📖 복습_db reorg
💡 db reorg 작업 후에 얻을 수 있는 효과 2가지
- 성능이 좋아진다.
- 공간이 확보된다.
💡 db reorg 방법 3가지
- table export -> table drop -> table import
- table
move하고 인덱스를rebuildtable compact -> shrink: reorg 대상 테이블들의 연관된 인덱스들을 rebuild하지 않아도 된다.
✏️ db reorg 작업 대상이 되는 테이블 선별하기
drop table sales500; SCOTT @ orcl3 > create table sales500 as select * from sh.sales; SCOTT @ orcl3 > delete from sales500 where amount_sold<188; -- HWM아래쪽 구멍뚫기 SCOTT @ orcl3 > commit; -- 테이블의 크기 구하기(테이블의 가로사이즈 x 14) SCOTT @ orcl3 > analyze table sales500 compute statistics; #평균 가로사이즈를 구하려면 분석을 꼭 해주어야 한다. SCOTT @ orcl3 > select table_name,(num_rows * avg_row_len)/8192 as real_data_blocks, blocks from user_tables where table_name='SALES500'; TABLE_NAME REAL_DATA_BLOCKS BLOCKS ------------------------------ ---------------- ---------- SALES500 353.452881 4512 #전체블락의 갯수 #데이터가 있는곳까지의 blocks > real_data_blocks 445 324 ------------------------- 1. 차이 : 4512 - 353 = 4159 2. 상대적 차이(%) : (4159 / 4512) *100 = 92% -- 92%이므로 20%가 훨씬 넘으니 작업 대상이다.➡️ blocks > real_data_blocks의 차이가 20%이상 나는 테이블이 바로 db reorg 대상 테이블이다!
문제 sales500을 compact, shrink를 이용해서 reorg 하고, 다시 sales500을 분석해서 reorg대상인지 재확인하기
1. sales500 테이블의 실제 사용하고 있는 block 의 갯수
SCOTT @ orcl3 > select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from sales500; BLOCKS ---------- 8982. High water mark 까지 할당된 block 의 갯수 확인
SCOTT @ orcl3 > select blocks from user_segments where segment_name='SALES500'; BLOCKS ---------- 46083. 테이블 compact 작업 수행
SCOTT @ orcl3 > alter table sales500 enable row movement; SCOTT @ orcl3 > alter table sales500 shrink space compact;4. High water mark 를 내려주는 작업 수행
SCOTT @ orcl3 > alter table sales500 shrink space;5. 테이블을 분석해서 사이즈 구하기
-- 테이블의 크기 구하기(테이블의 가로사이즈 x 14) SCOTT @ orcl3 > analyze table sales500 compute statistics; #평균 가로사이즈를 구하려면 분석을 꼭 해주어야 한다. SCOTT @ orcl3 > select table_name,(num_rows * avg_row_len)/8192 as real_data_blocks, blocks from user_tables where table_name='SALES500'; TABLE_NAME REAL_DATA_BLOCKS BLOCKS ------------------------------ ---------------- ---------- SALES500 353.452881 430SCOTT @ orcl3 > select count(distinct dbms_rowid.rowid_block_number(rowid)) as blocks from sales500; BLOCKS ---------- 430 SCOTT @ orcl3 > select blocks from user_segments where segment_name='SALES500'; BLOCKS ---------- 448
✏️ 테이블 압축하기
💡 디스크 공간을 절약하기 위해서 (p.18-17)
✔️ 오라클의 압축 방법 2가지
basic table compression: insert시 테이블 압축이 수행되는데 HWM위에 입력하는 insert문에 대해서만 압축이 수행된다.
-- 압축X
insert into emp01(empno, ename, sal)
values(1111,'aaa',3000);
-- 압축O
insert /*+ append */ into emp01
select *
from emp➡️ 주로 압축대상이 되는 테이블은 oltp 서버가 아니라 dw(data warehouse) 서버에 존재한다.
oltp table compression: insert 시에 테이블이 압축되는데 HWM위, 아래에 입력하는 insert 문을 모두 압축한다. 아래의 2개 insert문장을 모두 압축해주는 기술이다.
-- HWM 아래에 입력하는 insert문
insert into emp01(empno, ename, sal)
values(1111,'aaa',3000);
-- HWM 위에 입력하는 insert문
insert /*+ append */ into emp01
select *
from emp⭐ 실시간 주문 들어오는 쪽이 oltp 서버쪽!
❓ 압축의 원리
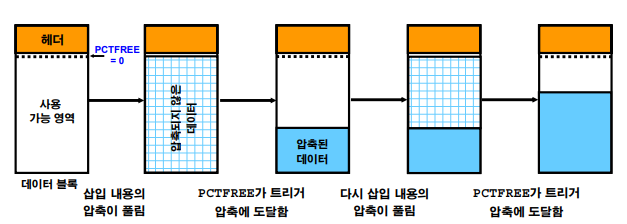
scott analyst 3000 20 5000 10 dallas allen analyst 3000 20 5000 10 dallas ford analyst 3000 20 5000 10 dallas king analyst 3000 20 5000 10 dallas jones analyst 3000 20 5000 10 dallas ↓ 압축 analyst 3000 20 500010dallas --> 하나의 row 로 저장 scott . allen . ford . king . jones . . 이 바로 ---> analyst 3000 20 5000 10 dallas➡️ name들은 중복되지 않았는데 중복된 데이터들을
.에 넣는다.
scott analyst 3000 20 5000 10 dallas=scott .
중복된 데이터가 많을수록 압축이 잘된다!!
✔️ 압축테이블의 장단점
- 장점 : 공간이 확보된다.
- 단점 : insert 속도가 느려진다.
oltp는 insert가 활발하게 일어난다. 그렇지만 DW 서버는 주로 분석가들이 select 하는 일들이 많아서 DW 서버에 압축을 하는것이 좋다.
: 회사에 따라 다르다!
압축 테이블의 장점을 확인하는 실습
SCOTT> @demo.sql1. 압축되지 않는 테이블 생성
SCOTT @ orcl3 > create table normal as select * from emp;2. 압축된 테이블을 생성한다 (basic) -
compress이것이 압축 테이블을 만드는 옵션!SCOTT @ orcl3 > create table basic compress as select * from emp;3. 압축된 테이블을 생성한다 (oltp) -
compress for all operations: oltp용 압축 테이블이 된다.SCOTT @ orcl3 > create table oltp compress for all operations as select * from emp;4. 위의 3개의 테이블에 아래의 insert 작업을 시도한다. (10번 수행)
SCOTT @ orcl3 > insert /*+ append */ into normal select * from normal; commit; SCOTT @ orcl3 > insert /*+ append */ into basic select * from basic; commit; SCOTT @ orcl3 > insert /*+ append */ into oltp select * from oltp; commit;5. 3개의 테이블의 건수를 확인한다.
SCOTT @ orcl3 > select count(*) from normal; COUNT(*) ---------- 7168 SCOTT @ orcl3 > select count(*) from basic; COUNT(*) ---------- 14336 SCOTT @ orcl3 > select count(*) from oltp; COUNT(*) ---------- 286726. 압축이 잘되어서 공간절약이 되고있는지 비교하시오 !
SCOTT @ orcl3 > select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks from normal; 2 BLOCKS ---------- 49 SCOTT @ orcl3 > select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks from basic; 2 BLOCKS ---------- 29 SCOTT @ orcl3 > select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks from oltp; 2 BLOCKS ---------- 54
문제 normal과 basic 테이블의 insert 속도의 차이가 있는지 확인하기
set timing on
SCOTT @ orcl3 > insert /*+ append */ into normal
select *
from normal;
-- Elapsed: 00:00:00.01
commit;
SCOTT @ orcl3 > insert /*+ append */ into basic
select *
from basic;
-- Elapsed: 00:00:00.02
commit;➡️ 별 다른 차이가 보이지 않지만, 데이터가 더 크면 차이가 발생한다!
✏️ deferred segment 생성하기
💡 공간관리를 효율적으로 하기 위한 오라클의 기술들 (p.18-11)
1. db reorg 작업
2. table 압축
3. dererred segment 사용하기
❓ deferred segment란
💡 테이블을 생성하자 마자 바로 공간을 할당하는것이 아니라, insert가 되는 시점에서 공간을 할당 받게 하는 기능이다.
우리회사 db <- 응용 프로그램 설치 (테이블이 여러개 만들어지고 view도 만들고 procedure도 여러개 생성)
데이터가 없는 테이블만 생성해도 그 테이블이 많으면 공간을 많이 차지하게 된다. 그리고 관련 객체들을 생성할 때 시간도 많이 걸린다! -> 오라클에서 eferred segment를 만들었다.
실습
1. 테이블 생성시 공간 할당이 되는 파라미터의 값을 조회
SYS @ orcl3 > show parameter deferred_segment_creation ; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ deferred_segment_creation boolean TRUE
true: 테이블 생성시 바로 segment 를 할당하지 않음
false: 테이블 생성시 바로 segment 를 할당함.2. scott 으로 접속해서 emp600 테이블을 생성한다.
SCOTT @ orcl3 > create table emp600 ( empno number(10), ename varchar2(500) );3. emp600 세그먼트가 생성되었는지 확인하시오 !
SCOTT @ orcl3 > select segment_name from user_segments where segment_name='EMP600'; no rows selected -- 지금은 안보인다! insert하는 순간에 보이게 될 것4. emp600 에 insert 를 시도하고 세그먼트가 보이는지 확인하시오 !
SCOTT @ orcl3 > insert into emp600 values(1111,'aaaa'); SCOTT @ orcl3 > select segment_name from user_segments where segment_name='EMP600'; 2 SEGMENT_NAME -------------------------------------------------------------------------------- EMP600
✔️ 테이블 생성시 deferred segment를 제어하는 방법
segment creation immediate: 테이블을 생성하자마자 바로 세그먼트 할당segment creation deferred: 테이블을 생성하자마자 바로 세그먼트를 할당하지 않고, insert를 하면 할당
create table emp700
(empno number(10),
ename varchar2(500) )
segment creation immediate tablespace users;
SCOTT @ orcl3 > select segment_name from user_segments
where segment_name='EMP700'; 2
SEGMENT_NAME
--------------------------------------------------------------------------------
EMP700 -- insert 없이바로 보인다! 문제 dept 테이블과 구조가 똑같은 dept700 table을 생성하는데, 만들자마자 바로 segment가 할당 되도록 생성하기
create table dept700 segment creation immediate tablespace users as select * from dept where 1=2; SCOTT @ orcl3 > select segment_name from user_segments where segment_name='DEPT700'; SEGMENT_NAME -------------------------------------------------------------------------------- DEPT700
✏️ orcl4 만들것임
[orcl3:~]$ ps -ef | grep pmon
oracle 5709 1 0 Oct24 ? 00:00:09 asm_pmon_+ASM
oracle 12993 1 0 04:42 ? 00:00:04 ora_pmon_orcl3
oracle 18121 1 0 09:12 ? 00:00:01 ora_pmon_orcl2
oracle 20550 18703 0 11:24 pts/2 00:00:00 grep pmon
-- asm_pmon_+ASM 인스턴스가 떠있어야 다시 작업할 수 있는데 아니라면 밑에처럼 startup 시키기
. oraenv
+ ASM
sqlplus / as sysasm
@i -> started 여야하는데, 아니라면 startup✔️ 푸티말고 서버에서 진행
[orcl3:~]$ whoami -- oracle에서 진행
[orcl3:~]$ dbcaoltp 서버 -> 범용또는 트랜잭션
dw 서버 -> 데이터 웨어하우스
전역베이스이름, SID orcl4
비밀번호 oracle_4U
SYS @ orcl4 > @i STATUS ------------ OPEN
📖 5장. ASM 인스턴스 관리
💡 ASM 이란 ? 자동으로 스토리지를 관리하는 오라클에서 만든 소프트웨어
✏️ ASM 필요성
❓ ASM 을 우리가 꼭 써야하는가 ? 필요한가 ?
1. 오라클 Exa data 시스템 ~> 대기업이나 여러 기업에서 도입하고 있는 추세
(오라클 하드웨어 + 소프트웨어를 함께 제공함)
엄청난 성능을 보여줌
Exa data 가 ASM 기반으로 되어 있음2. 11g 버전부터 오라클 설치 화면에서 스토리지 선택하는 부분에 raw device 가 빠짐
✅스토리지 3가지
1.File system
2.Raw device-> dbca에서 만들 때 이거 선택하는게 없었다. Raw device로 db를 생성하고 싶다면 수동으로 스크립트로 생성해야한다./raw/raw2/raw22 <- system01.dbf
➡️ 테라를 기가단위로 나누어놓는것이 Raw device이다.
3.ASM
✏️ 시스템에서의 ASM 구성도
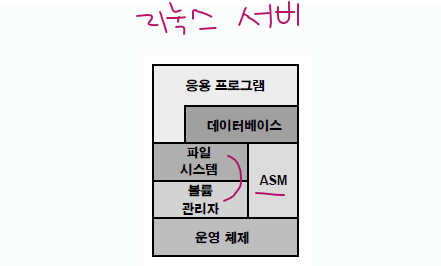
➡️ 볼륨 관리자(C, D 드라이브)와 파일 시스템(각 C, D 드라이브 안에 있는 디렉토리 및 파일들)을 ASM 으로 대체하겠다.
원래 볼륨 관리자와 파일 시스템 관리는 OS 엔지니어(TA)의 역할을 하는데, 그 역할을 ASM 이 한다는 것이다.
즉, OS 엔지니어의 역할이었던 볼륨 매니저 관리와 파일 시스템 관리를 오라클 ASM 이 담당하게 되었다.
그래도 OS 엔지니어의 역할이 크긴 한데 DBA 도 ASM 에 대한 원리를 잘 알고 있어야 한다.
-> ASM 관리는 dba역할이다.
✏️ ASM 의 장점 2가지
Striping (Raid 0)Mirorring (Raid 1)
✔️ Striping (Raid 0)
💡Insert 시 데이터를 Disk 에 분산시켜서 저장함, select 시 Disk 4개가 동시에 작동함 -> 성능이 좋아짐
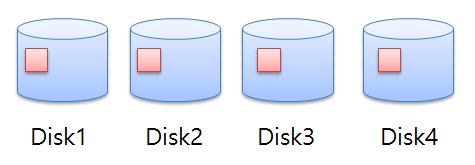
- emp 테이블을 4개로 나누어놓는것이다. (외장형 디스크 생각!외장형 디스크 4개에 emp테이블을 나눠놓는다.)
- 원래 os의 볼륨매니저가 하던 일이다.
✔️ Mirorring (Raid 1)
💡 만약 Striping은 하고 미러링을 안하고 깨졌을 경우 selet from emp; 하면 에러난다. (깨진 디스크에 안의 데이터 있을 경우)
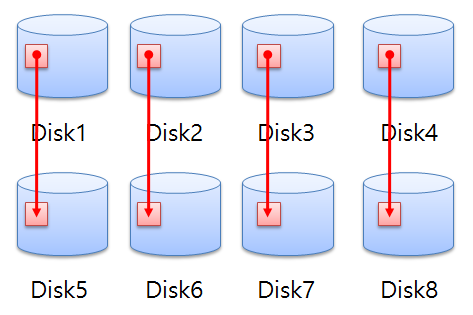
Striping 만 존재한다면 DB 가 깨졌을 경우, 복구할 수 없는 장애가 발생하게 된다.
따라서 비용이 더 올라가지만 (돈이 더 들지만) Disk 4개를 더 만들어서 Striping 데이터와 똑같은 데이터로 구성해준다.
이렇게 할 경우, 디스크가 깨지는 경우 미러링 한 Disk 로 복구가 가능하다.
ASM Disk Group 에다가 Disk 만 추가해주면 됨.
✅ raid 0 + 1이 가장 바람직하다!
💡 디스크 볼륨 구성이 raid 0+1로 되어있는지 raid 5로 되어있는지 확인
✏️ ASM 확인 SQL
✔️ 현재 시스템에 구성되어 있는 ASM 디스크 그룹 확인하기
SYS @ orcl4 > select group_number, name, state
from v$asm_diskgroup; 2
GROUP_NUMBER NAME STATE
------------ ------------------------------ -----------
1 DATA CONNECTED
2 FRA CONNECTED✔️ 현재 시스템에 구성되어 있는 disk 확인하기
select group_number, mount_status, path, total_mb
from v$asm_disk;
GROUP_NUMBER MOUNT_S PATH TOTAL_MB
------------ ------- -------------------- --------
1 CACHED ORCL:ASMDISK01 2304
1 CACHED ORCL:ASMDISK02 2304
1 CACHED ORCL:ASMDISK03 2304
1 CACHED ORCL:ASMDISK04 2304
2 CACHED ORCL:ASMDISK05 2304
2 CACHED ORCL:ASMDISK06 2304
2 CACHED ORCL:ASMDISK07 2304
2 CACHED ORCL:ASMDISK08 2304
0 CLOSED ORCL:ASMDISK13 0
0 CLOSED ORCL:ASMDISK12 0
0 CLOSED ORCL:ASMDISK11 0
0 CLOSED ORCL:ASMDISK10 0
0 CLOSED ORCL:ASMDISK09 0 ➡️ CACHED 는 사용중인 디스크이고 CLOSED는 아직 사용하지 않은 디스크
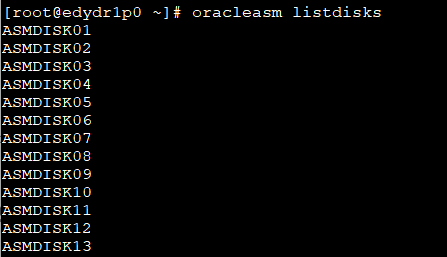
✔️ OS 에서 ASM 디스크 리스트 확인
-- root 로 접속 [orcl4:~]$ su - Password: -- ASM 디스크 리스트 확인 [root@edydr1p0 ~]# oracleasm listdisks
✔️ 현재 ASM diskgroup 의 사용량을 쿼리문으로 조회하기
SYS @ orcl4 > select name, total_mb, free_mb
from v$asm_diskgroup; 2
NAME TOTAL_MB FREE_MB
------------------------------ ---------- ----------
DATA 9216 5783
FRA 9216 8927- DATA Disk : datafile, control file, redo log file 이 저장됨
- FRA Disk : ~> backup 관련 file 이 저장됨
✏️ 관리자를 위한 ASM 의 이점
➡️ ASM 을 구성하게 되면 어떠한 업무의 부담이 줄어드는가 ?
1. 로지컬 볼륨 관리에 대한 부담이 줄어든다. (ASM 이 알아서 관리)
2. DBA 가 시스템 엔지니어에 대한 의존도를 줄일 수 있다.
(개발자 → DBA → OS 엔지니어)3. 수동 유지 관리 작업과 관련된 오류 발생 가능성
즉, OS 에서 실수로 OS 의 파일을 삭제할 가능성이 줄어든다.
$ rm users01.dbf --> 휴지통 기능이 없기 때문에 복구가 불가능함문제 asmcmd 로 접속해서 users.279...를 rm으로 지우면 지워지는지 확인!
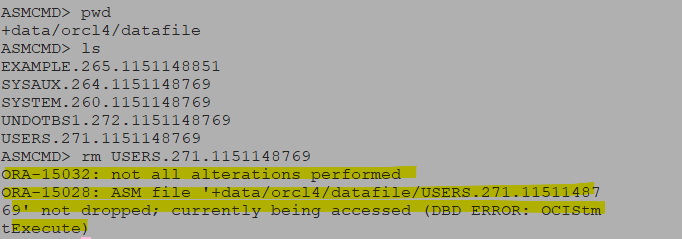
ASM 위에 오라클 Instance 가 떠있으면 (오라클 DB 가 운영중일때는) rm 으로 datafile 을 삭제할 수 없다. (실수를 방지할 수 있다.) 오라클 DB 가 내려간 후에는 삭제할 수 있다.
✏️ ASM Instance (p5-4)
💡 data diskgroup 을 관리하기 위한 별도의 메모리
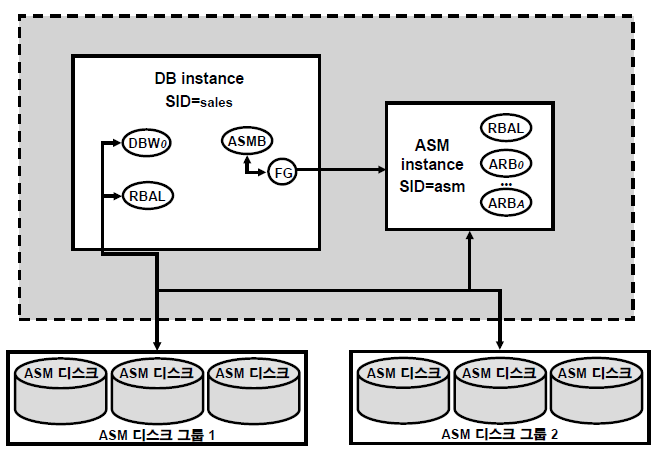
✔️ 인스턴스 시작과 종료 순서
시스템이 올라올 때 인스턴스 올라오는 순서
ASM instance ---> DB instancedb 인스턴스와 ASM 인스턴스를 내리기
1. DB 인스턴스를 내리고
[orcl4:~]$ sqlplus / as sysdba SYS @ orcl4 > shutdown immediate Database closed. Database dismounted. ORACLE instance shut down.2. ASM 인스턴스를 내린다.
[orcl4:~]$ . oraenv ORACLE_SID = [orcl4] ? +ASM [+ASM:~]$ sqlplus / as sysasm SQL> shutdown immediate ASM diskgroups dismounted ASM instance shutdown
ASM 인스턴스와 db 인스턴스를 올리기
위 내린 순서를 반대로 한다.
1. ASM 인스턴스를 올리기
SQL> startup2. DB 인스턴스를 올리기
SYS @ orcl4 > startup💡 ASM인스턴트 올렸을 때 마운트 단계까지 올라가는데 이것은 파라미터 파일이 있다는 것이다.
SQL> show parameter spfile NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ spfile string +DATA/asm/asmparameterfile/reg istry.253.796856615
✏️ ASM 을 운영하는 백그라운드 프로세서
💡 ASM 을 사용했을때의 장점중에 하나가 새로운 Disk 를 추가할 때 시스템을 내리지 않아도 된다.
즉, 시스템 운영중에 새로운 disk 를 추가할 수 있다.
💡 새로운 disk 가 disk group 에 추가가 되면 ASM 백그라운드 프로세서들이 rebalancing 을 한다.
💡rebalancing 이란 ?
새로운 디스크가 들어오면 새로운 디스크로 기존 데이터를 분배하는 것을 rebalancing이라고 한다. ASM 백그라운드 프로세서중에 rebalancing하는 프로세서 이름이 RBAL입니다!
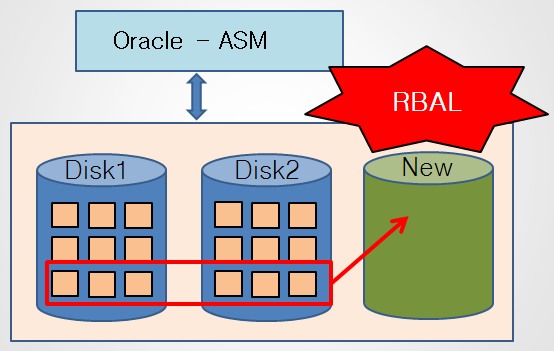
✅ RBAL : Rebalancing 을 하는 총 사령관 프로세서
RBAL이 떠있는지 확인해보자[orcl4:~]$ ps -ef | grep rbal oracle 6498 1 0 14:23 ? 00:00:00 asm_rbal_+ASM oracle 6596 1 0 14:24 ? 00:00:00 ora_rbal_orcl4 oracle 7672 5669 0 14:32 pts/2 00:00:00 grep rbal
✅ arbn : rbal 의 명령을 듣고 행동하는 프로세서! 부하 프로세스다. (balancing 을 수행하는 프로세서)
[orcl4:~]$ ps -ef | grep ARB0
oracle 9007 5669 0 14:50 pts/2 00:00:00 grep ARB0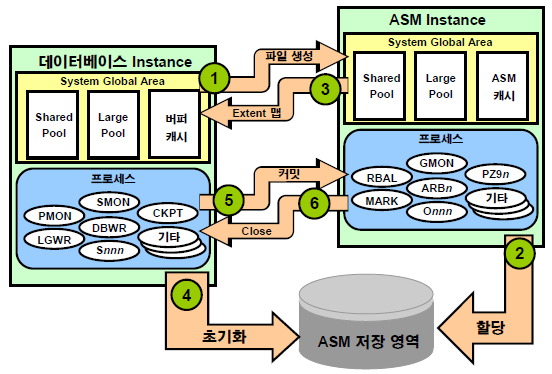
➡️ 왼쪽은 오라클 데이터 베이스를 관리하는 백그라운드 프로세스 들이고, ASM은 디스크만 관리하는 거라서 datafile, redo log file... 필요없다. 얘네를 띄우기 위한 인스턴스만 있으면 된다.
외장하드라고 치면 외장하드 안에 datafile, redo log, controlfile 이 있어서 거기에 오라클 프로세스들이 write한다. 근데 ASM 인스턴스들은 그냥 외장하드를 관리하는 애들이다.
❓ ASM pmon을 kill 시키면, orcl4도 사라진다.(자동으로 다시 살아나는데, ASM부터 살아난다.)
[orcl4:~]$ ps -ef | grep pmon
oracle 9676 1 0 14:57 ? 00:00:00 asm_pmon_+ASM
oracle 9771 1 0 14:57 ? 00:00:00 ora_pmon_orcl4
oracle 9860 5669 0 14:58 pts/2 00:00:00 grep pmon
oracle 12993 1 0 05:51 ? 00:00:05 ora_pmon_orcl3
oracle 18121 1 0 10:20 ? 00:00:03 ora_pmon_orcl2
[orcl4:~]$ kill -9 9676 --프로세스 번호
[orcl4:~]$ ps -ef | grep pmon
-- orcl4 pmon, asm pmon이 없어졌다.
oracle 9933 5669 0 14:58 pts/2 00:00:00 grep pmon
oracle 12993 1 0 05:51 ? 00:00:05 ora_pmon_orcl3
oracle 18121 1 0 10:20 ? 00:00:03 ora_pmon_orcl2➡️ kill은 정상적으로 내린게 아니라서 다시 자동으로 올라온다.
✔️ ASM 관련 파라미터
asm_diskgroups: ASM을 올릴 때 마운트 시킬 그룹명asm_diskstring: ASM을 올릴 때 마운트 시킬 디스크의 위치asm_power_limit: 로드 밸랜싱 하는 RBAL의 갯수asm_preferred_read_failure_groups: RAC 환경에서 특정 노드와 가까운 failure group을 선택할 때 사용하는 파라미터
[orcl4:~]$ . oraenv ORACLE_SID = [orcl4] ? +ASM The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/grid is /u01/app/oracle [+ASM:~]$ sqlplus / as sysasm SQL> select instance_name, status 2 from v$instance; INSTANCE_NAME STATUS ---------------- ------------ +ASM STARTED SQL> show parameter asm NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ asm_diskgroups string FRA asm_diskstring string asm_power_limit integer 1 asm_preferred_read_failure_groups string
실습 rbal의 갯수를 2개로 늘린다.
: RBAL 의 개수를 올려주면 rebalancing 속도를 높일 수 있다.
SQL> alter system set asm_power_limit = 2;위 alter문 수행 후
- orcl4 인스턴스를 내리고
- asm 인스턴스를 내린다.
- asm 인스턴스를 올리고 rbal의 갯수 변했나 확인
SQL> show parameter asm NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ asm_diskgroups string FRA asm_diskstring string asm_power_limit integer 2 asm_preferred_read_failure_groups string
- orcl4로 와서 인스턴스 올린다.
➡️ 지금 로드 밸랜싱 작업이 없어서 1개만 떠있다.
SQL> select name, value from v$parameter where name like '%diskgroup%';
NAME
--------------------------------------------------------------------------------
VALUE
--------------------------------------------------------------------------------
asm_diskgroups
FRA✔️ ASM 인스턴스에 대한 ALERT LOG FILE 확인하기
SQL> show parameter background_dump_dest; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ background_dump_dest string /u01/app/oracle/diag/asm/+asm/ +ASM/trace➡️ ASM쪽에 문제가 생기면 이 alert log file을 열어보면 된다.
[+ASM:trace]$ pwd /u01/app/oracle/diag/asm/+asm/+ASM/trace
[+ASM:trace]$ vi alert_+ASM.log
✏️ ASM diskgroup 에 disk 추가 작업 (중요)
✔️ 현재 시스템에 구성되어 있는 asm 디스크 그룹 확인
1. sysdba 으로 orcl4 에서 확인SYS> select group_number, name, state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ------------ ------------------------------ ----------- 1 DATA CONNECTED 2 FRA CONNECTED2.sysasm 으로 ASM 에서 확인
SQL> select group_number, name, state from v$asm_diskgroup;✔️ 현재 시스템에 구성되어 있는 disk 확인
SYS> col path for a20 SYS> select group_number, mount_status, path, total_mb from v$asm_disk; GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 1 CACHED ORCL:ASMDISK01 2304 1 CACHED ORCL:ASMDISK02 2304 1 CACHED ORCL:ASMDISK03 2304 1 CACHED ORCL:ASMDISK04 2304 2 CACHED ORCL:ASMDISK05 2304 2 CACHED ORCL:ASMDISK06 2304 2 CACHED ORCL:ASMDISK07 2304 2 CACHED ORCL:ASMDISK08 2304 0 CLOSED ORCL:ASMDISK13 0 0 CLOSED ORCL:ASMDISK12 0 0 CLOSED ORCL:ASMDISK11 0 GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 0 CLOSED ORCL:ASMDISK10 0 0 CLOSED ORCL:ASMDISK09 0➡️ closed는 사용 전인 디스크
✔️ data disk group 에 ORCL:ASMDISK09 디스크 추가하기
1. 디스크 추가하기 전의 크기SYS> select name, total_mb, free_mb from v$asm_diskgroup; NAME TOTAL_MB FREE_MB ------------------------------ ---------- ---------- DATA 9216 5783 FRA 9216 8927 > SQL> save asm_space.sql Created file asm_space.sql [yeomdb:~]$ . oraenv ORACLE_SID = [yeomdb] ? +ASM The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/grid is /u01/app/oracle [+ASM:~]$ sqlplus / as sysasm SQL> alter diskgroup data add disk 'ORCL:ASMDISK09' rebalance power 5; -- power 5 는 프로세서를 5개 띄워서 해라
- 디스크 추가한 후의 크기
SQL> @asm_space.sql NAME TOTAL_MB FREE_MB ------------------------------ ---------- ---------- DATA 11520 8085 FRA 9216 8927
문제 FRA 디스크 그룹에도 DISK를 1개 추가하기
1. 현재 시스템에 구성되어있는 disk 확인
SQL> col path for a20 SQL> select group_number, mount_status, path, total_mb from v$asm_disk; 2 GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 0 CLOSED ORCL:ASMDISK10 0 0 CLOSED ORCL:ASMDISK11 0 0 CLOSED ORCL:ASMDISK12 0 0 CLOSED ORCL:ASMDISK13 0 1 CACHED ORCL:ASMDISK01 2304 1 CACHED ORCL:ASMDISK02 2304 1 CACHED ORCL:ASMDISK03 2304 1 CACHED ORCL:ASMDISK04 2304 2 CACHED ORCL:ASMDISK05 2304 2 CACHED ORCL:ASMDISK06 2304 2 CACHED ORCL:ASMDISK07 2304 GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 2 CACHED ORCL:ASMDISK08 2304 1 CACHED ORCL:ASMDISK09 23042. data disk group 에 ORCL:ASMDISK10 디스크 추가하기
SQL> alter diskgroup data add disk 'ORCL:ASMDISK10' rebalance power 5;3. 디스크 추가한 후의 크기, 현재 시스템에 구성되어있는 disk 상태 확인
SQL> @asm_space.sql NAME TOTAL_MB FREE_MB ------------------------------ ---------- ---------- DATA 13824 10387 FRA 9216 8927 SQL> select group_number, mount_status, path, total_mb from v$asm_disk; 2 GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 0 CLOSED ORCL:ASMDISK11 0 0 CLOSED ORCL:ASMDISK12 0 0 CLOSED ORCL:ASMDISK13 0 1 CACHED ORCL:ASMDISK01 2304 1 CACHED ORCL:ASMDISK02 2304 1 CACHED ORCL:ASMDISK03 2304 1 CACHED ORCL:ASMDISK04 2304 2 CACHED ORCL:ASMDISK05 2304 2 CACHED ORCL:ASMDISK06 2304 2 CACHED ORCL:ASMDISK07 2304 2 CACHED ORCL:ASMDISK08 2304 GROUP_NUMBER MOUNT_S PATH TOTAL_MB ------------ ------- -------------------- ---------- 1 CACHED ORCL:ASMDISK09 2304 1 CACHED ORCL:ASMDISK10 2304➡️ CLOSED가 사용하지 않는 디스크라 여기에 추가해주어야함!!
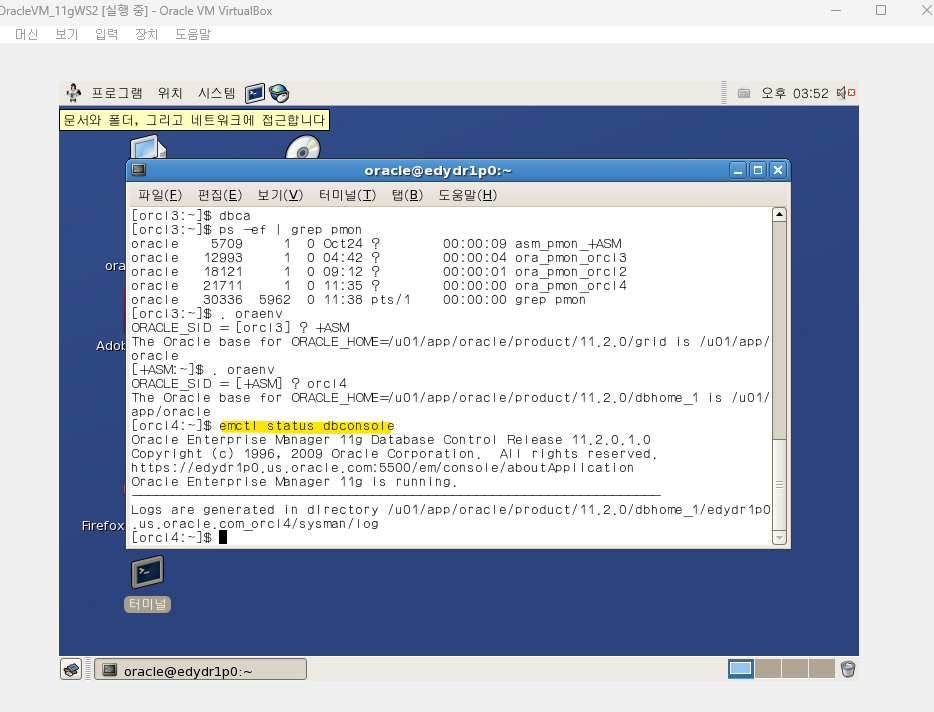
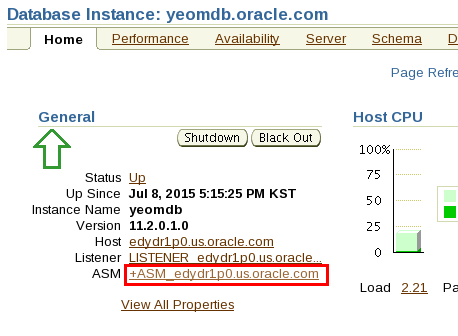
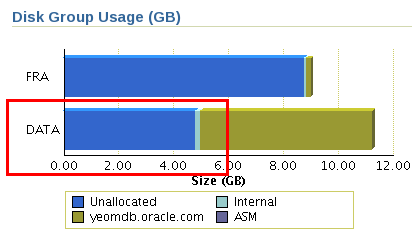
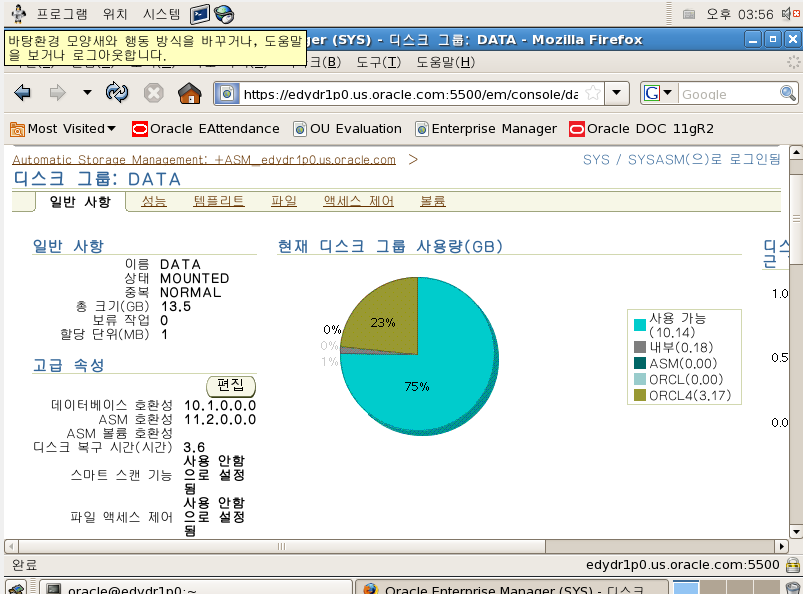
💡 EM 에서 증가한 테이블 스페이스 공간 확인하기
data 막대그래프 클릭하면 아래 화면이 나온다
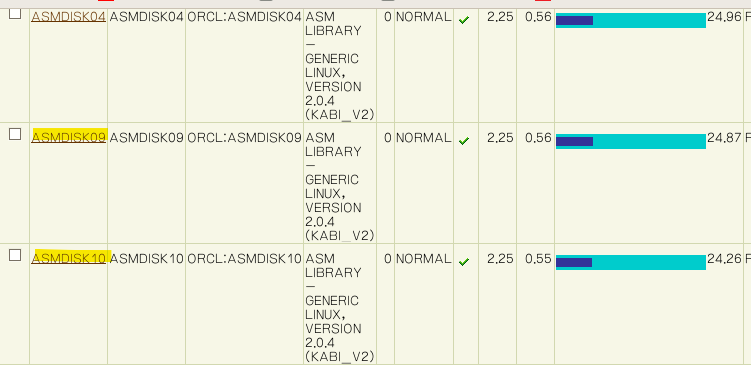
➡️ 새로 추가한 ASMDISK09 디스크의 사용량이 다른 Disk 의 사용량이 비슷해지는 것을 확인할 수 있다.
서서히 rebalancing 되면서 데이터가 골고루 분배되는 것이다. 이때 시스템이 조금 느려지는 현상을 볼 수 있다.
ASM 관리 쉘 스크립트 만들기
vi asm.sh✅ #!/bin/bash는 bash쉘 이라는 쉘 스크립트를 쓰겠다 라는 뜻. 가장 마지막에 나온 쉘이다!
✅ 아래 애들은 경로 지정.
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/grid
export ORACLE_SID=+ASM
export PATH=$ORACLE_HOME/bin:$PATH
#!/bin/bash
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/grid
export ORACLE_SID=+ASM
export PATH=$ORACLE_HOME/bin:$PATH
echo "
########## ASM Management List ##########
# #
# 1) Print ASM Diskgroup Storage Size #
# #
# 2) Print ASM Diskgroup Status #
# #
# 3) Print ASM Disk List #
# #
# 4) Add ASM Disk #
# #
#########################################"
echo -n "Enter your choice : "
read choice
case $choice in
1)
sqlplus -s / as sysasm <<EOF
select name, total_mb, free_mb
from v\$asm_diskgroup;
EOF
;;
2)
sqlplus -s / as sysasm <<EOF
select group_number, name, state
from v\$asm_diskgroup;
EOF
;;
3) sqlplus -s / as sysasm <<EOF
col path for a20
select group_number, mount_status, path, total_mb
from v\$asm_disk;
EOF
;;
4) echo -n "Input Disk Name : "
read dname
echo -n "Input Rebalance Power : "
read power
sqlplus -s / as sysasm <<EOF
alter diskgroup data
add disk '$dname' rebalance power $power;
EOF
;;
*)
echo "Enter [ 1, 2, 3, 4 ]"
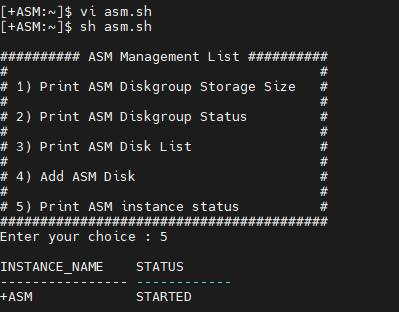
esac오늘의 마지막 문제 asm.sh 5번에 아래의 쿼리를 실행하는 문장을 추가하세요
select instance_name, status
from v$instance;#!/bin/bash
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/grid
export ORACLE_SID=+ASM
export PATH=$ORACLE_HOME/bin:$PATH
echo "
########## ASM Management List ##########
# #
# 1) Print ASM Diskgroup Storage Size #
# #
# 2) Print ASM Diskgroup Status #
# #
# 3) Print ASM Disk List #
# #
# 4) Add ASM Disk #
# #
# 5) Print ASM instance status #
#########################################"
echo -n "Enter your choice : "
read choice
case $choice in
1)
sqlplus -s / as sysasm <<EOF
select name, total_mb, free_mb
from v\$asm_diskgroup;
EOF
;;
2)
sqlplus -s / as sysasm <<EOF
select group_number, name, state
from v\$asm_diskgroup;
EOF
;;
3) sqlplus -s / as sysasm <<EOF
col path for a20
select group_number, mount_status, path, total_mb
from v\$asm_disk;
EOF
;;
4) echo -n "Input Disk Name : "
read dname
echo -n "Input Rebalance Power : "
read power
sqlplus -s / as sysasm <<EOF
alter diskgroup data
add disk '$dname' rebalance power $power;
EOF
;;
5) sqlplus -s / as sysasm <<EOF
select instance_name, status
from v\$instance;
EOF
;;
*)
echo "Enter [ 1, 2, 3, 4, 5 ]"
esac