
복습 17장. 데이터 이행 방법 3가지
데이터 이행 3가지
✔️ 서브쿼리를 사용한 insert인 Direct load insert (direct=y)
✔️ SQL * Loader를 사용한 direct path insert (direct=y)
✔️ export/import1. table level 2. schema level 3. tablespace level 4. database level💡 가장 빠른 데이터 이행 순위
1. 오라클 골든 게이트(유료)
2. 테이블 스페이스 레벨의 데이터 이행(빠르고 전부 옮겨진다.)
3. 스키마 레벨
- 어설픈 이행 : as-is에서 SH계정의 데이터를 export하고 to-be에서 SH계정의 데이터를 import
: 위 방법은 데이터가 작은 회사는 좋은방법이지만 KT나 텔레콤, 대기업 DB에서는 이렇게 작업하면 시간이 너무 오래걸리고 제일 중요한 것은 UNDO가 full나고 TEMP도 full이 납니다.
- 효율적 이행 :
1. as - is DB 에서 테이블 생성 스크립트만 뽑아내서 to- be DB에 빌드한다. 2. 데이터 덤프를 뽑아내서 import 한다. 3. 인덱스 생성 스크립트를 뽑아내서 to - be DB에 병렬도를 지정해서 인덱스를 생성한다. 4. 제약 생성 스크립트를 뽑아내서 to - be DB에 제약을 생성 5. 시너님, 프로시저, 함수 생성 스크립트 뽑아내서 to - be DB에 생성 6. as - is와 to - be 간의 테이블 갯수와 데이터 건수, 인덱스 건수, 시너님, 프로시저, 함수의 갯수, 권한이 일치하는지 확인✅ 위 효율적 이행 하기 전에 테이블 스페이스 레벨 이행으로 진행해도 괜찮은지 물어보고 된다고 하면 테이블스페이스 레벨이 더 편하다. 이행 후에 변경해도 된다고 해도 테이블스페이스 레벨로 하고 굳이 스키마 레벨로 해달라고 하면, 회사가 작다면 기본 export, import 해도 되지만 회사가 크다면 아래 방법으로 하자.
데이터 이행 미니테스트
orcl2 ------------------> orcl3 emp --------------------> emp 인덱스1. (orcl2) demp 스크립트로 emp와 dept를 초기화 합니다.
SCOTT @ orcl2 > @demo2. (orcl2) emp테이블에 결합 컬럼 인덱스 등 여러 인덱스를 생성합니다.
SCOTT @ orcl2 > create index emp_index1 on emp(empno,ename,sal); SCOTT @ orcl2 > create index emp_index2 on emp(ename); SCOTT @ orcl2 > create index emp_index3 on emp(ename,job);3. (orcl2) sqldeveloper 로 emp테이블의 생성 스크립트와 인덱스 스크립트를 추출합니다.
4. (orcl2) emp테이블을 export 합니다.[orcl2:~]$ exp scott/tiger tables=emp file=emp.dmp Export terminated successfully with warnings.5. (orcl3) scott_dev라는 계정을 생성합니다.
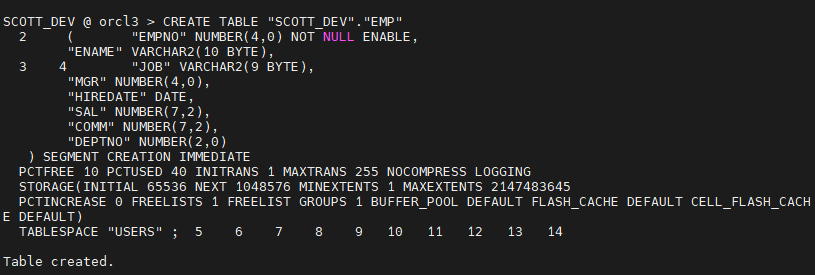
SYS @ orcl3 > create user scott_dev identified by tiger; SYS @ orcl3 > grant resource , connect to scott_dev;6. (orcl3) scott_dev에서 위 3번에서 생성한 테이블 생성 스크립트를 생성합니다.
7. (orcl3) 4번에서 생성한 덤프파일을 임포트 합니다.
$ imp scott_dev/tiger file=emp.dmp tables=emp ignore=y indexes=no . . importing table "EMP" 14 rows imported Import terminated successfully without warnings. SCOTT_DEV @ orcl3> select count(*) from emp;8. (orcl3) 3번에서 생성한 인덱스 생성 스크립트를 병렬도를 지정해서 돌립니다.
parallel 4쓰기SCOTT_DEV @ orcl3> CREATE INDEX "SCOTT_DEV"."EMP_INDEX1" ON "SCOTT_DEV"."EMP" ("EMPNO", "ENAME", "SAL") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."EMP_INDEX2" ON "SCOTT_DEV"."EMP" ("ENAME") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."EMP_INDEX3" ON "SCOTT_DEV"."EMP" ("ENAME", "JOB") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4;
✅ 위 스크립트는 orcl2에서 뽑아낸 스크립트라서scott_dev라고 이름 바꾸었다.테이블스페이스가 users로 되어있는데 이 ts가 orcl3에도 있어야 생성이 된다.9. (orcl3) index의 병렬도를 1로 변경해줍니다.
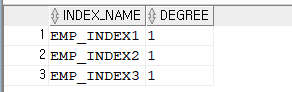
alter index emp_index1 parallel 1; alter index emp_index2 parallel 1; alter index emp_index3 parallel 1;✅ 병렬도를 지정해서 인덱스를 생성한 이유는 인덱스를 빠르게 생성하려고 이다. 병렬도를 다시 1로 변경해주어야 하는데 그렇지 않으면
옵티마이저가 full table scan 보다는 무조건 인덱스 스캔을하려고 하는 실행계획이 나온다.-- 잘 바뀌었는지 확인하는 방법 select index_name, degree from user_indexes;
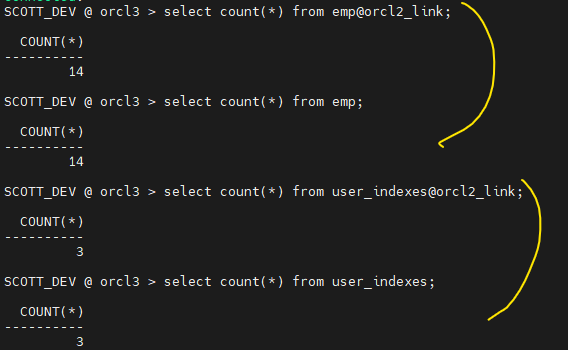
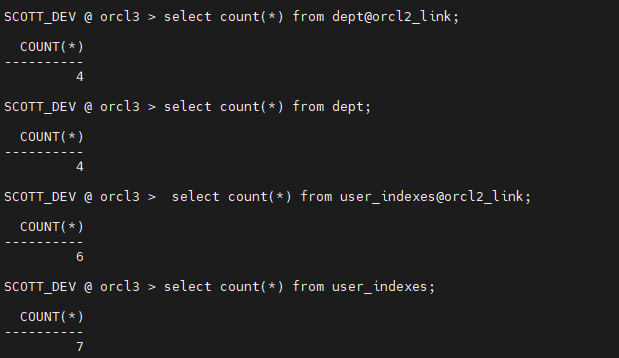
10. 양쪽의 데이터와 인덱스의 갯수가 같은지 확인합니다. (db link 만들기)
orcl3 $ lsnrclt status--리스너 상태 확인 SYS @ orcl3> grant create database link to scott_dev; SCOTT_DEV @ orcl3 > create database link orcl2_link connect to scott identified by tiger using 'edydr1p0.us.oracle.com:1521/orcl2'; SCOTT_DEV @ orcl3 > select count(*) from emp@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from emp; SCOTT_DEV @ orcl3 > select count(*) from user_indexes@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from user_indexes;

문제 dept 테이블로 위 작업 수행하기!
1. (orcl2) demo 스크립트로 emp와 dept를 초기화 합니다.
SCOTT @ orcl2 > @demo2. (orcl2) dept테이블에 결합 컬럼 인덱스 등 여러 인덱스를 생성합니다.
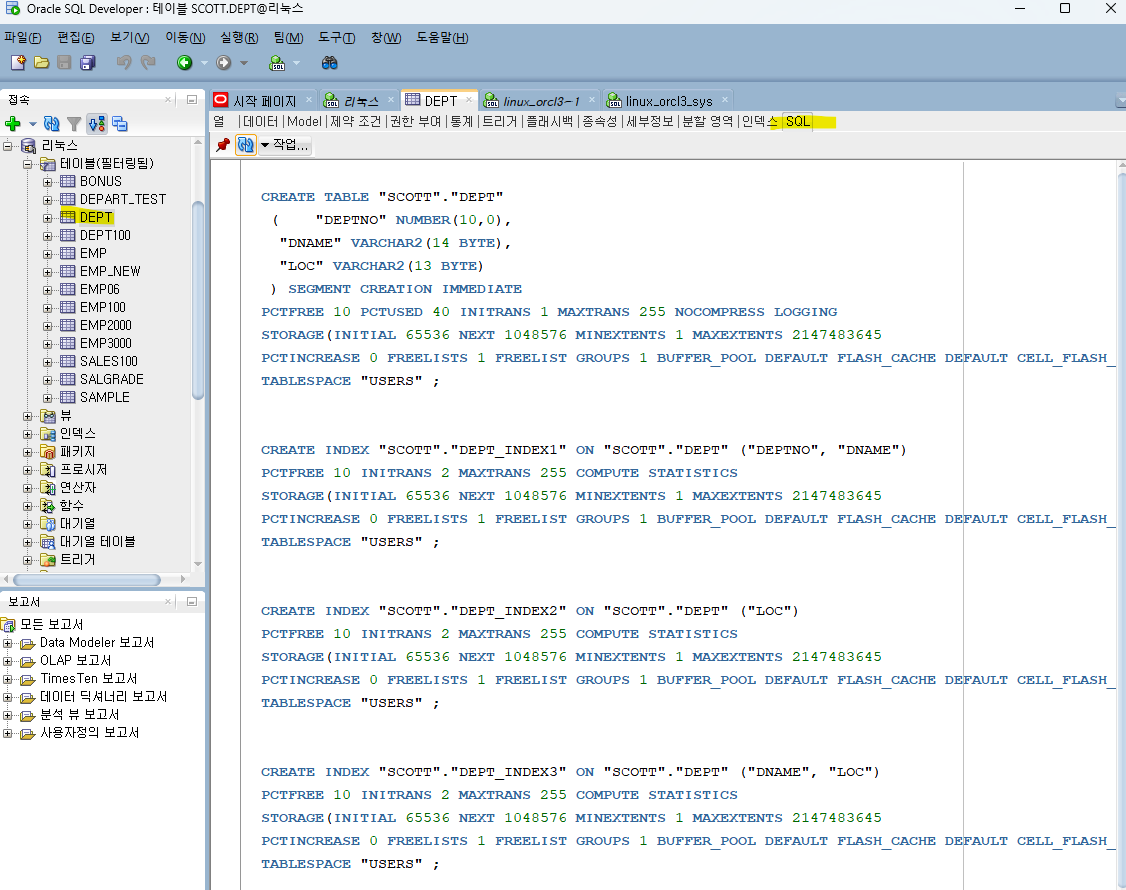
SCOTT @ orcl2 > create index dept_index1 on dept(deptno,dname); SCOTT @ orcl2 > create index dept_index2 on dept(loc); SCOTT @ orcl2 > create index dept_index3 on dept(dname,loc);3. (orcl2) sqldeveloper 로 dept테이블의 생성 스크립트와 인덱스 스크립트를 추출합니다.
4. (orcl2) dept테이블을 export 합니다.[orcl2:~]$ exp scott/tiger tables=dept file=dept.dmp5. (orcl3) scott_dev라는 계정을 생성합니다.
SYS @ orcl3 > create user scott_dev identified by tiger; SYS @ orcl3 > grant resource , connect to scott_dev;6. (orcl3) scott_dev에서 위 3번에서 생성한 테이블 생성 스크립트를 생성합니다.
: 3번에서 추출한거 돌림! scott -> scott_dev라고 변경해야하고, table space가 orcl3에도 있는지 확인해야 한다.
7. (orcl3) 4번에서 생성한 덤프파일을 임포트 합니다.$ imp scott_dev/tiger file=dept.dmp tables=dept ignore=y indexes=no SCOTT_DEV @ orcl3> select count(*) from dept;8. (orcl3) 3번에서 생성한 인덱스 생성 스크립트를 병렬도를 지정해서 돌립니다.
parallel 4쓰기CREATE INDEX "SCOTT_DEV"."DEPT_INDEX1" ON "SCOTT_DEV"."DEPT" ("DEPTNO", "DNAME") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."DEPT_INDEX2" ON "SCOTT_DEV"."DEPT" ("LOC") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4; CREATE INDEX "SCOTT_DEV"."DEPT_INDEX3" ON "SCOTT_DEV"."DEPT" ("DNAME", "LOC") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" parallel 4;
✅ 위 스크립트는 orcl2에서 뽑아낸 스크립트라서scott_dev라고 이름 바꾸었다.테이블스페이스가 users로 되어있는데 이 ts가 orcl3에도 있어야 생성이 된다.9. (orcl3) index의 병렬도를 1로 변경해줍니다.
alter index dept_index1 parallel 1; alter index dept_index2 parallel 1; alter index dept_index3 parallel 1;✅ 병렬도를 지정해서 인덱스를 생성한 이유는 인덱스를 빠르게 생성하려고 이다. 병렬도를 다시 1로 변경해주어야 하는데 그렇지 않으면
옵티마이저가 full table scan 보다는 무조건 인덱스 스캔을하려고 하는 실행계획이 나온다.-- 잘 바뀌었는지 확인하는 방법 select index_name, degree from user_indexes;10. 양쪽의 데이터와 인덱스의 갯수가 같은지 확인합니다. (db link 만들기)
orcl3 $ lsnrclt status--리스너 상태 확인 SYS @ orcl3> grant create database link to scott_dev;--진행했음 SCOTT_DEV @ orcl3 > create database link orcl2_link connect to scott identified by tiger using 'edydr1p0.us.oracle.com:1521/orcl2'; SCOTT_DEV @ orcl3 > select count(*) from dept@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from dept; SCOTT_DEV @ orcl3 > select count(*) from user_indexes@orcl2_link; SCOTT_DEV @ orcl3 > select count(*) from user_indexes;
⭐ 스스로 해볼 것
1. pump로 위 작업 수행
2. scott이 가지고 있는 모든 테이블에 대해 전부 orcl3 scott_dev에 이행
외부 테이블 external table (p.17-31)
💡 os의 텍스트 파일이나 csv파일을 database로 입력하려면 SQL*Loader를 이용해서 입력해야 합니다. 그런데 만약 입력해야할 데이터가 대용량 데이터라고 하면 그 데이터를 데이터베이스에 입력하기 위해서 테이블 스페이스 공간도 넉넉해야하고, 입력할 때 undo와 temp가 full나지 않는지도 걱정하며 모니터링 해야한다.
요번 한달만 열심히 select 할 테이블이고 다음달에는 select할 가능성이 적은 테이블인데 아주 큰 빅데이터면 외부 테이블로 생성하는게 바람직합니다.
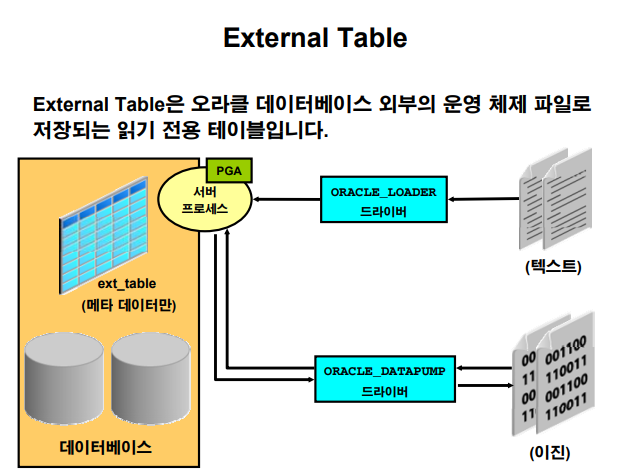
external table이 사용하는 엔진 2가지
SQL*Loaderpump
SQL*Loader를 엔진으로 하는 외부테이블 생성하기
SQL*Loader를 엔진으로 하는external table 실습
1. emp1.txt 편집(/home/oracle/emp1.txt)[orcl2:~]$ vi emp1.txt SMITH,101,2001/03/15 JOHN,102,2002/04/152. Directory 생성 (external용 디렉토리)
SYS @ orcl2> grant create any directory to scott; SYS @ orcl2> connect scott/tiger SCOTT @ orcl2> create directory emp_dir as '/home/oracle/';✅ 디렉토리 만들 때 뒤에
/꼭 만들기
3. External table 생성SCOTT @ orcl2> create table ext_emp (emp_id number(3), emp_name varchar2(10), hiredate date) organization external --필수문법 (type oracle_loader default directory emp_dir --위에서 만든 디렉토리 access parameters (records delimited by newline --행과행은 엔터로 구분하겠다. fields terminated by "," --컬럼과 컬럼은 콤마로 구분하겠다. (emp_name char, --varchar2가 아니라 char로 emp_id char, hiredate date "yyyy/mm/dd") ) location ('emp1.txt') ); --이게 emp_dir 디렉토리 안에 있어야한다.✅ type은 oracle_loader 혹은 oracle_pump
4. Select & DML 테스트SCOTT @ orcl2 > select * from ext_emp; EMP_ID EMP_NAME HIREDATE ---------- ---------- ------------------- 101 SMITH 2001/03/15:00:00:00 102 JOHN 2002/04/15:00:00:00 SCOTT @ orcl2 > update ext_emp 2 set emp_name=null; update ext_emp * ERROR at line 1: ORA-30657: operation not supported on external organized table⭐ 외부 테이블에 대해서는 DML작업이 되지 않는다. 그렇지만 제일 중요한
조인을 할 수 있다!국민은행 ------------- 우리은행 * 이렇게 이체 내역을 조회한다고 가정하에 이것을 수정할 일은 없다. 그렇지만 조인해서 볼 일은 있다.SCOTT @ orcl2> select e.ename, e2.emp_name from emp e, ext_emp e2 where e.ename=e2.emp_name; ENAME EMP_NAME ---------- ---------- SMITH SMITH⭐ index 생성 가능
점심시간 문제 dept.txt를 가지고 ext_dept 외부 테이블을 생성하시오
1. 1. dept.txt 편집(/home/oracle/dept.txt)
$ vi dept.txt 10,ACCOUNTING,NEW YORK 20,RESEARCH,DALLAS 30,SALES,CHICAGO 40,OPERATIONS,BOSTON2. Directory 생성
SCOTT @ orcl2> create directory emp_dir as '/home/oracle/';3. External table 생성
SCOTT @ orcl2> create table ext_dept (deptno number(10), dname varchar2(20), loc varchar2(20)) organization external (type oracle_loader default directory emp_dir access parameters (records delimited by newline fields terminated by "," (deptno char, dname char, loc char) ) location ('dept.txt') );4. select 해보기
SCOTT @ orcl2 > select * from ext_dept; DEPTNO DNAME LOC ---------- -------------------- -------------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON
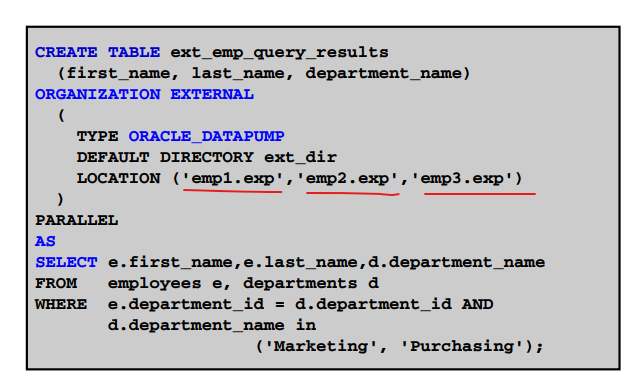
Data pump 엔진을 이용해서 외부테이블 생성하기(p.17-34)
SQL*Loader를 엔진으로 하는external table 실습
1. emp, dept테이블을 조인한 결과로 외부 테이블을 생성하기 (엔진을 data pump로 이용)create table ext_emp_dept (ename,sal,loc) organization external ( type oracle_datapump default directory emp_dir location ('empdept.dmp') ) as select e.ename, e.sal, d.loc from emp e, dept d where e.deptno = d.deptno;2. select 해보기
SCOTT @ orcl2 > select * from ext_emp_dept; ENAME SAL LOC ---------- ---------- ------------- KING 5000 NEW YORK BLAKE 2850 CHICAGO CLARK 2450 NEW YORK JONES 2975 DALLAS MARTIN 1250 CHICAGO ALLEN 1600 CHICAGO TURNER 1500 CHICAGO JAMES 950 CHICAGO WARD 1250 CHICAGO FORD 3000 DALLAS SMITH 800 DALLAS SCOTT 3000 DALLAS ADAMS 1100 DALLAS MILLER 1300 NEW YORK [orcl2:~]$ ls -l empdept.dmp -rw-r----- 1 oracle dba 12288 10월 11 13:51 empdept.dmp
문제 emp, dept, salgrade를 조인해서 이름, 월급, 부서위치, 등급(grade)를 출력하는 external 테이블을 ext_e_grade로 생성하시오!
1. 외부 테이블을 생성하기 (엔진을 data pump로 이용)
create table ext_e_grade (ename,sal,loc,grade) organization external ( type oracle_datapump default directory emp_dir location ('empdeptsal.dmp') ) as select e.ename, e.sal, d.loc, s.grade from emp e, dept d, salgrade s where e.deptno = d.deptno and e.sal between s.losal and s.hisal ;2. select 해보기
SCOTT @ orcl2 > select * from ext_e_grade; ENAME SAL LOC GRADE ---------- ---------- ------------- ---------- SMITH 800 DALLAS 1 JAMES 950 CHICAGO 1 ADAMS 1100 DALLAS 1 WARD 1250 CHICAGO 2 MARTIN 1250 CHICAGO 2 MILLER 1300 NEW YORK 2 TURNER 1500 CHICAGO 3 ALLEN 1600 CHICAGO 3 CLARK 2450 NEW YORK 4 BLAKE 2850 CHICAGO 4 JONES 2975 DALLAS 4 FORD 3000 DALLAS 4 SCOTT 3000 DALLAS 4 KING 5000 NEW YORK 5 [orcl2:~]$ ls -l empdeptsal.dmp -rw-r----- 1 oracle dba 12288 10월 11 13:58 empdeptsal.dmp✅ 좋은점은, 위에서 만든 pump파일을 다른 db로 가지고갈 수 있다. 이진(바이너리) 파일이라서 열어도 보이지 않는다!
국민은행 ---------------> 우리은행 이체내역을 csv 말고 pump 파일로 넘겨주면 보안상 아주 유용하다.
실습 orcl2의 empdeptsal.dmp파일을 이용해서 orcl3 에서 외부 테이블을 생성하기
orcl2 ------------------------------------> orcl3
(국민은행) (우리은행)
scott scott
emp_dir emp_dir
/home/oracle /home/oracle
empdeptsal.dmp select * from ext_e_grade;1. orcl3 sys에서 스캇에게 디렉토리 만들 수 있는 권한주기
SYS @ orcl3> grant create any directory to scott;2. scott유저에서 디렉토리 생성
SCOTT @ orcl3> create directory emp_dir as '/home/oracle/';3.scott에서 empdeptgrade.dmp 열기
SCOTT @ orcl3 > CREATE TABLE ext_e_grade ( ename CHAR(50), sal NUMBER, loc CHAR(50), grade NUMBER ) ORGANIZATION EXTERNAL ( TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY emp_dir LOCATION ('empdeptsal.dmp') );
문제 orcl2에서 아래의 sql 결과로 data pump 엔진으로 외부 테이블을 생성하고 orcl3 에서 해당 덤프로 외부 테이블을 생성하시오
✔️ DALLAS 에서 근무하는 사원들의 이름, 월급, 부서위치를 출력하는 쿼리 !
ext_dallas ext_dallas
orcl2 ------------------------------------> orcl3
(국민은행) (우리은행)
scott scott
emp_dir emp_dir
/home/oracle /home/oracle
empdeptsal.dmp select * from ext_e_grade;1. orcl2에서
ext_dallas외부 테이블을 생성, 조회해보기SCOTT @ orcl2> create table ext_dallas (ename,sal,loc) organization external ( type oracle_datapump default directory emp_dir location ('dallas.dmp') ) as select e.ename, e.sal, d.loc from emp e, dept d where e.deptno = d.deptno and d.loc='DALLAS'; SCOTT @ orcl2> select * from ext_dallas;2. orcl3 scott에서 dallas.dmp로 외부테이블 생성하기
SCOTT @ orcl3 > CREATE TABLE ext_dallas ( ename CHAR(50), sal NUMBER, loc CHAR(50) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY emp_dir LOCATION ('dallas.dmp') ); SCOTT @ orcl3 > select * from ext_dallas; ENAME SAL LOC --------------------- -------- --------------------- JONES 2975 DALLAS FORD 3000 DALLAS SMITH 800 DALLAS SCOTT 3000 DALLAS ADAMS 1100 DALLAS
어떤 외부 테이블이 있는지 조회하기
SQL> select * from user_external_tables; ➡️ workshop2 교재로 넘어갔음! 1장은 workshop 1 복습
2장. Recovery 가능성을 고려한 구성
RMAN 명령의 유형
RMAN 명령은 다음 유형 중 하나입니다.
독립형 명령:
- RMAN 프롬프트에서 개별적으로 실행됩니다.
- RUN 내에 하위 명령으로 나타날 수 없습니다.
작업형 명령:
- RUN 명령의 중괄호 내에 있어야 합니다.
- 그룹으로 실행됩니다.
➡️ 일부 명령은 독립형 또는 작업형 명령으로 실행될 수 있습니다.
✔️ 독립형 명령
예) RMAN> backup datafile 4;✔️ 작업형 명령
예) RMAN> run {
backup datafile 1;
backup datafile 2;
}✅ 작업형 명령의 장점 : 독립형과는 다르게 백업과 복구 스크립트를 생성해서 작업을 할 수 있으므로 장애시 빠르게 복구를 수행할 수 있게 된다.
실습 작업형으로 datafile 1번과 3번과 4번을 백업하시오(아카이브 모드에서만 되어서 orcl2에서 진행했다.)
$ rman target / nocatalog RMAN> run { backup datafile 1; backup datafile 3; backup datafile 4; }
문제 orcl2의 datafile 번호가 총 몇개 있는지 확인하고 전부 알맨으로 작업형으로 백업하세요
SYS> select file# from v$datafile_header;
FILE#
----------
1
2
3
4
5
6
7
8
9
9 rows selected.
$ rman target / nocatalog
RMAN> run { backup datafile 1;
backup datafile 2;
backup datafile 3;
backup datafile 4;
backup datafile 5;
backup datafile 6;
backup datafile 7;
backup datafile 8;
backup datafile 9;
} 작업형으로 데이터 파일 복구하기
-- 1. tablespace 생성 및 테이블 생성
$ cd ~ $ mkdir ysh SYS> create tablespace ts01 datafile '/home/oracle/ysh/ts01.dbf' size 20m; SYS> conn scott/tiger SCOTT> create table emp01 tablespace ts01 as select * from emp; SCOTT> select count(*) from emp01; COUNT(*) ---------- 14-- 2. DB 내리기 (shutdown)
SYS> shutdown abort-- 3. rm 으로 datafile 삭제
SYS> !rm /home/oracle/ysh/ts01.dbf✅ 느낌표를 쓰면 sql prompt 창에서 리눅스 명령어를 수행할 수 있다.
-- 4. DB 시작해서 오류 확인SYS> startup ORACLE instance started. Total System Global Area 418484224 bytes Fixed Size 1336932 bytes Variable Size 293603740 bytes Database Buffers 117440512 bytes Redo Buffers 6103040 bytes Database mounted. ORA-01157: cannot identify/lock data file 10 - see DBWR trace file ORA-01110: data file 10: '/home/oracle/ysh/ts01.dbf' SYS> select file# , error from v$recover_file; FILE# ERROR ---------- ----------------------------------------------------------------- 1 UNKNOWN ERROR 2 UNKNOWN ERROR 3 UNKNOWN ERROR 4 UNKNOWN ERROR 5 UNKNOWN ERROR 10 FILE NOT FOUND-- 5. RMAN 에서 작업형으로 복구 스크립트 작성 (DB 를 올려놓고 작업하기)
$ rman target / nocatalog RMAN> run { sql "alter database datafile 10 offline"; sql "alter database open"; restore datafile 10; recover datafile 10; sql "alter database datafile 10 online"; }-- 6. 복구 확인
SYS> select count(*) from scott.emp01; COUNT(*) ---------- 14-- 7. full backup 수행
RMAN> exit $ rman target / nocatalog RMAN> backup database;
문제 이번에 위 2번부터 다시하는데 알맨 들어가서 작업형이 아닌 독립형으로 수행해서 복구하기
[orcl2:~]$ rman target / nocatalog
RMAN> sql "alter database datafile 8 offline";
RMAN> sql "alter database open";
RMAN> restore datafile 8;
RMAN> recover datafile 8;
RMAN> sql "alter database datafile 8 online";
sql statement: alter database datafile 8 online아카이브 로그 파일이 생성되는 위치 결정 (p.2-16)
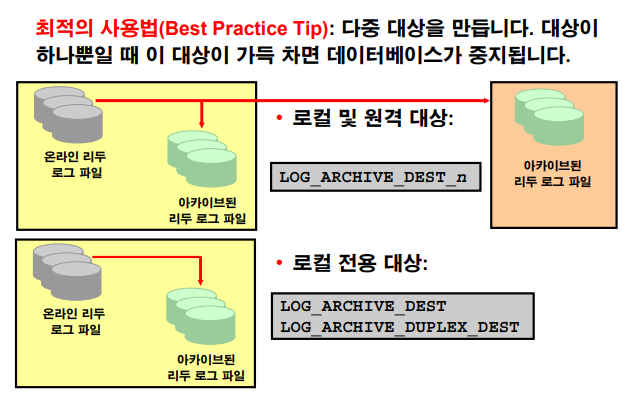
아카이브 로그 파일이 생성되는 위치를 결정하는 파라미터
SYS> show parameter log_archive_dest;
NAME TYPE VALUE
------------------------------------ ----------- --------------------------
log_archive_dest string
log_archive_dest_1 string
SQL> show parameter recovery
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_recovery_file_dest string /u01/app/oracle/flash_recovery
_area
db_recovery_file_dest_size big integer 10G
recovery_parallelism integer 0➡️ 위의 파라미터를 지정을 하지 않으면 fast recovery area 영역에 생성됨
만약, 아카이브 로그 파일을 여러군데 생성되게 하고 싶으면 위의 파라미터를 설정한다.
❓ 로컬 서버에 2군데 아카이브 로그 파일이 생성되게 하고 싶다면 ?
log_archive_dest= 첫번째 위치
log_archive_duplex_dest= 두번째 위치
log_archive_min_succeed_dest= 21 : 두군데 중에 한군데만 아카이빙 성공 되어도 다음 작업으로 진행되게 할 수 있다. 2 : 위의 두군데 다 아카이빙이 성공됭어야 에러 안나고 다음 작업으로 진행이 될 수 있다.❓ 원격지 서버에 아카이브 로그파일이 생성되게 하고 싶다면 ? -> 데이터 가드 수업때
log_archive_dest_1= 로컬 시스템의 위치
log_archive_dest_2= 원격 시스템의 위치
실습 두군데에 아카이브 로그 파일 생성 시키기
1. 디렉토리를 2군데 만듭니다
$ cd $ mkdir orcl2_arch $ mkdir orcl2_arch22. 아카이브 로그 파일이 두군데 생성되어질 수 있도록 설정합니다.
SYS> alter system set DB_RECOVERY_FILE_DEST=''; startup force alter system set log_archive_dest='/home/oracle/orcl2_arch/'; alter system set log_archive_duplex_dest='/home/oracle/orcl2_arch2/'; alter system set log_archive_min_succeed_dest = 2; alter system switch logfile; exit; [orcl2:~]$ cd orcl2_arch [orcl2:orcl2_arch]$ ls 1_52_1149499307.dbf 1_53_1149499307.dbf
문제 다시 fast recovery area 영역으로 아카이브 로그 파일이 생성되게 하기
✔️ 위치 : /u01/app/oracle/flash_recovery_area
SYS>
alter system set log_archive_min_succeed_dest = 1;
alter system set log_archive_duplex_dest='';
alter system set log_archive_dest='';
alter system set DB_RECOVERY_FILE_DEST='/u01/app/oracle/flash_recovery_area';알맨 백업 보존 정책(p.2-20)
💡 data file, controlfile이 깨지면 언제든 복구를 할 수 있어야 하고(완전복구),
db를 과거로 되돌리고 싶다면 30일 전으로 되돌리면 된다. (불완전 복구)
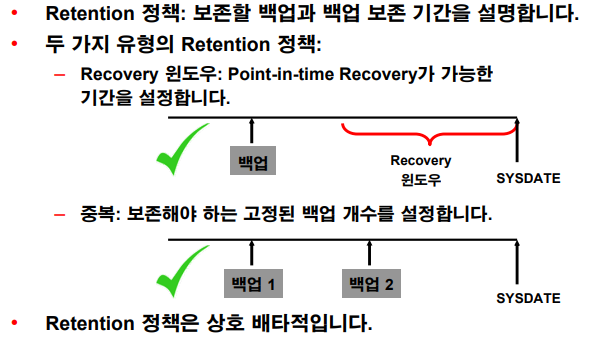
✅ 복구에 필요한 백업 파일만 유지하고 필요없는 파일들을 쉽게 지우기 위해서 백업본 보존 정책을 지정해야합니다. (30일??이런거)
✔️ 보존 정책 2가지
1.recovery window: 지정된 기간으로 복구할 수 있게 백업본을 유지
2.중복: 중복된 백업 파일을 몇개를 가지고 있을지 지정 (default)
실습 백업 보존 정책 확인하는 방법
1. 알맨으로 접속한다.
[orcl2:~]$ rman target /2. 지워도 되는 파일들을 보여달라고 한다.
RMAN> report obsolete; RMAN retention policy will be applied to the command RMAN retention policy is set to redundancy 1➡️
RMAN retention policy is set to redundancy 1은 똑같은 백업본을 하나 더 유지하겠다! (중복을 하나 더 허용하겠다.) 원본의 알맨 백업본이 2개까지 생성되고 3개부터는 지워도 되는 파일이 됩니다.
1. 보존 정책 (중복) 실습
RMAN> delete obsolete; RMAN> report obsolete; RMAN retention policy will be applied to the command RMAN retention policy is set to redundancy 1 no obsolete backups found
💡 1달 전으로 db를 되돌릴 가능성도 있다면 보존정책 두가지 중에 중복이 아닌 recovery window로 설정하면 된다.
2. 보존 정책 (recovery window) 실습
RMAN> configure retention policy to recovery window of 7 days; new RMAN configuration parameters: CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS; new RMAN configuration parameters are successfully stored RMAN> report obsolete; RMAN retention policy will be applied to the command RMAN retention policy is set to recovery window of 7 days no obsolete backups found
3. default 보존 정책 변경하기
문제 다시 recovery window가 아니라 중복 백업본을 1개만 유지하게끔 default 값으로 보존 정책을 돌려놓기

RMAN> configure retention policy to redundancy 1; RMAN> report obsolete; RMAN retention policy will be applied to the command RMAN retention policy is set to redundancy 1 no obsolete backups found
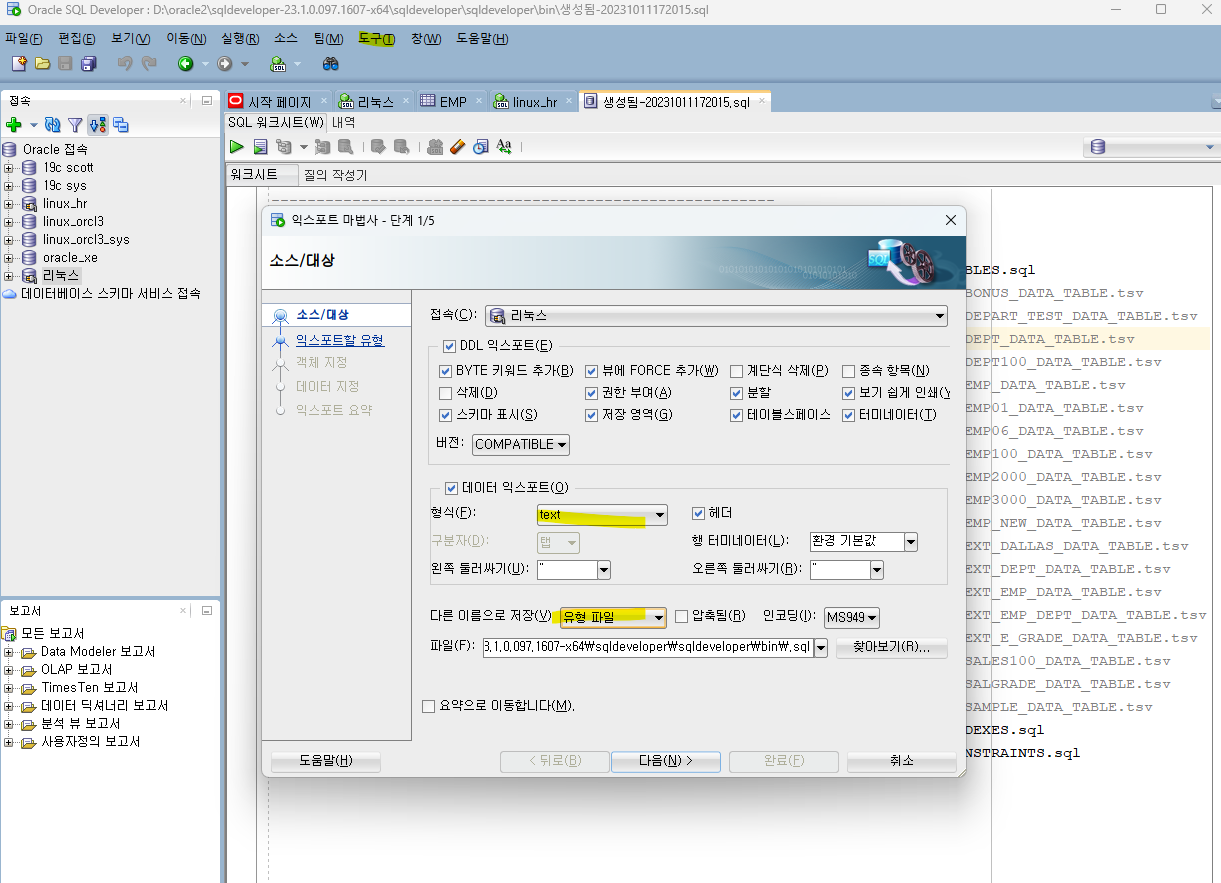
마지막 문제 orcl2의 hr 계정의 모든 테이블 생성 스크립트와 인덱스 생성 스크립트를 추출하기!
D:\oracle2\sqldeveloper-23.1.0.097.1607-x64\sqldeveloper\sqldeveloper\bin <- scott은 이 경로에 있음
- sqldeveloper > 도구 > 데이터베이스 익스포트 > 형식: text , 다른이름으로 저장: 유형파일

💡 바탕화면에 있는 확장자 .sql 파일들을 하나로 합치는 파이썬 코드
import os
# 특정 디렉토리 경로를 지정합니다.
directory_path = "C:\\Users\\ITWILL\\Desktop"
# 결과를 저장할 텍스트 파일을 열고 모든 내용을 저장할 변수를 초기화합니다.
output_file_path = "combined_sql_files.sql"
combined_sql_text = ""
# 디렉토리 내의 모든 .sql 파일을 찾아 합칩니다.
for filename in os.listdir(directory_path):
if filename.endswith(".sql"):
file_path = os.path.join(directory_path, filename)
with open(file_path, 'r', encoding='cp949') as file:
file_content = file.read()
combined_sql_text += file_content
# 하나의 텍스트 파일에 모든 내용을 저장합니다.
with open(output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(combined_sql_text)
print("SQL 파일 합치기 완료")