

✔️ time base 방식의 사용자 관리 불완전 복구
어제 수업 이어서
문제 어제 실습을 다시 수행하는데 이번에는 hr 계정의 employees 테이블을 drop 하고 drop되기전 시점으로 불완전 복구하시오 !
💡 어제 실습때 coldbackup3으로 콜드백업 해놓은 상태이다!
$ cp /home/oracle/coldbackup2/*.dbf /home/oracle/coldbackup3/
- 로그 스위치를 5번 수행한다.
alter system switch logfile;
- 체크 포인트도 일으킨다.
alter system checkpoint;
- scott 으로 접속해서 현재 시간을 확인한다.
alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS'; select sysdate from dual; SYSDATE ------------------- 2023/10/17:10:24:16
- 로그 스위치를 3번 일으키고 체크포인트를 일으킨다.
alter system switch logfile; alter system checkpoint;
- hr 계정의 employees 테이블을 drop 하시오 !
HR @ orcl2 > drop table employees cascade constraints purge;
- 불완전 복구 수행
shutdown immediate
기존 원본 data file 들을 모두 삭제하고 백업받은 모든 data file들을 복원한다.
❗ 단 controlfile 과 redo logfile 은 복원하지 않는다. data file 만 삭제하고 백업받은 파일 복원한다.$ cd /u01/app/oracle/oradata/orcl2 ls *.dbf rm *.dbf $ cp /home/oracle/coldbackup3/*.dbf /u01/app/oracle/oradata/orcl2/ -- $ cp /home/oracle/coldbackup2/*.dbf /home/oracle/
- startup mount , select name from v$datafile;
- alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS';
- 복구할 때 아카이브 로그파일 적용하는거 안물어보고 자동으로 다 적용되게끔 아래 키고
SYS> set autorecovery on
- 복구
SYS> recover database until time '2023/10/17:10:24:10';✅ 위에서 확인했던 시간에서 한 5~6초전으로 적는다.
14. 리두로그파일 초기화SYS> alter database open resetlogs ;
- select count(*)from employees ;
COUNT(*) ---------- 107✅ resetlogs로 오픈했으면 다시 fullbackup(coldbackup) 해야한다!
16. coldbackup4 디렉토리 만들고 하기 (datafile, controlfile,alter system switch logfile; alter system switch logfile; alter system switch logfile; alter system checkpoint; shutdown immediate $ mkdir coldbackup4 $ cp /u01/app/oracle/oradata/orcl2/* /home/oracle/coldbackup4/ startup✅ control파일이 경로가 두개라서 다른곳 가서 하나 copy해오기
SYS> show parameter control_files NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_files string /u01/app/oracle/oradata/orcl2/ control01.ctl, /u01/app/oracle /flash_recovery_area/orcl2/con trol02.ctl, /u01/app/oracle/or adata/orcl2/control03.ctl shutdown immediate $ cp /u01/app/oracle/flash_recovery_area/orcl2/control02.ctl /home/oracle/coldbackup4/ $ cp /u01/app/oracle/oradata/orcl2/control03.ctl /home/oracle/coldbackup4/
문제 /u01/app/oracle/oradata/orcl2/ 밑으로 이동할 때 그냥 편하게 oradata 하면 바로 갈 수 있도록 alias를 생성하기
$ cd
$ vi .bash_profile
alias oradata='/u01/app/oracle/oradata/orcl2/'
$ source .bash_profile
$ oradata
$ pwd💡 불완전 복구 후에는 반드시 whole 백업을 해야합니다.
1. full bakcup : 모든 data file을 백업
2. whole backup : 모든 datafile, controlfile, redo logfile을 백업
❓ 어떤 특정 data file 때문에 복구가 안된다면 ?
mount 상태에서 해당 data file 을 offline 시키고 db open 시킨 다음에 테이블 스페이스 drop 을 하면 됩니다.
SQL> alter database datafile 번호 offline drop; SQL> 복구 명령어가 필요하면 복구 수행 SQL> alter database open; SQL> drop tablespace 테이블스페이스 이름 including contents and datafiles;
✔️ RMAN 으로 time base 불완전 복구 수행하기
- 로그스위치를 3번 수행하고 체크포인트를 1번 수행한다.
SYS> @logs SYS> @logs SYS> @logs SYS> @ckpt
- RMAN 으로 Full backup 을 수행한다.
$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3 RMAN> backup database include current controlfile;
- 로그스위치를 3번 수행하고 체크포인트를 1번 수행한다.
- scott 으로 접속해서 현재 시간을 확인한다.
SQL> alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS'; SQL> select sysdate from dual; <------- 현재 시간을 꼭 확인한다. SYSDATE ------------------- 2023/10/17:11:12:02
- scott 에서 emp 테이블을 drop 한다.
SCOTT> drop table emp purge;❗ 여기서 중요한 작업을 해야한다.
.bash_profile을 열어서 아래 내용 추가
이 작업을 왜 하냐면, RMAN으로 불완전 복구를 할 때 위와 같이 환경설정이 되어있어야 time base 불완전 복구를 할 수 있다.$ vi /home/oracle/.bash_profile --아래내용 추가(원래 예전에 해놓음) NLS_LANG=american_america.we8iso8859p15 NLS_DATE_FORMAT='RRRR/MM/DD:HH24:MI:SS' export NLS_LANG export NLS_DATE_FORMAT SCOTT @ orcl2 > select sysdate from dual; SYSDATE ------------------- 2023/10/17:11:15:48 -- 시분초가 잘 나오면 잘 된거임!⭐ RMAN 으로 불완전 복구 수행
6. DB 를 shutdown immediate 하고 mount 로 올린다.
7. mount 상태에서 RMAN 으로 접속하는데 새로운 터미널 창에서 수행$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3
- 알맨에서 불완전 복구를 수행한다.
-- scott 유저 지우기 3초전 ↓ RMAN> run { set until time='2023/10/17:11:11:58'; restore database; recover database; } RMAN> alter database open resetlogs; SCOTT> select * from emp;
- 다 되었으면 알맨으로 다음과 같이 fullbackup 수행!
SYS> @logs SYS> @ckpt RMAN> backup database include current controlfile;
문제 scott 계정을 drop하고 scott계정을 drop하기 전 시점으로 불완전 복구 하시오!
- RMAN 으로 Full backup 을 수행한다.
$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3 RMAN> backup database include current controlfile;
- 드롭하기전 현재 시간 확인
SYS> select sysdate from dual; SYSDATE ------------------- 2023/10/17:11:40:28 SYS> @logs SYS> @logs SYS> @ckpt SYS> drop user scott cascade;⭐ RMAN 으로 불완전 복구 수행
6. DB 를 shutdown immediate 하고 mount 로 올린다.
7. mount 상태에서 RMAN 으로 접속하는데 새로운 터미널 창에서 수행$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3
- 알맨에서 불완전 복구를 수행한다.
-- emp 테이블 drop 하기 3초전 ↓ RMAN> run { set until time='2023/10/17:11:40:25'; restore database; recover database; } RMAN> alter database open resetlogs;
- scott 접속해보기 -> 된다.
- 다 되었으면 알맨으로 다음과 같이 fullbackup 수행!
SYS> @logs SYS> @ckpt RMAN> backup database include current controlfile;
resetlogs를 확인하는 쿼리문
💡 불완전 복구를 하고 resetlogs로 open을 하게되면 새롭게 redo logfile이 reset 되므로, 앞으로 생기는 로그 시퀀스 번호는 다시 1번으로 초기화됩니다.
그동안 어떻게 b에 resetlogs를 했는데 확인하는 쿼리문을 실행합니다.
SYS> select name, resetlogs_time, prior_resetlogs_time
from v$database;
NAME RESETLOGS_TIME PRIOR_RESETLOGS_TIM
--------- ------------------- -------------------
ORCL2 2023/10/17:11:45:49 2023/10/17:11:23:51✔️ LOGMINER 사용하는 방법!
❓내가 언제 drop을 했는지 시간을 모르겠다? 그런데 drop되기 전 시점으로 되돌아 가고 싶다면, LOGMINER 를 이용하면 리두 로그 파일을 분석해서 table drop, user drop을 한 시간을 알아낼 수 있다.
사실 누군가 drop했을때 시간을 확인하며 하는게 아니다. 그런데 우리는 시간을 확인하고 drop 실습을 진행했었다! -> logminer 사용해서 확인
Logminer 사용법
💡log (redo log file, archive log file) 를 mining 하는 툴 (mining: 캐다, 캐내다)
redo log file 와 archive log file 에는 DB 에 가한 모든 변경사항들이 적혀있다. 시간정보와 함께
1. logminer 를 사용하기 위한 환경 구성
SQL> show parameter utl_file_dir NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ utl_file_dir string2. /home/oracle 밑에 miner 라는 디렉토리를 생성하고 이 디렉토리를 log 파일을 분석할 장소로 지정한다.
[orcl2:~]$ mkdir miner SQL> alter system set utl_file_dir='/home/oracle/miner' scope=spfile; SQL> startup force SQL> show parameter utl_file_dir NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ utl_file_dir string /home/oracle/miner3. 로그마이너로 분석할 디렉토리에 디렉토리 파일을 생성한다.
SQL> execute dbms_logmnr_d.build('dir_file','/home/oracle/miner'); PL/SQL procedure successfully completed. [orcl2:miner]$ cd /home/oracle/miner [orcl2:miner]$ ls dir_file -- 이게 있는지 확인 !!✅
dbms_logmnr는 패키지,dir_file는 이름 내맘대로 지정!
4. 테이블을 drop 을 하고 checkpoint 를 일으킨다.SCOTT > drop table dept purge; SYS > alter system checkpoint ;✅ 설명 : checkpoint 를 하는 이유는 테이블을 drop 했다는 내용이 redo log buffer 에는 적혀있는데 redo logfile 에 내려써야 분석이 되니까 drop 했다는 내용을 redo log file 에 내려쓰려고 checkpoint 를 일으킨것이다.
5. Current redo logfile 이 무엇인지 알아낸다.
SQL> select group#, status from v$log; GROUP# STATUS ---------- ---------------- 1 INACTIVE 2 INACTIVE 3 CURRENT ----- 3번이 current group 이다라고 하면 SQL> select group#, member from v$logfile; 3 /u01/app/oracle/oradata/orcl2/redo03.log 3 /u01/app/oracle/oradata/orcl2/redo03b.log ----- 3번 그룹의 멤버 -- ↑ drop table dept가 여기에 적혀있을 것!6. 분석할 redo log file 을 추가하는 작업을 수행한다.
SQL> exec dbms_logmnr.add_logfile('/u01/app/oracle/oradata/orcl2/redo03.log',1); PL/SQL procedure successfully completed. ★ 숫자의 의미 ★ 1 --------> new (새로 추가) 3 --------> add (추가) 2 --------> remove (삭제)7. 분석시도
SQL> exec dbms_logmnr.start_logmnr(dictfilename=>'/home/oracle/miner/dir_file');8. 분석된 결과 확인
v$logmnr_contents라는 뷰!SQL> alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS'; SQL> select timestamp, username, sql_redo from v$logmnr_contents where sql_redo like '%drop%'; 2023/10/17:13:50:24 UNKNOWN drop table dept purge;
문제 scott의 emp table을 drop하고 drop된 시간을 확인하시오 !
4. 테이블을 drop 을 하고 checkpoint 를 일으킨다.
SCOTT > drop table emp purge; SYS > alter system checkpoint ;✅ 설명 : checkpoint 를 하는 이유는 테이블을 drop 했다는 내용이 redo log buffer 에는 적혀있는데 redo logfile 에 내려써야 분석이 되니까 drop 했다는 내용을 redo log file 에 내려쓰려고 checkpoint 를 일으킨것이다.
5. Current redo logfile 이 무엇인지 알아낸다.
SQL> select group#, status from v$log; GROUP# STATUS ---------- ---------------- 1 CURRENT 2 INACTIVE 3 INACTIVE SQL> select group#, member from v$logfile; 1 /u01/app/oracle/oradata/orcl2/redo01b.log 1 /u01/app/oracle/oradata/orcl2/redo01.log6. 분석할 redo log file 을 추가하는 작업을 수행한다.
💡 current인 redo01.log만 했는데 쿼리문에 나오지 않아서 리두로그 파일 다 했다. 아마 넘어간듯 함!!SQL> exec dbms_logmnr.add_logfile('/u01/app/oracle/oradata/orcl2/redo01.log',3); SQL> exec dbms_logmnr.add_logfile('/u01/app/oracle/oradata/orcl2/redo02.log',3); SQL> exec dbms_logmnr.add_logfile('/u01/app/oracle/oradata/orcl2/redo03.log',3); PL/SQL procedure successfully completed. ★ 숫자의 의미 ★ 1 --------> new (새로 추가) 3 --------> add (추가) 2 --------> remove (삭제)7. 분석시도
SQL> exec dbms_logmnr.start_logmnr(dictfilename=>'/home/oracle/miner/dir_file');8. 분석된 결과 확인
v$logmnr_contents라는 뷰!SQL> alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS'; SQL> select timestamp, username, sql_redo from v$logmnr_contents where sql_redo like '%drop%'; 2023/10/17:14:00:53 UNKNOWN drop table emp purge;
💡 scott에서 @demo 돌려서 emp, dept 다시생성

- 완전복구
- 불완전 복구
- time base 불완전 복구
- cancle base 불완전 복구
✔️ cancle base 불완전 복구
💡 cancle base 불완전 복구가 필요한 때가 언제인지?
1.current redo log group이 깨졌을 때
2.모든 redo log file이 다 삭제되었을 때❓ db 운영중에 없으면 바로 db가 다운되거나, 운영이 안되는 파일들의 종류!
1.data file
2.controlfile
3.redo log file
✏️ redo log file이 손상되었을 때 복구방법
- inactive 상태의 redo log file -> 깨지면 깨진 redo log group 정보를 지우면 해결됨
- active 상태의 redo log file -> cancle base 불완전 복구
- current 상태의 redo log file -> cancle base 불완전 복구
✔️ inactive 상태의 redo log file이 깨졌을 때의 복구방법 (완전복구)
💡 drop 하고 새로 추가하는 방법이라서 사실 복구랄게 없다!
➡️ 실습 전, 백업 먼저 하기
- shutdown immediate
- whole backup을 수행하기 (/home/oracle/coldb5/)
$ mkdir coldb5
$ cp /u01/app/oracle/oradata/orcl2/* /home/oracle/coldb5/
$ cp /u01/app/oracle/flash_recovery_area/orcl2/control02.ctl /home/oracle/coldb5/ -- controlfile 다른위치
$ cp /u01/app/oracle/oradata/orcl2/control03.ctl /home/oracle/coldb5/ -- controlfile 다른위치- startup
1.
INACTIVE상태의 redo log group을 확인한다.SYS> @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 CURRENT 4 2 2 INACTIVE 2 3 2 INACTIVE 32. current에서 먼것을 (3번) 깨트린다. 가까운거는 바로 바뀔수가 있으니!
: 만약 active로 되어있으면 체크포인트 일으키기SYS> @logf 3 /u01/app/oracle/oradata/orcl2/redo03b.log 3 /u01/app/oracle/oradata/orcl2/redo03.log
- rm으로 INACTIVE log member를 삭제 (member 2개라서 둘다 날리기)
$ rm /u01/app/oracle/oradata/orcl2/redo03.log $ rm /u01/app/oracle/oradata/orcl2/redo03b.log
- startup force
ORA-03113: end-of-file on communication channel Process ID: 9592 Session ID: 125 Serial number: 5
5. db가 강제로 내려가져서 mount상태로 올렸다.SYS @ orcl2 > startup mount
- alter database drop logfile group 3;
✅ controlfile에 적혀있는 3번 그룹에 대한 리두 정보를 지워버린다.
✅ 만약 current 상태나 active 상태의 그룹을 깨트렸으면 drop할 수 없다.- alter database open;
- member를 만들어주기
alter database add logfile group 3 '/u01/app/oracle/oradata/orcl2/redo03.log' size 20m;
- 잘 생성되었는지 확인
SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 CURRENT 6 2 2 INACTIVE 5 3 1 UNUSED 0 SYS @ orcl2 > @logf SP2-0734: unknown command beginning "selt lines..." - rest of line ignored. GROUP# MEMBER ---------- --------------------------------------------- 1 /u01/app/oracle/oradata/orcl2/redo01.log 1 /u01/app/oracle/oradata/orcl2/redo01b.log 2 /u01/app/oracle/oradata/orcl2/redo02b.log 2 /u01/app/oracle/oradata/orcl2/redo02.log 3 /u01/app/oracle/oradata/orcl2/redo03.logSYS> @logf SYS> @logs SYS> @ckpt
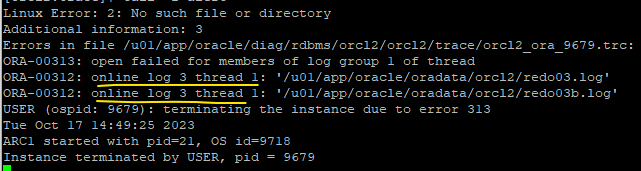
✔️current log file이 깨졌을 때 cancle base로 불완전 복구 하기 (난이도 상)
- 사용자 관리 백업으로 cold backup 을 수행한다. -> 아까했음 안해도됨
SQL> select file_name from dba_data_files; SQL> select name from v$controlfile; SQL> select member from v$logfile; SQL> shutdown immediate - coldbackup5 에 copy SQL> startup
- 로그 스위치를 3번일으키고 체크포인트를 일으킨다.
SYS @ orcl2 > @logs SYS @ orcl2 > @logs SYS @ orcl2 > @logs SYS @ orcl2 > @ckpt
- 깨트릴 current redo log file 을 확인한다.
SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 INACTIVE 9 2 2 INACTIVE 8 3 1 CURRENT 10 --current!!! SQL> select group#, stauts, sequence# from v$log;
- current redo log group 의 멤버를 확인한다.
SYS> @logf 3 /u01/app/oracle/oradata/orcl2/redo03.log SQL> select group#, member from v$logfile;5. shutdown abort
※ shutdown immediate 로 내리면 current 가 바뀔수 있어서
6. os 에서 current redo log group 의 멤버를 모두 삭제$ rm /u01/app/oracle/oradata/orcl2/redo03.log7. startup
<--------- mount 에서 멈춘다. alert log file 을 보고 어떠한 파일이 문제가 있어서
db 가 안올라오는지 확인8. 문제가 되는 redo log file 의 현재 상태가 무엇인지 확인
-- current redo log group 의 시퀀스번호 확인 -- 예를 들어 6번으로 확인이 되었다면 인데 나는 3번의 SEQUENCE#는 10 !!! SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 INACTIVE 9 3 1 CURRENT 10 2 2 INACTIVE 89. shutdown abort
10. 모든 data file 들을 복원한다.
✅ controlfile 과 redo logfile 은 복원 안한다.
덮어써도 되긴하지만 기존 원본 data file들을 rm으로 지우고 백업받은 파일을 복원한다.$ cd /u01/app/oracle/oradata/orcl2/ $ rm *.dbf $ cp /home/oracle/coldb5/*.dbf .✅
.은 현재 디렉토리로 복원하겠다 라는 것 !
11. startup mount
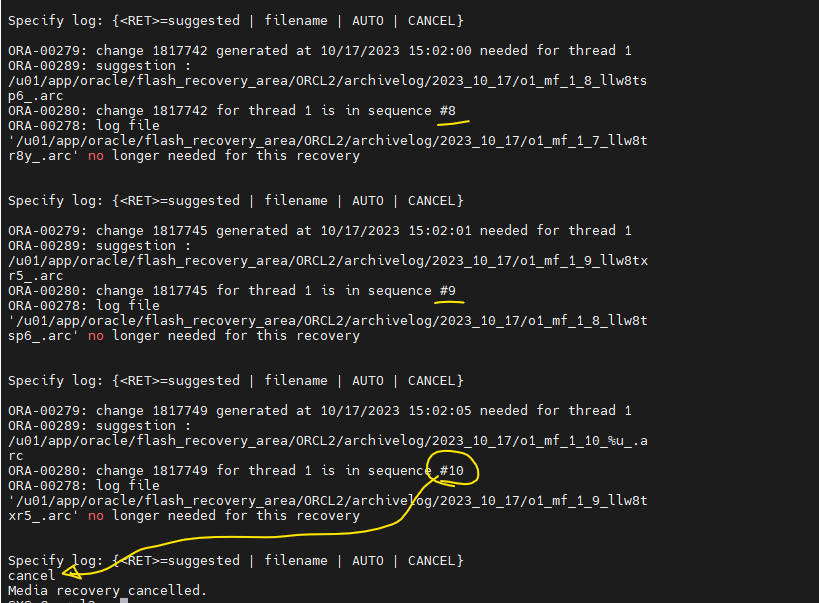
12. set autorecovery off <--- 복구할때 자동으로 적용하는것이 아니라, 적용해야할 로그파일을 하나씩 하나씩 물어보게 설정
13. recover database until cancel;
⭐ 엔터를 치다가 시퀀스 10번을 물어볼때cancel이라고 적고 엔터
14. alter database open resetlogs; -> 얘때문에 시퀀스 번호가 처음부터 리셋됨SYS @ orcl2 > @/home/oracle/log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 CURRENT 1 2 2 UNUSED 0 3 1 UNUSED 015. RMAN으로 풀백업 하기
RMAN> rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3 RMAN> backup database include current controlfile; Starting Control File and SPFILE Autobackup at 2023/10/17:15:16:30 piece handle=/u01/app/oracle/flash_recovery_area/ORCL2/autobackup/2023_10_17/o1_mf_s_1150470990_llw9oylx_.bkp comment=NONE Finished Control File and SPFILE Autobackup at 2023/10/17:15:16:31
- 사용자 관리 whole backup도 수행
shutdown immediate $ mkdir coldb6 $ cp /u01/app/oracle/oradata/orcl2/* /home/oracle/coldb6/ $ cp /u01/app/oracle/flash_recovery_area/orcl2/control02.ctl /home/oracle/coldb6/ -- controlfile 다른위치 $ cp /u01/app/oracle/oradata/orcl2/control03.ctl /home/oracle/coldb6/ -- controlfile 다른위치
문제 리두 로그 그룹의 상태 확인하지 말고 아래의 3개중에 하나를 지우시오
GROUP# MEMBER
---------- ---------------------------------------------
1 /u01/app/oracle/oradata/orcl2/redo01.log
1 /u01/app/oracle/oradata/orcl2/redo01b.log
2 /u01/app/oracle/oradata/orcl2/redo02b.log
2 /u01/app/oracle/oradata/orcl2/redo02.log
3 /u01/app/oracle/oradata/orcl2/redo03.log
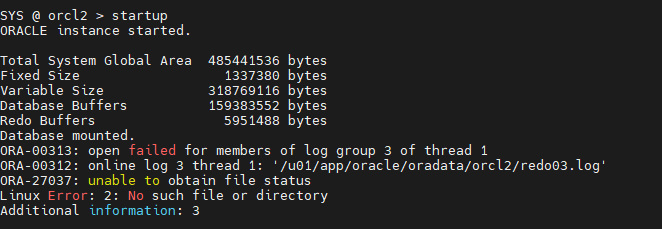
- shutdown abort
- 지우기
$ rm /u01/app/oracle/oradata/orcl2/redo03.log $ rm /u01/app/oracle/oradata/orcl2/redo02.log $ rm /u01/app/oracle/oradata/orcl2/redo02b.log
- startup
ORA-03113: end-of-file on communication channel Process ID: 10978 Session ID: 125 Serial number: 5
- 문제가 되는 멤버 확인하기
GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 CURRENT 1 3 1 UNUSED 0 --얘 2 2 UNUSED 0 --얘
- logfile 드롭해주기
alter database drop logfile group 2; alter database drop logfile group 3;
- alter database open;
- member를 만들어주기
alter database add logfile group 2; '/u01/app/oracle/oradata/orcl2/redo02.log' size 20m; alter database add logfile group 3; '/u01/app/oracle/oradata/orcl2/redo03.log' size 20m;
- 잘 생성되었는지 확인
SYS @ orcl2 > @log
🚨 실습중에 하나지우는건데 두개 지웠음 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋcurrent는 아니고 unused 였어서 아래 순서로 진행. 5번처럼 한번에 drop을 연속으로는 에러남
1. 2번 logfile drop
alter database drop logfile group 2;2. 2번 logfile 추가
alter database add logfile group 2; '/u01/app/oracle/oradata/orcl2/redo02.log' size 20m;3. 3번 logfile drop
alter database drop logfile group 3;4. 3번 logfile 추가
alter database add logfile group 3; '/u01/app/oracle/oradata/orcl2/redo03.log' size 20m;
✔️ Rman 으로 current redo log file 이 깨졌을때의 cancel base 불완전 복구
위 문제 직후 💡RMAN 으로 full backup 을 수행!!
[orcl2:~]$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3
RMAN> backup database include current controlfile;
- 로그 스위치를 3번 일으킨다.
@logs
- 체크 포인트를 수동으로 일으킨다.
- RMAN 으로 Full backup 을 수행한다. - 방금했으니 안해도 됨
- 로그 스위치를 3번 일으킨다.
@logs
- 체크 포인트를 수동으로 일으킨다.
- current redo log group 이 몇번인지 확인한다.
SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 INACTIVE 4 2 1 CURRENT 5 -- 2번이 CURRENT 3 1 INACTIVE 3
- current redo log group 의 멤버가 무엇인지 확인한다.
- shutdown abort
- os 에서 current redo log group 의 멤버를 모두 삭제한다.
$rm /u01/app/oracle/flash_recovery_area/ORCL2/onlinelog/o1_mf_2_llwbx5gr_.log
- startup
- current redo log group 의 시퀀스 번호 확인
SYS @ orcl2 > select group#, status, sequence# from v$log; 2 GROUP# STATUS SEQUENCE# ---------- ---------------- ---------- 1 INACTIVE 4 3 INACTIVE 3 2 CURRENT 5 -- 5!!!
- RMAN으로 복구!
RMAN> run { set until 5 thread 1; restore database; recover database; }⭐ 혹시 위 방법으로 복구가 안된다?? 아래로 수행!
RMAN> list failure; RMAN> advise failure; RMAN> repair failure;➡️ 위와 같이 했는데 복구를 못했으면 datafile, controlfile, redo log file 전체 다 whole backup 받은 파일을 전부 원본 위치에 다 복원한 후에 startup 하면 됨!!
13. RMAN> alter database open resetlogs;
14. rman fullbackupRMAN> backup database include current controlfile;

/u01/app/oracle/flash_recovery_area/ORCL2/onlinelog
오라클 block 손상시 복구 방법
💡 현업에서 자주 발생하는 장애
database의 논리적 구조 ------------------------ 물리적 구조
database
↓
tablespace -----------------> datafile
↓ ↓
segment os block
↓
extent
↓
block ✅ data file 을 손상시켜왔는데 이제 os block을 손상시켜 볼 것이다!
os block이 손상되면 db가 내려가지는 않고 내렸다 올려도 잘 올라온다. 그렇지만 block이 손상된 특정 테이블의 일부 데이터를 select할 때 error가 난다. (다른데이터는 select됨) 그래서 테이블을 drop하고 다시 만들려고 하면 또 drop이 안된다.
block 손상시 복구 방법 실습
- ts600 테이블 스페이스 생성
create tablespace ts600 datafile '/home/oracle/ts600.dbf' size 20m;
- scott으로 접속
connect scott/tiger
- emp600 table 생성하는데 emp와 똑같이 만들고 ts600안에 만든다.
SCOTT> create table emp600 tablespace ts600 as select * from emp;
- RMAN 으로 ts600 테이블 스페이스를 백업한다.
RMAN> backup tablespace ts600;
- os 에서 ts600.dbf 를 손상시킬 준비 작업을 한다.
➡️ 카페에서 블럭 손상시키는 쉘(lab_07_02.sh) 를 /home/oracle 밑에 전송한다.[orcl2:~]$ ls -l lab_07_02.sh -rw-r--r-- 1 oracle oinstall 697 10월 17 16:23 lab_07_02.sh
- 손상시킬 블럭의 data file 의 파일번호와 블럭번호를 확인한다.
SYS> select file_id, block_id from dba_extents where segment_name='EMP600'; FILE_ID BLOCK_ID ---------- ---------- 7 128✅ 블럭번호를 확인한다. (예: 블럭번호 128번)
7. 블럭을 손상시킨다.[orcl2:~]$ ls -l lab_07_02.sh -rw-r--r-- 1 oracle oinstall 697 10월 17 16:23 lab_07_02.sh [orcl2:~]$ chmod 777 lab_07_02.sh -- 모든 권한 주기 [orcl2:~]$ ls -l lab_07_02.sh -rwxrwxrwx 1 oracle oinstall 697 10월 17 16:23 lab_07_02.sh $ ./lab_07_02.sh /home/oracle/ts600.dbf 128 8192 ↑ ↑ 블럭번호 블럭의 크기
- buffer cache 와 shared pool 을 flush 시킨다.
SYS> alter system flush buffer_cache; SYS> alter system flush shared_pool;
- scott 으로 접속해서 emp600 을 쿼리한다.
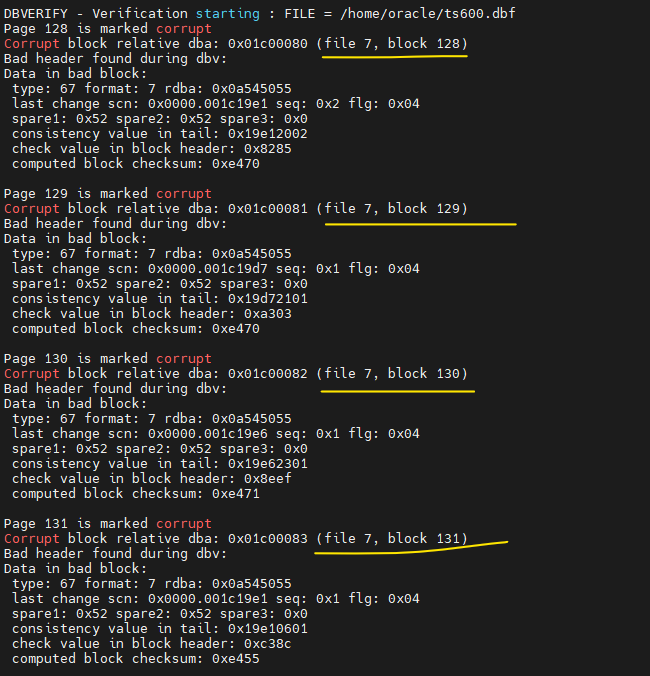
SCOTT> select * from emp600; <--------- 에러나는지 확인한다. ERROR at line 1: ORA-01578: ORACLE data block corrupted (file # 7, block # 130) ORA-01110: data file 7: '/home/oracle/ts600.dbf'
- 손상된 블럭이 정확하게 어떤건지 확인한다.
$ dbv file=/home/oracle/ts600.dbf blocksize=8192 -- 블럭 손상에 관련한 레포트가 출력
11. RMAN 으로 들어가서 위의 레포트를 보고 복구를 한다.RMAN> blockrecover datafile 7 block 128,129,130,131; ↑ ↑ emp600이 있는 datafile 번호 손상된 블럭번호들 starting media recovery media recovery complete, elapsed time: 00:00:03 Finished recover at 2023/10/17:16:33:27
- scott으로 가서 emp600 select 해보기
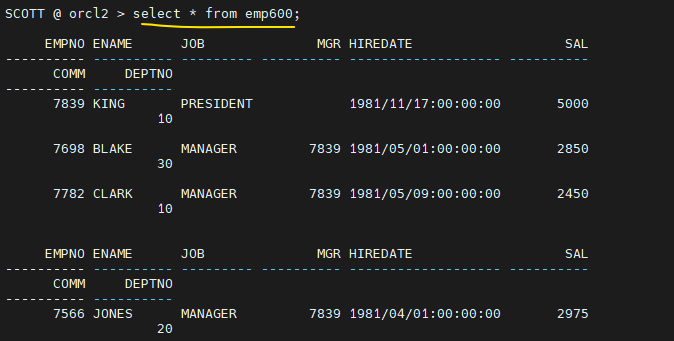
오늘의 마지막 문제 scott 유저에서 시간 확인하지 말고 salgrade table을 drop 시키기. 그리고 log miner를 이용해서 salgrade 테이블이 drop된 시간을 확인한 후, salgrade 테이블이 drop되기 전 시점으로 RMAN으로 timebase 불완전 복구 하기!
✔️ 수행 전, rman full backup 먼저 수행후에 로그 스위치 3번, 체크포인트 한번 수행하고 진행
[orcl2:~]$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3
RMAN> backup database include current controlfile;
SYS> @logs
SYS> @logs
SYS> @logs
SYS> @ckptSQL> show parameter utl_file_dir NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ utl_file_dir string /home/oracle/miner [orcl2:miner]$ cd /home/oracle/miner [orcl2:miner]$ ls dir_file1. salgrade 테이블을 drop 을 하고 checkpoint 를 일으킨다.
SCOTT > drop table salgrade purge; SYS > alter system checkpoint ;✅ 설명 : checkpoint 를 하는 이유는 테이블을 drop 했다는 내용이 redo log buffer 에는 적혀있는데 redo logfile 에 내려써야 분석이 되니까 drop 했다는 내용을 redo log file 에 내려쓰려고 checkpoint 를 일으킨것이다.
2. Current redo logfile 이 무엇인지 알아낸다. - 1번
SQL> select group#, status from v$log; GROUP# STATUS ---------- ---------------- 1 CURRENT 2 INACTIVE 3 INACTIVE SQL> select group#, member from v$logfile; GROUP# MEMBER ---------- --------------------------------------------- 1 /u01/app/oracle/oradata/orcl2/redo01.log 1 /u01/app/oracle/oradata/orcl2/redo01b.log -- ↑ drop table dept가 여기에 적혀있을 것!3. 분석할 redo log file 을 추가하는 작업을 수행한다.
SQL> exec dbms_logmnr.add_logfile('/u01/app/oracle/oradata/orcl2/redo01.log',1); PL/SQL procedure successfully completed. ★ 숫자의 의미 ★ 1 --------> new (새로 추가) 3 --------> add (추가) 2 --------> remove (삭제)4. 분석시도
SQL> exec dbms_logmnr.start_logmnr(dictfilename=>'/home/oracle/miner/dir_file');5. 분석된 결과 확인
v$logmnr_contents라는 뷰!SQL> alter session set nls_date_format='RRRR/MM/DD:HH24:MI:SS'; SQL> select timestamp, username, sql_redo from v$logmnr_contents where sql_redo like '%drop%'; 2023/10/17:16:57:39 UNKNOWN drop table salgrade purge;6. DB 를 shutdown abort 하고 mount 로 올린다.
7. 알맨에서 불완전 복구를 수행한다.$ rman target sys/oracle@orcl2 catalog rc_user/rc_user@orcl3 -- scott 유저 지우기 3초전 ↓ RMAN> run { set until time='2023/10/17:16:57:36'; restore database; recover database; } RMAN> alter database open resetlogs;8. 확인
SCOTT @ orcl2 > select * from salgrade;
💡 다 되었으면 알맨으로 다음과 같이 fullbackup 수행!SYS> @logs SYS> @ckpt RMAN> backup database include current controlfile;
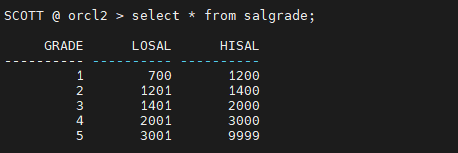
member 경로 바꾸기
💡 아까 위에 실습에서 member를 다시 만들어줬었는데 경로가 이상한곳으로 설정되었었다.
정리해주기 위해 한것!
SYS @ orcl2 > @logf
>
GROUP# MEMBER
---------- ---------------------------------------------
1 /u01/app/oracle/oradata/orcl2/redo01.log
1 /u01/app/oracle/oradata/orcl2/redo01b.log -- 얘도 지울것임
2 /u01/app/oracle/flash_recovery_area/ORCL2/onl
inelog/o1_mf_2_llwj2237_.log
3 /u01/app/oracle/flash_recovery_area/ORCL2/onl
inelog/o1_mf_3_llwj22bj_.log1. INACTIVE 상태에서 해야해서 확인하기
SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 CURRENT 4 2 1 INACTIVE 2 3 1 INACTIVE 32. 1번은 CURRENT상태라 2번먼저 수행
-- 2번그룹 지우고 SYS @ orcl2 > alter database drop logfile group 2; -- 멤버 추가해주기 SYS @ orcl2 > alter database add logfile group 2 '/u01/app/oracle/oradata/orcl2/redo02.log' size 20m;3. 1번 INACTIVE로 바꾼후 삭제
SYS @ orcl2 > @logs System altered. SYS @ orcl2 > @ckpt System altered. SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 2 INACTIVE 4 2 1 INACTIVE 5 3 1 CURRENT 6 SYS @ orcl2 > alter database drop logfile member '/u01/app/oracle/oradata/orcl2/redo01b.log';4. 3번 그룹도 똑같이
SYS @ orcl2 > @log GROUP# MEMBERS STATUS SEQUENCE# ---------- ---------- ---------------- ---------- 1 1 CURRENT 7 2 1 INACTIVE 5 3 1 INACTIVE 6 SYS @ orcl2 > alter database drop logfile group 3; Database altered. SYS @ orcl2 > alter database add logfile group 3 '/u01/app/oracle/oradata/orcl2/redo03.log' size 20m; SYS @ orcl2 > @logf GROUP# MEMBER ---------- --------------------------------------------- 1 /u01/app/oracle/oradata/orcl2/redo01.log 2 /u01/app/oracle/oradata/orcl2/redo02.log 3 /u01/app/oracle/oradata/orcl2/redo03.log
