
📖 12장. 데이터 이행
개발 단계: db생성, db구성, 데이터 이행예전 서버 -> 새로운 서버 예전 버전 -> 새로운 버전
운영 단계: db운영(공간관리, 락관리, 악성 세션의 SQL튜닝, 오라클 문제들 해결), 데이터 이행운영 서버 -> 개발 서버 OTLP 서버 -> DW 서버개념!
data 이행 시 중요하게 다뤄야 할 점 2가지
- data 의 정합성
- data 이행 성능(속도)
data 이행 성능을 높이기 위해서는 어떻게 해야 하는가 ?
중요!
⭐ 1. table 구조 --> data 입력 --> 인덱스 생성(병렬처리) ⭐
: 이 순서가 굉장히 중요하다 !
2. buffer 옵션을 사용한다. 데이터 행들을 가져오는데 사용되는 작업단위의 크기를 설정
data 이행에 관련한 개념 및 툴 3가지
Direct load insertSQL * Loaderexport/import
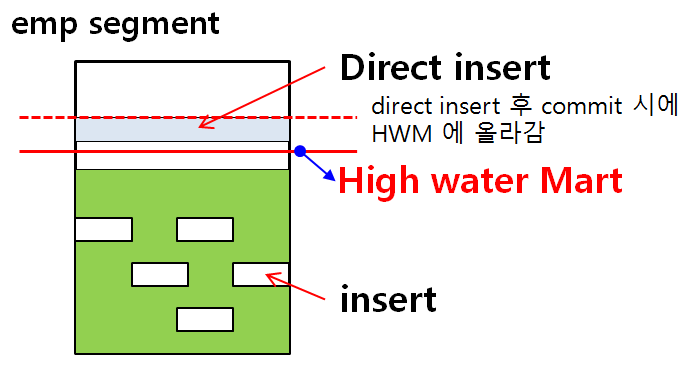
1. Direct load insert
DB
↓
tablespace
↓
segment (emp, dept...)
↓
extent
↓
block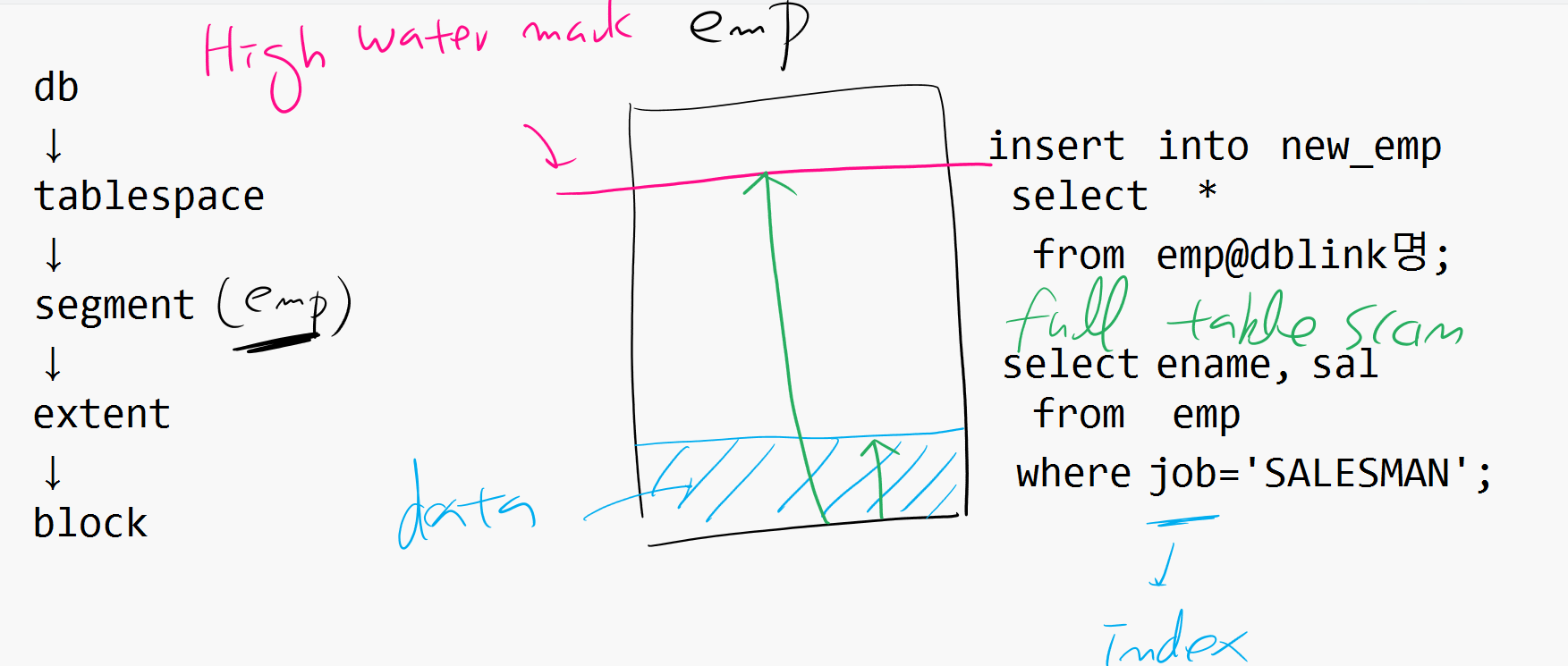
💡 Insert 할 때
insert into new_emp select * from emp@dblink명;✅ 위 경우 데이터가 아래에서 위로 차오른다. 그 때 마크가 하나 생기는데 이것이
High water mark이다. 마치 음료를 먹고 위에 있는 자국같은 것 ! 그래서 데이터를 지워도 하이워터마크는 내려오지 않는다. truncate로 지울 수 있고 delete나 다른것은 지울수가 없다.select ename, sal from emp where job='SLAESMAN';✅ 이 경우 job에 인덱스가 없어서 full table scan이 일어나는데, 이때 HWM까지 읽는다. HWM를 내려주는 작업이 디비 리워드 작업
⭐
정리: 테이블에 데이터를 입력하게 되면 데이터는 HWM아래에 입력이 됩니다. 그리고 해당 테이블을 풀테이블 스캔 하게 되면 HWM까지 스캔합니다. HWM가 높다면 full table sca 할 때 시간이 많이 걸립니다. 즉 성능이 떨어집니다!
💡 서브쿼리를 사용한 insert문
1. direct load insert가 아닌 방법의 SQL - 초급--scott계정 lock풀기 SYS @ orcl2 > alter user scott account unlock; User altered. SYS @ orcl2 > alter user scott identified by tiger; User altered. SCOTT> create table emp_new as select * from emp where 1=2; -- 구조 만들기 SCOTT> insert into emp_new select * from emp; -- 데이터 넣기 SCOTT> commit;
2. direct load insert 방법의 SQL - 상급!
힌트 사용delete from emp_new; commit; SCOTT> insert /*+ append */ into emp_new select * from emp; SCOTT> commit;
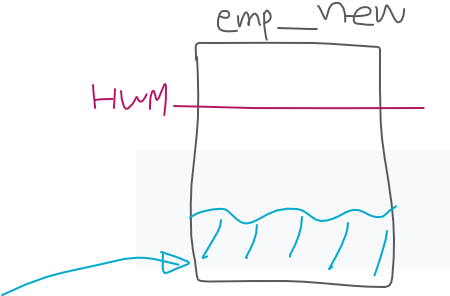
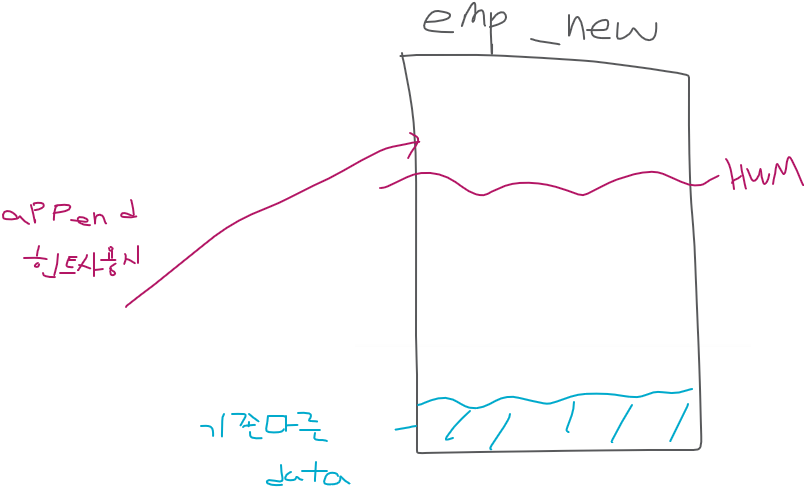
✅ High Water Mark 위쪽에 데이터를 입력합니다. HWM위에 입력하는것이 아래에 입력하는 것 보다 속도가 훨씬 빠릅니다! 이미지는 데이터가 예쁘게 있는 것 같지만 HWM 밑에는 구멍이 송송 뚤려있는 형태라서 구멍이 없는쪽을 찾아서 데이터를 넣기때문에 느리다.
❗ HWM위에 넣는것이 용량이 부족할 수는 있지만, 데이터 이행을 빠르게 하는것이 중요한 상황이라면 append를 사용하여 위에 넣는게 더 좋다.
direct load insert시 병렬로 데이터 이행하는 방법
💡좀 더 빠르게 데이터 이행을 하고자 하면, 병렬로 작업해야 합니다.
SCOTT> delete from emp_new;
SCOTT> insert /*+ parallel(emp_new, 4) */ into emp_new
select *
from emp;
-- 병렬도?!
/*+ parallel(emp_new, 4) */
↑ 병렬도 (cpu_count * 2만큼 줄 수 있다.)
SYS> show parameter cpu_count;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cpu_count integer 2
✅ parallel 힌트를 사용하면 4개의 프로세서가 나눠서 데이터를 이행한다. 원래는 1개가 했다. 더 빨라짐 !
✅ commit;을 해야 select가 되어야 하는게 맞는데 commit;을 하지 않았는데 select가 된다는 것은 HWM아래로 데이터가 들어갔다는 것입니다 -> 병렬처리 작업이 안되었다 !
❗ 병렬 쿼리 작업을 할 때는 병렬쿼리 작업이 가능하도록 활성화 작업을 해주어야 한다.
SCOTT @ orcl2 > alter session enable parallel dml; Session altered. SCOTT @ orcl2 > insert /*+ parallel(emp_new, 4) */ into emp_new select * from emp; SCOTT @ orcl2 > select * from emp_new; select * from emp_new * ERROR at line 1: ORA-12838: cannot read/modify an object after modifying it in parallel
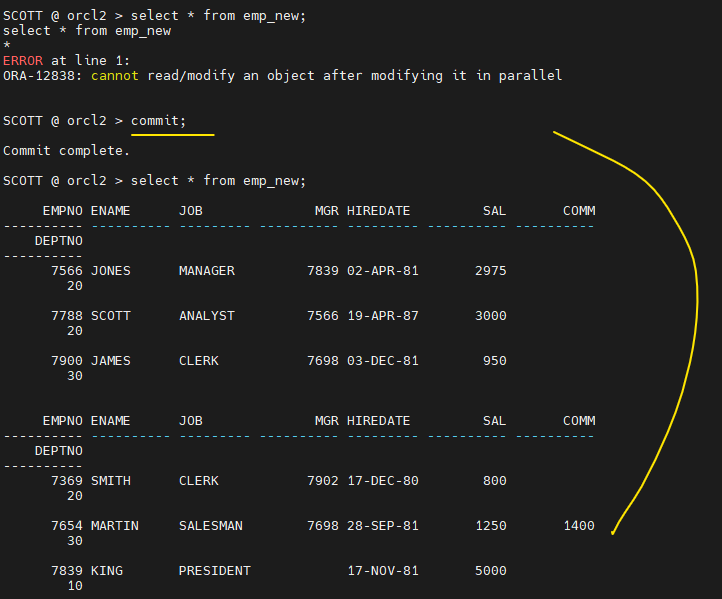
관련문제 SH계정으로 접속해서 SALES 테이블의 구조로 sales_new테이블을 생성하고, sales테이블을 sales_new 테이블에 입력하는데, direct load insert 병렬 방법으로 입력하기!
SH> create table sales_new
as
select *
from sales
where 1=2; -- 구조 만들기
SH> alter session enable parallel dml;
SH> insert /*+ parallel(sales_new, 4) */ into sales_new
select *
from sales;
918843 rows created.
-- commit;을 하지 않아서 에러가 난다 !
SH @ orcl2 > select count(*) from sales_new;
select count(*) from sales_new
*
ERROR at line 1:
ORA-12838: cannot read/modify an object after modifying it in parallel Direct load insert 의 특징 및 장단점 (ws1_p17-30)
✔️ 장점 : 속도가 빠르다.
✔️ 단점 : 낭비되는 저장공간이 생긴다. (즉, 저장공간이 더 많이 소요된다.) nologging 으로 insert 를 하면 복구가 안된다.
Direct load insert 의 특징
1. DATA 를 HWM 위로 입력된다.
2. append, parallel 힌트를 사용해서 입력
3. nologging 옵션을 사용할 수 있다. -> redo 가 생성되지 않는다. 속도는 빠르지만 복구가 되지 않는다.
nologging 옵션을 이용해서 데이터 입력하는 방법
SCOTT> delete from emp_new;
SCOTT> commit;
SCOTT> alter session enable parallel dml;
SCOTT> insert /*+ append */ into emp_new
nologging
select *
from emp;⭐ Direct load insert 의 제약사항
- LOB 컬럼이 하나라도 있으면 수행이 안된다.
create table emp ( ename number(10), email clob); -- 이런거 있으면 안된다.
- IOT(index organized table) 는 지원하지 않는다.
- 분산 DB 환경에서는 지원하지 않는다.
data 이행에 관련한 개념 및 툴 3가지
Direct load insertSQL * Loaderexport/import
2. SQL * Loader
엑셀, csv, 텍스트 파일을 오라클 데이터 베이스의 테이블에 입력하는 툴 !
direct=y 옵션을 사용하면 더 빠르게 입력할 수 있다. 이렇게 로드하는 방법을 direct path insert 라고 한다.
direct load insert는 hwm위에 데이터가 입력되게 하는 서브쿼리를 사용하는 insert 문이었고, sql*loader 에서 direct=y 옵션을 써서 데이터를 입력하면 이를 direct path insert 라고 합니다.
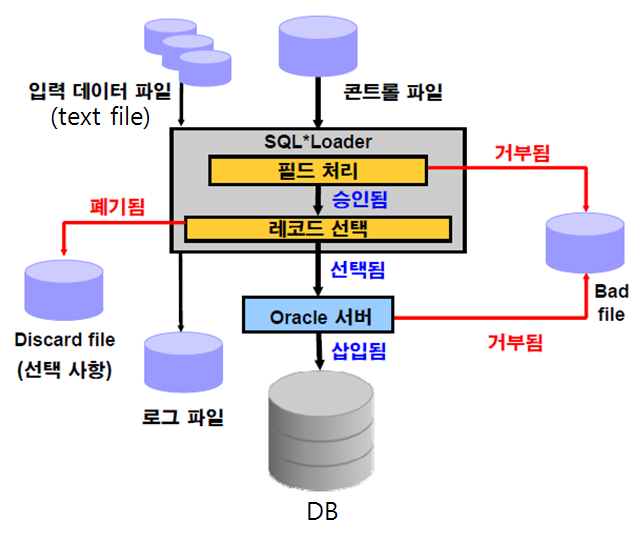
SQL * Loader 로 대용량 데이터 입력하기
✍🏻 text 데이터로 DB 에 insert 하기
✔️ scott으로 접속해서 아래 테이블 생성SCOTT> create table depart_test (did number(10), dname varchar2(20), last_updated date);✔️ 아래의 스크립트를 /home/oracle 밑에 a.txt로 저장
[orcl2:~]$ vi a.txt -- 아래 내용 넣고 저장 load data infile * into table depart_test fields terminated by ',' -- 데이터와 데이터는 콤마(,)로 구분하겠다. optionally enclosed by '"' -- 데이터 중에는 더블 쿼테이션 마크가 있을 수 있다. (did, dname, last_updated date 'yyyy-mm-dd') -- 컬럼명 begindata -- 여기까지는 데이터 넣기위한 문법 부분이고 아래는 데이터이다. 10,Electric,2000-01-05 11,Marketing,2000-07-05 12,transport,1999-03-02 13,manage,2001-03-05 10,Electric,2000-01-05 11,Marketing,2000-07-05 -- 테이블 만들 때 did는 숫자고 dname은 문자형태로 만들었다. 그렇지만 위에 '' 이런거 안했음. 그래도 잘 들어감! -- 날짜는 포맷을 지정해주자!
10,Electric,2000-01-05 11,Marketing,2000-07-05 12,transport,1999-03-02 13,manage,2001-03-05 10,Electric,2000-01-05 11,Marketing,2000-07-05이거를depart_test테이블에 넣을것임 ! 원래는 insert문장을 만들어서 넣어야 하는데, SQL * Loader를 이용하지 않는다면엑셀작업이나notepad++등 힘들게 작업을 해주어야 한다.✔️ 오라클의 데이터 이행 툴인 sqlloader를 이용해서 데이터 입력하기
$ sqlldr scott/tiger control=a.txt . . Commit point reached - logical record count 6✅
control=a.txt에 있는 컨트롤파일은 오라클의 컨트롤 파일이 아니고 sqlldr안의 컨트롤 파일이다.
✅ 데이터 파일은 텍스트 파일(데이터 들어있는파일), 콘트롤 파일은 데이터를 어떻게 넣겠다 라는 문법이 기록되어있다. (콤마로 구분, 옵션...등) 우리는 근데 컨트롤 파일 모든것을 다 넣고, 컨트롤 파일만 썼다.
✔️ 데이터가 잘 입력되었는지 확인하기SCOTT> select count(*) from depart_test; COUNT(*) ---------- 6💡 위에서 수행한 데이터 이행은 컨트롤 파일안에 데이터도 있는 상태의 데이터 이행이었다.
✔️ 데이터 파일과 컨트롤 파일을 서로 분리하고 데이터 이행을 해보자!
- 카페에서 sample.csv를 다운로드
- 아래의 테이블을 scott유저에서 생성
SCOTT> create table sample (line_no varchar2(20), time_inout varchar2(10), in_cnt varchar2(10), out_cnt varchar2(10) );✔️ 다운로드 받은 sample.csv를 리눅스에 /home/oracle밑에 올린다.
✔️ 데이터 입력 문법이 있는 아래의 컨트로 파일을 생성하시오 !$ vi sample.txt options(skip=1) load data infile '/home/oracle/sample.csv' into table sample fields terminated by ',' optionally enclosed by '"' (line_no , time_inout, in_cnt, out_cnt )✔️ SQLloader를 이용해서 다음과 같이 데이터를 이행한다!
$ sqlldr scott/tiger control=sample.txt data=sample.csv . . Commit point reached - logical record count 20✔️ 확인하기!
SCOTT @ orcl2 > select count(*) from sample; COUNT(*) ---------- 20✅ text, csv 등을 oracle의 테이블로 구성하는 것이 SQL loader!
✅control=sample.txt에는 문법이 들어있고data=sample.csv는 데이터가 들어있다.
✅ 문법상 문제가 있다면 Bad file에 들어간다. 문제가 없지만 테이블에 입력되지 못하는 데이터는 Discard file에 들어간다. 이 과정을 로그파일에 쓴다. (어떤게 bad file,discard file에 들어갔는지, 성공적으로 수행 되었는지..)data file -> data가 있는 파일 controlfile -> SQL loader 문법이 들어있는 파일 bad file -> 문법에 어긋난 data가 들어간 파일 discard file -> 문법은 맞는데 테이블에 제약이 있어서 제약에 어긋나서 입력 안되는 data가 들어간 파일 log file -> SQL loader로 데이터를 이행한 이력정보
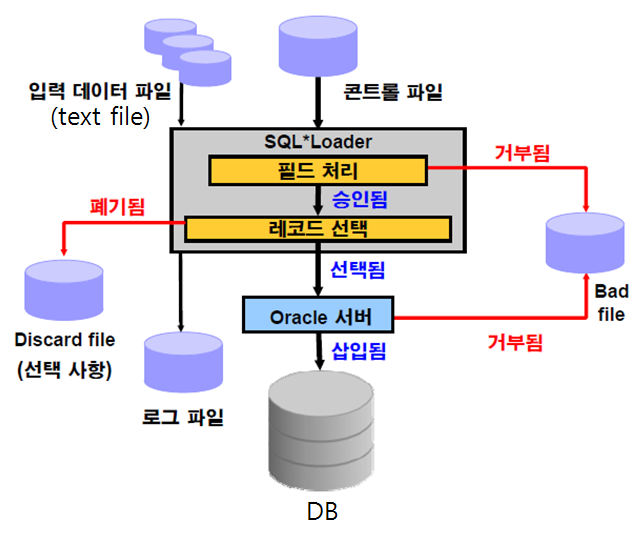
문제 dept2.csv를 dept100 table에 입력하기
1. dept100 테이블 만들기
SCOTT> create table dept100 (deptno number(10), dname varchar2(20), loc varchar2(20) );2. dept2.csv 올리기
3. 데이터 입력 문법이 있는 아래의 컨트롤 파일 생성$ vi dept2.ctl options(skip=1) load data infile '/home/oracle/dept2.csv' into table dept100 fields terminated by ',' optionally enclosed by '"' (deptno , dname, loc )4. SQLloader로 다음과 같이 데이터 이행
$ sqlldr scott/tiger control=dept2.ctl data=dept2.csv . . Commit point reached - logical record count 4
문제 scott 계정에서 sales100 테이블을 생성하고 sales.csv 파일을 sqlloader 로 입력하시오 !
- sales테이블로 sales100 생성 스크립트를 뽑는다.(SH에서)
SH> create table sales100 as select * from sales; SH> set long 50000 SH> select dbms_metadata.get_ddl('TABLE',TABLE_NAME,'SH') from user_tables where table_name='SALES100'; SCOTT> CREATE TABLE "SCOTT"."SALES100" ( "PROD_ID" NUMBER NOT NULL ENABLE, "CUST_ID" NUMBER NOT NULL ENABLE, "TIME_ID" DATE NOT NULL ENABLE, "CHANNEL_ID" NUMBER NOT NULL ENABLE, "PROMO_ID" NUMBER NOT NULL ENABLE, "QUANTITY_SOLD" NUMBER(10,2) NOT NULL ENABLE, "AMOUNT_SOLD" NUMBER(10,2) NOT NULL ENABLE ) SEGMENT CREATION IMMEDIATE PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS";
- 데이터 입력 문법이 있는 아래의 컨트롤 파일 생성
$ vi sales100.txt options(skip=1) load data infile '/home/oracle/sales.csv' into table sales100 fields terminated by ',' optionally enclosed by '"' (prod_id,cust_id,time_id date 'YYYY/MM/DD HH24:MI:SS',channel_id,promo_id,quantity_sold,amount_sold ) $ sqlldr scott/tiger control=sales100.txt data=sales.csv $ wc -l sales.csv⭐ SQL loader를 이용해서 데이터 입력시 성능을 높이는 방법
$ sqlldr scott/tiger control=sales100.txt data=sales.csv direct=y✅ direct 옵션
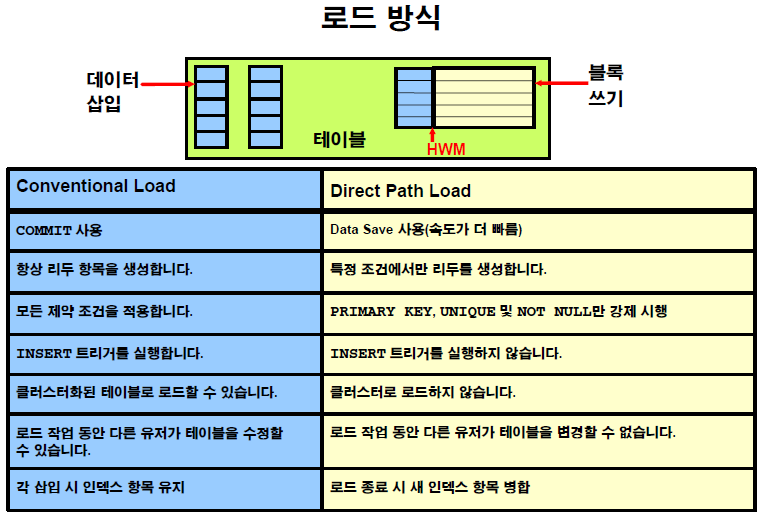
- y : direct path load 방식으로 load 한다. (HWM 위에 입력)
- n : conventional load 방식으로 load 한다. (HWM 아래에 입력)
Direct Path Load
관련문제⭐ SQL loader를 이용해서 데이터 입력시 성능을 높이는 방법!!
: scott 유저로 가서 sales100를 truncate 해주고 실행.SCOTT> truncate table sales100; $ sqlldr scott/tiger control=sales100.txt data=sales.csv direct=y✅ 위 문제보다 데이터 입력이 훨씬 빠르게 되는것을 확인할 수 있다. (HWM위에 들어가서) 이거 안쓰는 사람 없음!!!
로드 방식의 장단점!
🚨 데이터 이관 vs 데이터 이행
데이터 이관은 구서버에있는 데이터를 그대로(통채로) 신서버로 옮기는 것이고 데이터 이행은 구서버에 있는 데이터를 일부 변경하고, 컬럼을 삭제/추가 등 특별한 작업을 해서 옮긴다.
alter session enable parallel dml;
insert /*+ parallel(emp_new, 4) */ into emp(empno, ename, sal, job, mgr, comm, hiredate, deptno)
select /*+ parallel(emp,6) */ empno, ename, '0000' as sal, substr(job,1,5) as job, mgr, comm, hiredate, deptno
from emp;3. export / import
💡 실습을 위해 db를 하나 더 생성한다. dbca로 만드는데, db 이름은 orcl3. 이곳에는 샘플 스키마를 만들지 않기!!
[orcl2:~]$ . oraenv
ORACLE_SID = [orcl2] ? orcl3
The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle
[orcl3:~]$ ✅ . oraenv라는 쉘 스크립트를 이용해서 orcl2, orcl3를 왔다갔다 하기 !
💡 export / import -> export pump / import pump로 이름이 바뀌었다.
export pump / import pump의 종류 4가지
1. table 단위: 특정 테이블만 export / import
2. user 단위: scott과 같이 유저가 가지고 있는 모든 객체를 export / import
3. tablespace 단위: tablespace의 데이터를 통채로 export / import
4. database 단위: database를 통채로 export / import# 실습환경 orcl2 ----------------> orcl3 # orcl2에 있는 emp를 orcl3로 옮길것이다! # orcl3의 scott 계정을 삭제하겠습니다. SYS @ orcl3 > drop user scott cascade; User dropped. # 다시 생성 SYS @ orcl3 > create user scott identified by tiger ; User created. SYS @ orcl3 > grant dba to scott; Grant succeeded.
실습1. 테이블 레벨로 export/import 하는 실습
1. orcl2의 scott계정의 emp 테이블을 export 하기
$ . oraenv orcl2 [orcl2:~]$ exp scott/tiger tables=emp file=emp.dmp2. orcl3 scott계정에 emp 테이블을 import 하기
$ . oraenv orcl3 [orcl3:~]$ imp scott/tiger tables=emp file=emp.dmp
문제 orcl2의 dept테이블을 orcl3 scott계정에 만들기
1. orcl2의 scott계정의 emp 테이블을 export 하기
$ . oraenv orcl2 [orcl2:~]$ exp scott/tiger tables=dept file=dept.dmp2. orcl3 scott계정에 emp 테이블을 import 하기
$ . oraenv orcl3 [orcl3:~]$ imp scott/tiger tables=dept file=dept.dmp SCOTT @ orcl3 > select * from dept; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON
문제 orcl2 sh계정의 sales 테이블을 export하는데, 그 과정을 디스플레이 하기
$ . oraenv orcl2 $ exp sh/sh tables=sales file=sales.dmp feedback=10✅
feedback=10를 쓰면 과정이 보인다.
문제 orcl2의 sales.dmp를(방금만든거) orcl3 sh 계정에 import 하세요 !
1. 먼저 sh 계정을 만들어줍니다.
SYS @ orcl3 > create user sh identified by sh; User created. SYS @ orcl3 > grant dba to sh;2. import하기 (example tablespace가 없어서 생성해줬다.)
SYS @ orcl3 > create tablespace example datafile '/u01/app/oracle/oradata/orcl3/example01.dbf' size 500m; [orcl3:~]$ imp sh/sh tables=sales file=sales.dmp feedback=10
실습2. 유저 레벨로 export/import하는 실습
1. orcl2의 scott이 가지고 있는 모든 테이블을 통채로 export 하기
$ . oraenv orcl2 $ exp scott/tiger owner=scott file=scott.dmp2. orcl3의 scott계정을 drop, 다시 생성한 후에 orcl2의 scott.dmp를 orcl3에 import 하기
$ . oraenv orcl3 SYS @ orcl3 > drop user scott cascade; User dropped. SYS @ orcl3 > create user scott identified by tiger; SYS @ orcl3 > grant dba to scott; [orcl3:~]$ imp system/oracle file=scott.dmp fromuser=scott touser=scott✅ 데이터의 정합성이 중요하다고 했는데, 두 데이터가 똑같이 맞는지 확인해보자.
문제 orcl2의 scott의 테이블 데이터 건수와 orcl3 scott의 테이블의 데이터 건수가 일치하는지 확인해보기 minus를 통해 차이점을 구할 것! -> db링크로 연결할거라 db링크 만들어줌
$ . oraenv orcl2
SYS @ orcl2 > exec dbms_stats.gather_schema_stats('SCOTT');
PL/SQL procedure successfully completed.
$ . oraenv orcl3
SYS @ orcl3 > exec dbms_stats.gather_schema_stats('SCOTT');
SYS @ orcl3 > select table_name, num_rows
from dba_tables
where owner='SCOTT';
TABLE_NAME NUM_ROWS
------------------------------ ----------
DEPART_TEST 6
DEPT 4
DEPT100 4
EMP 14
EMP_NEW 14
SALES100 918843
SALGRADE 5
SAMPLE 20
8 rows selected.문제 orcl3에서 orcl2의 데이터를 조회할 수 있도록 dblink를 생성하기
SCOTT @ orcl3> create database link orcl2_link
connect to scott
identified by tiger
using 'edydr1p0.us.oracle.com:1521/orcl2';
SCOTT @ orcl3> select * from dept@orcl2_link; -- 잘 보임 문제 orcl3에서 orcl2 scott 유저의 테이블들의 이름, 건수를 확인
SCOTT @ orcl3> select table_name, num_rows
from user_tables@orcl2_link;문제 minus를 이용해서 orcl2, orcl3간의 scott계정 테이블과 건수의 차이가 있는지 확인하기
-- orcl3에는 있는데 orcl2에는 없는 것. SCOTT @ orcl3> select table_name, num_rows from user_tables minus select table_name, num_rows from user_tables@orcl2_link; no rows selected -- orcl2에는 있는데 orcl3에는 없는 것. SCOTT @ orcl3> select table_name, num_rows from user_tables@orcl2_link minus select table_name, num_rows from user_tables; TABLE_NAME NUM_ROWS ------------------------------ ---------- BONUS 0 #아래 확인해보면 orcl3에는 보너스 테이블이 없다. SCOTT @ orcl3 > select table_name, num_rows from user_tables ; TABLE_NAME NUM_ROWS ------------------------------ ---------- SAMPLE 20 SALGRADE 5 SALES100 918843 EMP_NEW 14 EMP 14 DEPT100 4 DEPT 4 DEPART_TEST 6 8 rows selected.
오늘의 마지막 문제 orcl2의 sh 계정과 hr 계정의 모든 테이블과 객체들을 orcl3의 sh계정과 hr계정에 import 하시오. 그리고 두 db간의 테이블 갯수와 건수간의 정합성을 확인하기!
orcl2 ------------------> orcl3
sh sh
hr hr1. orcl3에서 sh, hr 계정을 drop 하고 다시 만든다.
SYS @ orcl3 > drop user sh cascade; User dropped. SYS @ orcl3 > create user sh identified by sh; SYS @ orcl3 > grant dba to sh; SYS @ orcl3 > create user hr identified by hr; SYS @ orcl3 > grant dba to hr;2. 유저 레벨로 export/import 하기
$ . oraenv orcl2 $ exp sh/sh owner=sh file=sh.dmp SYS @ orcl2 > alter user hr account unlock; SYS @ orcl2 > grant dba to hr; $ exp hr/hr owner=hr file=hr.dmp🚨 export중, hr 계정 비밀번호가 틀리다고 하여 sys계정에서 비밀번호 다시 변경함!
$ exp hr/hr owner=hr file=hr.dmp EXP-00056: ORACLE error 1017 encountered ORA-01017: invalid username/password; logon denied SYS @ orcl2 > alter user hr identified by hr; User altered.3. orcl3에 import 하기
$ . oraenv orcl3 [orcl3:~]$ imp system/oracle file=sh.dmp fromuser=sh touser=sh [orcl3:~]$ imp system/oracle file=hr.dmp fromuser=hr touser=hr4. orcl3에서 orcl2의 데이터를 조회할 수 있도록 dblink를 생성하기
--SH 계정 dblink 만들기 SH @ orcl3> create database link orcl2_link_sh connect to sh identified by sh using 'edydr1p0.us.oracle.com:1521/orcl2'; SH @ orcl3> select count(*) from sales@orcl2_link_sh; -- 잘 보임 --HR 계정 dblink 만들기 HR @ orcl3> create database link orcl2_link_hr connect to hr identified by hr using 'edydr1p0.us.oracle.com:1521/orcl2'; HR @ orcl3> select * from jobs@orcl2_link_hr; -- 잘 보임5. 정합성 확인
✔️ SH 계정 정합성 확인SH @ orcl3> select table_name, num_rows from user_tables minus select table_name, num_rows from user_tables@orcl2_link_sh; no rows selected SH @ orcl3> select table_name, num_rows from user_tables@orcl2_link_sh minus select table_name, num_rows from user_tables; TABLE_NAME NUM_ROWS ------------------------------ ---------- DIMENSION_EXCEPTIONS SALES_TRANSACTIONS_EXT 0✅
DIMENSION_EXCEPTIONS,SALES_TRANSACTIONS_EXT가 import 되지 않았다. 즉 orcl3에는 없음
✔️ HR 계정 정합성 확인HR @ orcl3> select table_name, num_rows from user_tables minus select table_name, num_rows from user_tables@orcl2_link_hr; no rows selected HR @ orcl3> select table_name, num_rows from user_tables@orcl2_link_hr minus select table_name, num_rows from user_tables; no rows selected
