SELECT * FROM scott.emp WHERE sal = 5000; END;', start_date => systimestamp, event_condition => 'tab.user_data.object_owner = ''SCOTT'' and tab.user_data.event_type = ''JOB_SUCCEEDED''', queue_spec => 'sys.scheduler$_event_queue, TEST_AGENT', enabled => TRUE); END; /✔️ 테스트 테이블 데이터 삭제
DELETE FROM emp01; DELETE FROM emp02;✔️ JOB 삭제
BEGIN DBMS_SCHEDULER.DROP_JOB ('INSERT_EMP01'); END; / BEGIN DBMS_SCHEDULER.DROP_JOB ('INSERT_EMP02'); END; /✔️ Subscriber 삭제
EXEC DBMS_SCHEDULER.REMOVE_EVENT_QUEUE_SUBSCRIBER('TEST_AGENT');✔️ queue 테이블 데이터 삭제(SYS)
DELETE FROM SCHEDULER$_EVENT_QTAB;
문제 dept 테이블의 구조를 가지고 dept01, dept02테이블을 각각 생성한다. 그리고 아래의 insert문이 성공하면 dept02에도 insert가 성공할 수 있도록 코드를 구현하기!
insert into dept01
select *
from scott.dept
where dept=10;✔️ 테스트 테이블 생성
CREATE TABLE dept01 AS SELECT * FROM scott.dept WHERE 1=2; CREATE TABLE dept02 AS SELECT * FROM scott.dept WHERE 1=2;✔️ 이벤트를 발생시키는 job 생성
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'INSERT_DEPT01', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN INSERT INTO scott.dept01 SELECT * FROM scott.dept WHERE deptno =10; END;', start_date => systimestamp, repeat_interval => 'freq=minutely; interval=1', enabled => TRUE); END; /✔️이벤트 속성 설정
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'INSERT_DEPT01', attribute => 'raise_events', VALUE => DBMS_SCHEDULER.JOB_SUCCEEDED); END; /✔️ subscriber 추가
EXEC DBMS_SCHEDULER.ADD_EVENT_QUEUE_SUBSCRIBER('TEST_AGENT2'); BEGIN DBMS_AQADM.ENABLE_DB_ACCESS ( agent_name => 'TEST_AGENT2', db_username => 'SCOTT'); END; /✔️ SCHEDULER$_EVENT_QTAB 조회 (SYS)
SELECT user_data FROM SCHEDULER$_EVENT_QTAB;✔️ 이벤트 기반 job 생성
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'INSERT_DEPT02', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN INSERT INTO scott.dept02 SELECT * FROM scott.dept WHERE deptno=10; END;', start_date => systimestamp, event_condition => 'tab.user_data.object_owner = ''SCOTT'' and tab.user_data.event_type = ''JOB_SUCCEEDED''', queue_spec => 'sys.scheduler$_event_queue, TEST_AGENT2', enabled => TRUE); END; /✔️ 테스트 테이블 데이터 삭제
DELETE FROM dept01; DELETE FROM dept02;✔️ JOB 삭제
BEGIN DBMS_SCHEDULER.DROP_JOB ('INSERT_DEPT01'); END; / BEGIN DBMS_SCHEDULER.DROP_JOB ('INSERT_DEPT02'); END; /✔️ Subscriber 삭제
EXEC DBMS_SCHEDULER.REMOVE_EVENT_QUEUE_SUBSCRIBER('TEST_AGENT2');✔️ queue 테이블 데이터 삭제(SYS)
DELETE FROM SCHEDULER$_EVENT_QTAB;
📖 18장. 공간 관리
💡 이번 단원에서 배우게 될 것 !
1. db reorg 작업
2. 테이블 압축하기
3. Defferd segment 생성방법
✏️ DB reorg 작업
💡db reorg 작업 후에 얻을 수 있는 효과 2가지
- 성능이 좋아진다.
- 공간이 확보된다.
➡️ db reorg 작업을 하게 되었을 때 구체적인 효과
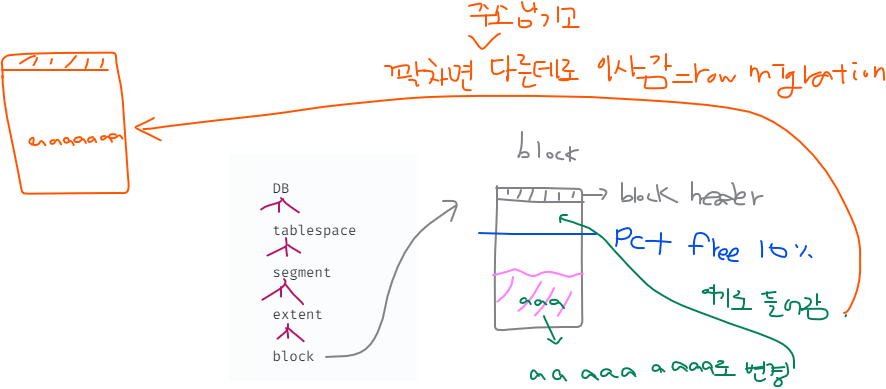
1. HWM (High Water Mark)를 아래로 내린다.
2. row migration 현상이 일어난 row들이 정리된다.
3. 여유공간이 확보된다.
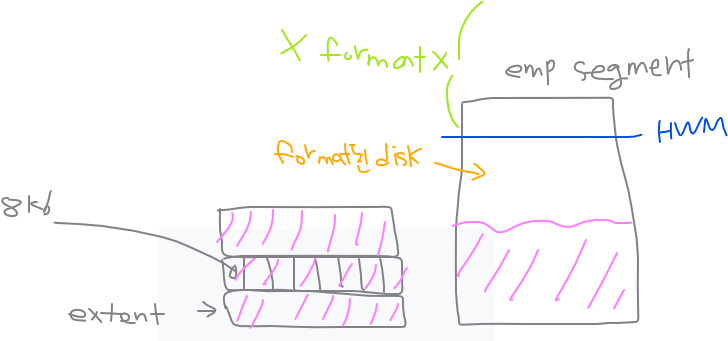
1. HWM (High Water Mark)를 아래로 내린다. 에 대한 설명
extent가 할당되서 HWM 밑에 여유공간이 있는것이다. HWM는 포맷된 디스크와 포맷되지 않은 디스크의 경계선이다.
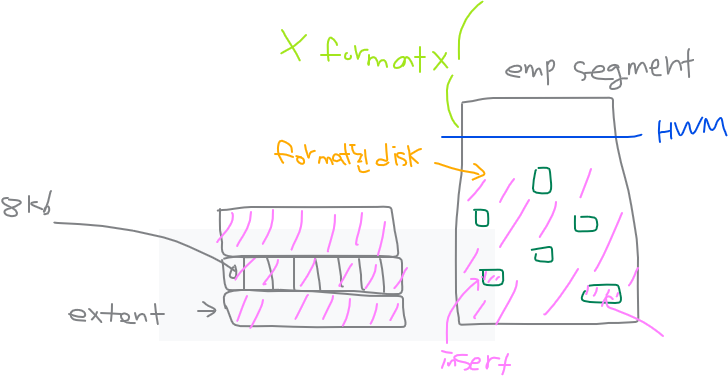
selet ename, sal
from emp
where job='SALESMAN';➡️ 위 job이 인덱슥 없다면 아래에서 HWM까지 풀테이블 스캔을 한다 그러면 HWM가 아래에 있을수록 작업이 빨라진다. DB reorg 작업을 하게되면 데이터가 없어서 듬성듬성 구멍난것을 위로 올리고 HWM를 밑으로 내린다.
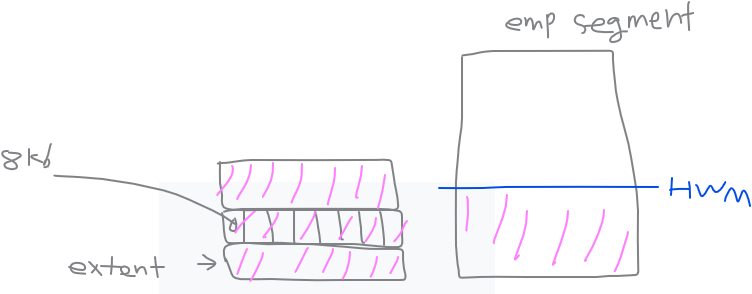
2. row migration 현상이 일어난 row들이 정리된다. 에 대한 설명
✏️ DB reorg 작업 방법 3가지
1. table export -> table drop -> table import
↓
drop에 대한 부담감
drop을 하게되면 테이블 엑세스가 안됨
2. table move (테이블의 테이블 스페이스를 다른 테이블 스페이스로 이동!
같은 테이블 스페이스 내에서 이동해도 정리가 된다.)
3. table compact -> shrink ✔️ table move로 db reorg 하기!
: 현업에서 가장 많이 사용된다.
1. emp 테이블의 HWM 를 높인다. (SCOTT)
SQL> insert into emp select * from emp; SQL> / 엔터 -- 10번 수행 SQL> commit; SQL> delete from emp where deptno in (10,20); -- 구멍뚫기! SQL> commit;2. emp 테이블의 HWM 가 어떻게 되는지 확인한다.
select count(distinct dbms_rowid.rowid_block_number(rowid) ) blocks from emp; -- High Water Mark 까지의 블럭의 갯수 BLOCKS ---------- 3403. emp 테이블이 어느 테이블스페이스에 있는지 조회하시오 !
💡 이게 db reorg 작업!-- emp의 테이블 스페이스가 어딘지 조회 SCOTT> select table_name, tablespace_name from user_tables where table_name='EMP'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ EMP USERS create tablespace ts100 datafile '/home/oracle/ts100.dbf' size 50m;4. emp 테이블을 ts100 테이블스페이스로 move 하시오 !
alter table emp move tablespace ts100;5. emp 테이블이 다른 테이블스페이스로 이동했는지 확인한다.
select table_name, tablespace_name from user_tables where table_name='EMP'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ EMP TS1006. High Water Mark 가 아래로 내려왔는지 확인하시오 !
select count(distinct dbms_rowid.rowid_block_number(rowid) ) blocks from emp; BLOCKS ---------- 153
문제 dept 테이블을 가지고 위 작업처럼 똑같이 작업해보기
1. dept 테이블의 HWM 를 높인다. (SCOTT)
SQL> insert into dept select * from dept; SQL> / 엔터 -- 10번 수행 SQL> commit; SQL> delete from dept where deptno in (10,20); -- 구멍뚫기! SQL> commit;2. dept 테이블의 HWM 가 어떻게 되는지 확인한다.
select count(distinct dbms_rowid.rowid_block_number(rowid) ) blocks from dept; -- High Water Mark 까지의 블럭의 갯수 BLOCKS ---------- 143. dept 테이블이 어느 테이블스페이스에 있는지 조회하시오 !
💡 이게 db reorg 작업!-- emp의 테이블 스페이스가 어딘지 조회 SCOTT> select table_name, tablespace_name from user_tables where table_name='DEPT'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ EMP USERS -- users 말고 move할 새로운 tablespace 만들어주기 SCOTT> create tablespace ts101 datafile '/home/oracle/ts101.dbf' size 50m;4. dept 테이블을 ts101 테이블스페이스로 move 하시오 !
SCOTT> alter table dept move tablespace ts101;5. dept 테이블이 다른 테이블스페이스로 이동했는지 확인한다.
SCOTT> select table_name, tablespace_name from user_tables where table_name='DEPT'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ EMP TS1016. High Water Mark 가 아래로 내려왔는지 확인하시오 !
select count(distinct dbms_rowid.rowid_block_number(rowid) ) blocks from dept; BLOCKS ---------- 7
🚨 위의 move 작업을 할 때 주의할 사항은?
: emp테이블과 dept테이블에 인덱스가 있다면 move 시킨 이후에 반드시 그 인덱스가 사용이 가능한지 확인해야한다.
만약 사용이 불가능하다면, 관련 인덱스를 rebuild 해야한다.
✔️ 테이블에 인덱스가 있는 상태에서 테이블 move 시키기
SCOTT> @demo
SCOTT> create index emp_empno on emp(empno);
SCOTT> create index emp_ename on emp(ename);
SCOTT> create index emp_sal on emp(sal);
SCOTT> create index emp_job on emp(job);
SCOTT> create index emp_detpno on emp(deptno);
SCOTT> select index_name, status
from user_indexes
where table_name='EMP';
SCOTT> alter table emp move tablespace ts100;
SCOTT> select index_name, status
from user_indexes
where table_name='EMP';
INDEX_NAME STATUS
------------------------------ --------
EMP_DETPNO UNUSABLE
EMP_JOB UNUSABLE
EMP_SAL UNUSABLE
EMP_ENAME UNUSABLE
EMP_EMPNO UNUSABLE 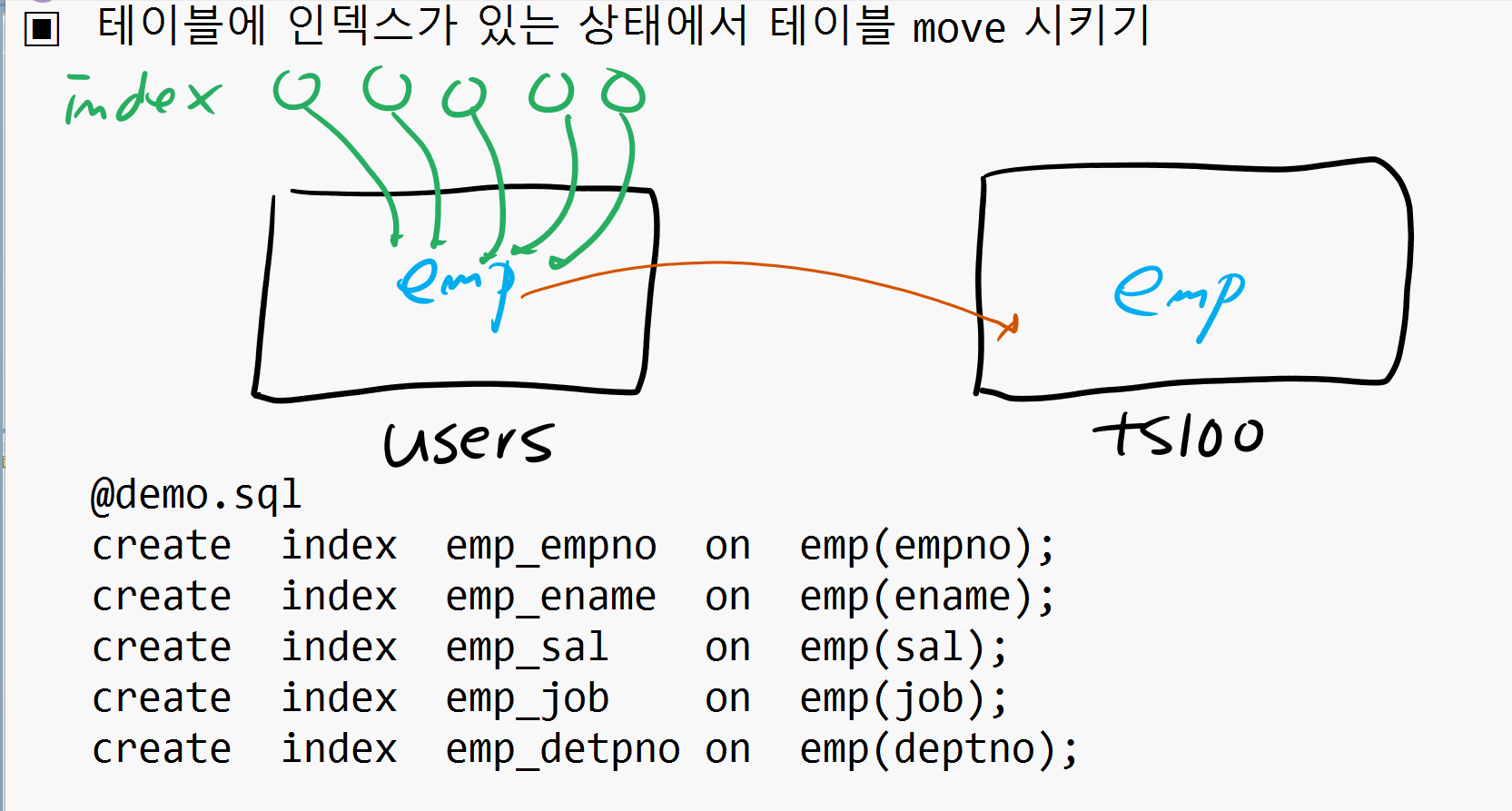
✅ 위 그림처럼 emp가 ts100으로 테이블스페이스가 변경되면서 index만 남았으므로 UNUSABLE 상태가 되었다!
실습 emp테이블과 관련된 인덱스들을 rebuild 하여 valid한 상태로 만들기
SCOTT @ orcl2 > alter index emp_sal rebuild online; SCOTT @ orcl2 > select index_name, status from user_indexes where table_name='EMP'; 2 3 INDEX_NAME STATUS ------------------------------ -------- EMP_DETPNO UNUSABLE EMP_JOB UNUSABLE EMP_SAL VALID -- 바뀌었다 ! EMP_ENAME UNUSABLE EMP_EMPNO UNUSABLE
실습 scott이 가지고있는 모든 UNUSABLE된 index에 대해서 모두 rebuild하는 프로시저를 생성하기
* scott이 dba권한이 있어도 아래를 직접 넣어주어야한다.
SYS @ orcl2 > grant select on user_indexes to scott;
SYS @ orcl2 > grant alter any index to scott;
SYS @ orcl2 > grant create any index to scott; create or replace procedure index_rebuild
authid current_user
is
cursor emp_cursor is
select index_name as name
from user_indexes
where status ='UNUSABLE';
v_stmt varchar2(100);
begin
for emp_record in emp_cursor loop
v_stmt := ' alter index ' || emp_record.name || ' rebuild online';
execute immediate v_stmt ;
end loop;
end;
/
set serveroutput on
---------------------------------------------------------------
exec index_rebuild➡️ emp_cursor를 비긴 밑에 넣어서 loop 돌린다. ' alter index ' || emp_record.name || ' rebuild online'; sql 문장을 v_stmt에 넣고 execute immediate 한다.
- 위 프로시저 잘돌았나 확인하기
SCOTT @ orcl2 > select index_name, status from user_indexes where table_name='EMP'; 2 3 INDEX_NAME STATUS ------------------------------ -------- EMP_DETPNO VALID EMP_JOB VALID EMP_SAL VALID EMP_ENAME VALID EMP_EMPNO VALID
💡 authid current_user 옵션!!
⭐
authid current_user는 프로시저를 수행하는 유저의 권한을 따르겠다 라는 것 !
user_xxx, all_xxx, dba_xxx같은 데이터 딕셔너리를 PL/SQL에서 조회할 때는 프로시저 생성시 이 옵션을 사용해야 권한 오류가 나지 않는다.
문제 HR 계정의 employees 테이블에 걸려있는 인덱스의 상태를 확인하고, HR 계정의 employees 테이블을 ts100 테이블 스페이스로 move한 다음 관련된 인덱스들을 다시 VALID한 상태로 만들기
1. 인덱스 상태 확인
HR> select index_name, status from user_indexes where table_name='EMPLOYEES';2. employees 테이블을 ts100 테이블 스페이스로 move
alter table employees no flashback archive; alter table employees move tablespace ts100;3. 인덱스 상태 재확인
HR @ orcl2 > select index_name, status from user_indexes where table_name='EMPLOYEES'; 2 3 INDEX_NAME STATUS ------------------------------ -------- EMP_NAME_IX UNUSABLE EMP_MANAGER_IX UNUSABLE EMP_JOB_IX UNUSABLE EMP_DEPARTMENT_IX UNUSABLE EMP_EMP_ID_PK UNUSABLE EMP_EMAIL_UK UNUSABLE4. 프로시저 만들어서 VALID한 상태로 만들기
create or replace procedure index_rebuild_hr authid current_user is cursor employees_cursor is select index_name as name from user_indexes where status ='UNUSABLE'; v_stmt varchar2(100); begin for employees_record in employees_cursor loop v_stmt := ' alter index ' || employees_record.name || ' rebuild online'; execute immediate v_stmt ; end loop; end; / exec index_rebuild_hr -- 했는데 에러났다 ERROR at line 1: ORA-01647: tablespace 'EXAMPLE' is read-only, cannot allocate space in it ORA-06512: at "HR.INDEX_REBUILD_HR", line 16 ORA-06512: at line 1 SYS @ orcl2 > alter tablespace example read write; -- 해주고 다시 실행해주니까 되었음5. 인덱스 상태 확인
HR @ orcl2 > select index_name, status from user_indexes where table_name='EMPLOYEES'; INDEX_NAME STATUS ------------------------------ -------- EMP_NAME_IX VALID EMP_MANAGER_IX VALID EMP_JOB_IX VALID EMP_DEPARTMENT_IX VALID EMP_EMP_ID_PK VALID EMP_EMAIL_UK VALID
✅ 실습 중 참고할 에러
: 저번 실습때 employees 테이블을 flashback archive 설정해준게 있었음.
HR @ orcl2 > alter table employees move tablespace ts100; alter table employees move tablespace ts100 * ERROR at line 1: ORA-55610: Invalid DDL statement on history-tracked table alter table employees no flashback archive; -- 이거 실행하고 진행함
✔️ table compack과 shrink로 db reorg 하기!
💡 위에서 실행한 table move시 단점은 인덱스를 리빌드 해야했었는데, 이 reorg 작업은 인덱스 rebulid 하지 않아도 된다.
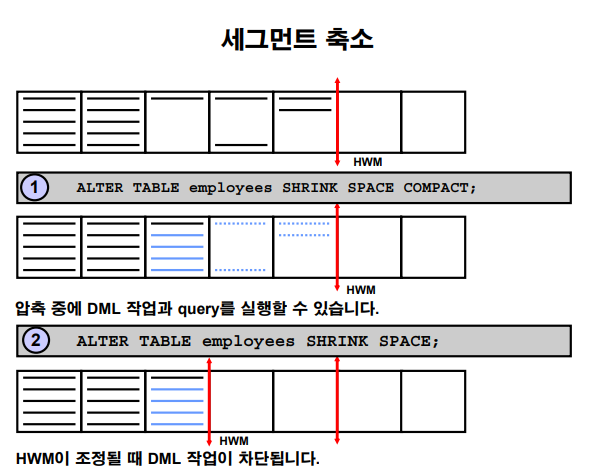
➡️ table compact : 비어있는 공간으로 data를 채워넣는 것.
➡️ table shrink : HWM를 아래로 내리는 작업
실습
- table 을 준비한다.
SCOTT @ orcl2 > @demo SCOTT @ orcl2 > insert into emp select * from emp; -- 10번 수행 SCOTT @ orcl2 > delete from emp where deptno in (10,20);
- emp 테이블의 실제 사용하고 있는 block 의 갯수 - 그림에서 5개
select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from emp; BLOCKS ---------- 169
- High water mark 까지 할당된 block 의 갯수 확인 - 그림에서 5개 근데 데이터 비어있으면 6,7 일수 있다. 위 그림은 같다.
SCOTT @ orcl2 > select blocks from user_segments where segment_name='EMP'; BLOCKS ---------- 256
- 테이블 compact 작업 수행
SCOTT @ orcl2 > alter table emp enable row movement; SCOTT @ orcl2 > alter table emp shrink space compact;
- emp 테이블의 실제 사용하고 있는 block 의 갯수
SCOTT @ orcl2 > select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from emp; BLOCKS ---------- 77
- High water mark 까지 할당된 block 의 갯수 확인 : 얘는 안내려온다.
SCOTT @ orcl2 > select blocks from user_segments where segment_name='EMP'; BLOCKS ---------- 256
- High water mark 를 내려주는 작업 수행
SCOTT @ orcl2 > alter table emp shrink space; SCOTT @ orcl2 > select blocks from user_segments where segment_name='EMP'; BLOCKS ---------- 88💡 관련된 인덱스들을 rebuild 하지 않아도 된다!!!
오늘의 마지막 문제 HR 계정의 employees 테이블을 가지고 compact과 shrink를 한 후에 관련 인덱스들의 상태가 계속 valid 한지 확인하기. 정말 rebuild 하지 않아도 되는지!
1. 인덱스 상태 확인
HR @ orcl2 > select index_name, status from user_indexes where table_name='EMPLOYEES'; INDEX_NAME STATUS ------------------------------ -------- EMP_NAME_IX VALID EMP_MANAGER_IX VALID EMP_JOB_IX VALID EMP_DEPARTMENT_IX VALID EMP_EMP_ID_PK VALID EMP_EMAIL_UK VALID2. employees 테이블에 data insert, delete 하기
HR @ orcl2 > delete from employees where SALARY in (2800,3000,7000,6200,6400);3. employees 테이블의 실제 사용하고 있는 block 의 갯수
select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from employees; BLOCKS ---------- 24. High water mark 까지 할당된 block 의 갯수 확인
HR @ orcl2 > select blocks from user_segments where segment_name='EMPLOYEES'; BLOCKS ---------- 85. 인덱스 상태 다시 확인
HR @ orcl2 > select index_name, status from user_indexes where table_name='EMPLOYEES'; INDEX_NAME STATUS ------------------------------ -------- EMP_NAME_IX VALID EMP_MANAGER_IX VALID EMP_JOB_IX VALID EMP_DEPARTMENT_IX VALID EMP_EMP_ID_PK VALID EMP_EMAIL_UK VALID6. 테이블 compact 작업 수행
HR @ orcl2 > alter table employees enable row movement; HR @ orcl2 > alter table employees shrink space compact;7. employees 테이블의 실제 사용하고 있는 block 의 갯수
select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from employees; BLOCKS ---------- 18. High water mark 를 내려주는 작업 수행
HR @ orcl2 > alter table employees shrink space; SCOTT @ orcl2 > select blocks from user_segments where segment_name='EMPLOYEES'; BLOCKS ---------- 89. index 상태 확인
HR @ orcl2 > select index_name, status from user_indexes where table_name='EMPLOYEES'; 2 3 INDEX_NAME STATUS ------------------------------ -------- EMP_NAME_IX VALID EMP_MANAGER_IX VALID EMP_JOB_IX VALID EMP_DEPARTMENT_IX VALID EMP_EMP_ID_PK VALID EMP_EMAIL_UK VALID
