오라클 관리 수업
1장. 오라클 데이터베이스 구조 탐색
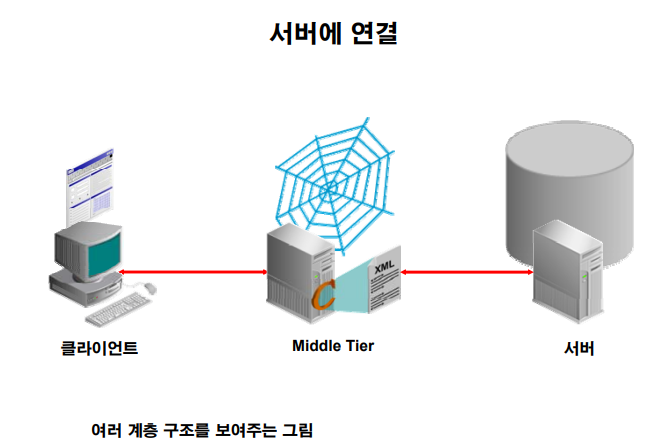
서버에 연결하는 구조
✔️ two tier 환경
클라이언트 -------> 서버(DB)✔️ tree tier 환경:
미들티어를 통해서 디비에 접속하는 환경클라이언트 -------> 미들티어 -------> 서버(DB)✅ 미들티어는 클라이언트가 접속할 때 접속이 원활하게 진행돠게 접속 로드를 분할하는 역할을 한다. 예) 턱시도, 티베로

💡 오라클 데이터베이스
오라클 RDBMS(관계형 데이터베이스 관리 시스템)를 사용하면, 정보를 개방적이고 포괄적이며 통합적으로 관리할 수 있습니다.
오라클 데이터베이스 서버 구조
SQL
클라이언트 ----------------------------------> 서버
user process server process
↓
select * 1. 오라클 메모리에서 DATA검색
from emp 2. 없다면 database에서 DATA 검색
where ename='SCOTT'; 3. 오라클 메모리에 결과 데이터를 올린다.
↓
<----------------------------------- 결과 데이터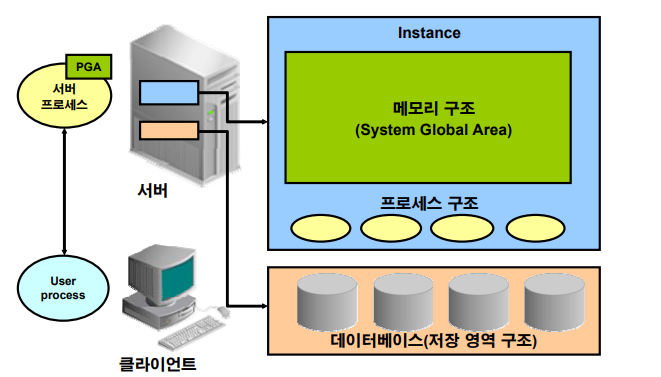
✅ 오라클 데이터 베이스의 구조는 데이터베이스와 메모리로 구성되어 있다. 오라클 메모리를 따로 두는 이유는 메모리에 데이터를 올려놓고 데이터 검색을 빠르게 하기 위해서 입니다.
예) 사전 --------------------------------- 단어장
(database) (오라클 메모리)
단어장에 사전에있는 단어를 적어놓으면 다음번에 모르는게 나왔을 때
단어장을 빠르게 펴서 단어를 찾을 수 있다. Instance: 데이터베이스 구성
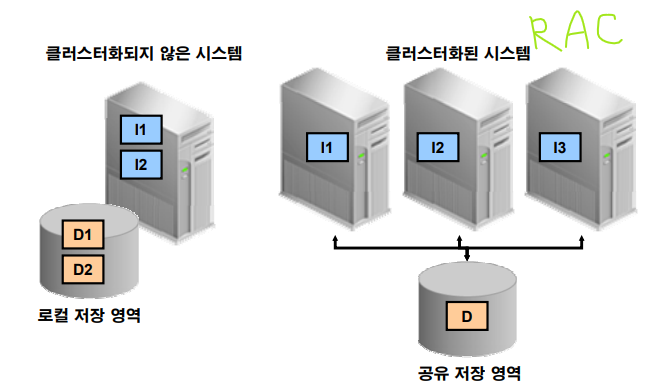
❓클러스터란 집단화, 묶음 이라는 뜻!
❓RAC : real application cluster (data가드)
❓스토리지: 외정형 하드라고 생각하기
❓instance (즉시)
✔️ 만약 클러스터화 되지 않은 시스템을 쓰면 컴퓨터 죽으면 아무것도 안된다. 그래서 오른쪽처럼 data가드!
✅ 클러스터화 되지 않은 시스템 : single node(컴퓨터) instance(메모리) 로 구성된 서버
✅ 클러스터화 된 시스템 : multi node(컴퓨터) instance(메모리) 로 구성된 서버
예) 오라클 RAC(real application cluster)
: 하나의 인스턴스 노드가 다운되어도 서버에 접속한 클라이언트는 그것을 모른다.
데이터베이스 Instance에 연결
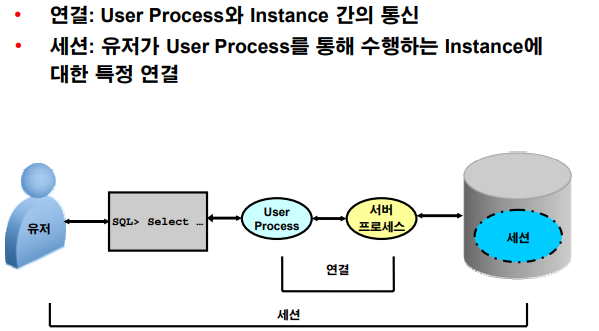
✔️ 연결(connect): 유저 프로세서와 instance(오라클 메모리)간 통신
✔️ 세션(session): 유저 프로세서가 서버의 서버프로세서를 할당받아서 연결한 것
✅ 유저프로세서가 건네준 SQL을 서버 프로세서가 받아서 처리를 해주는 구조
실습1. 서버의 오라클 프로세서들을 확인하기 (푸티에서 스캇으로 접속하고 모바텀에서 실행했다)
[orcl:~]$ ps -ef | grep oracle실습2. 위 결과에서 oracle이라는 단어를 포함하는 프로세서가 총 몇개?
[orcl:~]$ ps -ef | grep oracle | wc -l
✅ 100개의 프로세서들이 떠있다.
실습3. sqlplus scott/tiger로 접속한 세션의 프로세서 확인
[orcl:~]$ ps -ef | grep oracle | grep sqlplus | grep -v grep
[orcl:~]$ ps -ef | grep 16923
✅ 16923는 16961의 부모 프로세서의 pid이다.
실습 4. 현재 접속한 세션의 프로세서 번호를 확인하는 쿼리문
select osuser, sid, serial#, process
from v$session
where sid = (select sys_context('USERENV','SID')
from dual);
✅ sid, seraial#는 오라클에 접속하는 세션에 붙여주는 유일한 식별번호. 그리고 프로세서번호는 현재 세션의 데이터베이스 프로세서 번호. 이 프로세서 번호는 유저 프로세서의 번호이다.
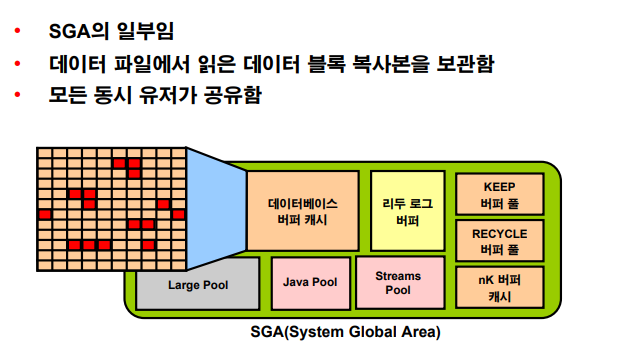
오라클 데이터베이스 메모리 구조
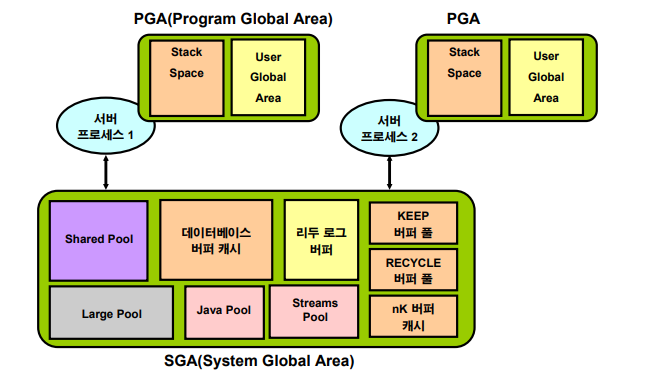
클라이언트(유저프로세서)가 아래처럼 sql을 날렸을 때 SGA(공유 메모리 영역)에서 emp테이블 먼저 찾는다. PGA는 개별메모리 영역이다. 누군가 emp테이블을 select 했었다면 데이터베이스 버퍼 캐시에 올라와있을것이다. 처음 select한 사람은 아주 잠깐 느렸을것이다 메모리에 올려야하니까!
회사 디비는 잘 안끄기 때문에 올라와있을것. 정렬작업은 PGA에서 한다. 그래서 가장 마지막에 한다!
select ename, sal
from emp
order by sal desc;✅ 정리 : 유저 프로세서가 서버 프로세서에게 SQL 을 던지면,
SGA(System Global Area): 오라클 프로세서들이 공유해서 사용하는 공유 메모리 영역
PGA(Program or Private Global Area): 서버 프로세서가 개별적으로 사용하는 메모리 영역
위의 영역은 11g부터 memory_target이라는 파라미터로 통합되었고 전부 자동으로 관리되고있다. 예전에는 사람이 수동으로 메모리 영역 관리를 해야했다.자동으로 관리되면서 오라클 메모리 영역의 각각의 사이즈를 정해진 사이즈 안에서 스스로 잘 분배하여 사용하고 있다.
실습1. 오라클 메모리가 자동으로 관리되고 있는지 확인해보기 (11g)
SQL> show parameter memory_target
✅ 460M로 설정해 놓으면 460M 안에서 오라클이 알아서 각각의 메모리에 필요한 사이즈를 자동할당 해준다.

SQL> show parameter memory_max_target
✅ memory_max_target 값을 설정해놓으면 이 값을 초과하여 메모리 사용을 하지 않는다.

💡 오라클 18c(윈도우 오라클) 에서는 memory_target가 0으로 세팅되어져 있으면 오라클 메모리 관리가 활성화 되어있다는 것이고, 메모리 할당을 자동으로 조절하고 관리하고 있다는 것 입니다. 오라클은 자동으로 메모리를 관리
하는것을 권장하고 있다.
낮시간에는 pga보다 sga를 크게 잡고 쓰고있다가 정렬작업이 과도하게 작업되는 배치작업이 도는 밤시간에는 pga가 더 큰 메모리를 할당받아 사용하게 되는데, 이 모든것이 자동으로 관리되고 있다.
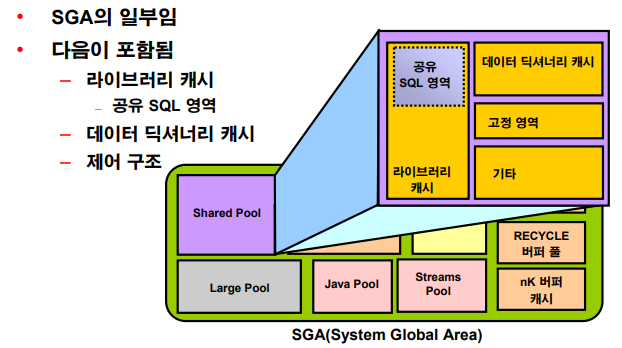
Shared Pool
💡Shared Pool의 역할: parsing을 최소화 하기 위한 메모리 영역
parsing은, 사람이 알아볼 수 있는 SQL과 같은 코드를 기계어로 변환하는 것이다.
파싱은 메모리 사용이 많아서 메모리 사용을 최소화 하려고 특정 SQL을 파싱했을 때 그 파싱된 데이터를 shared pool에 올리고 재사용한다. 재사용을 하면 다시 파싱하지 않는다.
파싱은 cpu를 많이 사용하는 비싼 작업이다!
✔️ select 문의 처리과정
-- 유저 프로세서 --------------------------------> 서버 프로세서
select empno, ename, sal 파싱 수행
from emp
where ename='SCOTT';1. parsing
- 문법검사: SQL이 문법적으로 문제가 없는지 확인
- 의미검사:
- SQL에 사용된 emp테이블이 db에 있는지 확인
- emp 테이블에 empno, ename, sal 컬럼이 있는지 확인
- scott 유저가 emp테이블을 select할 수 있는 권한이 있는지 확인
✔️ 파싱을 통해 얻어지는 결과물 3가지?1. SQL문 2. 실행계획 3. parse tree(실행 가능한 코드) ⭐ 위 결과물을 shared pool 라이브러리 캐시에 올려놓습니다. ⭐ 왜? 다음번에 똑같은 SQL이 실행되면 파싱과정을 생략하고 바로 execute실행을 위해 ⭐ 위 구조를 알고 있는 개발자나 dba가 SQL작성시 성능을 위해 신경써야할 부분은, 똑같은 SQL을 날려야 한다는 것이다. 오라클에서 공유풀을 잘 사용하게 권장하는 SQL은 바인드 변수를 사용한 SQL이다 SQL> variable p_empno number; SQL> exec :p_empno :=7788; SQL> select empno, ename, sal from emp where empno = :p_empno;2. execute: 파싱이 끝나면 옵티마이저가 실행계획을 생성해주는데 그 실행계획을 가지고 실행하는 단계
3. fetch: server process -----------> user process에게 결과물 전달하는 과정
💡 공유풀이 필요한 이유
한번 parsingSql 과 그 결과물(실행계획, 기계어)를 저장하고 다음번에 똑같은 SQL이 실행되면 파싱 과정 생략하고 바로 실행한다.
실습1. 바인드 변수를 사용하지 않고 다음과 같은 리터럴 SQL을 반복 수행하고 CPU 사용율이 올라가는지 확인하기 (다른쪽에서 top명령어로 보기)
SQL> ALTER system FLUSH shared_pool;
-- shared_pool내용을 비우는 역할을 한다.
-- 이렇게 하는 이유는 이후 실행할 쿼리에 대한 parse결과를 메모리상에서 없애기 위해서이다.
SQL> SET timing ON
SQL> SET serveroutput ON
SQL> DECLARE
TYPE rc IS REF cursor;
l_rc rc;
l_dummy all_objects.object_name%TYPE;
l_start NUMBER DEFAULT dbms_utility.get_time;
BEGIN
FOR i IN 1 .. 1000
loop
OPEN l_rc FOR
'select object_name from all_objects where object_id = ' || i;
fetch l_rc INTO l_dummy;
close l_rc;
END loop;
dbms_output.put_line ( round( (dbms_utility.get_time - l_start)/100, 2) || 'seconds');
END;
/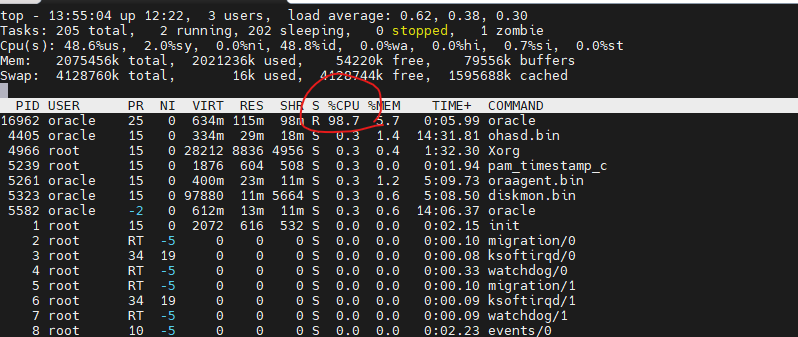
✅ 위의 리터럴 SQL을 1000번 수행하는 plsql을 돌렸더니 cpu 사용율이 99.9%로 올라가면서 수행시간도 21초가 걸렸다. 컴퓨터의 두뇌에 해당하는 cpu 사용율이 크게 올라갔다.
왜 똑같은 SQL로 취급하지 않고 파싱을 하는가? 그럼 똑같은 SQL이란 어떤것인가
1. 대소문자를 구분한다. 아래는 서로 다른 SQL로 인식된다.select empno, ename, sal from emp; SELECT EMPNO, ENAME, SAL FROM EMP;
- 공백과 들여쓰기도 구분한다. 아래는 서로 다른 SQL로 인식된다.
select empno, ename from emp; select empno, ename from emp;
- 리터럴 SQL도 서로 다른 sql로 인식합니다.
select empno, ename, sal from emp where empno =7788; select empno, ename, sal from emp where empno =7902;
실습2. 지금 현재 shared pool에 있는 SQL을 확인해보기
select sql_text, parse_calls, executions
from v$sql
where sql_text like '%select object_name%';❓ 그래서 해결방법은?
: 똑같은 SQL문장을 사용하도록 SQL 사용 지침준사항을 개발자들에게 메일로 공지한다.
- sql은 소문자로 전부 통일하세요
- 공백과 들여쓰기 한번씩만 해서 작성합니다
- (가장중요) 리터럴 SQL대신에 바인드 변수를 사용하세요
실습3. PL/SQL 개발자들이 바인드 변수를 사용하여 PL/SQL 프로그래밍을 한다 라는것은 무엇인지 확인해보기
DECLARE
TYPE rc IS REF cursor;
l_rc rc;
l_dummy all_objects.object_name%TYPE;
l_start NUMBER DEFAULT dbms_utility.get_time;
BEGIN
FOR i IN 1 .. 1000
loop
OPEN l_rc FOR
'select object_name from all_objects where object_id = :x' USING i;
fetch l_rc INTO l_dummy;
close l_rc;
END loop;
dbms_output.put_line ( round ( (dbms_utility.get_time - l_start) / 100, 2) || 'seconds..');
END;
/using절을 사용해서 i가 바인드변수에 들어가 계속 돌아가도록 했다.
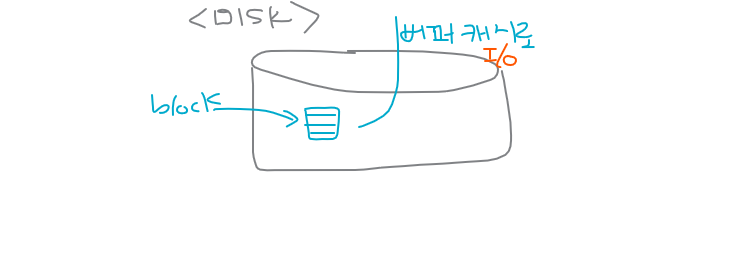
데이터 베이스 버퍼 캐시
select ename, sal
from emp
where enam='SCOTT'; -> block안에 있다.
1. 검색하려는 데이터를 처음에는 db buffer cache에서 찾습니다.
2. buffer cache에 없으면 data file에서 찾습니다.
3. 찾은 데이터의 행과 주변행들을 같이 모아서 block으로 메모리에 올린다. (disk i/o)
4. 메모리의 buffer cache에 복사본을 올려놓고 user process에게 fetch.⭐ 왜 SCOTT의 행 하나만 올리면 될것을 SCOTT의 행 주변행들까지 다 같이 포함해서 BLOCK단위로 올리는가???
-> 스캇의 주변 행들은 또다시 유저에 의해 select될 확률이 높은 행들이기 때문이다.
✔️ select문의 단계 3가지
1. parsing (shared pool)
2. execute (db buffer cache)
3. fetch
💡 바둑판처럼 생긴 네모칸 하나가 버퍼라고 한다. 8kb정도 됨.
실습1. 오라클 블럭의 크기를 확인하기
show parameter db_block_size
✅ 메모리의 버퍼 크기 하나도 8kb인 것이다.
- db buffer cache도 한정된 메모리 영역이기 때문에 효율적으로 사용해야하는데, 이 메모리 영역을 효율적으로 사용하기 위한 알고리즘이 있다.
답:LRU(Least Recent Used) 알고리즘
버퍼는 질서로 올라가는데 그게 LRU알고리즘.
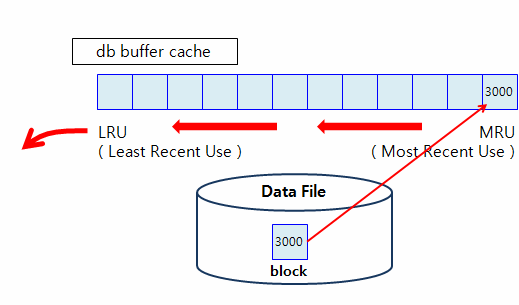
select sal
from emp
where ename='SCOTT';✅ 최근에 읽은 데이터를 MRU 쪽에 올리고 최근 데이터가 메모리에 오래 머물도록 하는 알고리즘!
모든 액세스 방법이 전부 데이터를 MRU쪽으로 올리는 것은 아닙니다.
데이터 액세스 방법에 따라서 MRU쪽으로 올릴수도 있고, LRU근방으로 올려서 바로 메모리에서 빠져나가게 될 수도 있다!
1. index range scan : 인덱스를 통해서 데이터를 엑세스 하는 방법 (single block i/o)
2. full table scan : 테이블 전체를 다 스캔하는 스캔방법 (multi block i/o)
인덱스 스캔을 할 때는 MRU 쪽으로 데이터를 올리고 풀테이블 스캔을 할 때는 LRU근방으로 올려서 바로 메모리에서 빠져나가게 합니다.
❓ LRU 알고리즘을 이해한 dba가 해야할 일은!?
자주 액세스 하는 중요한 테이블은 index scan을 하던, full table scan을 하던 MRU 쪽으로 올리게끔 테이블 설계를 해야한다. (물리적 설계)
무조건 MRU 올리려면 테이블을 CACHE 테이블로 생성해야 한다.
실습1.scott이 가지고 있는 테이블들의 cache속성을 확인하시오SQL> select table_name, cache from user_tables;
N 이라고 나오면 NOCACHE! 노캐시는 디폴트값인데 인덱스 스캔일때는 MRU로 올리고, 풀테이블 스캔일때는 LRU로 올리는 스캔방법입니다.
⭐ 우체국으로 예를들면 우편번호 테이블 같은 경우 사람들이 자주 엑세스 하는 테이블이라서 cache테이블로 만들어줘야 합니다.alter table emp cache; select table_name, cache from user_tables;
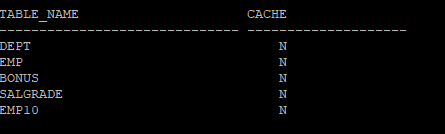
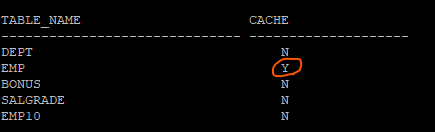
문제 dept table을 cache table로 만들어보기
alter table dept cache;
select table_name, cache from user_tables;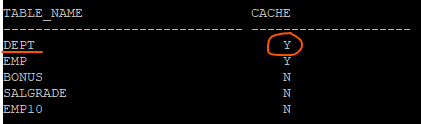
💡 (ocp문제) 어떤 테이블을 cache속성으로 만들어야하나?
답: 작고 자주 엑세스 하는 테이블
❓ 만약 cache테이블로 안만들고 그냥 내가 select 할 때에 cache테이블처럼 작동되게 하고싶다면? (힌트사용)
select /*+ cache */ ename, sal
from emp
where ename='SCOTT';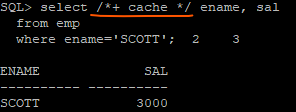
💡 cache힌트를 쓰면 어떤 스캔을 하던 MRU로 올라갑니다.
리두 로그 버퍼
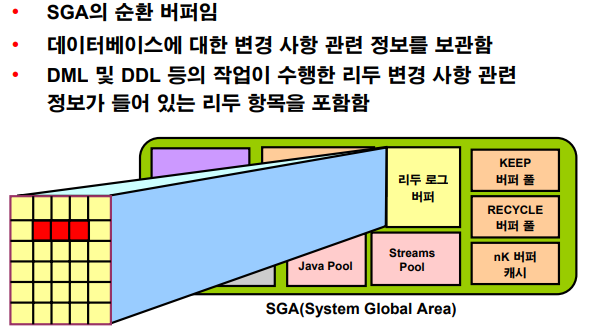
💡 리두 로그 버퍼는 데이터베이스에 대한 변경 사항 관련 정보가 포함된 SGA의 순환 버퍼입니다.
이 정보는 리두 항목에 저장됩니다. 리두 항목은 DML, DDL 또는 내부 작업에 의해 데이터베이스에
수행된 변경 사항을 재생성(또는 리두)하는 데 필요한 정보를 포함합니다. 필요한 경우 리두 항목은
데이터베이스 Recovery에 사용됩니다.redo ---> 다시 작업하다. 다시 작업하기 위한 데이터가 들어있는 버퍼(메모리)입니다.예) update emp set sal=0 where ename='SCOTT'; # 3000 -> 0 으로 바꿨다고 내역이 저장되어있다. 혹시라도 나중에 DB에 데이터파일이 깨지거나 데이터가 엑세스 안되는 장애상황이 발생한다면 복구하려고 평상시에 일일이 기록한다.❓ dba가 1순위로 챙겨야 하는 일????????? -> 백업이 잘 수행되었는지 확인하는 일!!
⭐ update문의 처리과정
1. parsing : 문법검사, 의미검사를 합니다. select 문장과 같습니다.
2. execute (순서대로)
- 데이터를 db 버퍼 캐시에 올립니다
- 업데이트 하려는 해당 행에 lock을 겁니다
- redo log buffer 에 변경사항을 기롭합니다
- cr buffer에 3000을 기록합니다
- 버퍼 캐시 영역 값을 변경(3000->0)
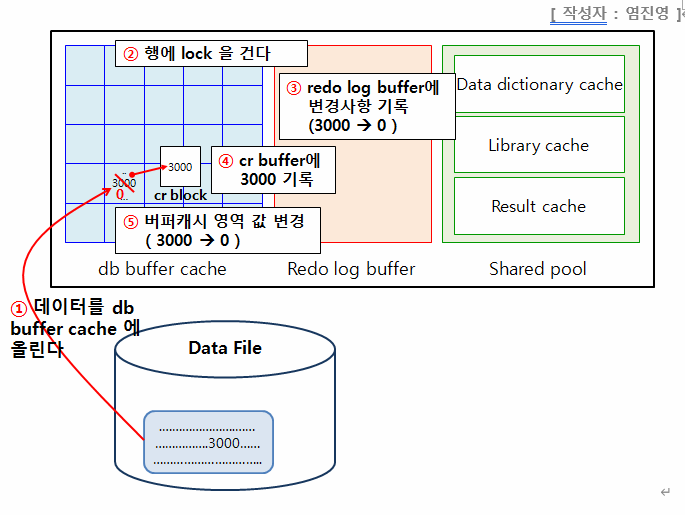
💡 오라클은 변경사항에 대해 전부 스스로 기록하고 있다.
실습1. 리두로그 버퍼의 크기를 확인하기 (11g, 18c 모두 5.5m가 기본값으로 세팅)
SQL> show parameter log_buffer
select 5767168/1024/1024
from emp;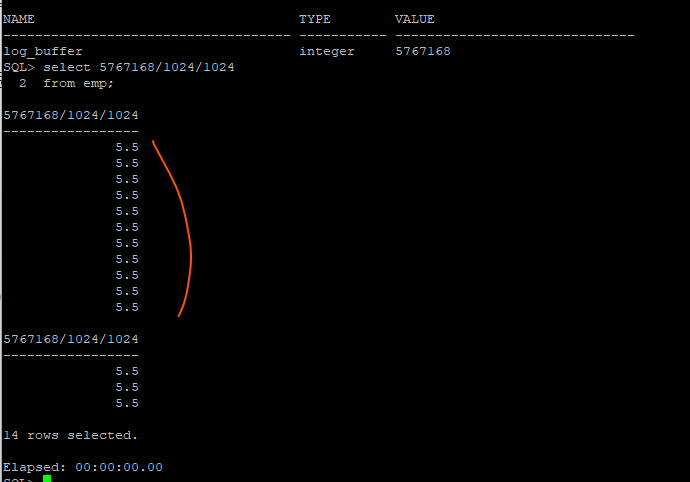
Large Pool
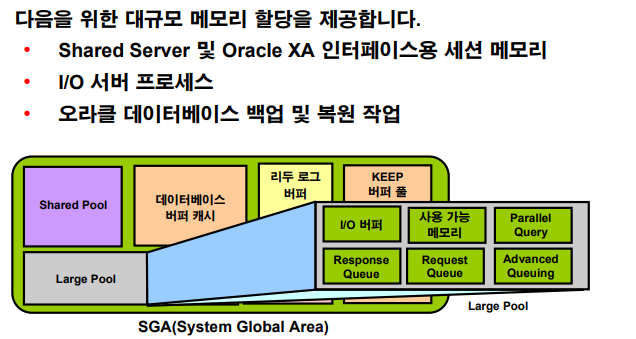
💡 1. 병렬처리 SQL을 수행할 때 작업하는 메모리 영역입니다.
select /*+ full(emp) parallel(emp,4) */ ename, sal
from emp
where sal > 1200;✅ 힌트의 내용은, emp 테이블을 4개의 프로세서가 나눠서 스캔해준다. 하나가 모든것을 풀스캔 하는 것 보다 빠르다 !
💡 2. 백업과 복구를 RMAN 이라는 오라클 툴을 이용해서 명령어로 편하게 할 수 있습니다. 이 RMAN이 수행될 때 사용되는 메모리 영역이 large pool.
(백업과 복구를 빠르게 수행하고 싶다면 성능을 위해서 large pool을 늘리고 작업하면 됩니다.)
실습1. large pool의 사이즈를 확인
SQL> show parameter large_pool

✅ 0 이라는 것은, 자동관리가 되고 있다는 뜻이다. 필요하면 늘리고, 없으면 줄인다.
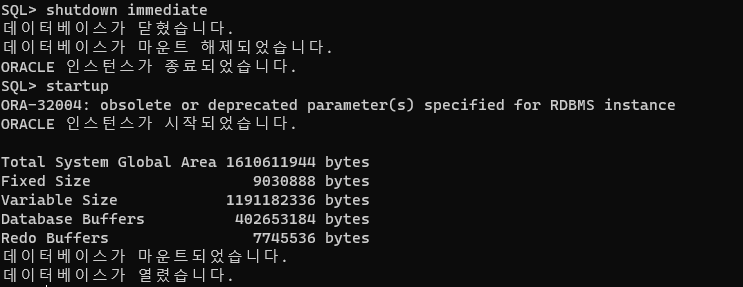
connect /as sysdba
shutdown immediate
startup