
복습
1장.PL/SQL 소개
2장.PL/SQL 변수
3장.PL/SQL 실행문 작성
4장.PL/SQL 내에서의 DML문장(INSERT, UPDATE, DELETE..)
5장.IF문과 LOOP문
6장.조합 데이터 유형 변수(레코드, 컬렉션)
7장.명시적 커서
8장.예외처리
9장.프로시저와 함수
마지막장: 현업에서 사용하는 PL/SQL 프로시저
오늘의 TIL
- 서브 블록의 예외 전달
서브 블록의 예외 전달

서브블럭 사용하는 이유는, 하나의 PLSQL 안에 여러개의 업무를 넣으려고!
✅ 메인 블럭에서 선언한 사용자 정의 예외인 e_no_rows를 서브 블럭에서 사용할 수 있으면 서브블럭에서 e_no_rows예외를 raise시켜 메인 블럭의 exception절로 넘길 수 있습니다.
💡
복습!메인블럭에서 선언한 변수는 서브블럭에서 호출할 수 있지만, 서브블럭에서 선언한 변수는 메인블럭에서 호출할 수 없다.
RAISE_APPLICATION_ERROR 프로시저
➡️ 그냥 오류를 내버리고 프로그램 끝내버리는 것

declare
begin
실행문1; <------ 10억을 이체할 계좌번호를 받는 실행문
if 만약 유효한 계좌번호가 아니면 then
raise 사용자정의 예외처리;
실행문2; <------ 10억을 이체 시도하는 실행문 (★중요한 실행문★)
실행문3; <------
end;
/✅ 유효한 계좌번호가 아니라면 사용자정의 예외처리로 메세지 띄우고 끝나지만 실행문2에 혹시 insert나 update들이 수행될까봐 불안하다. 너무 중요한 실행문이라서!
이럴 때 RAISE_APPLICATION_ERROR를 사용하면 예외처리 단계에서 그냥 프로그램이 죽어버린다.
✅ 사용자 정의 예외처리 경우는 유효한 계좌번호가 아닙니다. 라는 메세지가 나오면서 두번째 실행문을 실행하지 않고 예외처리를 합니다. 그러면서 PLSQL이 정상적으로 처리되었다는 메세지가 나옵니다. 이것이 불안하다면 유효한 계좌번호가 아닐 시, 그자리에서 프로그램이 유언을 남기고 죽는것이 두번째 실행문을 실행하지 않았다는 가장 확실한 방법입니다. (RAISE_APPLICATION_ERROR 사용)
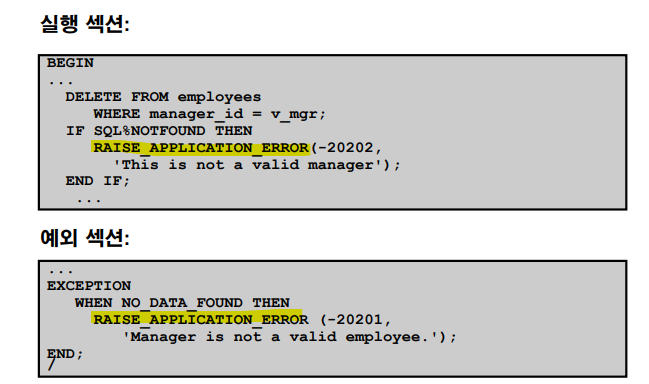
✏️ 예제 ! (프로시저 생성)
CREATE OR REPLACE PROCEDURE verify_emp (
p_empno NUMBER -- 9장에서 배울 프로시저 실행 관련 코드. 값을 입력받아 실행할 수 있는 코드
)
IS
v_ename emp.ename%TYPE;
v_job emp.job%TYPE;
v_mgr emp.mgr%TYPE;
v_hiredate emp.hiredate%TYPE;
BEGIN
SELECT ename, job, mgr, hiredate
INTO v_ename, v_job, v_mgr, v_hiredate FROM emp
WHERE empno = p_empno; -- 입력받은 사원번호 들어간다.(7788~)
-- 변수들이 null이면 프로그램 끝내버리겠다. (너무 중요한 정보라서)
IF v_ename IS NULL THEN
RAISE_APPLICATION_ERROR(-20010, 'No name for ' || p_empno);
END IF;
IF v_job IS NULL THEN
RAISE_APPLICATION_ERROR(-20020, 'No job for' || p_empno);
END IF;
IF v_mgr IS NULL THEN
RAISE_APPLICATION_ERROR(-20030, 'No manager for ' || p_empno);
END IF;
IF v_hiredate IS NULL THEN
RAISE_APPLICATION_ERROR(-20040, 'No hire date for ' || p_empno);
END IF;
-- 에러가 없으면 정상적으로 출력되었다 메세지 나온다.
DBMS_OUTPUT.PUT_LINE('Employee ' || p_empno ||
' validated without errors');
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('SQLCODE: ' || SQLCODE);
DBMS_OUTPUT.PUT_LINE('SQLERRM: ' || SQLERRM);
END;
/
CALL verify_emp(7839); -- CALL, EXIT해도 됨
SQLCODE: -438
SQLERRM: SQL0438N Application raised error or warning with
diagnostic text: "No manager for 7839". SQLSTATE=UD030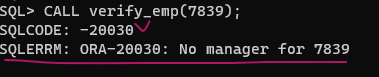
문제 108. 사원번호를 물어보게하고 해당 사원번호를 지우는 익명 PL/SQL 프로그램 작성
set verify off set serveroutput on accept p_empno prompt '사원번호를 입력하세요 ' declare v_empno emp.empno%type := &p_empno; v_cnt number(10); begin delete from emp where empno = v_empno; v_cnt := SQL%ROWCOUNT; dbms_output.put_line ( v_cnt ||' 행이 지워졌습니다'); end; /
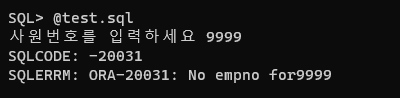
문제 109. 위 코드를 수정해서 없는 사원번호를 입력하면 다음과같이 출력되게 하시오!
사원번호를 입력하세요 -> 9999
SQLCODE: -20031
SQLERRM: ORA-20031: No empno for 9999
set verify off set serveroutput on accept p_empno prompt '사원번호를 입력하세요 ' declare v_empno emp.empno%type := &p_empno; v_cnt number(10); begin delete from emp where empno = v_empno; IF SQL%NOTFOUND THEN RAISE_APPLICATION_ERROR(-20031, 'No empno for' || v_empno); END IF; DBMS_OUTPUT.PUT_LINE('Employee ' || v_empno || ' validated without errors'); EXCEPTION WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('SQLCODE: ' || SQLCODE); DBMS_OUTPUT.PUT_LINE('SQLERRM: ' || SQLERRM); end; /
🤔 퀴즈 ! (정답1)

예외처리 요약
➡️ PL/SQL 예외 정의
➡️ PL/SQL 블록에 EXCEPTION 섹션을 추가하여 런타임에
예외 처리
➡️ 다양한 유형의 예외 처리:
– 미리 정의된 예외
– 미리 정의되지 않은 예외
– 유저 정의 예외
➡️ 중첩 블록 및 호출 응용 프로그램에서의 예외 전달
📖 9장 내장 프로시저 및 함수 소개
배우게 될 것들!
✅ 익명 블록과 서브 프로그램 구분
✅ 간단한 프로시저 작성 및 익명 블록에서 프로시저 호출
✅ 간단한 함수 작성
✅ 파라미터를 받아들이는 간단한 함수 작성
✅ 프로시저와 함수 구분
프로시저 및 함수

- 익명 PL/SQL과 프로시저와 함수와의 차이는 이름이 있느냐, 없느냐의 차이이다.
- 프로시저와 함수의 코드는 익명과 똑같은데 DECLARE 키워드가 없다.
익명 PL/SQL 블럭과 서브 PL/SQL 블럭의 차이
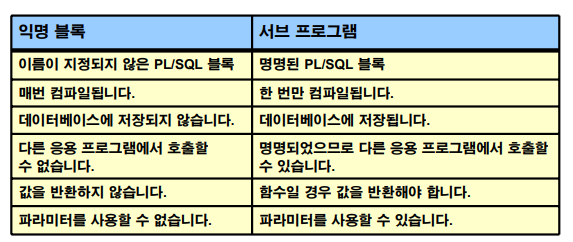
⭐ 익명블럭은 매번 컴파일된다. (우리가 알수있는 코드를 기계어로 바뀌는것)
: 기계어 란, 0과 1!
프로시저 생성 문법
CREATE [OR REPLACE] PROCEDURE procedure_name
[(argument1 [mode1] datatype1,
argument2 [mode2] datatype2,
. . .)]
IS|AS
procedure_body;✅ mode는 디폴트가 입력(in) 이지만 출력할 변수로도 쓸 수 있다. (in, out)
✅ 대괄호는 있어도 없어도 된다는 뜻. 입력매개변수 만드는 자리!
✅ IS 또는 AS 사용가능
✍🏻 예제
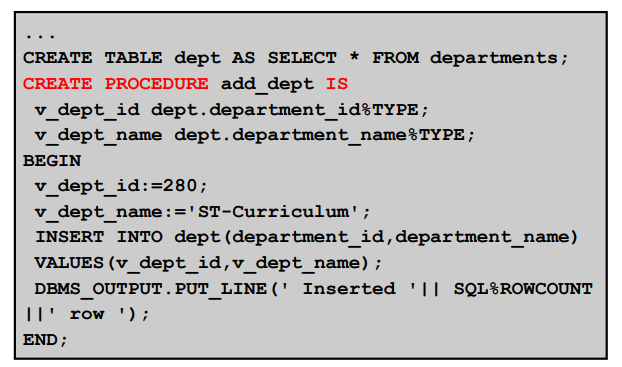
✍🏻 실습
- dept2 테이블을 dept 테이블의 구조로 생성한다.
create table dept2 as select * from dept where 1=2; select * from dept2; or desc dept2
- dept2 테이블에 데이터를 입력하는 프로시저를 생성한다.
create procedure pro1 is v_deptno dept2.deptno%type; v_dname dept2.dname%type; begin v_deptno := 10; v_dname := 'RESEARCH'; insert into dept2(deptno, dname) values(v_deptno, v_dname); dbms_output.put_line(SQL%ROWCOUNT || '행이 입력되었습니다!'); end; /
⭐ 프로시저가 생성되었다는 것은, PL/SQL코드 문법이 오류없이 잘 컴파일 되었다는 뜻이다. 그리고 프로시저 이름(예- pro1)으로 db에 PL/SQL을 저장한 것이다. 실행한것이 아니다!
⭐ 프로시저 실행은,EXEC나CALL명령어로 따로 해주어야한다.
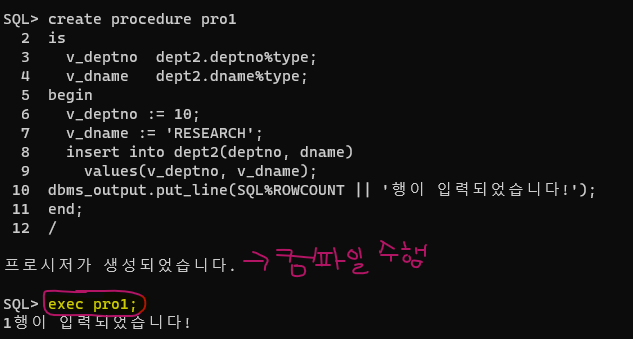
문제 110. [점심시간 문제] 지금 만든 pro1의 프로시저를 실행하는 코드를 작성하시오!
1. 첫번째 방법 :
exec pro1
2. 두번째 방법 :
begin
pro1;
end;
/입력 파라미터를 사용한 프로시저 생성하기
create or replace procedure pro1
( p_deptno dept2.deptno%type,
p_dname dept2.dname%type ) -- 이부분 추가!
is
v_deptno dept2.deptno%type;
v_dname dept2.dname%type;
begin
v_deptno := p_deptno; -- 이부분 수정
v_dname := p_dname;
insert into dept2(deptno, dname)
values(v_deptno, v_dname);
dbms_output.put_line(SQL%ROWCOUNT || '행이 입력되었습니다!');
end;
/
문제 111. 아래와 같이 프로시저를 수행하면 해당 부서번호의 사원들의 커미션이 자신의 월급의 20%로 갱신되는 프로시저를 생성하시오!
exec pro2(20);
// 4명의 데이터가 갱신되었습니다.create or replace procedure pro2 ( p_deptno emp.deptno%type) is begin update emp set comm = sal * 0.2 where deptno = p_deptno; dbms_output.put_line(SQL%ROWCOUNT || '행이 갱신되었습니다!'); end; /✅ 익명블럭이랑다른점은 p_deptno앞에
&가 없다.
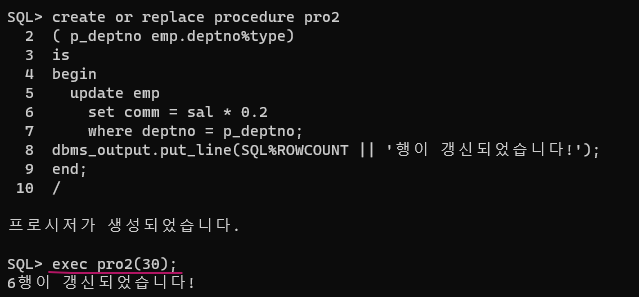
문제 112. 위 프로시저에 예외처리를 해서 다음과 같이 실행하면, 해당 부서번호는 없는 부서입니다. 라고 출력되게 하시오!
exec pro2(70);
해당 부서번호는 없는 부서입니다.
create or replace procedure pro2 ( p_deptno emp.deptno%type ) is e_exception exception ; begin update emp set comm = sal * 0.2 where deptno = p_deptno; if SQL%NOTFOUND then raise e_exception; end if; dbms_output.put_line ( SQL%ROWCOUNT || ' 행이 갱신되었습니다'); exception when e_exception then dbms_output.put_line('해당 부서번호는 없는 부서입니다'); end; /

함수
✍🏻 문법
CREATE [OR REPLACE] FUNCTION function_name
[(argument1 [mode1] datatype1,
argument2 [mode2] datatype2,
. . .)]
RETURN datatype -- ⭐RETURN 무조건 있어야한다.⭐
IS|AS
function_body;✅ 함수는 무조건 결과를 null값이라도 리턴한다.
✍🏻 예제
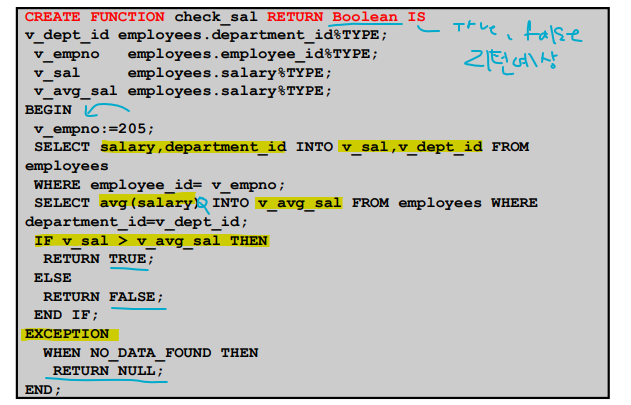
✍🏻 예제 실습
월급이 3000 이상이면 A를 리턴하고, 월급이 2000 이상이면 B를 리턴하고, 월급이 1000 이상이면 C를 리턴하고, 나머지는 D리턴하는 함수를 생성하시오!
create or replace function func1
( p_sal emp.sal%type )
return varchar2 -- 리턴되는게 A,B,C..문자라서 varchar2 !! 숫자는 number 가로열고 쓰는거 없다.
is
v_grade varchar2(5);
begin
if p_sal >= 3000 then
v_grade := 'A';
elsif p_sal >= 2000 then
v_grade := 'B';
elsif p_sal >= 1000 then
v_grade := 'C';
else
v_grade := 'D';
end if;
return v_grade;
end;
/
-----------
select ename, sal, func1(sal)
from emp;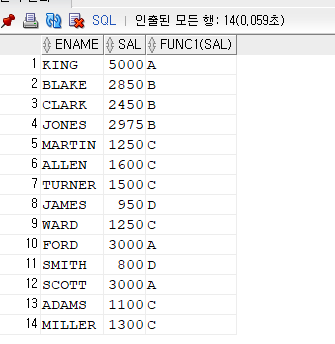
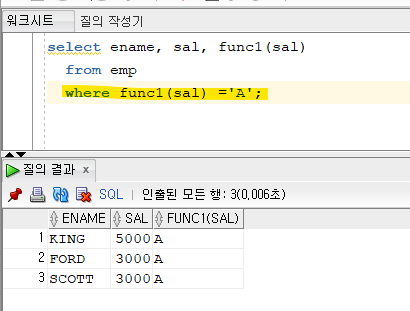
✅ 사용자 정의 함수를 생성하게되면, SQL을 아주 심플하게 작성할 수 있게된다.
문제 113. 다음과 같이 SQL을 수행하면 결과가 출력되는 함수를 생성하시오!
select ename, sal, job, find_loc(deptno)
from emp;
// KING 5000 PRESIDENT NEW YORK내 답
create or replace function find_loc ( p_deptno emp.deptno%type ) return varchar2 is v_loc dept.loc%type; begin select loc into v_loc from dept where deptno = p_deptno; return v_loc; end; /쌤 답
create or replace function find_loc ( p_deptno emp.deptno%type ) return varchar2 is v_loc dept.loc%type; begin if p_deptno = 10 then v_loc := 'NEW YORK'; elsif p_deptno = 20 then v_loc := 'DALLAS'; elsif p_deptno = 30 then v_loc := 'CHICAGO'; else v_loc := 'BOSTON'; end if; return v_loc; end; /✅ 사용자 정의 함수의 장점: SQL을 아주 심플하게 작성할 수 있다. 조인을 사용하지 않고 조인된 결과를 볼 수 있다.
문제 114. 달라스에서 근무하는 사원들의 이름, 월급, 부서위치를 출력하시오
select ename, sal, find_loc(deptno) from emp where find_loc(deptno) = 'DALLAS';
문제 115. (튜닝전 SQL) 부서번호, 부서번호별 평균월급을 출력하세요
select deptno, round(avg(sal)) from emp group by deptno;
문제 116. 이름, 월급, 자기가 속한 부서번호의 평균월급을 출력하시오!
// 1. 스칼라 서브쿼리 select ename, sal, ( select avg(sal) from emp where deptno = o.deptno) from emp o; -------------------------- // 2. partition by 사용 select ename, sal, avg(sal) over (partition by deptno) 평균월급 from emp;
문제 117. 이름, 월급, 자기가 속한 부서번호의 평균 월급을 출력하는데 자기의 월급이 자기가 속한 부서번호의 평균월급보다 더 큰 사원들만 출력
// from절 서브쿼리 select ename, sal, 평균월급 from ( select ename, sal, avg(sal) over (partition by deptno) 평균월급 from emp ) where sal > 평균월급;
문제 118. 부서번호를 입력, 실행하면 해당 부서번호의 평균월급이 출력되는 사용자 정의 함수를 생성하기
create or replace function deptno_avgsal ( p_deptno emp.deptno%type ) return number is v_avgsal number(10,2); begin select avg(sal) into v_avgsal from emp where deptno = p_deptno; return v_avgsal; end; /
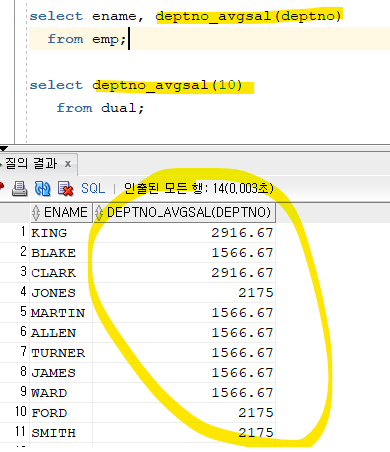
문제 119. 위에 만든 함수를 이용해서 아래의 sql을 튜닝하세요
튜닝 전
select ename, sal, 평균월급
from (
select ename, sal, avg(sal) over (partition by deptno) 평균월급
from emp
)
where sal > 평균월급;튜닝 후
select ename, sal, deptno_avgsal(deptno) from emp;✅ 사용자정의함수를 너무많이 쓰면 느려진다.
9장 요약
이 단원에서는 다음 항목에 대해 배웠습니다!
➡️ 간단한 프로시저 작성
➡️ 익명 블록에서 프로시저 호출
➡️ 간단한 함수 작성
➡️ 파라미터를 받아들이는 간단한 함수 작성
➡️ 익명 블록에서 함수 호출 (근데 우리는 sql에서 호출해보았다)
PL/SQL을 현업에서 어떻게 활용하는지 사례
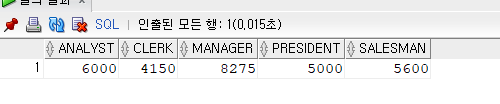
문제 120. (SQL문제) 직업, 직업별 토탈월급을 출력하는데 가로로 출력하세요!
select sum(decode (job, 'ANALYST', sal, null) ) as "ANALYST", sum(decode (job, 'CLERK', sal, null) ) as "CLERK", sum(decode (job, 'MANAGER', sal, null) ) as "MANAGER", sum(decode (job, 'PRESIDENT', sal, null) ) as "PRESIDENT", sum(decode (job, 'SALESMAN', sal, null) ) as "SALESMAN" from emp;
문제 121. (SQL문제) 위 SQL로 부서번호별 직업별 토탈월급을 출력하시오
select deptno, sum(decode (job, 'ANALYST', sal, null) ) as "ANALYST", sum(decode (job, 'CLERK', sal, null) ) as "CLERK", sum(decode (job, 'MANAGER', sal, null) ) as "MANAGER", sum(decode (job, 'PRESIDENT', sal, null) ) as "PRESIDENT", sum(decode (job, 'SALESMAN', sal, null) ) as "SALESMAN" from emp group by deptno;

문제 122. 위 결과를 프로시저로 수행하시오
// 프로시저를 만드는 부분 create or replace procedure get_data --get_data은 프로시저 이름 -- p_x는 파라미터, out자리는 in도 쓸수있는데 in이 디폴트값이라 지금까지 생략했던 것. -- out은 프로시저를 실행했을 때 결과를 담아내는 것이다. -- in은 입력값을 담아서 결과를 출력하는 것 -- 테이블처럼 생긴 표 데이터를 담아내려고 refcursor 를 썼다. (p_x out sys_refcursor) -- 이 코드는 결과테이블을 담을 변수 선언 as -- 400 바이트를 넣은 이유는, 121번 문제의 sum+decode 코드를 다 넣을거라서 l_query varchar2(400) :='select deptno '; begin for x in (select distinct job from emp order by 1) loop -- 실행문! 위 x가 salesman일 때 실행문 실행, clerk일때 실행문 실행.... l_query := l_query ||replace(', sum(decode(job,''$X'',sal)) as $X ' ,'$X',x.job ); end loop; l_query := l_query ||' from emp group by deptno '; open p_x for l_query; end; / // 프로시저를 실행하는 부분 variable x refcursor; -- variable를 사용해서 만든 변수는 호스트변수(바인드변수) exec get_data(:x); print x;
x가 analyst일 때?
l_query || replace(', sum(decode(job,''X'',sal)) as $X ' ,'X',x.job );
select deptno 위에서 할당했으니까
select deptno || , sum(decode(job,''$X'',sal)) as $X --라는 문자열 . 얘를 x.job으로 리플레이스 하겠다.
l_query := 'select deptno , sum(decode(job, 'ANALYST', sal)) as ANALYST'
x가 CLERK일 때?
'select deptno , sum(decode(job, 'ANALYST', sal)) as ANALYST'
|| replace(', sum(decode(job,''X'',sal)) as $X ' ,'X',x.job );
위 아래쪽 문장은 아래와 같다.
, sum (decode(job, 'CLERK',sal) ) as CLERK
두개를 이어붙히면,
select deptno , sum(decode(job, 'ANALYST', sal)) as ANALYST , sum (decode(job, 'CLERK',sal) ) as CLERK
x가 MANAGER일 때?
select deptno ,sum(decode(job, 'ANALYST', sal)) as ANALYST , sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'MANAGER',sal) ) as MANAGER
x가 SALESMAN일 때?
select deptno ,sum(decode(job, 'ANALYST', sal)) as ANALYST , sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'MANAGER',sal) ) as MANAGER
,sum (decode(job, 'PRESIDENT',sal) ) as PRESIDENT
,sum (decode(job, 'SALESMAN',sal) ) as SALESMAN
END LOOP를 만나고 l_query := l_query ||' from emp group by deptno ';를 만나면
select deptno ,sum(decode(job, 'ANALYST', sal)) as ANALYST , sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'CLERK',sal) ) as CLERK
,sum (decode(job, 'MANAGER',sal) ) as MANAGER
,sum (decode(job, 'PRESIDENT',sal) ) as PRESIDENT
,sum (decode(job, 'SALESMAN',sal) ) as SALESMAN
from emp
group by deptno;
가 되는것이다.
open p_x for l_query; 를 통해 l_query의 sql결과를(위코드) p_x커서에 할당합니다.
✅ replace(컬럼, 변경전, 변경후)
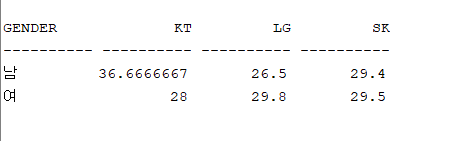
문제 123. (SQL문제) 우리반 테이블로 아래의 결과를 출력하세요
성별별, 통신사별 평균 나이 출력
select gender, avg(decode (telecom, 'kt', age, null) ) as "kt", avg(decode (telecom, 'lg', age, null) ) as "lg", avg(decode (telecom, 'sk', age, null) ) as "sk" from emp17 group by gender;
문제 124. 위 결과를 프로시저로 작성해서 수행하시오
create or replace procedure get_data2 --get_data은 프로시저 이름 (p_i out sys_refcursor) as l_query varchar2(400) :='select gender '; begin for i in (select distinct telecom from emp17 order by 1) loop l_query := l_query ||replace(', avg(decode(telecom,''$I'',age)) as $I ' ,'$I',i.telecom ); end loop; l_query := l_query ||' from emp17 group by gender '; open p_i for l_query; end; / -------------------------------------------------------------------------------- variable i refcursor; exec get_data2(:i); print i;
✅ 왜i.telecom를 썼는가!? -> kt.telecom, lg.telecom ...하게되기 위해
원래 for i in 1.. 10 이라고 썼다면 출력할 때 i만 써도 되는데, 지금은 컬럼에서 선택하는거라서!begin for i in 1.. 10 loop dbms_output.put_line(i) end loop; end; /✅ 리플레이스 쪽에 달러표시 없어도 된다.
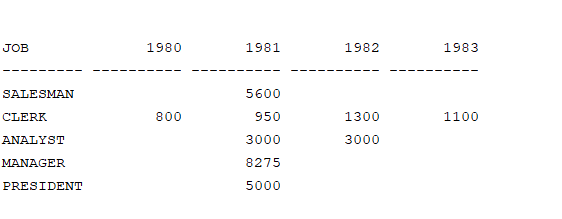
문제 125. 아래의 SQL의 결과를 프로시저로 구현하기
select job,
sum(decode(to_char(hiredate,'RRRR'), '1980',sal) ) "1980",
sum(decode(to_char(hiredate,'RRRR'), '1981',sal) ) "1981",
sum(decode(to_char(hiredate,'RRRR'), '1982',sal) ) "1982",
sum(decode(to_char(hiredate,'RRRR'), '1983',sal) ) "1983"
from emp
group by job;create or replace procedure get_data5 (p_i out sys_refcursor) as l_query varchar2(1000) :='select job '; begin for i in (select distinct to_char(hiredate,'RRRR')as hiredate from emp order by 1) loop l_query := l_query ||replace(', sum(decode(to_char(hiredate,''RRRR''),''$I'',sal)) as "$I" ' ,'$I',i.hiredate); end loop; l_query := l_query ||' from emp group by job '; open p_i for l_query; end; / ------------------------------------------------------------------- variable i refcursor; exec get_data5(:i); print i;

좋은 글 감사합니다.