

복습
✔️ Failure(장애) 범주
1. SQL 문장 에러
2. 유저 프로세서 에러
3. 네트워크 에러
4. 휴먼 에러 (인간의 실수)
5. 인스턴스 Failure
6. 디스크 손상 또는 파일 손상 (미디어 Failure)
❓ SM dba(유지보수)의 일상
- 아침 : 간밤에 돌았던 백업이 잘 수행되었는지, 간밤에 돌았던 배치 작업과 통계정보 수집작업이 잘 수행 되었는지, 개발자들이나 운영자들이 DB 오류 관련해서 온 메일들 처리
- 오후 : DB 모니터링 하면서 악성 SQL 찾아서 튜닝, DB관련한 오류들이 있다면 해결, 데이터 이행에 관련한 모니터링 작업,
운영 db -> 개발 db싱크 맞춰주는 작업, 테이블이나 인덱스 생성 - 3개월에 한번 토요일 : DB reorg 작업
❓ db엔지니어 의 일상
- 오라클에 발생하는 여러 문제들을 해결해주는 역할
- 장애가 발생하면 백업받은 데이터로 복구
❓ data 엔지니어 의 일상
- 오라클, 하둡 등의 여러 문제들 해결, 데이터 이행(파이프라인 구성) 예쁘게 테이블에 적재하는 역할, 시각화, 장애가 발생하면 백업받은 데이터로 복구
유저에러에 대한 복구 기술인 Flashback 기능
1. flashback 기술 총정리
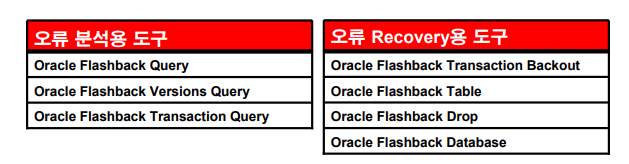
- 평상시에 flashback이 가능한지 미리 확인을 하고 있어야한다.
SQL> show parameter recyclebin;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
recyclebin string on- 휴지통의 공간은 해당 테이블이 존재하는 테이블 스페이스에 있습니다. 그래서 emp 같은 경우는 users 테이블 스페이스에 있는데 만약 emp 테이블을 drop하면 users 테이블 스페이스에 있는 휴지통에 들어갑니다. users테이블 스페이스가 거의 꽉찼을때 emp 테이블을 드롭하면 휴지통에 안들어가고 그냥 사라진다. 90% 이상 테이블 스페이스가 공간이 차지 않도록 관리하고 있어야합니다.
실습1. scott 유저로 접속해서 휴지통 속에 있는 테이블들을 모두 삭제하시오!
SCOTT @ orcl > show recyclebin; ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME ---------------- ------------------------------ ------------ ------------------- DEPT BIN$BjyPmuQ//j3gYAB/AQB2Yg==$0 TABLE 2023-09-26:15:23:13 EMP BIN$BjyPmuQ+/j3gYAB/AQB2Yg==$0 TABLE 2023-09-26:15:23:13 EMP70 BIN$BavC7l93l3DgYAB/AQA/Mg==$0 TABLE 2023-09-19:09:58:48 EMP900 BIN$BZ2Yjje6RrzgYAB/AQA00g==$0 TABLE 2023-09-18:17:04:47 EMP901 BIN$BZ2Yjje7RrzgYAB/AQA00g==$0 TABLE 2023-09-18:17:05:13 SCOTT @ orcl > purge recyclebin; Recyclebin purged.
실습2. sh계정과 hr계정의 테이블이 어느 테이블 스페이스가 존재하는지 확인하고 공간이 넉넉한지 확인하시오
select table_name, tablespace_name
from dba_tables
where owner in('SH','HR');
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
TIMES EXAMPLE
PRODUCTS EXAMPLE
CHANNELS EXAMPLE
PROMOTIONS EXAMPLE
CUSTOMERS EXAMPLE
COUNTRIES EXAMPLE
SUPPLEMENTARY_DEMOGRAPHICS EXAMPLE
CAL_MONTH_SALES_MV EXAMPLE
FWEEK_PSCAT_SALES_MV EXAMPLE
DR$SUP_TEXT_IDX$I EXAMPLE
DR$SUP_TEXT_IDX$R EXAMPLE
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
SALES400 USERS
REGIONS TS200
JOB_HISTORY TS200
JOBS TS200
LOCATIONS TS200
DEPARTMENTS TS200
EMPLOYEES TS200
COUNTRIES
SALES
COSTS
DR$SUP_TEXT_IDX$K
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
DR$SUP_TEXT_IDX$N
SALES_TRANSACTIONS_EXT
DIMENSION_EXCEPTIONS USERS
25 rows selected. ✅ 공간은 sh dba.sh 해서 봤음
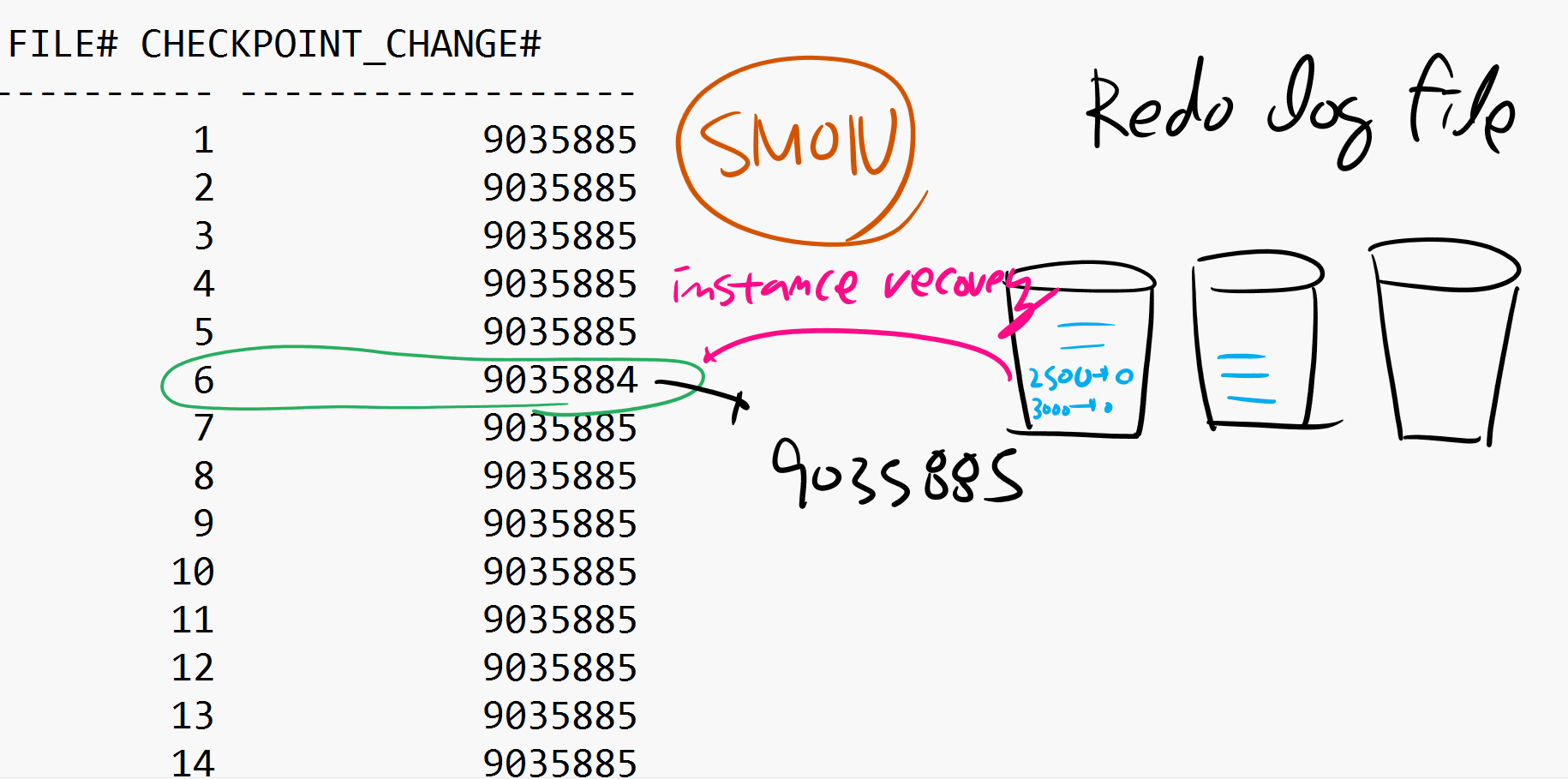
p.14-10 Instance Failure
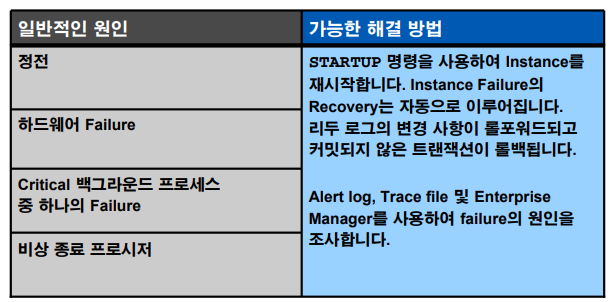
스캇의 월급을 update 3000 -> 0 , commit O 일때 DB buffer cache 에 0으로 수정하고 Redo log buffer에 commit한것도 올렸다. (LGWR는 커밋할때, 3초, Redo log buffer가 1/3 찼을 때, check point가 작동할때 작동한다) LGWR얘가 redo log file에 3000 -> 0 커밋했다고 넣는다. DBWR는 commit할 때 작동하지 않아서 아직 data file은 0으로 바뀌지 않고 3000으로 남아있다. DBWR는 체크포인트가 일어날때까지 기다리고 있는 것이다. 이 상태에서 디비가 내려간다면 (정전이나 shutdown abort..) 메모리는 다 날라가고 data file은 0으로 바뀌기전 3000 이라는 데이터가 남아있을 것이다. 그렇지만 다시 startup 했을 때 0으로 잘 읽는다 . SMON이 redo log file에 있는 내용을 보고서 commit을 해주고 적용시켜준다.
만약 커밋을 하지 않은 상태라면 rollback해서 3000으로만들고, commit했지만 반영이 안된거라면 0으로 적용해준다. ➡️Instance recovery
- update 하고 commit한 상태 -> 정전 -> startup 할 때 복구 (롤포워드)
- update하고 commit 안한 상태 -> 정전 -> startup할 때 롤백
실습1. scott으로 접속해서 KING의 월급을 0으로 변경하세요(커밋하지말기)
SCOTT @ orcl > update emp 2 set sal = 0 3 where ename = 'KING'; 1 row updated.
실습2. 다른 터미널 창에서 백그라운드 프로세서 pmon을 강제로 kill 시켜서 인스턴스를 failure시킨다. (alert 로그 파일 실시간 확인하기)
[orcl:~]$ ps -ef | grep pmon oracle 5176 1 0 Sep24 ? 00:00:50 asm_pmon_+ASM oracle 8229 7529 0 10:27 pts/5 00:00:00 grep pmon oracle 29360 1 0 05:26 ? 00:00:04 ora_pmon_orcl -- 얘 죽이기 [orcl:~]$ kill -9 29360 * 이렇게 pmon을 죽이면, alert log file에 디비가 내려갔다가 다시 자동으로 올라오는것을 볼 수 있다.
✅ 이 상황에서 에러 확인 해달라고 하면 trace로 가서 alert log file 열고 /terminating the instance 해서 보기[orcl:~]$ trace [orcl:trace]$ ls -rlt [orcl:trace]$ vi alert_orcl.log
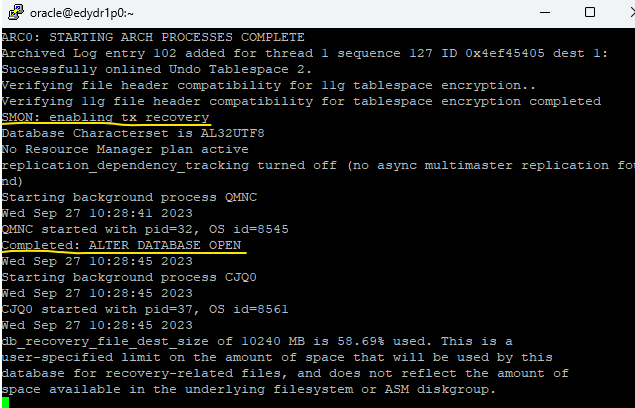
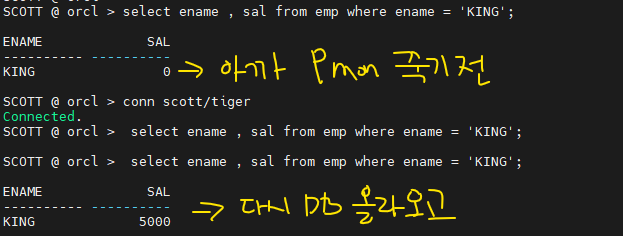

p.14-11 Checkpoint시 발생하는 일들
💡 Checkpoint 이벤트란 메모리의 변경사항을 database에 반영하는 작업
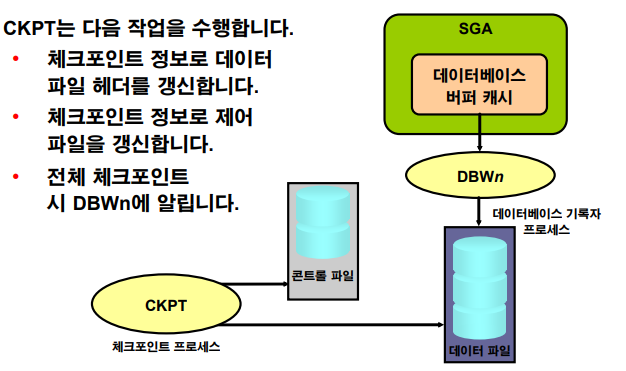
ckpt ------> LGWR ------> DBWR ↓ control file, data file header에 몇번째 체크포인트를 일으켰다 라고 기록을 한다.
실습1. 지금 db의 체크포인트 주기를 확인하기
SQL> show parameter checkpoint; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_checkpoint_timeout integer 1800✅ 30 분에 한번씩 체크포인트 발생!
실습2. data file header에 기록된 checkpoint 주기 번호를 확인하기
SYS> select file#, checkpoint_change# from v$datafile_header; FILE# CHECKPOINT_CHANGE# ---------- ------------------ 1 5466332 2 5466332 3 5466332 4 5466332 5 5466332 6 5466332 7 5466332 8 5466332 9 5466332 10 5466332 11 5466332 FILE# CHECKPOINT_CHANGE# ---------- ------------------ 12 5466332 13 5466332 14 5466332 15 5466332 16 5466332 17 5466332 18 5466332 19 5466332 20 5466332 21 5466332 22 5466332 FILE# CHECKPOINT_CHANGE# ---------- ------------------ 23 5466332 24 5466332 24 rows selected.✅ 위에 나오는 번호들이 모두 동일해야한다. 틀린게 있다면 옛날거라서 셧다운되면 그 파일이 깨져서 혹시 안올라올 수 있으니 수동으로 체크포인트를 일으켜준다 !
SYS> alter system checkpoint; -- 이렇게 하니까 위 번호들이 모두 동일하게 다른 번호로 바뀌었다.
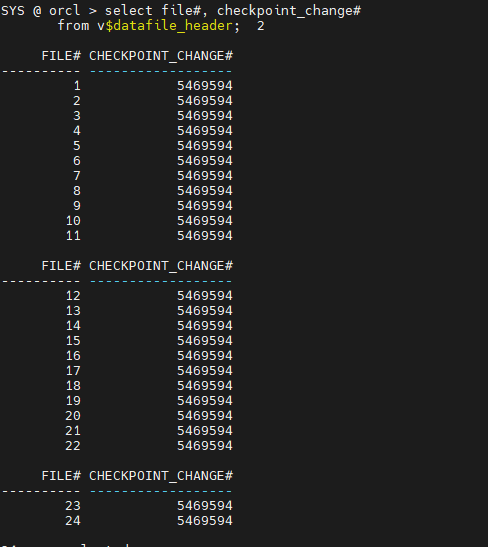
실습3. 컨트롤 파일에 있는 체크포인트 번호 확인하기 (위와 동일해야한다!)
SYS> select checkpoint_change# from v$database; CHECKPOINT_CHANGE# ------------------ 5469594✅ 만약 datafile 중에서 하나라도 checkpoint 번호가 다른것이 있다면, 그 파일은 현재 시점의 파일이 아니라 옛날 파일이다. 혹시라도 그상태에서 갑자기 정전이되어 db가 shutdown 된다면 그 파일로 인해서 db가 안올라올 수 있다. 그래서 복구를 해주어야 한다!
💡 알고있자 !
✔️ datafile header에 있는 체크포인트 번호 확인은
v$datafile_header✔️ 컨트롤 파일에 있는 체크포인트 번호 확인은
v$databasep14-12. Instance Recovery 이해
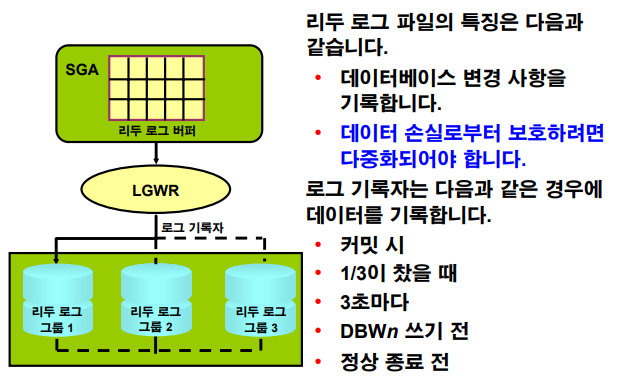
💡 갑자기 정전이 일어났을 때 다시 dba가 startup을 하게 되는데, 그 때 오픈단계에서 Instance Recovery가 발생한다. Instance Recovery를 하려면 redo log file이 있어야하는데 만약 redo log file이 하나라도 손상되었으면 Instance Recovery를 할 수 없다. 그래서 redo log file은 다중화를 해야한다.
SQL> select group#, members from v$log; GROUP# MEMBERS ---------- ---------- 1 2 2 2 3 2 4 2 5 2
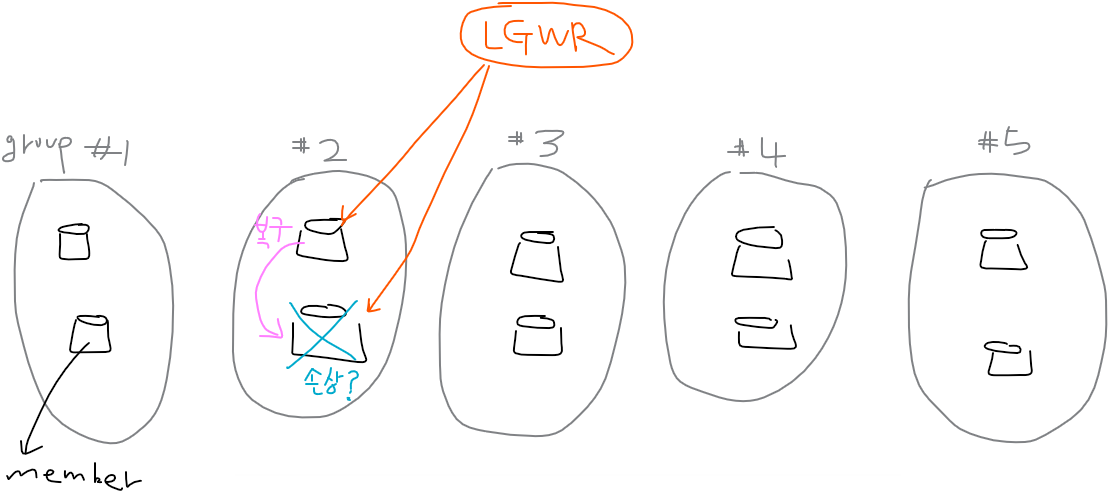
✅ 로그라이터는 내려쓸 때 2개의 멤버에 다 내려쓴다. 만약 하나가 손상되었다면 다른 한쪽에서 복구를 해준다. 그룹에 멤버가 하나밖에 없다면 복구가 어렵다.
p.14-13 Instance Recovery 이해
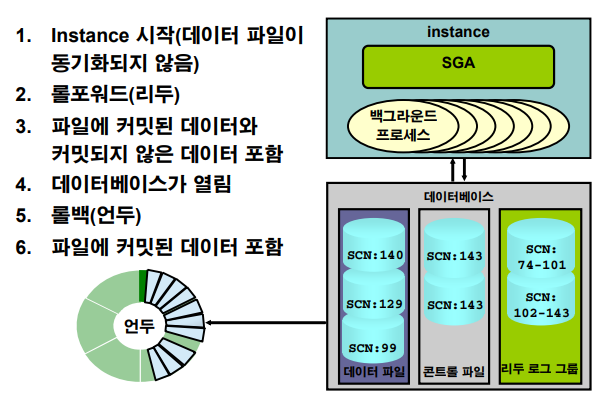
자동 Instance Recovery 또는 Crash Recovery의 특징은 다음과 같습니다.
- 종료 시 동기화되지 않은 파일이 있는 데이터베이스를 열려고 할 때 발생합니다.
- 리두 로그 그룹에 저장된 정보를 사용하여 파일을 동기화합니다. (만약 체크포인트 번호가 하나가 다르다면 그것을 동기화해주는 것)
- 두 개의 개별 작업을 포함합니다.
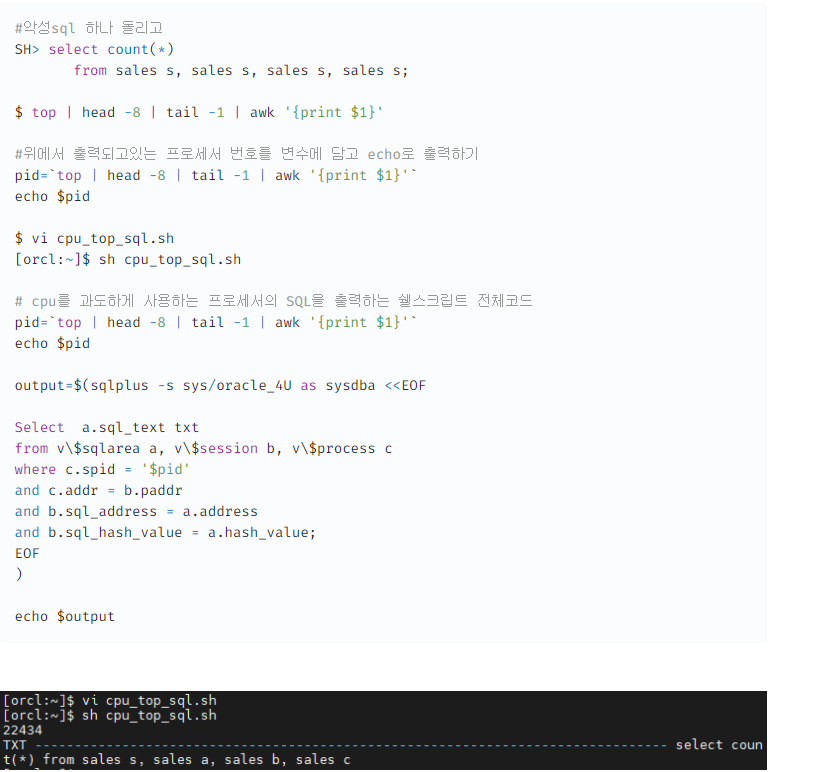
롤포워드: 리두 로그 변경 사항(커밋된 사항 및 커밋되지 않은 내용 모두)은 데이터 파일에 적용됩니다. (1.커밋했던 안했던 모두 다 일단 적용하고)롤백: 변경되었지만 커밋되지 않은 내용이 원래 상태로 돌아갑니다. (2.롤백해버림)❓ 만약 대량의 DML 작업을 하는 도중에 갑자기 Instance Failure가 발생하면 startup 하고 나서 instance recovery를 하느랴고 cpu를 과다하게 사용한다. 그래서 db에 작업이 안되는 현상이 비일비제하다.
- PL/SQL 개발자 터무니 없는 잘못된 프로그램이 수행되어서 DB가 먹통?
- DB가 너무 느리다고 DBA에게 문의가 옵니다.
- DBA가 원인 파악을 해줘야한다. 어떤 개발자가 어떤잘못을 해서 문제가 되었다 라고 알려주기
- shurdown immediate를 먼저 한다. -> pid 찾아서 악성 sql 찾는 쿼리 우리 어제 함
- 30분 이상 안된다면, shutdown abort 해야한다. (startup을 하고 나서 instance recovery 하느랴 db에 작업이 안될 각오를 한다.)
- 다시 shutdown immediate 하고 startup을 한다 (상황이 많이 좋아짐)
p.14-14 인스턴스 리커버리 단계
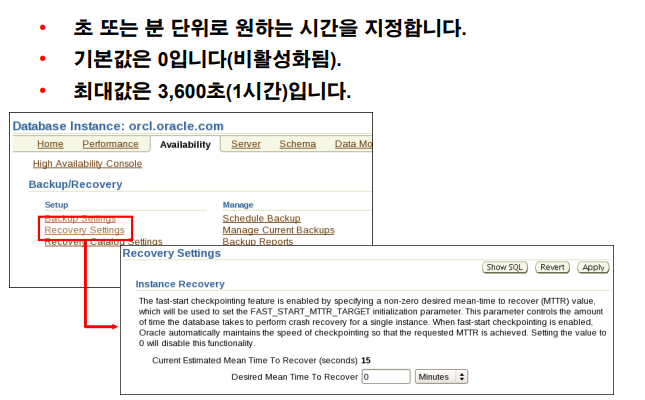
💡 dba가 instance recovery에 대해서 신경써야하는 단 하나의 파라미터는
SYS> show parameter mttr; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ fast_start_mttr_target integer 0 SYS> show parameter fast_start_mttr_target;
fast_start_mttr_target얘를 600(10분)으로 지정하면, 혹시라도 instance failure가 발생했을 때 instance recovery에 걸리는 시간을 10분이 되도록 평상시에 오라클이 알아서 체크포인트 주기를 스스로 정해서 일으켜라 ! 그리고 혹시 인스턴스 장애가 발생하면, startup할 때 인스턴스 리커버리 시간이 10분을 넘기지 말라고 지정하는 것이다. -> 디비에 변경사항 많으면 더 자주, 없으면 덜 해라 오라클 너가 알아서 하고 나는 10분만 기다릴게
문제 fast_start_mttr_target를 600으로 지정
SYS @ orcl > @para Enter value for name: fast_start_mttr_target old 3: where name like '%&name%' new 3: where name like '%fast_start_mttr_target%' NAME ISSYS_MOD ------------------------------ --------- fast_start_mttr_target IMMEDIATE -- 바로 적용 가능 alter system set fast_start_mttr_target=600; System altered. SYS @ orcl > show parameter fast_start_mttr_target; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ fast_start_mttr_target integer 600
Instance Recovery 튜닝
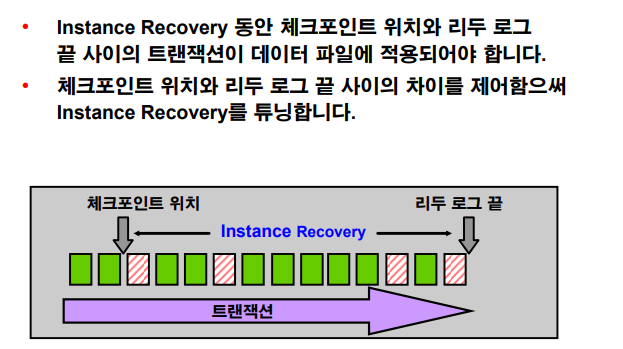
MTTR Advisor 사용
💡 위에서 fast_start_mttr_target 를 10분으로 설정했는데, 난 얼마나 지정해야할지 잘 모르겠다 할때 이것을 사용한다 !
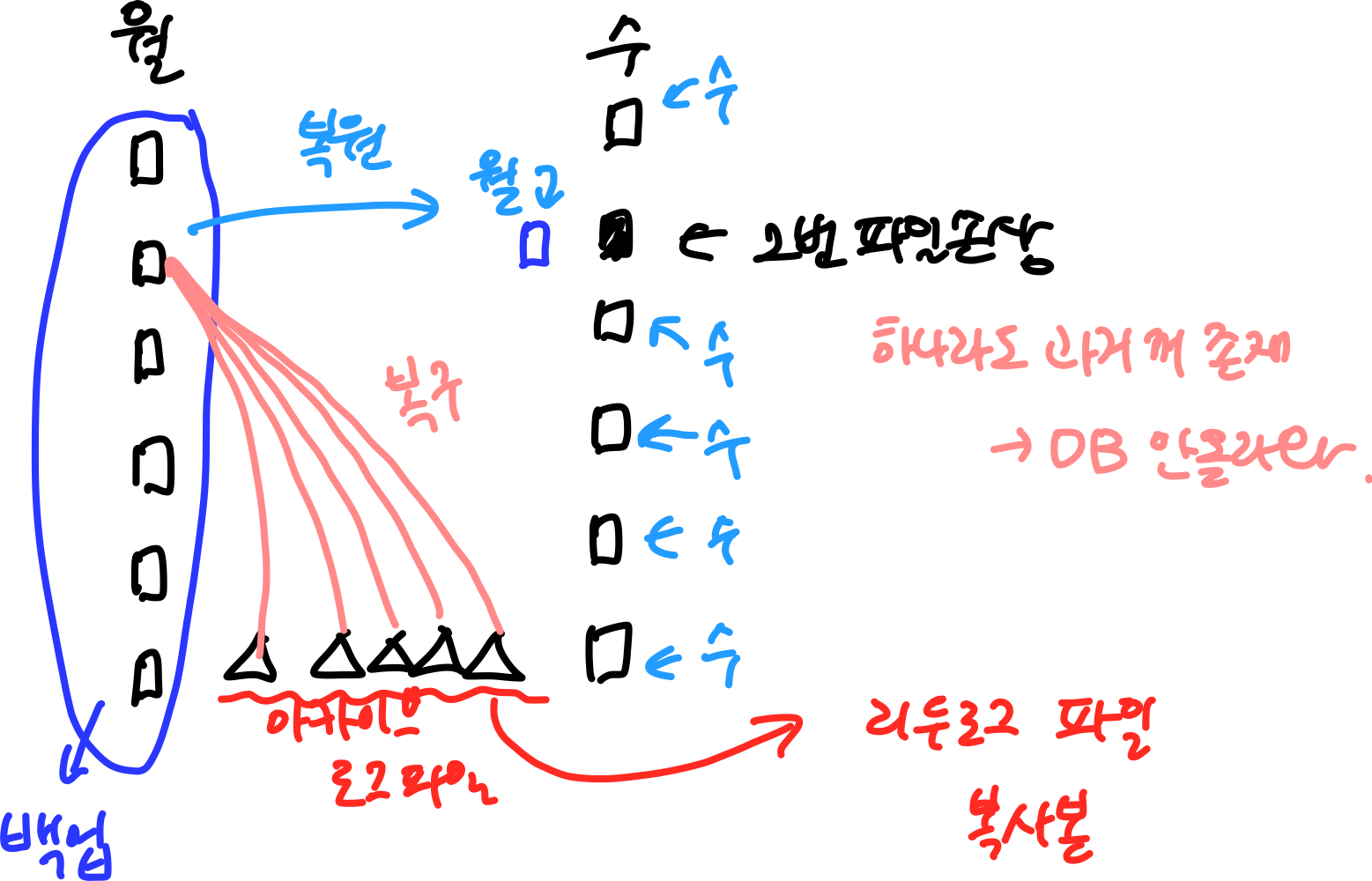
p.14-17 Media Failure

- old 디스크가 깨지면 새로운 디스크에 써야한다.
- 리두 정보를 적용해야 최신 파일로 만들어줄 수 있다.
월 수 1 □ □ 2 □ ■ <--- 2번 파일 손상 3 □ □ 4 □ □ 5 □ □ 6 □ △ △△△△△△△△△△△△ □ △는 아카이브 로그 파일 (리두로그 파일의 복사본)
위 상황에서 다행히 월요일에 백업을 했다. 그러면 수요일 2번자리에서 백업받은것을 가져온다면 손상된 2번파일의 데이터는 월요일 상태이고 나머지는 수요일 상태일것이다.
아카이브 로그 파일을 백업에 적용하기.
✅ 월요일 데이터를 수요일 손상된 파일로 가져오는 행위, 즉 과거에 백업받은것을 가져오는것복원(restore)라고 한다. 복원한 백업에 아카이브 로그 파일을 적용해서 최신 파일로 만들어 주는 작업이복구(recovery) 이다.
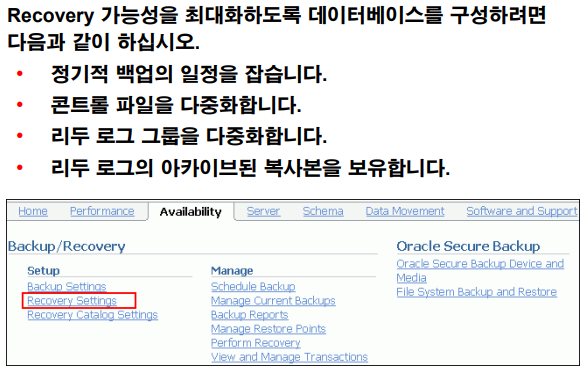
p.14-18 Recovery 가능성 구성
💡 오라클에서 권장하는 백업 최적화 구성 내영 4가지
실습1. control file이 다중화가 되어있는지 확인하기
✔️ CKPT가 두개에 동시에 내려쓴다. 두개중 하나가 깨졌으면 나머지에서 받으면 되고 두개다 깨지면 백업 받아야 한다.
SQL> select * from v$controlfile;
STATUS
-------
NAME
--------------------------------------------------------------------------------
IS_ BLOCK_SIZE FILE_SIZE_BLKS
--- ---------- --------------
+DATA/orcl/controlfile/current.260.796857737
NO 16384 600
+FRA/orcl/controlfile/current.256.796857739
YES 16384 600실습2. 리두 로그 그룹이 다중화 되어있는지 확인하기
SQL> select group#, members from v$log; GROUP# MEMBERS ---------- ---------- 1 2 2 2 3 2 4 2 5 2 SYS @ orcl > col member for a45 SYS @ orcl > select group#, member GROUP# MEMBER ---------- --------------------------------------------- 1 +DATA/orcl/onlinelog/group_1.261.796857743 -- 1이 +DATA에 1 +FRA/orcl/onlinelog/group_1.257.796857749 -- 1이 +FRA에 2 +DATA/orcl/onlinelog/group_2.262.796857753 2 +FRA/orcl/onlinelog/group_2.258.796857757 3 +FRA/orcl/onlinelog/group_3.259.796857763 3 +DATA/orcl/onlinelog/group_3.263.796857759 4 +DATA/orcl/onlinelog/group_4.271.1146924991 4 +FRA/orcl/onlinelog/group_4.264.1146924997 5 +FRA/orcl/onlinelog/group_5.265.1146925423 5 +DATA/orcl/onlinelog/group_5.272.1146925419✅ 그룹당 멤버를 2개 이상 유지하고 멤버들은 서로 다른 디스크에 분리해서 구성해야 장애가 났을 때 잘 대처할 수 있다!!
실습3. 아카이브 모드로 구성되어있는지 확인
SYS @ orcl > archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 125 Next log sequence to archive 129 Current log sequence 129
💡 리두로그파일은 덮어씌워지면서 없어지기 때문에 아카이브 로그 파일이 리두로그 파일을 복사해놓는다.
실습4. 아카이브 로그 파일이 얼마나 생성되어져 있는지 확인하기
SQL> select * from v$archived_log;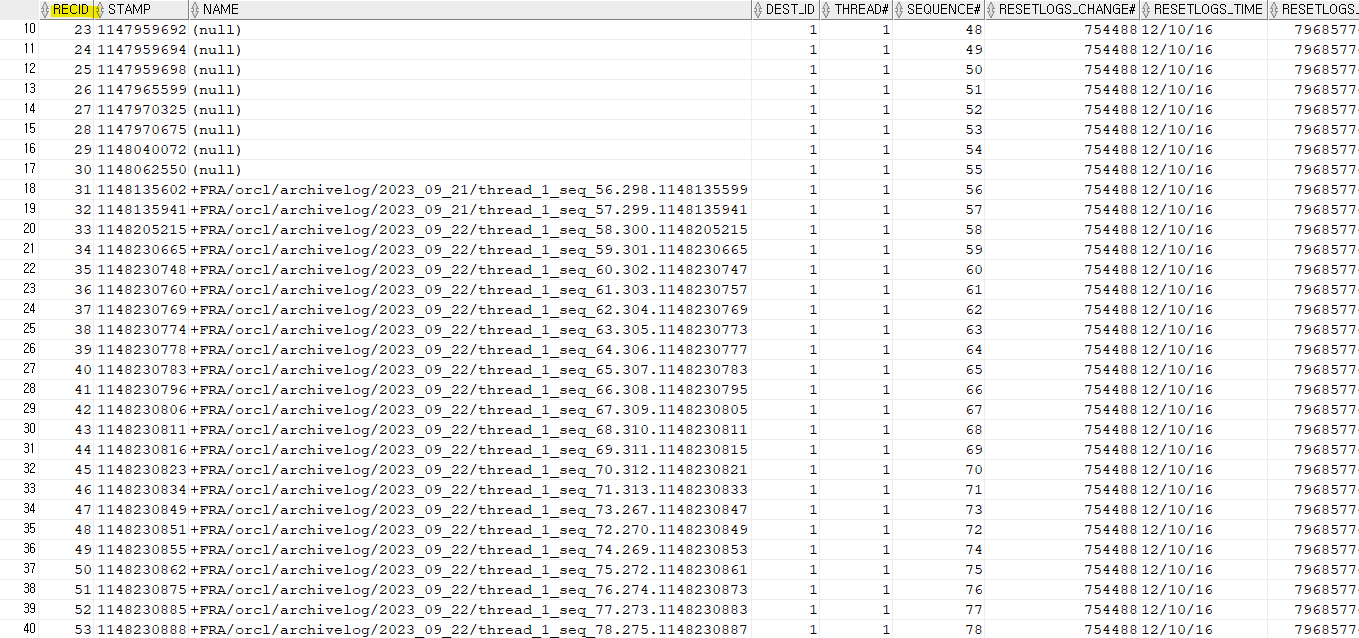
💡 데이터 베이스를 전체 백업 받고 기존 백업본과 아카이브 로그 파일을 모두 지우기
: 우리 공간 없어서 !
[orcl:~]$ rman target / nocatalog Recovery Manager: Release 11.2.0.1.0 - Production on Wed Sep 27 14:03:52 2023 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: ORCL (DBID=1324638472) using target database control file instead of recovery catalog1. 아카이브 로그 파일을 전부 지우기
RMAN> delete copy;2. 예전에 백업받았던 백업본도 전부 지우기
RMAN> delete backup;3. 여유공간 확인하기
col "FRA Name" for a10 SYS> @fra_space.sql FRA Name Space Limit (MB) Space Used (MB) Space Reclaimable (MB) Free Space (MB) ---------- ---------------- --------------- ---------------------- --------------- +FRA 10240 366 0 9874col "Disk Group Name" for a10 SELECT dg.name AS "Disk Group Name", ROUND(SUM(dg.free_mb) / 1024, 2) AS "Free Space (GB)", ROUND(SUM(dg.total_mb) / 1024, 2) AS "Total Space (GB)", ROUND((SUM(dg.total_mb) - SUM(dg.free_mb)) / 1024, 2) AS "Used Space (GB)", ROUND((SUM(dg.free_mb) / SUM(dg.total_mb)) * 100, 2) AS "Used Space (%)" FROM v$asm_diskgroup dg group by dg.name; Disk Group Free Space (GB) Total Space (GB) Used Space (GB) Used Space (%) ---------- --------------- ---------------- --------------- -------------- FRA 8.57 9 .43 95.25 DATA .74 9 8.26 8.18 SYS @ orcl > @dataspace.sql SYS @ orcl > select table_name from dba_tables where tablespace_name='TS500'; no rows selected SYS @ orcl > drop tablespace ts500 including contents and datafiles;4. 전체 백업받기
RMAN> backup database; RMAN> list backup;
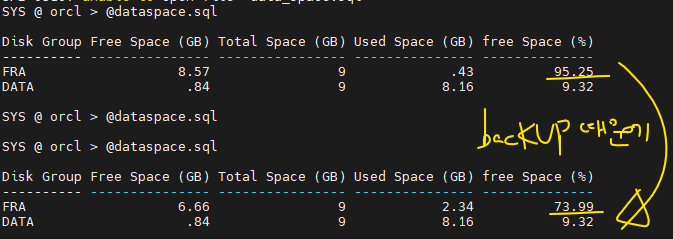
p.14-19 Fast Recovery Area(FRA)
💡 이 영역에 rman 백업본과 아카이브 로그 파일이 생성된다. 또, 다중화한 control file 미러본과 redo log file 다중화한 redo log file 미러본이 생성된다.
왜 fast냐면, 빠르게 백업과 복구를 할 수 있어서.

한달이라고 설정하면 알맨이 항상 한달전으로 돌릴 수 있도록 설정해놓는다.
실습1. fast recovery area영역이 어딘지 확인하기
SQL> show parameter db_recovery;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_recovery_file_dest string +FRA -- 여기에 생성
db_recovery_file_dest_size big integer 10G문제 db_recovery_file_dest_size 의 사이즈를 20G로 늘리기
SYS @ orcl > @para
Enter value for name: db_recovery_file
old 3: where name like '%&name%'
new 3: where name like '%db_recovery_file%'
NAME ISSYS_MOD
------------------------------ ---------
db_recovery_file_dest IMMEDIATE
db_recovery_file_dest_size IMMEDIATE
SYS> alter system set db_recovery_file_dest_size=20G;
System altered.
SYS @ orcl > show parameter db_recovery;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_recovery_file_dest string +FRA
db_recovery_file_dest_size big integer 20Gp.14-20 컨트롤 파일 다중화
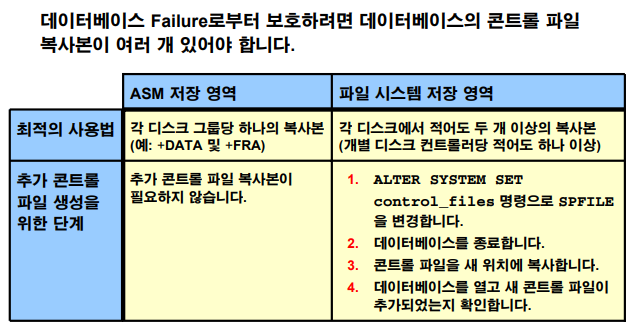
실습1. ASM쪽에 컨트롤 파일을 다중화 하지 말고 1개만 유지하게 하기
1. controlfile 이 있는 위치를 확인
SQL> select name from v$controlfile; NAME -------------------------------------------------- +DATA/orcl/controlfile/current.260.796857737 +FRA/orcl/controlfile/current.256.7968577392. controlfile 생성하는 스크립트를 만듭니다.
$ sh dba.sh [7] 컨트롤 파일 백업 텍스트 생성하기 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options PL/SQL procedure successfully completed.3. db 인스턴스를 내린다. (alert log file 보기)
SYS> shutdown immediate4. 다시 db를 올린다.
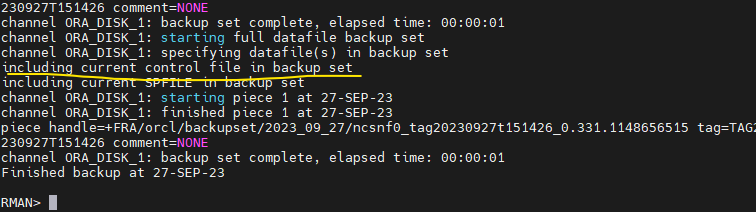
SYS> startup5. db전체 백업을 하는데 컨트롤파일도 포함해서 백업하기
$ rman target / nocatalog RMAN> backup database include current controlfile;
6. spfile에 control_files에 컨트롤 파일 위치를 하나만 남겨둔다.
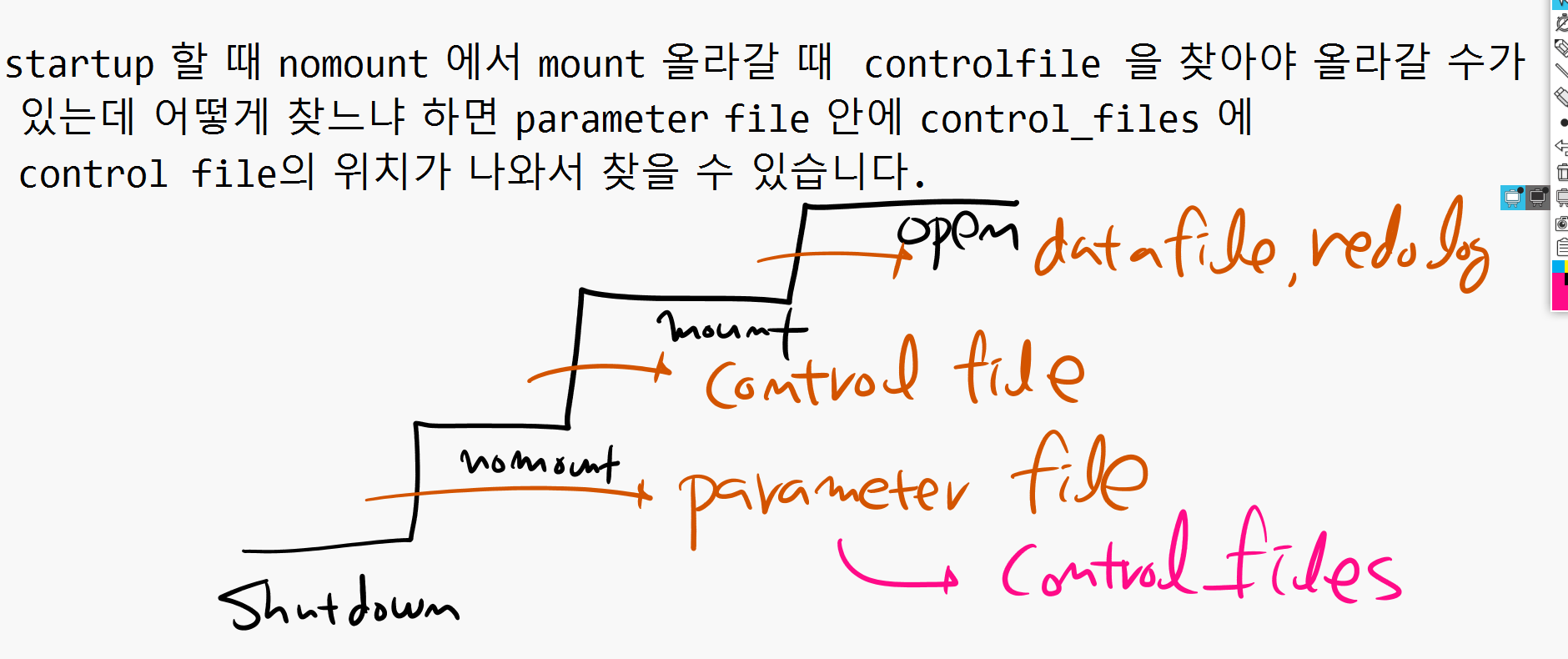
💡 startup할 때 control_files 파라미터가 컨트롤 파일 위치를 보고 여는데 이 위치가 두개가있다. 하나는 +DATA고 하나는 +FRA이다. 두군데를 다 찾아가서 연다.
nomount에서 인스턴스 구성되려면 파라미터 파일이다. nomount에서 파라미터 파일이 필요하고, mount로 올라갈 때 컨트롤 파일이 필요하고, open 단계로 올라가려면 datafile, redolog file인데 이 둘을 어케 찾냐면 컨트롤 파일을 찾아서 보고 컨트롤 파일을 어떻게 여냐면 파라미터 파일안에 control_files 안에 control file의 위치가 나온다.
SYS> @para alter system set control_files='+DATA/orcl/controlfile/current.260.796857737' scope=spfile; SYS @ orcl > show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.796857737, +FRA/orcl/cont rolfile/current.256.7968577397. db내렸다 올린다 -> 여기까지 다중화를 해놓지 않는거!! 한개만 유지함
SYS> shutdown immediate SYS> startup SYS> select * from v$controlfile; SYS> show parameter control_files; ------------------------------------------- SYS @ orcl > select * from v$controlfile; STATUS NAME IS_ BLOCK_SIZE FILE_SIZE_BLKS ------- ---------------------------------------- --- ---------- -------------- +DATA/orcl/controlfile/current.260.79685 NO 16384 600 7737 SYS @ orcl > show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.796857737✔️ 아까 주소 두개였는데 하나
+FRA/orcl/controlfile/current.256.796857739를 지워주어야 한다.
8. ASM 커멘드로 접속해서 +FRA 쪽의 CONTROL FILE 지우기[orcl:~]$ . oraenv ORACLE_SID = [orcl] ? +ASM The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/grid is /u01/app/oracle [+ASM:~]$ asmcmd ASMCMD> pwd + ASMCMD> cd +fra ASMCMD> pwd +fra ASMCMD> cd orcl ASMCMD> pwd +fra/orcl ASMCMD> cd controlfile ASMCMD> pwd +fra/orcl/controlfile ASMCMD> ls Current.256.796857739 ASMCMD> rm Current.256.796857739 ASMCMD> rm Current.256.796857739 ASMCMD-08002: entry 'controlfile' does not exist in directory '+fra/orcl/' ASMCMD> pwd +fra/orcl/controlfile ASMCMD> ls ASMCMD-08002: entry 'controlfile' does not exist in directory '+fra/orcl/' ASMCMD> quit [+ASM:~]$ . oraenv ORACLE_SID = [+ASM] ? orcl The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle [orcl:~]$✅ 위 수행 이후에 sys 접속해서 디비 내렸다가 올렸다. 이상없음
실습2. ASM쪽 컨트롤파일 다중화 하기
<순서>
1. 현재 control file 위치 확인하기
2. shutdown immediate
3. startup nomount
4. rman 접속
5. 기존 +DATA쪽에 있는 control file을 +fra쪽으로 복원하기
6. asmcmd 커맨드 모드로 가서 resore된 control file이 잘 있는지 확인하기
7. control_files 파라미터 파일을 수정한다. (+data와 +fra 두군데 있다고 수정)
8. shutdown immediate
9. startup
10. 다중화 되었는지 확인
1. 현재 control file 위치 확인하기
SYS> show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.7968577372. shutdown immediate
3. startup nomount
4. rman 접속 (nomount상태에서 접속-> controlfile이 아직 필요하지 않음)SYS> exit; $ rman target / nocatalog5. 기존 +DATA쪽에 있는 control file을 +fra쪽으로 복원하기
rman> restore controlfile to '+FRA' from '+DATA/orcl/controlfile/current.260.796857737'6. asmcmd 커맨드 모드로 가서 resore된 control file이 잘 있는지 확인하기
[orcl:~]$ . oraenv ORACLE_SID = [orcl] ? +ASM The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/grid is /u01/app/oracle [+ASM:~]$ asmcmd ASMCMD> pwd + ASMCMD> cd fra ASMCMD> ls ORCL/ ASMCMD> cd orcl ASMCMD> ls BACKUPSET/ CONTROLFILE/ ONLINELOG/ ASMCMD> cd controlfile ASMCMD> ls current.256.1148659713 ASMCMD> pwd +fra/orcl/controlfile +fra/orcl/controlfile/current.256.11486597137. control_files 파라미터 파일을 수정한다. (+data와 +fra 두군데 있다고 수정)
ASMCMD> quit [+ASM:~]$ . oraenv ORACLE_SID = [+ASM] ? orcl The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle [orcl:~]$ sys SYS> show parameter control_files; SYS> alter system set control_files='+DATA/orcl/controlfile/current.260.796857737','+FRA/orcl/controlfile/current.256.1148659713' scope=spfile;8. shutdown immediate
SYS @ orcl > shutdown immediate ORA-01507: database not mounted ORACLE instance shut down.9. startup
10. 다중화 되었는지 확인SYS @ orcl > show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.796857737, +FRA/orcl/cont rolfile/current.256.1148659713
p.14-22 리두 로그 파일
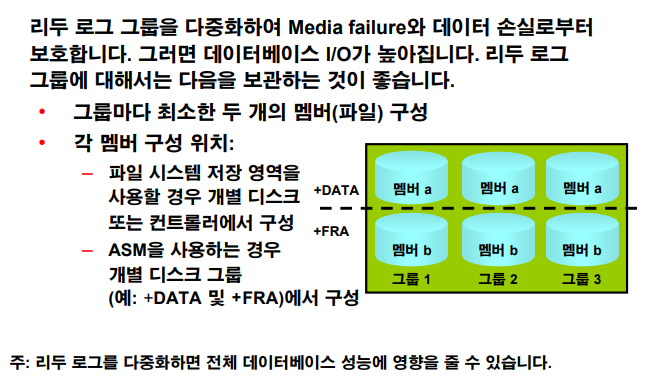
ASM쪽 리두 로그 파일 다중화하기
💡 기존애들은 그냥 두고, 그룹 하나 추가해서 멤버 2개 만들것임
📖 순서!
1. 리두 로그 그룹 상태를 확인합니다.
2. 6번 리두 로그 그룹을 추가하는데 멤버를 하나를 추가합니다.
3. 6번 리두 로그 그룹에 멤버를 하나 더 추가해서 다중화 시킵니다.
실습
- 리두 로그 그룹 상태를 확인합니다.
SYS> select group#, members from v$log; SYS> save log.sql GROUP# MEMBERS ---------- ---------- 1 2 2 2 3 2 4 2 5 2 SYS> select group#, member from v$logfile; SYS> save logfile.sql
- 6번 리두 로그 그룹을 추가하는데 멤버를 하나를 추가합니다.
SYS> alter database add logfile group 6 '+data' size 10m; SYS @ orcl > @log2.sql GROUP# MEMBERS ---------- ---------- 1 2 2 2 3 2 4 2 5 2 6 1 -- 6번 그룹에 멤버 하나만 추가되었다.
- 6번 리두 로그 그룹에 멤버를 하나 더 추가해서 다중화 시킵니다.
SYS> alter database add logfile member '+fra' to group 6; SYS @ orcl > @log2.sql GROUP# MEMBERS ---------- ---------- 1 2 2 2 3 2 4 2 5 2 6 2 SYS @ orcl > @logfile.sql GROUP# MEMBER ---------- --------------------------------------------- 1 +FRA/orcl/onlinelog/group_1.257.796857749 1 +DATA/orcl/onlinelog/group_1.261.796857743 2 +DATA/orcl/onlinelog/group_2.262.796857753 2 +FRA/orcl/onlinelog/group_2.258.796857757 3 +FRA/orcl/onlinelog/group_3.259.796857763 3 +DATA/orcl/onlinelog/group_3.263.796857759 4 +DATA/orcl/onlinelog/group_4.271.1146924991 4 +FRA/orcl/onlinelog/group_4.264.1146924997 5 +DATA/orcl/onlinelog/group_5.272.1146925419 5 +FRA/orcl/onlinelog/group_5.265.1146925423 6 +DATA/orcl/onlinelog/group_6.275.1148660837 GROUP# MEMBER ---------- --------------------------------------------- 6 +FRA/orcl/onlinelog/group_6.330.1148660945
컨트롤 파일 3개로 다중화
컨트롤 파일이 2개인데 3개로 다중화 합니다. 3번째 컨트롤 파일은 asm쪽이 아닌 /home/oracle/control03.ctl로 다중화 되게 하시오 !
📖 순서
0. dba.sh로 컨트롤 파일 생성 스크립트 생성하고 시작하기!
1. 현재 control file 위치 확인하기
2. shutdown immediate
3. startup nomount
4. rman 접속
5. 기존 +DATA쪽에 있는 control file을 /home/oracle/control03.ctl 로 복원하기
6. /home/oracle로 가서 restore된 control file이 잘 있는지 확인하기
7. control_files 파라미터 파일을 수정한다. (+data, +fra, /home/oracle/control03.ctl)
8. shutdown immediate
9. startup
10. 다중화 되었는지 확인
📖 실습
0. dba.sh로 컨트롤 파일 생성 스크립트 생성하고 시작하기!
1. 현재 control file 위치 확인하기SYS @ orcl > show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.796857737, +FRA/orcl/cont rolfile/current.256.1148659713 '+DATA/orcl/controlfile/current.260.796857737' '+FRA/orcl/controlfile/current.256.1148659713'2. shutdown immediate
3. startup nomount
4. rman 접속[orcl:~]$ rman target / nocatalog Recovery Manager: Release 11.2.0.1.0 - Production on Wed Sep 27 16:54:27 2023 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. connected to target database: ORCL (not mounted) using target database control file instead of recovery catalog5. 기존 +DATA쪽에 있는 control file을 /home/oracle/control03.ctl 로 복원하기
RMAN> restore controlfile to '/home/oracle/control03.ctl' from '+DATA/orcl/controlfile/current.260.796857737'; Starting restore at 27-SEP-23 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=14 device type=DISK channel ORA_DISK_1: copied control file copy Finished restore at 27-SEP-236. /home/oracle 로 가서 restore 된 control file 이 잘 있는지 확인
[orcl:~]$ pwd /home/oracle [orcl:~]$ ls -rlt -rw-r----- 1 oracle dba 9846784 9월 27 17:08 control03.ctl7. control_files 파라미터 파일을 수정합니다. ( +data, +fra, /home/oracle/control03.ctl )
SYS> alter system set control_files='+DATA/orcl/controlfile/current.260.796857737','+FRA/orcl/controlfile/current.256.1148659713','/home/oracle/control03.ctl' scope=spfile;8. shutdown immediate
9. startup
10. 다중화 되었는지 확인 ->/home/oracle/control03.ctl추가 잘 됨!SYS @ orcl > show parameter control_files; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string +DATA/orcl/controlfile/current .260.796857737, +FRA/orcl/cont rolfile/current.256.1148659713 , /home/oracle/control03.ctl
