📖 6장. RAC 성능 튜닝
✔️ RAC 성능 튜닝 목차
- RAC 튜닝 요소
- RAC 에서의 instance recovery 튜닝
- Cache Fusion 알고리즘
- RAC 환경에서의 대기이벤트
- RAC 성능 튜닝 팁
- RAC 환경에서 3가지 레포트 사용하는 방법
* Awr report * Addm report * ASH report
✏️ 1. RAC 튜닝 요소
💡 RAC에서는 SQL 튜닝 만으로는 안되는 것이 있다. 그래서 아키텍쳐를 아는것이 중요.
❓ db를 튜닝 한다는 것은, 응답시간을 줄이는 것이다.
response time = cpu time + wait time (응답시간) (서비스 시간) (대기한 시간) ex) 점심시간 = 밥먹는 시간 + 메뉴 나오는 시간➡️ 응답시간이 느리다는 것은 서비스 시간이 느리다기 보다는 대기한 시간이 느린것이 더 영향이 크다.
➡️ 튜닝의 목표 : wait time (대기 시간)을 줄이는 것
💡 RAC 환경에서 튜닝 요소 3가지
1. instance recovery 튜닝
2. interconnect traffic 튜닝
3. global 동기화 작업에 대한 경합 튜닝
✔️ instance recovery 튜닝
✅ instance recovery란 갑자기 db가 먹통이 되었을 때 shutdown abort 해야하는데, 그럴 때 다시 db를 startup 하면 한참동안을 instance 복구를 오라클이 수행합니다.
현업에서는 과도한 DB 작업이 있었을 때 shutdown abort로 내리고 startup하면 db가 되게 느려집니다.
노드#1 ---------------------------------- 노드#2
비정상 종료 instance recovery
(shutdown abort) ↓
1. rollback
2. rollforward➡️ instance recovery는 두가지를 수행한다. rollback, rollforward
rollback: update했는데 commit 하지 않은 것을 rollback하는 작업rollforward: commit 했는데 data file에 반영 안된거 반영하는 작업
💡 2번 노드에서 빠르게 instance recovery를 수행할 수 있도록 튜닝을 할 수 있을까?
➡️ 아래의 2개의 파라미터에 설정된 시간만큼만 instance recovery 할 수 있도록 설정한다. ex) 1번 5분, 2번 5분이면 10분!!!!
1.
_fast_start_instance_recovery_target: GRD가 재구성 되는 시간
:_는 히든(hidden) 파라미터 이다. 이유는 오라클이 알아서 할게 건들지마!
:GRD(Global Resource Directory)는 내가 검색하고자 하는 최신 데이터가 어느 노드에 있는지 위치정보가 있는 저장소이다.#1번 노드 #2번 노드 GRD GRD emp 테이블 위치관리 dept 테이블 위치 관리✅ 위 상황에서 1번 노드가 꺼진다면 emp 테이블의 위치가 2번 노드쪽으로 오는데 이때 걸리는 시간을
_fast_start_instance_recovery_target이라 한다.2.
fast_start_mttr_target: instance recovery에 걸리는 시간. 싱글 인스턴스 일때는 얘만 설정해주면 된다 !
히든 파라미터 확인하는 쿼리
실습 _fast_start_instance_recovery_target 파라미터 셋팅값을 확인하기! show parameter로 볼 수 없고 히든 파라미터를 보는 쿼리로 보아야한다.
col "Parameter" format a40
col "Session Value" format a15
col "Instance Value" Format a15
select a.ksppinm "Parameter",
b.ksppstvl "Session Value",
c.ksppstvl "Instance Value"
from x$ksppi a, x$ksppcv b, x$ksppsv c
where a.indx = b.indx and a.indx = c.indx
and a.ksppinm like '%¶m_name%';➡️ 안나옴
fast_start_mttr_target은 어어떻게 설정되어 있는지 확인!
show parmeter fast_target
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_io_target integer 0
fast_start_mttr_target integer 00으로 되어있는 것은 instance recovery를 오라클이 알아서 최적으로 빨리 해라 라고 맡기는 것 (자동)
문제 fast_start_mttr_target을 600으로 설정!
select name, issys_modifiable from v$parameter where name like '%fast_start%'; fast_start_mttr_target IMMEDIATE -- both가능 SYS @ racdb1 > alter system set fast_start_mttr_target=600 scope=both sid='*'; System altered. SYS @ racdb1 > show parameter fast_start NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ fast_start_io_target integer 0 fast_start_mttr_target integer 600
문제 _fast_start_instance_recovery_target 를 60으로 설정
(진행안함)
✔️ interconnect traffic 튜닝
💡 interconnect 의 부하로 인해 성능이 느려지는 원인이 발생하지 않도록 튜닝
- 인터커넥트 하드웨어를 비싼걸로 설정한다.
- 1gb 비트 이더넷 (초당 125mb의 전송 속도를 보장)
- 10gb 비트 이더넷
- 100gb 비트 이더넷 (인피니밴드)
- 요즘 RAC 19c 구현하는 곳은 대부분 사용
- interconnect 가
private ip를 쓰는게 맞는지 확인
- RAC 에서 사용하는 IP 주소 4가지?
Public ip: 외부에서 rac로 접속할 때 사용하는 ipprivate ip: interconnect를 통해 통신할 때 사용하는 ipvirtual ip: failover 할 때 사용하는 ipscan ip: scan listener가 사용하는 ip
❓ RAC를 설치하고 가장 먼저 해야할 일
1. failover 테스트
2. interconnect 가 private ip가 맞는지
💡 interconnect 가 private ip가 맞는지 확인하는 명령어
✔️ $GRID_HOME/bin/oifcfg 명령어를 이용한 방법
[oracle@racdb1 ~]$ oifcfg getif eth0 10.0.2.0 global public eth1 192.168.56.0 global cluster_interconnect➡️ 명령어 수행 결과 eth1 NIC가 인터커넥트용임을 알 수 있다.
[oracle@racdb1 ~]$ oifcfg iflist -p -n eth0 10.0.2.0 PRIVATE 255.255.255.0 eth1 192.168.56.0 PRIVATE 255.255.255.0 eth1 169.254.0.0 UNKNOWN 255.255.0.0 -- private를 백업하는 ip 주소➡️ 명령어 수행 결과 eth1에는 2개의 IP 대역이 설정되어 있음을 알 수 있습니다.
169.254.0.0은 11gR2부터 제공되는HAIP 대역대입니다. 따라서 명령어 수행결과 에 169.254.0.0이 출력된다면 해당 시스템은 HAIP를 사용하는 것.✔️
X$KSXPIA fixed테이블 및GV$CLUSTER_INTERCONNECTS 뷰를 이용한 방법-- 1. select pub_ksxpia as is_public, name_ksxpia as name, ip_ksxpia as ip_address from x$ksxpia; IS_PUBLIC NAME IP_ADDRESS ---------- --------------- ---------------- N eth1:1 169.254.215.245 Y eth0 10.0.2.15 Y eth0:1 10.0.2.111 -- 2. select inst_id, name, ip_address, is_public from gv$cluster_interconnects order by inst_id; INST_ID NAME IP_ADDRESS IS_ ---------- --------------- ---------------- --- 1 eth1:1 169.254.215.245 NO 2 eth1:1 169.254.213.137 NO➡️ 쿼리 수행 결과를 통해 인터커넥트용 NIC는 eth1:1이며 실제 IP도 확인할 수 있다.
여기서 보이는 인터커넥트용 IP가 /etc/hosts 파일에 설정한 private ip와 다른 경우에는 11gR2부터 제공하는 HAIP를 사용하고 있다고 보면 됨.✔️ ed /u01/app/oracle/diag/rdbms/racdb/racdb1/trace/racdb1_ora_24882.trc 열어서 확인하기 (HAIP이 적어져있음)
$ cat /etc/hosts ### Private 192.168.56.111 rac1-priv 192.168.56.112 rac2-priv SQL> oradebug setmypid SQL> oradebug ipc SQL> oradebug tracefile_name /u01/app/oracle/diag/rdbms/racdb/racdb1/trace/racdb1_ora_24882.trc SQL> ed /u01/app/oracle/diag/rdbms/racdb/racdb1/trace/racdb1_ora_24882.trc SKGXP:[7f34ac123a68.43]{ctx}: SSKGXPT 0x7f34ac124fd8 flags 0x0 sockno 4 IP 169.254.215.245 UDP 61299 lerr 0
문제 2번 노드에서도 위 작업을 수행하여 인터커넥트 ip가 private ip가 맞는지 확인하기
SYS @ racdb2 > select pub_ksxpia as is_public, name_ksxpia as name, ip_ksxpia as ip_address 2 from x$ksxpia; IS_PUBLIC NAME IP_ADDRESS ---------- --------------- ---------------- N eth1:1 169.254.213.137 Y eth0 10.0.2.16 Y eth0:2 10.0.2.120 Y eth0:3 10.0.2.112 SYS @ racdb2 > select inst_id, name, ip_address, is_public 2 from gv$cluster_interconnects 3 order by inst_id; INST_ID NAME IP_ADDRESS IS_ ---------- --------------- ---------------- --- 1 eth1:1 169.254.215.245 NO 2 eth1:1 169.254.213.137 NO SYS @ racdb2 > oradebug setmypid SYS @ racdb2 > oradebug ipc SYS @ racdb2 > oradebug tracefile_name /u01/app/oracle/diag/rdbms/racdb/racdb2/trace/racdb2_ora_26283.trc $ ed /u01/app/oracle/diag/rdbms/racdb/racdb2/trace/racdb2_ora_26283.trc SKGXP:[7f36c14b3a68.49]{ctx}: SSKGXPT 0x7f36c14b4fd8 flags 0x0 sockno 4 IP 169.254.213.137 UDP 57019 lerr 0
3. MTU 사이즈 확인
: 하드웨어 적으로 한번에 네트워크를 통해서 전송할 수 있는 패킷의 최대 크기 (1500이나 그 이상으로 되어있는지 확인)
$ netstat -i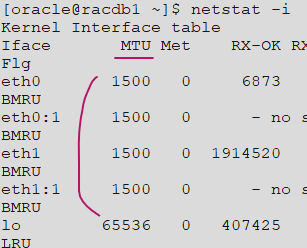
4. LMS 프로세서의 친절도(NICE)를 확인
💡LMS 프로세서의 역할은 노드간의 데이터 전송하는 프로세서이다.
친절도(NICE)란 cpu를 다른 프로세서에게 양보하는 친절도이다.(-20~20) 자기가 써야하는데 다른 프로세서에게 계속 양보하면 X
ps -ef | grep lms -- 프로세서의 번호 확인
grid 21631 1 0 12:52 ? 00:00:22 asm_lms0_+ASM1
oracle 24093 1 0 14:25 ? 00:00:06 ora_lms0_racdb1
oracle 24097 1 0 14:25 ? 00:00:07 ora_lms1_racdb1
oracle 24101 1 0 14:25 ? 00:00:07 ora_lms2_racdb1
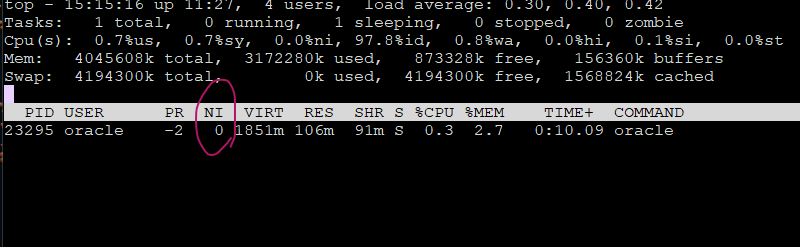
$ top -p 24093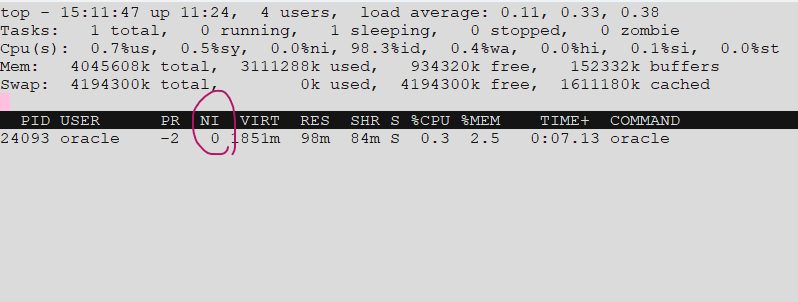
실습 root로 접속해서 친절도를 -20으로 변경하기
renice -20 -p 프로세서 번호
[root@rac1 ~]# renice -20 -p 24093
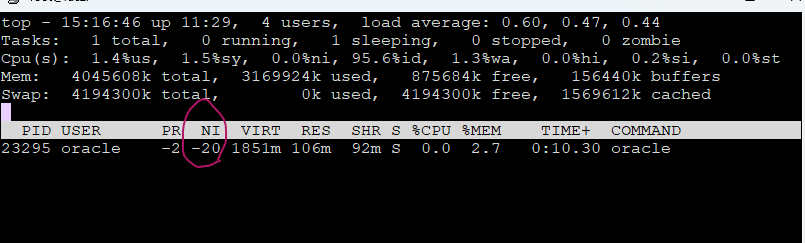
[root@rac1 ~]# top -p 24093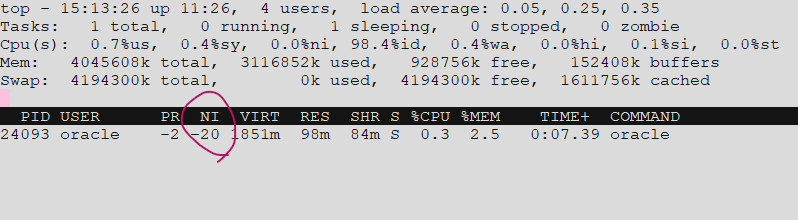
문제 2번 노드의 lms프로세서의 친절도를 -20으로 낮추기
1. lms 번호 확인
[oracle@racdb2 ~]$ ps -ef | grep lms grid 15861 1 0 10:23 ? 00:00:46 asm_lms0_+ASM2 oracle 23295 1 0 14:02 ? 00:00:09 ora_lms0_racdb2 oracle 23299 1 0 14:02 ? 00:00:10 ora_lms1_racdb2 oracle 23303 1 0 14:02 ? 00:00:10 ora_lms2_racdb2 oracle 25113 19597 0 15:14 pts/0 00:00:00 grep lms top -p 23295
- root 계정에서 친절도를 -20으로 변경
[root@rac2 ~]# renice -20 -p 23295 [root@rac2 ~]# top -p 23295
✔️ global 동기화 작업에 대한 경합 튜닝
📖 RAC service의 종류
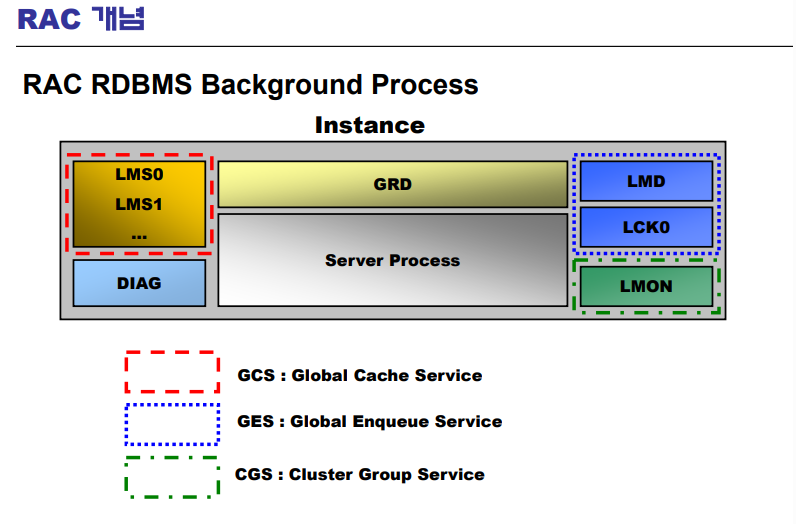
💡 data buffer cache 가 각각 노드에 있는데 이것을 하나로 연결해주려면 서로 전송을 해주는 애들이 있어야 한다. 그것이 LMS데몬 이고 GCS라고 함!
💡 인큐는 여러 lock을 가르키는 말이다. 글로벌한 락을 관리하는 데몬들이 LMD, LCK0
➡️ RAC의 서비스는 세가지가 있는데,
GCS,GES,CGS이다.
1.GCS는 LMS 데몬이 있다.
2.GES는 LMD, LCK0이 있다.
3.CGS는 LMON이 있다.


✏️ 1. global cache동기화
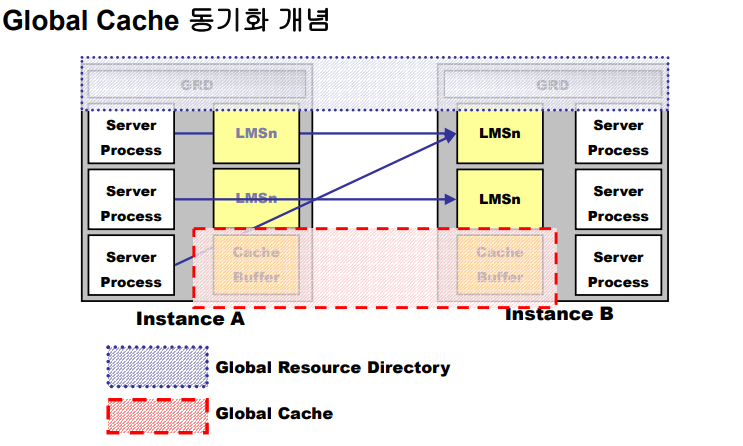
✔️ GRD : Global Resource Directory
: Global Resource의 위치 및 상태를 관리하는 분산 Database
✔️ Global Cache
: RAC에서는 여러 Instance의 Cache가 협동하여 Global Cache를 구성
✔️ Cache Fusion
: Oracle의 Global Cache 동기화 방법론
: Disk가 아닌 Interconnect를 통한 Block 전송과 Memory 동기화
1. GRD 관련
✔️ 1.
GRDGlobal Resource Directory
- Global Buffer 목록 관리를 위한 분산 Database (emp table은 어디서 관리, dept table은 어디서 관리..)
- 모든 Block의 정보는 Block이 속한 Master Node의 GRD에서 관리
✔️ 2. GRD가 관리하는 정보
- { DBA + Holder 위치 + Mode(Null, Shared, Exclusive) + Role(Local/Global) + SCN + PI 여부 }
- Mode: Block을 사용하기 위해 Lock을 획득한 Mode를 의미
– N(Null): 읽어 들인 후 다른 Instance에 의해 Lock이 획득된 상태 – S(Shared): 읽기 목적으로 Lock을 획득한 상태 – X(Exclusive): 쓰기 목적으로 Lock을 획득한 상태
- Role
– Local: Global 공유가 이루어지지 않은 상태 – Global: Global 공유가 이루어진 상태
2. Global Cache 관련
💡 RAC에서는 여러 Instance의 Cache가 협동하여 Global Cache를 구성
: 각 노드에 버퍼캐시를 연결해주는..
3. Cache Fusion관련

💡 Cache Fusion이 뭐냐(그림설명) 노드가 3개인 상황
: Request Node, Master Node, Holder Node가 Interconnect를 통해 Block/Message를 교환하는 Mechanism
마스터 노드는 emp 테이블의 최신 데이터가 어디에 있는지 아는 위치정보가있다.(GRD가 알고있음)
리퀘스트 노드는 만약 여기서 누가 emp 테이블을 select를 하면 리퀘스트 노드가 된다. 먼저 본인의 GRD를 먼저 본다. emp정보가 있는지
없다면 server process가 위쪽 GRD가서 물어본다. 마스터 노드 LMS가 holder Node에게 포워드를 해준다. emp테이블 너한테 있네? 너가 저 select 문에 대한 데이터 전달좀 해줘.
그러면 Holder Node가 Request Node에게 알려준다. LMS를 통해.
1 -> 2 갈때는 메세지가 전달된다. 있니?
2 -> 3 갈때도 메세지가 전달된다. 니가 가지고 있잖아 넘겨주렴
3 -> 1 데이터를 넘겨준다.

만약 그 어디에도 emp 테이블에 대한 정보가 없다면 스스로 디스크에서 데이터 가져올 수 있도록 권한을 준다.
✔️
Request Node: Master Node에게 Block 전송을 요청하는 Node
✔️Master Node: Block의 최신 정보를 관리하는 Node. Block의 최신
정보는 Master Node의 GRD에 저장
✔️Holder Node: 최신 Block Image를 가지고 있는 Node
✅ mode 설명
null mode : 이자리 내꺼 찜
shared mode : 읽기 목적. 자리에 앉았다! - 공유 가능한 lock.
Exclusive mode : 쓰기 목적으로 Lock을 획득한 상태. 컴퓨터를 썼다!
✅ RAC cache fusion 알고리즘
1. read to read with transfer: 다른 노드에서 요청해서 가지고 있는 이미지는 null 모드로 바꾸지 않고shared mode로 두는데 이걸 read to read with transfer라고 한다.
2. Read-to-Write With Transfer: emp 테이블을 update 하려고 master한테 부탁하면 holder가 이미지 전달해주면서 holder는null mode로 변하고 요청한 노드에는Exclusive가 된다. 왜냐면 최신 데이터니까!
3. Write-to-Read With Transfer (Commit 이후): 만약 위 상태에서 null mode인 노드가 emp table을 select 하려고 이미지를 요청했다. 그리고 emp 데이터를 가지고 있는 노드가 블럭을 전송한다면 둘다 shared mode로 바뀌지 않고,null mode이다. 4번 select를 반복해야 shared mode로 바뀐다!
⭐ Cache fusion test !
RAC cache fusion 알고리즘중에 첫번째인 initial read with no transfer 실습
✔️ 환경구성
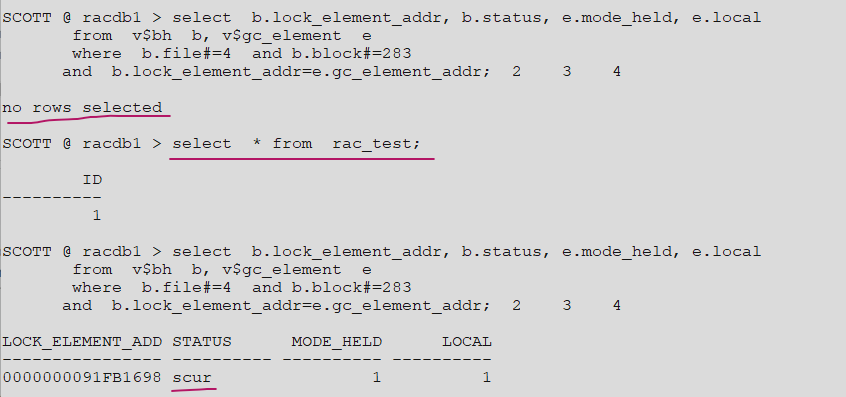
SQL#1> create table rac_test ( id number ); SQL#1> insert into rac_test values(1); SQL#1> commit; -- rac_test 테이블의 파일 번호와 블럭번호를 알아내는 명령어 SQL#1> select dbms_rowid.rowid_relative_fno(rowid) as fno, dbms_rowid.rowid_block_number(rowid) as blkno from rac_test; FNO BLKNO ---------- ---------- 4 283 SQL#1> select b.lock_element_addr, b.status, e.mode_held, e.local from v$bh b, v$gc_element e where b.file#=4 and b.block#=283 and b.lock_element_addr=e.gc_element_addr; LOCK_ELEMENT_ADD STATUS MODE_HELD LOCAL ---------------- ---------- ---------- ---------- 0000000091FB1698 xcur 2 1 -- 1번째 select ! null mode일 것이다. SQL#2> select * from rac_test ; SQL#2> select b.lock_element_addr, b.status, e.mode_held, e.local from v$bh b, v$gc_element e where b.file#=4 and b.block#=283 and b.lock_element_addr=e.gc_element_addr; -- 2번째 select ! shared mode일 것이다. SQL#2> select * from rac_test ; SQL#2> select b.lock_element_addr, b.status, e.mode_held, e.local from v$bh b, v$gc_element e where b.file#=4 and b.block#=283 and b.lock_element_addr=e.gc_element_addr; SQL#1> alter system flush buffer_cache; SQL#2> alter system flush buffer_cache;
✔️ 1. initial read with no transfer 실습
SQL#1> select b.lock_element_addr, b.status, e.mode_held, e.local from v$bh b, v$gc_element e where b.file#=4 and b.block#=283 and b.lock_element_addr=e.gc_element_addr; -- null 모드 SQL#1> select * from rac_test; SQL#1> select b.lock_element_addr, b.status, e.mode_held, e.local from v$bh b, v$gc_element e where b.file#=4 and b.block#=283 and b.lock_element_addr=e.gc_element_addr; -- shared 모드