복습
오라클 아키텍쳐 구조
✔️ 파라미터파일 없으면 디비 안올라온다
얼럿록, 트레이쓰파일 분석 못햄 1,2,3은 삭제되면 디비 멈춤
✔️ datafile, control file, redo log file은 삭제되면 db가 shutdown되지만 parameter file, archive log file, alert logfile, trace file은 삭제되어도 db shutdown은 안되고 운영된다. 그렇지만 나중에 문제가 되니까 조치를 취해야 한다.
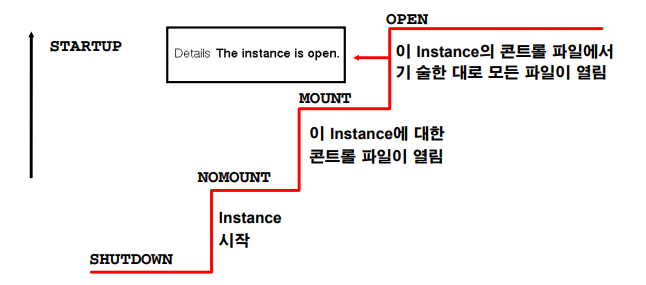
db startup 단계 4가지
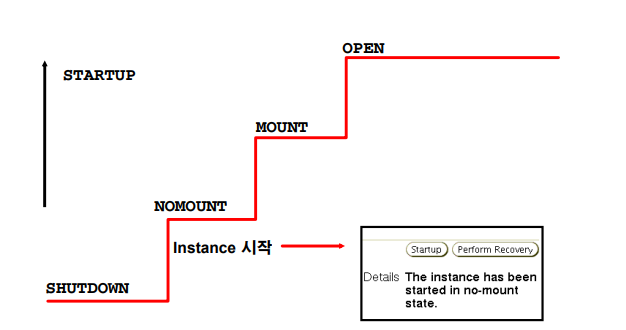
✔️ shutdown에서 nomount로 갈 때는 parameter file이 필요하다. -> 인스턴스 열림
노마운트에서 인스턴스가 열리면서 백그라운드 실행
마운트 단계에서 컨트롤 파일로 디비를 찾아서 디비를 연다.
datafile, redo log file이 있어야 오픈단계로 갈 수 있다.✔️ shutdown단계에서 $ORACLE_HOME/dbs 밑에 파라미터 파일이 있다. 오라클이 여기서 파일들이 찾는다.
.bash_profile이 오라클 시작할때 자동으로 도는데 여기안에 내용에 파일들이 어디있는지 (오라클홈 밑 dbs)나와있다.✔️ 파라미터 파일은 control_files안에 어디에있는지 나와있다.
✔️ control file 안에 data file, redo log file이 어디에있는지 나와있다.
실습1. db를 shutdown 시키기
실습2. db를 mount로 올리기
SQL > startup mount;
실습3. 마운트에서 open으로
SQL> alter database open;
실습4. 다시 db를 shutdown 하기
실습5. $ORACLE_HOME/dbs 밑으로 이동하기
SQL> exit;
[orcl:~]$ cd $ORACLE_HOME/dbs실습6. backup2 라는 디렉토리를 생성하기
mkdir backup2실습7. 오라클 파라미터 파일인 spfileorcl.ora와 initorcl.ora를 backup2 디렉토리로 copy하기
[orcl:dbs]$ cp spfileorcl.ora ./backup2/spfileorcl.ora
[orcl:dbs]$ cp initorcl.ora ./backup2/initorcl.ora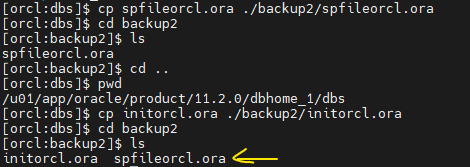
실습8. $ORACLE_HOME/dbs 밑에 있는 spfileorcl.ora와 initorcl.ora를 지우세요. (둘다)
[orcl:dbs]$ rm initorcl.ora
[orcl:dbs]$ rm spfileorcl.ora
[orcl:dbs]$ ls
backup hc_DBUA0.dat init.ora lkORCL peshm_DBUA0_0
backup2 hc_orcl.dat initorcl.ora.bak.edydr1p0 orapworcl peshm_orcl_0실습9. 오라클(sys)로 접속해서 db startup 해보기
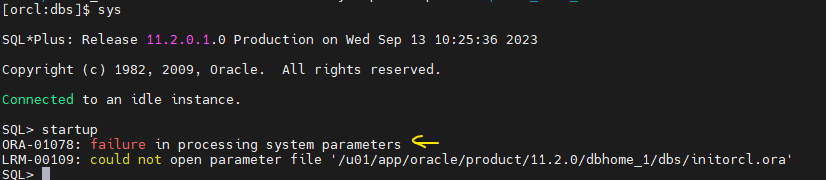
❗ 파라미터 파일이 $ORACLE_HOME/dbs 밑에 없어서 안올라간다.
실습10. db가 올라갈 수 있도록 위 문제를 해결해보기
[orcl:backup2]$ cp * ../
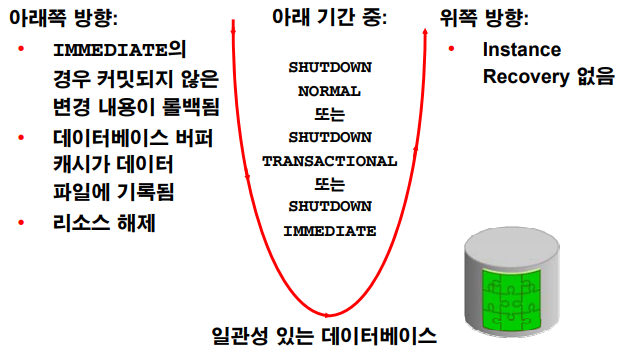
db 종료 모드 4가지
❓ 왜 dba가 db를 내리는지?
1. 오라클 파라미터 값을 변경한 것을 인스턴스에 적용하고자 할 때
2. 오라클 upgrade와 patch를 수행
3. 오라클 데이터를 백업할 때
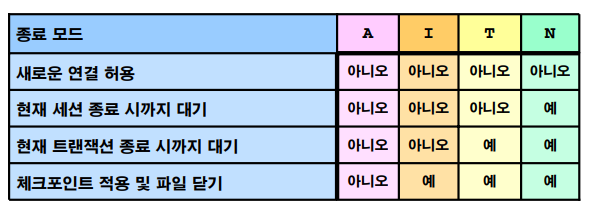
1. shutdown normal : 누가 scott으로 접속해있다? 누군가 update치고있다? 하면 안내려감. 사람들이 다 접속이 안되어있을 때, 체크포인트 일으키고 내려간다.
2. shutdown transactional : 현재 접속되어있는 세션 다 끊어버리지만 누가 update중이라면 기다려준다. commit시에 디비 내려간다.
3. shutdown immediate : 현재 접속되어있는 세션 다 끊고 누가 update중? 다무시(rollback됨)
4. shutdown abort : 얘는 진짜 급하게 할때.. 다 허용안하고 체크포인트도 안일으킨다. 어느정도 데이터 유실이 생길 확률이 있다. 체크포인트는 평상시에 수시로 일어나기 때문에 그렇게 크리티컬하게 문제가 생기지는 않을것이다.
➡️ shutdown immediate로 db 내리자. 그런데 몇시간이 지나도 내려갈 기미가 안보인다면 shutdown abort를 하기
shutdown transactional 실습
실습1. putty창 3개열기
1창: shutdown 하는 창
2창: alert log file 실시간 모니터링하는 창
3창: scott유저에서 update하는 창
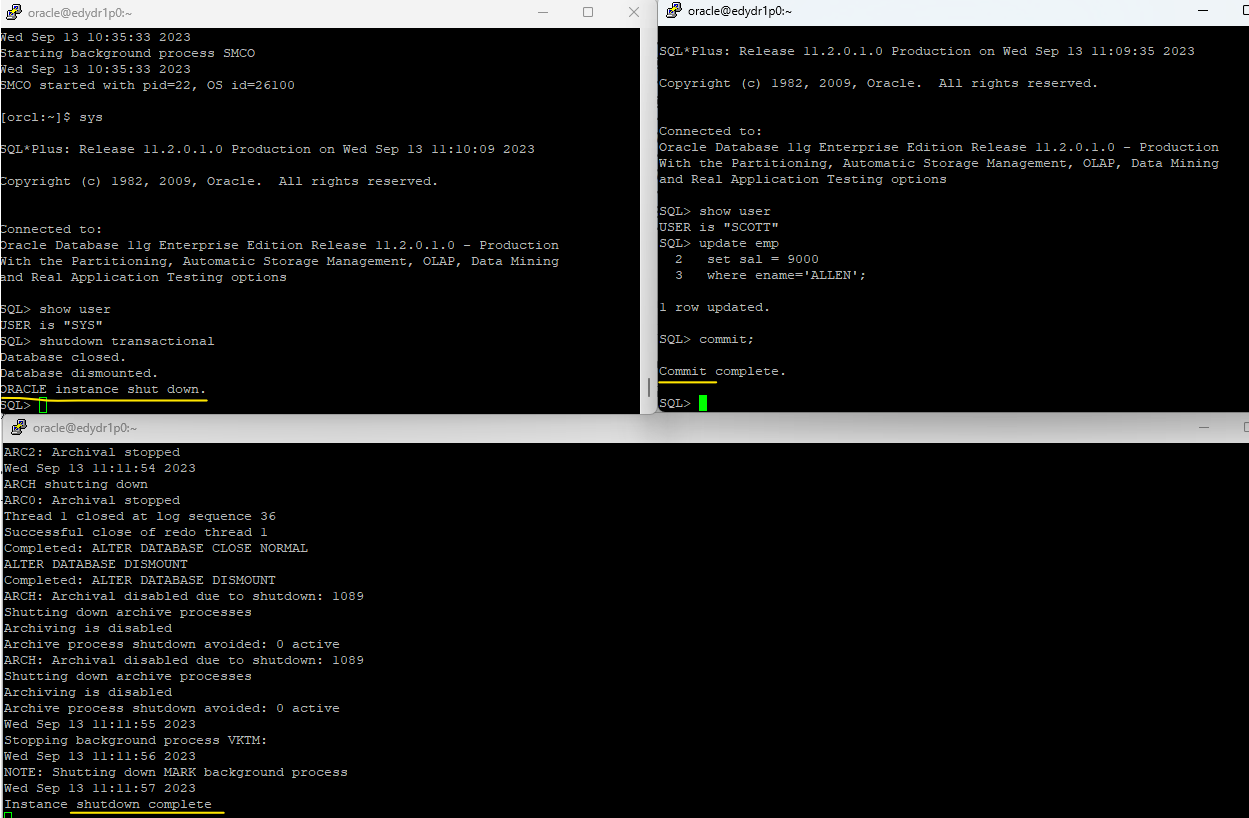
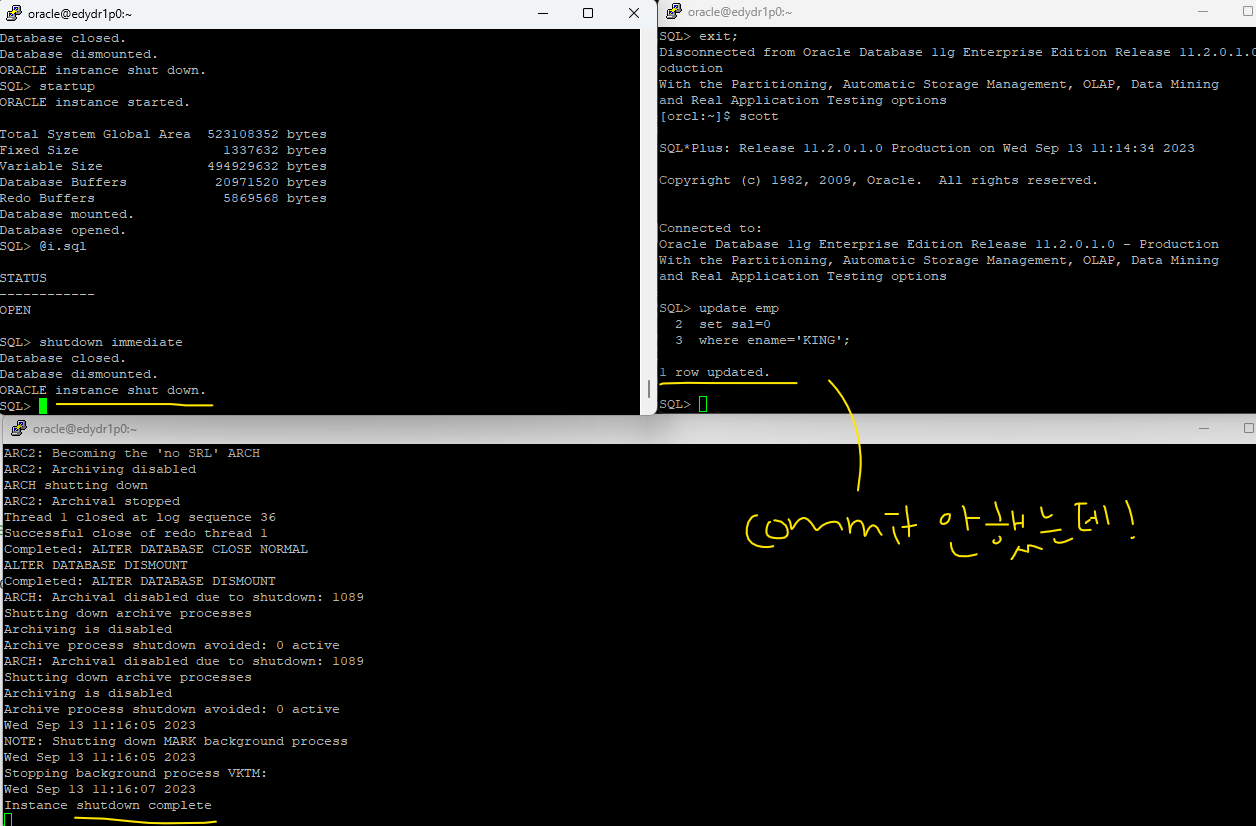
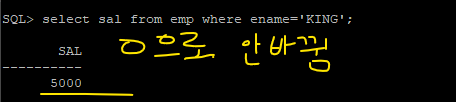
✅ update를 해놓은 상태라 디비가 안내려갔다. commit;을 하니까 내려갔음 !
shutdown immediate 실습
실습1. putty창 3개열기
1창: shutdown 하는 창
2창: alert log file 실시간 모니터링하는 창
3창: scott유저에서 update하는 창
✅ commit 안해도 db가 내려갔다. 다시 startup 후에 update하던 내용 확인해보니 수정이 안되어있음.
shutdown abort 실습
실습1. putty창 3개열기
1창: shutdown 하는 창
2창: alert log file 실시간 모니터링하는 창
3창: scott유저에서 update하는 창
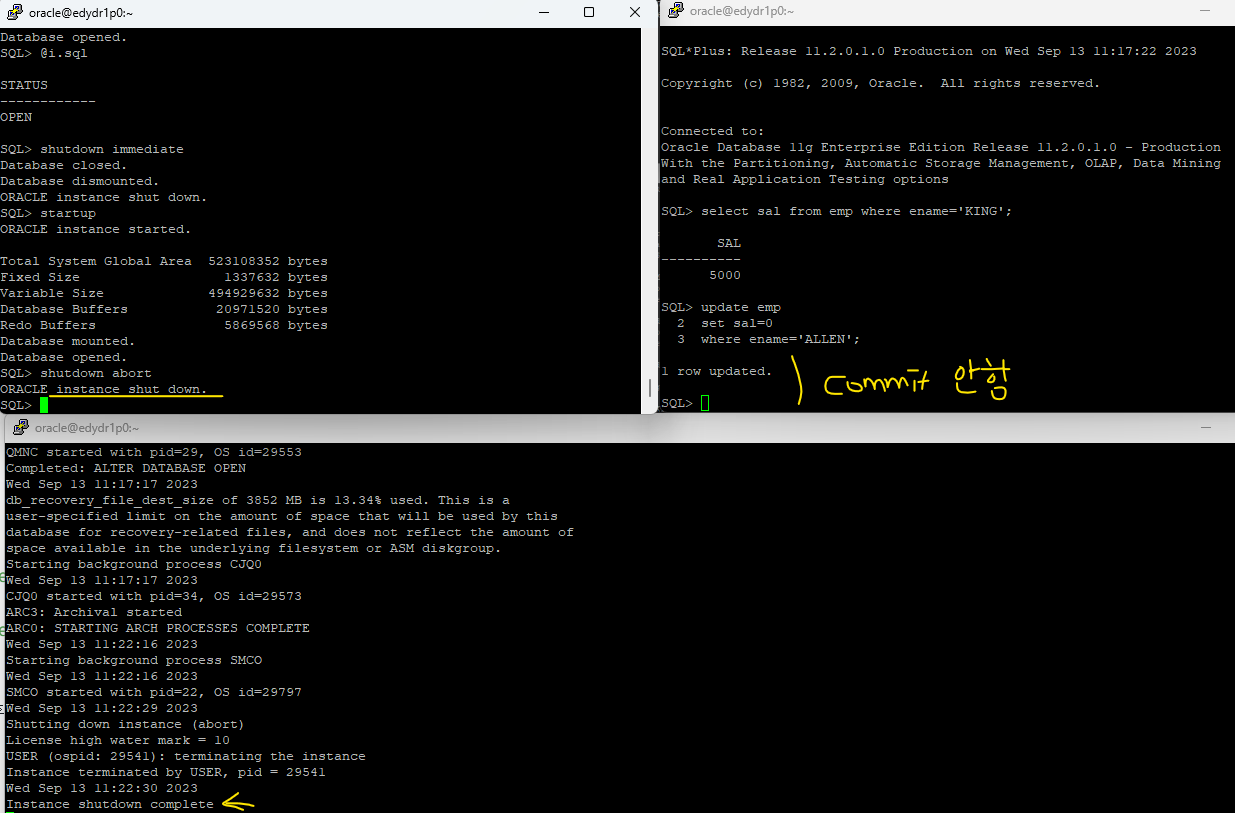
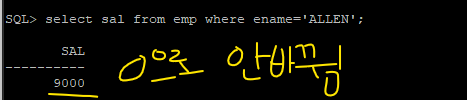
✅ 체크포인트가 주기적으로 자동으로 발생하기 때문에 아래의 UPDATE문에 대한REDO정보가 REDO LPGFILE에 내려써졌습니다. -> 디비 내리기 전에 ALLEN의 월급을 0으로 update했고 commit을 안했다는 redo 정보가 redo logfile에 lgwr에 의해 내려써졌고, 그리고 나서 shutdown abort를 수행한 것입니다.
그래서 open 단계에서 SMON이 redo logfile의 내용을 보고 commit안한 데이터는 다 rollback해버립니다. 이것을 instance recovery라고 합니다.
종료옵션
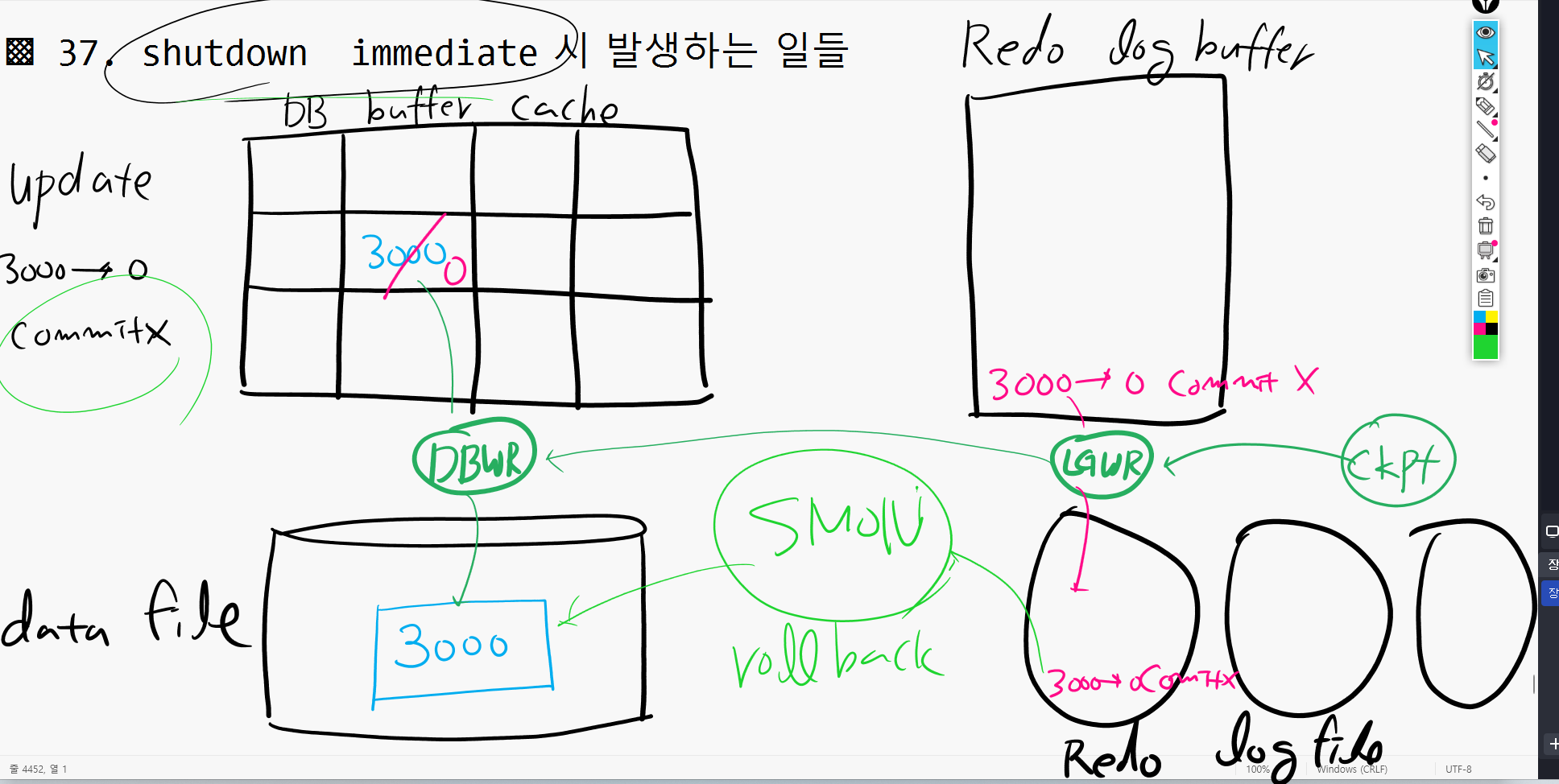
shutdown immediate 시에 발생하는 일들
DB buffer cache Redo log buffer
DBWR LGWR
data file redo log file
- 스캇의 월급을 update 3000 -> 0 , commit X 일때
데이터파일에 3000이 블락으로 되어있는데 서브프로세서에서 DB buffer cache 에 올리고 0로로 바꾼다. 그런데 커밋을 하지 않은상태. - 이순간 Redo log buffer 에는 3000을 0으로 바꾸고 commit하지 않은상태라고 저장해놓는다.
체크포인트(CKPT)가 redo log file에 내려쓰라고 해서 LGWR가 밑에 내려쓴다. 그리고 DBWR에 시킨다. 근데 지금 data file 는 3000이고 DB buffer cache 는 0이라서 (이것을 더티버퍼) 맞춰주려고 내려쓴다. - 이상태에서 shutdown immediate가 일어나면 지금 체크포인트에 의해 datafile에 3000이 아닌 0으로 되어있는데 디비가 다시 startup 되면서 이거 commit안한 거니까 SMON이 이것을 rollback해서 3000으로 올린다.
-
scott 의 월급을 3000-->0 로 변경했는데 아직 commit 을 안했습니다.
-
buffer cache 의 dirty buffer 와 redo log buffer 의 redo entry 는
data file 과 redo log file 에 내려써진 상태 입니다.
왜냐하면 체크포인트가 주기적으로 발생하기 때문입니다. -
이 상태에서 db 가 shutdown immediate 를 수행했습니다.
-
- commit 을 안했으므로 scott 월급을 다시 0 로 rollback 해버립니다.
💡 dba를 위한 tip
만약 shutdown immediate 하기 전에 대량의 DML작업이 있었다면 셧다운 할 때 시간이 오래 걸립니다. 왜냐하면 rollback을 해야 할 데이터가 많아서 입니다. 가급적 대량의 DML작업한 이후에 바로 DB를 내리지 않는게 좋습니다. 굳이 꼭 내려야한다면 수동으로 checkpoiint를 일으키고 shutdown immediate를 하세요! shutdown immediate할 때 체크포인트가 일어나는데 이 때 시간을 좀 줄일 수 있다.
★ 수동으로 체크 포인트 일으키는 명령어
alter system checkpoint;롤백 작업이 shutdown시 다 발생하므로 startup 할 때 복구할 것 없이 startup 되므로 수월하게 db가 잘 올라옵니다. 즉 instance recovery가 필요없음.
실습1. shutdown immediate를 하기 전에 수동으로 체크포인트를 일으키고 내리기. 그리고 startup 하기!
SQL> alter system checkpoint;
System altered.
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 523108352 bytes
Fixed Size 1337632 bytes
Variable Size 494929632 bytes
Database Buffers 20971520 bytes
Redo Buffers 5869568 bytes
Database mounted.
Database opened.
shutdown abort 시에 발생하는 일들(내려갈때, 올라갈때)

DB buffer cache Redo log buffer
DBWR LGWR
data file redo log file
- 스캇의 월급을 update 3000 -> 0 , commit O 일때 DB buffer cache 에 0으로 수정하고 Redo log buffer에 commit한것도 올렸다. (LGWR는 커밋할때, 3초, Redo log buffer가 1/3 찼을 때, check point가 작동할때 작동한다) LGWR얘가 redo log file에 3000 -> 0 커밋했다고 넣는다. DBWR는 commit할 때 작동하지 않아서 아직 data file은 0으로 바뀌지 않고 3000으로 남아있다. DBWR는 체크포인트가 일어날때까지 기다리고 있는 것이다. 이 상태에서 디비가 내려간다면 (정전이나 shutdown abort..) 그렇지만 다시 startup 했을 때 0으로 잘 읽는다 . SMON이라는 애가 redo log file에 있는 내용을 보고서 commit을 해주고 적용시켜준다.
->instance recovory
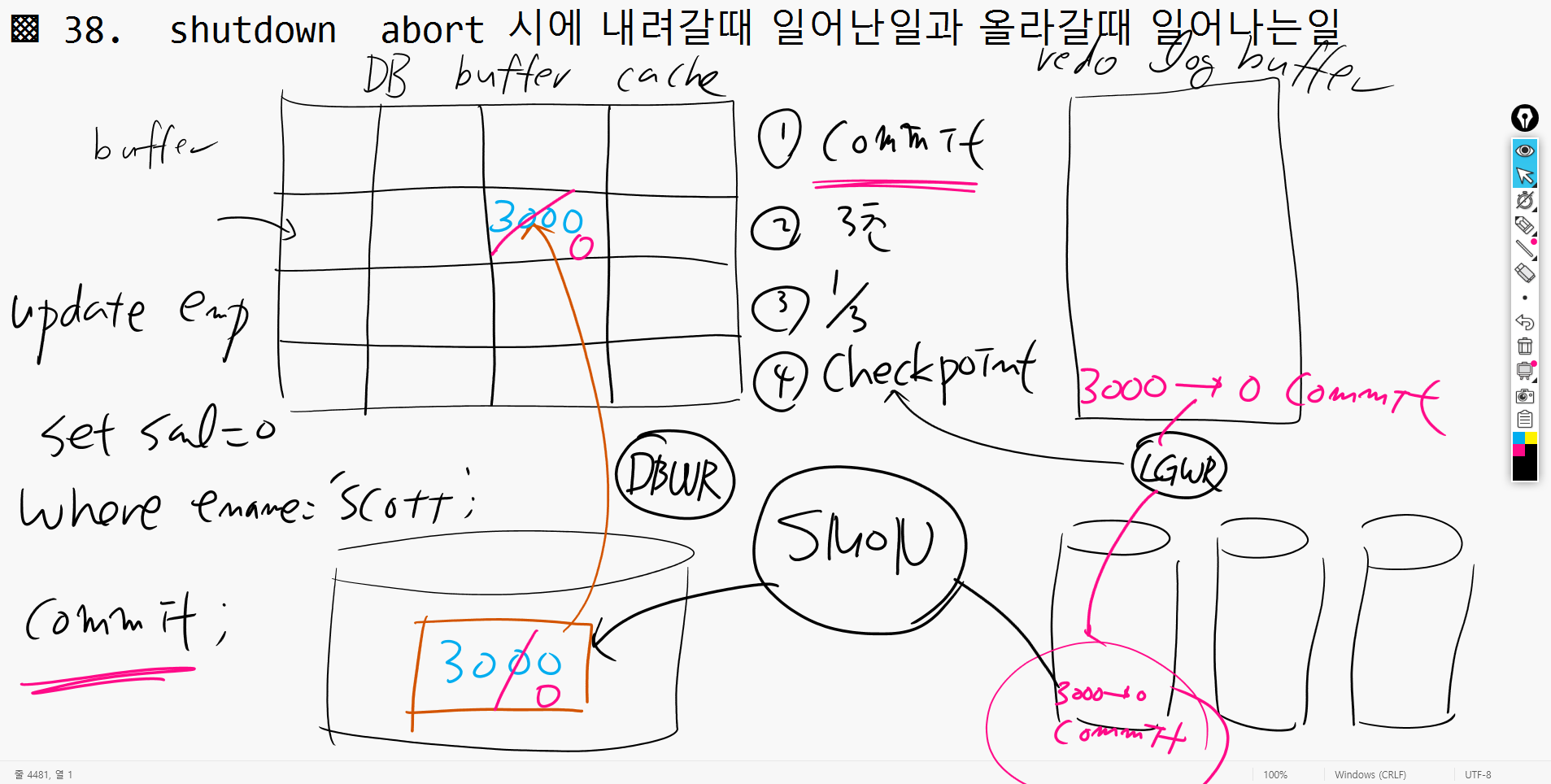
SMON은 commit 안한애들은 rollback시켜버리고, 한 애들은 commit해준다.
✅ 대량의 DML작업이 일어나는중에 갑자기 정전이 되거나 shutdown abort를 하면 메모리에서 commit한 데이터와 commit되지 아낳은 데이터가 다 사라지게 됩니다. data file에 반영 안된 상태에서 다 사라져 버립니다. 그러면 startup 할 때 open 단계에서 SMON이라는 백그라운드 프로세서가 redo logfile의 내용을 보고 하나하나 복구를 해줍니다.
commit한 데이터는 commit한 상태로 만들어주고, commit하지 않은 데이터는 다 rollback 시켜 버립니다. 그래서 startup이 다 완료되면, 복구된 상태의 데이터를 볼 수 있습니다. 이 복구작업을
instance recovery라고 합니다.💡 dba를 위한 tip
대량의 DML작업이 일어난 중에 갑자기 서버가 꺼지게 되면, startup 할 때 시간이 오래 걸리게 되는데 그 때 SMON이 얼마나 바쁜지 모니터링을 해야합니다.
실습1. ps명령어로 SMON의 프로세서 아이디를 알아냅니다.
$ ps -ef | grep smon
[orcl:~]$ ps -ef | grep smon
oracle 5198 1 0 04:34 ? 00:00:05 asm_smon_+ASM
oracle 31859 1 0 12:09 ? 00:00:00 ora_smon_orcl -> 이거 확인 !!
# 31859
$ top -p 31859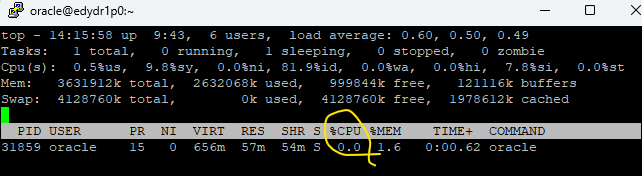
💡
instance recovery는 db가 완전히 starup 된 이후에도 계속해서 작업합니다.
그런데 이 때 cpu와 memory를 상당히 많이 사용해서 db가 여전히 느릴 수 있습니다. 따로 할 수 있는것은 없고 그냥 기다려야 한다.딱 한가지 해결방법이 있는데, shutdown immediate로 내렸다가 startup하면 풀린다.
startup force = shutdown abort + startup
alert log file 확인
✔️ db에 어떠한 이슈가 있을 때 반드시 먼저 열어봐야하는 오라클 파일
✔️ db를 올렸다 내렸다 하는 작업시 반드시 실시간 모니터링 해야하는 파일.
✔️ db백업과 복구시 반드시 실시간 모니터링을 해야하는 파일!
현업에서는 주로 이 파일을 직접 리눅스에서 열어서 본지만 아래처럼 em에서 볼 수도 있다.
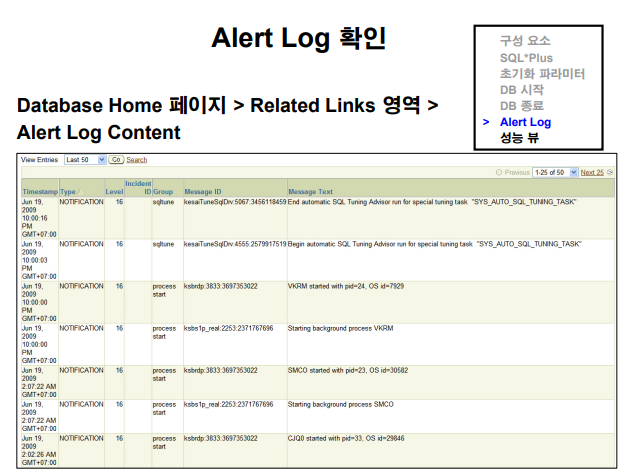
실습1. em을 시작시킨다.
$ emctl start dbconsole
- database hopage> 아래쪽으로 쭉내리기 > 관련링크 > 경보 로그 내용 > 마지막 50개 실행 하면 웹페이지로 볼 수 있다.
Trace file 사용
💡 서버 프로세서나 백그라운드 프로세서가 자신과 관련한 어떤 이슈가 발생하면, 그 내용을 자기 프로세서 번호로 파일을 만들어서 거기에 적습니다. 그 파일이 trace file입니다. 회사에서 문제가 생기면 이 파일을 오라클사에 보내거나 협력업체 오라클 엔지니어에게 보내면 분석해서 알려줍니다. 그런데 회사에서 일하는 dba가 이 파일에 어떤 이슈들이 있는지 쉽게 분석을 하고싶다면, ADR을 이용하면 됩니다.
실습
[orcl:~]$ trace
[orcl:trace]$ adrci
ADR base = "/u01/app/oracle"
adrci> help
adrci> show problem
adrci> show incident
- 각 서버 프로세스와 백그라운드 프로세스는 연관된 Trace file에 정보를 기록할 수 있습니다.
- 오류 정보는 해당하는 Trace file에 기록됩니다.
- ADR(Automatic Diagnostic Repository)
- 시스템 중앙 추적 및 로깅 Repository입니다.
- 다음과 같은 데이터베이스 진단 데이터를 저장합니다.
- Trace
- Alert log
- 상태 모니터 보고서
Dynamic Performance 뷰
💡 db가 오픈되지 않고 startup nomount 단계나 mount단계에서 데이터 베이스와 인스턴스의 정보를 확인할 때 유용한 뷰. 데이터 딕셔너리를 조회해서 db의 구조 정보를 확인합니다. 그런데 db가 올라오지 않았을 때는 dictionary를 조회할 수 없어서, v$ 로 시작하는 다이나믹 퍼포먼스 뷰를 조회해서 db 구조 정보를 확인합니다.
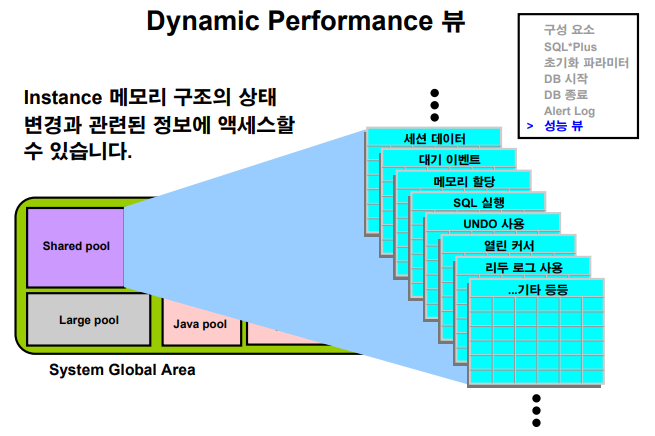
✔️
v$로 시작하는 다이나믹 퍼포먼스 뷰를 활용하는 방법
1. 악성 SQL을 찾을 수 있게 해줍니다. (v$sql.v$sqltext)
2. 지금 현재 waiting하고 있는 세션을 확인할 수 있게 해주고, 왜 기다리는지 알 수 있게 해줍니다ㅏ. (v$session,v$session_event)
3. 엄청난 DML작업 (몇천만 이상을 한번에 update하는 작업)을 하면 느려집니다. 왜 느려지냐면 롤백할 데이터를 UNDO tavlespace에 저장하는데 너무 많아서 undo 테이블 스페이스로 i/o가 심하게 발생합니다. 그래서 지금 얼마나 undo가 발생했는지 확인하는 view(v$undo_xxx)
4. lock(락) 이 발생했을 떄 원인 파악을 할 수 있습니다.
lock 실습 : 락이 발생했을 때 원인 파악을 빠르게 하는 방법
- putty창 3개 열기!
- 1창 : sys 유저에서 lock 발생 원인 찾는 쿼리
- 2창 : scott 유저에서 king의 월급을 9000으로 update (커밋하지말기)
- 3창 : scott 유저에서 king의 월급을 0로 update
아래 쿼리는 putty 1창에서 수행
select decode(status,'INACTIVE',username || ' ' || sid || ',' || serial#,'lock') as Holder,
decode(status,'ACTIVE', username || ' ' || sid || ',' || serial#,'lock') as waiter, sid, serial#, status
from( select level as le, NVL(s.username,'(oracle)') AS username,
s.osuser,
s.sid,
s.serial#,
s.lockwait,
s.module,
s.machine,
s.status,
s.program,
to_char(s.logon_TIME, 'DD-MON-YYYY HH24:MI:SS') as logon_time
from v$session s
where level>1
or EXISTS( select 1
from v$session
where blocking_session = s.sid)
CONNECT by PRIOR s.sid = s.blocking_session
START WITH s.blocking_session is null);
✅ ACTIVE는 기다리고 있는 중 !
lock 실습2. sid번호를 가지고 그 세션이 수행하고 있는 SQL문 알아내기
oracle sid를 이용한 sql문 찾기
set pages 40
col program for a25
col username for a10
col machine for a15
col module for a25
col spid for a6
col sid for 99999
select a.username,a.program,a.machine,a.module,b.spid,a.sid,a.serial#,a.status,
c.sql_text
from v$session a,
v$process b,
v$sql c
where a.sid = '&sid'
and b.addr = a.paddr
and a.sql_hash_value = c.hash_value(+)
and a.sql_address = c.address(+);✅ 상태가 active인 세션의 SQL을 볼 수 있습니다. (지금 waiting하는 세션)
os pid를 이용한 sql문 찾기
set pages 40
col module for a10
col MACHINE for a10
select /-+ use_hash(a,b,c) *-
a.username,a.program,a.machine,a.module,b.spid,a.sid,a.serial#,a.sql_hash_value,
d.PHYSICAL_READS, d.BLOCK_GETS,
c.sql_text
from v$session a,
v$process b,
v$sql c,
v$sess_io d
where b.spid = '&pid'
and b.addr = a.paddr
and a.sid = d.sid
and a.sql_hash_value = c.hash_value(+)
and a.sql_address = c.address(+);Dynamic Performance 뷰: 사용 예제
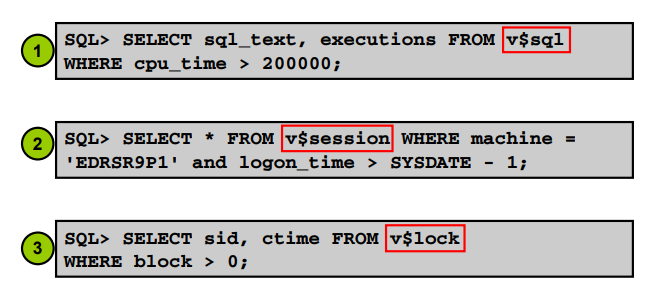
실습 현재 database에서 수행되고 있는 악성 SQL들을 찾아내시오
putty1 : 악성 SQL 수행
putty2 : cpu타임이 0.2초보다 큰 SQL text를 보여달라
SQL> SELECT sql_text, executions FROM v$sql
WHERE cpu_time > 200000;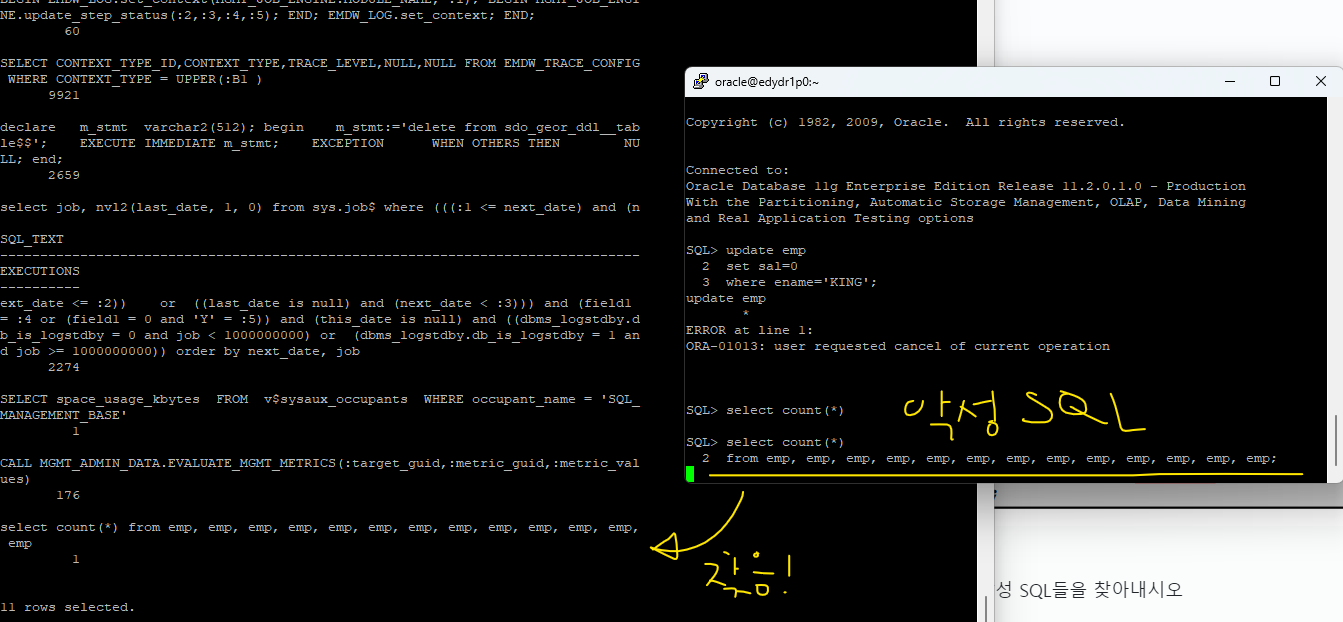
실습 누군가 우리 회사 db에 접속한 적이 있는지 확인해보기
SQL> SELECT * FROM v$session WHERE machine =
'EDRSR9P1' and logon_time > SYSDATE - 1;#우린 이렇게 수행했음
SQL> SELECT sid, machine
FROM v$session
WHERE logon_time > SYSDATE - 1;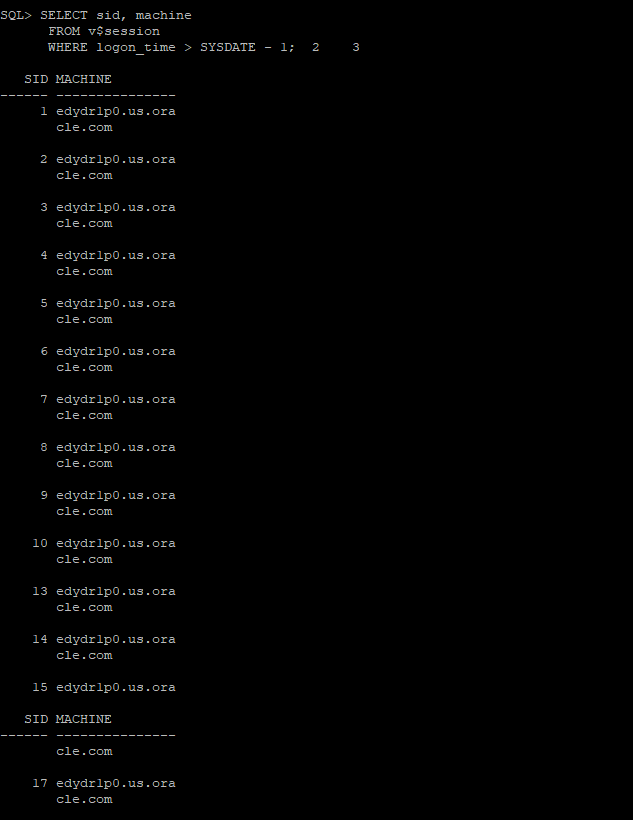
✅ 여기서 sid 확인하고 아래 sid로 sql문 찾는거에 sid넣어서 찾으면 악성sql찾을 수 있다.
set pages 40
col program for a25
col username for a10
col machine for a15
col module for a25
col spid for a6
col sid for 99999
select a.username,a.program,a.machine,a.module,b.spid,a.sid,a.serial#,a.status,
c.sql_text
from v$session a,
v$process b,
v$sql c
where a.sid = '&sid'
and b.addr = a.paddr
and a.sql_hash_value = c.hash_value(+)
and a.sql_address = c.address(+);실습 lock waiting 하고 있는 세션이 얼마나 락을 웨이팅하고 있는지 확인하는 쿼리
select sid, ctime
from v$lock
where block > 0;✅ update를 먼저 수행해서 락을 먼저 잡은 유저, 즉 락 홀더 세션의 SID번호와 락을 잡고있는 시간을 초로 보여줍니다. 그런데 락 홀더 세션의 sql은 위의 v$ 다이나믹 퍼포먼스 뷰로는 볼 수 없고 다른 SQL로 봐야한다. 락 홀더 세션의 상태가 INACTIVE 여서 그렇다. ACTIVE면 보인다.
✅ update할때는 TX락이 걸리고 select할 때도 락의 이름이 있는데 그게 잡힌다 !
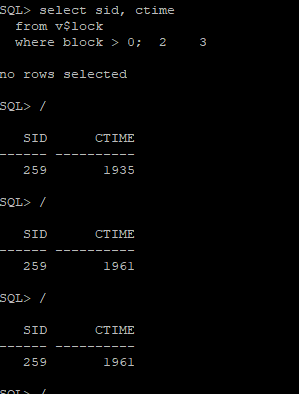
Dynamic Performance view의 고려 사항
- 이 view는 전부 sys유저가 소유하고있다.
- startup 단계에 따라서 서로 다른 뷰를 사용할 수 있다.
- Dynamic Performance view가 뭐가있는지 조회하려면 v$fixed_table을 보면 됩니다 !
- 동적 데이터를 보여주기 때문에 계속 갱신됩니다.
실습1. nomount 단계에서는 parameter file만 열리기 때문에 parameter file에 대한 정보만 볼 수 있다는 것을 실습하기
SQL> shutdown immediate
SQL> startup nomount
SQL> select count(*) from v$parameter;
COUNT(*)
----------
342
SQL> select count(*) from v$controlfile;
COUNT(*)
----------
0실습2 nomount상태에서 mount로 올리면 컨트롤파일을 열어서 올린거기 때문에 컨트롤 파일에 대한 정보를 볼 수 있다. 그래서 db 구조에 대한 모든 정보는 볼 수 있는데, data dictionary는 볼 수 없다. data dictionary는 시스템 테이블 스페이스에 있기 때문에 db를 open해야 볼 수 있다.
SQL> alter database mount;
SQL> select count(*) from v$controlfile;
COUNT(*)
----------
2
SQL> select count(*) from dba_tables;
select count(*) from dba_tables
*
ERROR at line 1:
ORA-01219: database not open: queries allowed on fixed tables/views only
# open단계가 아니라서 에러가 난다 !!!💡 dba를 위한 tip
db가 mount 상태에서 안올라가는 상황이 발생했다. db가 마운트 상태에 open으로 안올라가면 data file이나 redo logfile이 손상되거나 없어서 안올라가는 것이다. 그래서 data file과 redo log file의 위치를 mount상태에서 확인하고 싶다. 이럴 때 어떻게 해야할까?
- data file에 관련한 v$로 시작하는 뷰를 확인하는 방법
SQL> select name from v$fixed_table where name like '%DATA%FILE%';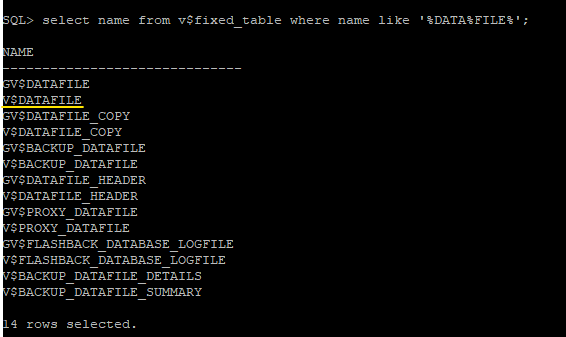
SQL> select name from v$datafile;
NAME
--------------------------------------------------------------------------------
+DATA/orcl/datafile/system.256.796857621
+DATA/orcl/datafile/sysaux.257.796857623
+DATA/orcl/datafile/undotbs1.258.796857625
+DATA/orcl/datafile/users.259.796857625
+DATA/orcl/datafile/example.265.796857803
+DATA/orcl/datafile/sysaux.267.1145464529
+DATA/orcl/datafile/users.268.1145464531
+DATA/orcl/datafile/system.269.1145464533
+DATA/orcl/datafile/system.270.1145464597
+DATA/orcl/datafile/ts01.273.1147004025
+DATA/orcl/datafile/ts02.274.1147260329
+DATA/orcl/datafile/ts07.275.1147260665
12 rows selected.
문제 log file에 관련한 v$로 시작하는 뷰를 확인하고 redo log file의 위치를 알아내세요!
SQL> select name
from v$fixed_table
where name like '%LOG%FILE%';
SQL> desc v$logfile;
Name Null? Type
----------------------------------------- -------- ----------------------------
GROUP# NUMBER
STATUS VARCHAR2(7)
TYPE VARCHAR2(7)
MEMBER VARCHAR2(513)
IS_RECOVERY_DEST_FILE VARCHAR2(3)
SQL> select member from v$logfile;
MEMBER
--------------------------------------------------------------------------------
+DATA/orcl/onlinelog/group_3.263.796857759
+FRA/orcl/onlinelog/group_3.259.796857763
+DATA/orcl/onlinelog/group_2.262.796857753
+FRA/orcl/onlinelog/group_2.258.796857757
+DATA/orcl/onlinelog/group_1.261.796857743
+FRA/orcl/onlinelog/group_1.257.796857749
+DATA/orcl/onlinelog/group_4.271.1146924991
+FRA/orcl/onlinelog/group_4.264.1146924997
+DATA/orcl/onlinelog/group_5.272.1146925419
+FRA/orcl/onlinelog/group_5.265.1146925423
10 rows selected.✅ v$datafile, v$logfile을 조회해서 data file, rode logfile 이 어디에 위치하고 있는지 확인하고, 여기 나온대로 실제로 os에 해당파일이 없으면 mount에서 open으로 올라가지 않는다.
데이터 딕셔너리: 개요
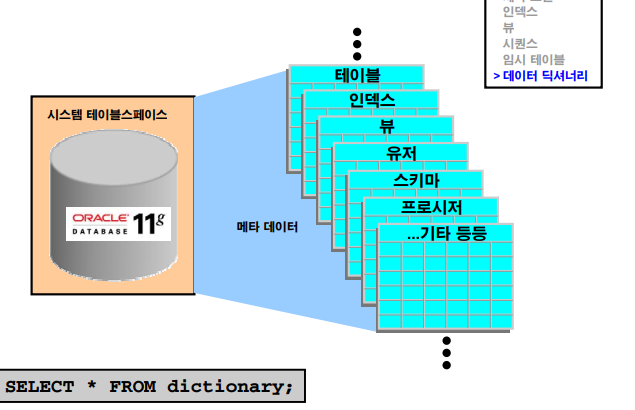
시스템 테이블 스페이스 안에 데이터 딕셔너리가 있다.
데이터 딕셔너리 뷰
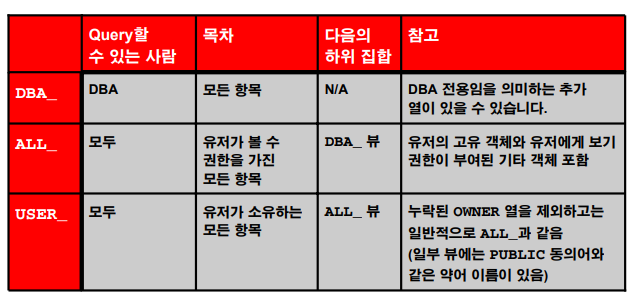
데이터 딕셔너리 (사용예제)
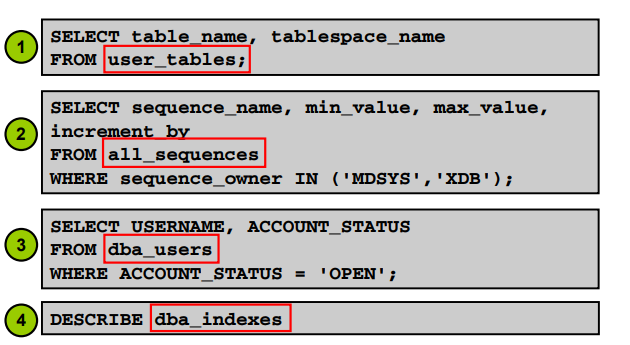
✔️ 데이터 딕셔너리의 소유자는 sys이다.
✔️ 데이터 딕셔너리는 system tablestace에 있다. db가 open되어야만 볼 수 있다.
✔️ 데이터 딕셔너리는 다음 3가지 종류가 있다.
1. user_xxx : user가 소유한 모든 객체
2. all_xxx : 유저가 볼 수 있는 권한을 가직 항목
3. dba_xxx : db에 내에 있는 모든 항목
객체 - 테이블, 뷰, 인덱스, 시퀀스, 시너님
문제 데이터 베이스에 생성되어 있는 유저가 몇명인지 조회하기(db계정이 몇개인지)
SQL> alter database open;
SQL> select table_name from dictionary
where table_name like '%USER%'
and table_name not like 'USER%';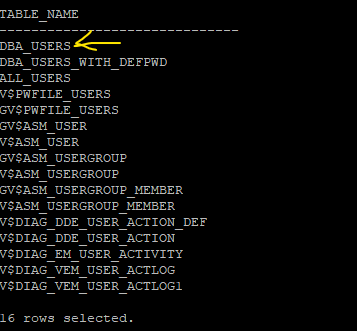
SQL> select username, account_status from dba_users;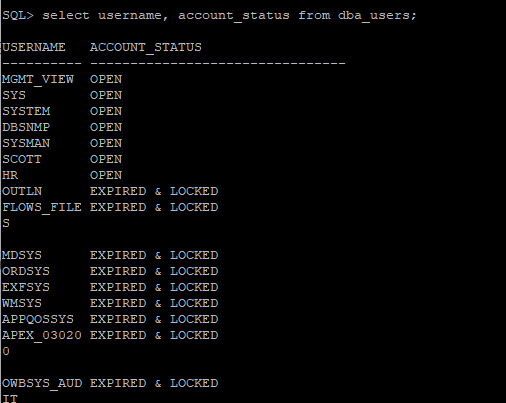
문제 hr유저가 가지고 있는 테이블의 갯수를 확인하세요
SQL> select count(*) from dba_all_tables where owner = 'HR';
SQL> select count(*) from dba_tables where owner = 'HR';
COUNT(*)
----------
0
정답은C,D,F
A: 데이터 딕셔너리는 뷰이다. x$로 시작하는 테이블을 조인해서 만든 뷰 ! DBA-defined table로 만든게 아니다.select table_name from dba_tables; ↑ x$table로 조인해서 만든 view!B: dba가 아니라 오라클이 만들고 유지도 오라클이.
C: CDB_xxx 이런것도 있다. 12c부터 ! 클라우드 뭐시기
E: system user아니고 sys!

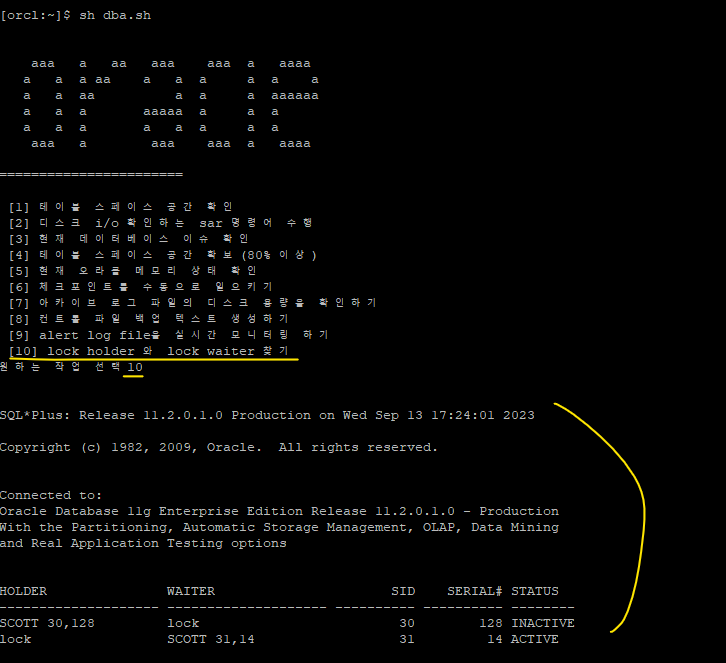
(오늘의 마지막 문제) dba.sh 쉘 스크립트에 8번째로 lock holder 세션과 waiting 세션을 찾는 코드를 추가하세요!
1. ed lock.sql 해서 안에 아래의 쿼리문을 넣었다.
SQL> ed lock.sql
col holder for a20
col waiter for a20
select decode(status,'INACTIVE',username || ' ' || sid || ',' || serial#,'lock') as Holder,
decode(status,'ACTIVE', username || ' ' || sid || ',' || serial#,'lock') as waiter, sid, serial#, status
from( select level as le, NVL(s.username,'(oracle)') AS username,
s.osuser,
s.sid,
s.serial#,
s.lockwait,
s.module,
s.machine,
s.status,
s.program,
to_char(s.logon_TIME, 'DD-MON-YYYY HH24:MI:SS') as logon_time
from v$session s
where level>1
or EXISTS( select 1
from v$session
where blocking_session = s.sid)
CONNECT by PRIOR s.sid = s.blocking_session
START WITH s.blocking_session is null);2. 확인해보기
SQL> @lock.sql 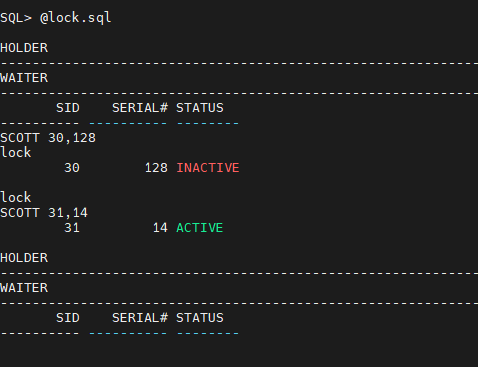
3. 스크립트에 추가
$ vi dba.sh
# /bin/bash
echo -e "
aaa a aa aaa aaa a aaaa
a a a aa a a a a a a
a a aa a a a aaaaaa
a a a aaaaa a a a
a a a a a a a a
aaa a aaa aaa a aaaa
"
echo -e "======================="
echo " "
echo " [1] 테이블 스페이스 공간 확인 "
echo " [2] 디스크 i/o 확인하는 sar 명령어 수행 "
echo " [3] 현재 데이터베이스 이슈 확인 "
echo " [4] 테이블 스페이스 공간 확보(80% 이상) "
echo " [5] 현재 오라클 메모리 상태 확인 "
echo " [6] 체크포인트를 수동으로 일으키기 "
echo " [7] 아카이브 로그 파일의 디스크 용량을 확인하기"
echo " [8] 컨트롤 파일 백업 텍스트 생성하기"
echo " [9] alert log file을 실시간 모니터링 하기"
echo " [10] lock holder 와 lock waiter 찾기"
echo -n "원하는 작업 선택"
read aa
echo " "
case $aa in
1) sh /home/oracle/t.sh;;
2) sh /home/oracle/sar.sh;;
3) sh /home/oracle/o.sh;;
4) sh /home/oracle/add_t.sh;;
5) sqlplus scott/tiger @/home/oracle/sga.sql ;;
6) sqlplus scott/tiger @/home/oracle/ckpt.sql ;;
7) sqlplus "/as sysdba" @/home/oracle/fra_space.sql ;;
8) sqlplus "/as sysdba" @/home/oracle/c.sql ;;
9) sh /home/oracle/testlog.sh ;;
10) sqlplus "/as sysdba" @/home/oracle/lock.sql ;;
esac
echo " "