
Query
 여러 관계형 Database (RDBMS)를 접하고 사용하다보면 Query 작성하여 원하는 데이터를 가공 후 불러오거나, DB의 데이터 확인등 Query는 Database를 직관적으로 분석하거나 사용자의 의도에 따라 가공하여 사용할 수 있도록 데이터의 플로우를 보여준다.
여러 관계형 Database (RDBMS)를 접하고 사용하다보면 Query 작성하여 원하는 데이터를 가공 후 불러오거나, DB의 데이터 확인등 Query는 Database를 직관적으로 분석하거나 사용자의 의도에 따라 가공하여 사용할 수 있도록 데이터의 플로우를 보여준다.
위에 같은 이유에서 Query를 사용할 때, 즉 불러오는 경우 Run time이나 Mmemory usage를 고려할 수 밖에없다.
그렇다면 효율적인 Query를 위해서는 무엇을 고려해야 할까?
*RDBMS(Relational DataBase Management System)?
→ 관계형 데이터베이스라 하고, 대표적으로 Oracle, MySQL, MSSQL, Maria, PostgreSQL가 있습니다.
반대되는 개념으로는 NoSQL이 있습니다.
✅ SQL Query Tuning?
Tuning이란 Query를 사용할 때, Cost및 Runtime를 줄이는 Query효율화 작업이라 생각한다.
하지만 명확하게 "이와같은 방법이 완벽한 Query를 짤 수 있습니다!"라고 단언할 수 는 없다. Query의 쓰임이나 Data형식에 따라 효율적일 수 있는 방법은 다양하기 때문에 하나로 정의할 수 없다.
✅ 그럼 효율적인 Query는 어떻게 설계하는가?
이와 관련하여 여러 포스팅이나 Oracle SQL Tuning Guide 공식문서를 참고하여 제 짧은 경험과 함께 정리해보겠습니다.
웹 프로젝트를 진행하면 W3C 웹표준에 의거하여 코드를 짜는데, 이와 마찬가지로 SQL Query도 Tuning에 정해진 방법은 없지만, 통념적인 설계 기반이 존재한다. 저는 이것을 Query Tuning Flow라고 정의하고, 아래와 같은 설계 Flow가 다양하게 설명되어있습니다.
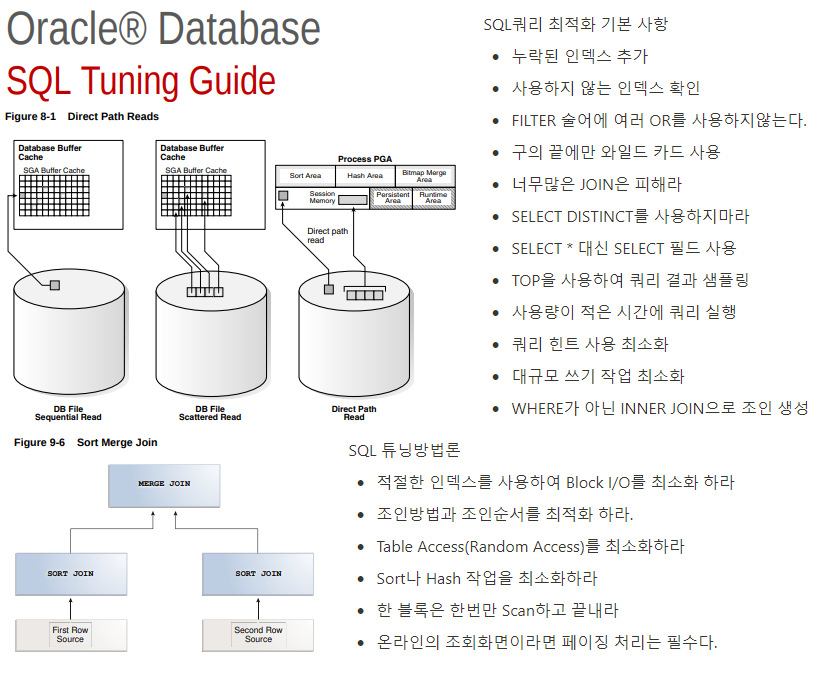
여러가지 방법론이나 가이드를 참고하였을 때, 공통적으로 언급된는 Flow위주로 키워드로 정리하면,
- 적절한 인덱스 사용 및 인덱스 활용도 최대로 가지기
- JOIN 방법및 순서를 최적/최소한으로 사용
- DISTINCT 가급적 피하기
- 과도한 hint 사용자제
- 부정형 문법보다는 긍정적문법을 사용
- Scan & Table Access(Random Access) 최소화하기
- Sort, Hash작업은 최소화(상위쿼리에서 한번에 처리)
위와 같이 정리하였다. 물론 Plan이나 Cost체크는 제외하고 키워드를 정리하였다.
1) 적절한 인덱스 사용 및 인덱스 활용도 최대로 가지기
Query를 설계하다보면 Table조회시 실사용 범위보다 큰 범위의 인덱스를 측정하는 경우 또는 사용하지않는 경우에도 범위를 같이 잡아 I/O작업을 진행한다. 이런경우는 Tuning Flow의 적합하지않다. 그렇기에 필요한 데이터 테이블의 인덱스 범위를 명확하게 알고, 낭비되는 인덱스가 없도록 해야한다.
인덱스는 DB의 약 10%에 해당되는 저장공간을 필요로하기에 과도한 인덱스 사용은 성능저하로 이어지기 때문이다.
* Use Memory in SQL
→ Oracle의 With AS와 같이 메모리를 주사용하는
방식은 지양하는 것을 추천한다.2) JOIN 방법및 순서를 최적/최소한으로 사용
JOIN은 여러 테이블에서 복합적으로 필요한 데이터를 산출하는데 이용하는 구문이다.
하지만 앞서 말했듯 여러 테이블을 불러오며 조건을 걸고 집합의 데이터를 산출하기에 자칫 효과적인 Tuning Flow에 적합하지 않는 경우가 발생할 수 있다. 그렇기에 명심해야하는 것은 예를 들어 A와 B라는 테이블이 존재할 때 각각의 데이터를 최소한으로 불러오고, 적절한 Key를 사용해 최소필요조건으로 필요한 데이터를 가져와야한다.
JOIN하는 과정에서는 여러 집합을 사용하며 조합하다보니, 낭비되는 데이터 호출이 발생할 수 있기에 미리 가져와야하는 데이터의 인덱스를 파악하고 테이블간 최소필요 인덱스를 도식화하여 눈으로 파악하고 조건을 고려하는 것이 나는 효과적이라 생각한다.
→ 물론 이를 위해서는 각 테이블 설계 단계에서 테이블간의 Key를 인덱스에 조건으로 첨삭하는 것이 필요하다.
[Example]
INDEX_INFO
| NUM | PART | ITEM_NAME | CI_MANAGE |
|---|---|---|---|
| 1 | Materials | IAU | BlackRock Inc |
| 2 | Materials | GLD | World Gold Trust Services LLC |
| 3 | Finance | JEPI | JPMorgan Investment Management Inc |
| 4 | Finance | AGG | BlackRock Fund Advisors |
| 5 | Energy | BOIL | ProShare Advisors LLC |
INDEX_COST
| NUM | PART | ITEM_NAME | COST_1M | COST_3M | COST_6M | COST_12M |
|---|---|---|---|---|---|---|
| 1 | Materials | IAU | 0.6 | 0.5 | 0.3 | -1.2 |
| 2 | Materials | GLD | 0.7 | 0.62 | 0.76 | 0.9 |
| 3 | Finance | JEPI | 0.4 | 0.44 | 0.51 | 0.46 |
| 4 | Finance | AGG | 0.3 | 0.2 | 0.22 | -0.1 |
| 5 | Energy | BOIL | 6.9 | 7.5 | 10.2 | 18.2 |
--잘못된 JOIN 사례
SELECT PART, ITEM_NAME, COST_6M FROM INDEX_COST
WHERE 1=1
AND PART = (
SELECT PART FROM INDEX_INFO
WHERE 1=1
AND PART IN (SELECT PART FROM INDEX_INFO WHERE 1=1 AND CI_MANAGE LIKE 'BlackRock Inc')
)--최적/최소한 JOIN사용사례
SELECT A.PART, B.ITEM_NAME, B.COST_6M
FROM INDEX_INFO A, INDEX_COST B
WHERE 1=1
AND A.CI_MANAGE = 'BlackRock Inc'
AND B.PART = A.PART3) DISTINCT 가급적 피하기
일단 해당 키워드에 언급된 DISTINCT는 전체 인덱스중 DISTINCT에 걸린 칼럼을 기준으로
중복제외하여 값을 산출하는 기능을 의미한다.
SELECT DISTINCT(PART) FROM INDEX_COST| PART |
|---|
| Materials |
| Finance |
| Energy |
여러가지 방법론에서나 문서에서 DISTINCT 자제하라고 한다고 했을 때, SQL을 사용한 분들이라면 공감하셨을거다.
해당 기능은 겉으로 보기에는 중복제거라는 기능이 매우 편리해보일 수 있지만, 실제로 여러테이블의 데이터를 복합하여 사용하는 구조에서는 대체적으로 사용할 수 있는 방법도 존재하고 굳이 중복제거하여 일부 단건의 데이터를 보는 것은 시스템에 들어가는 로직상 거의 없다고 생각한다. 또한 DISTINCT의 작동원리는 Temp Tablespace에 임시로 저장한 후에 작업후 반환하는 방식이라 버퍼캐시에 올려사용하게 되고, 이는 메모리사용량 증가로 이어진다. 이런흐름은 전반적인 시스템에 매우 부담스러운 방식이다.
데이터가 적고 간단한 쿼리문은 DISTINCT를 사용하고,
데이터가 많고 시스템에 부하를 줄 수 있는 쿼리문은 Group by절을 이용하는 좋다고 생각한다.
실제로 데이터가 적고 간단한 쿼리문으로 DISTINCT와 비슷한 기능인 GROUP BY의 Runtime과 Cost를 Plan으로 측정해보면 같은 결과를 출력하는 것을 확인할 수 있다. (Oracle기준)
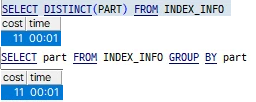
Temp Tablespace사용이나 DISTINCT 안좋은 방식이고 별로인 기능이라는 것이 아닌,
필요 상황을 고려해야 적절한가? 에대한 판단이후에 사용하자는 얘기이다.
이와같은 이유에서 Temp Tablespace를 사용하는 방식인 WITH ~ AS 임시테이블 사용도 지양하는 흐름이다.
4) 과도한 hint 사용자제
SQL Query를 통해 필요한 데이터를 가져올 때, ORDER BY 혹은 INDEX의 옵티마이저에 따라
데이터의 정렬과 순서 및 분포가 정해진다. 이와 같은 작업 혹은 계획은 규칙 기반, 비용 기반 이 두 가지 기반을 따라 최적화 하여 수립된다.
여기서 Hint란 위와 같은 작업 혹은 계획을 개발자 임의로 변경하거나 유도하는 것을 의미한다.
Hint는 튜닝에 있어서 핵심적인 가치이며, 효과적으로 비용 및 시간을 줄일 수 있다.
Hint는 사용하는 DBMS에 따라 다소 다르게 사용되는데,
* ORACLE, MariaDB, MSSQL, MySQL등 RDBMS에서 Hint는 비슷한 개념을 가지고 있지만
약간씩 사용하는 방법이나 문법이 다르다.
가장 중요한 개념인 Optimizer에게 SQL문 실행을 위한 데이터를 Scan하는 경로, 조인하는 방법들을 알려주기 위해 사용자가 SQL구문에 작성해, 직접 최적의 실행 경로를 작성해 주는 것이라고 가지고 가면 좋을 것 같다.
-
HINT로 액세스 경로, 조인 순서, 병렬 및 직렬 처리, Optimizer의 목표를 변경 가능 및 데이터 값 정렬의 경우에 Hint처리 가능
-
드라이빙 테이블(Join시 먼저 액세스 되어 Access path를 주도하는 테이블)을 원하는 대로 선정도 가능하다.
📢 그럼 이러한 좋은 기능의 사용을 자제하라는 이유는 무엇이냐?
hint에 기능은 위에서 설명한 것처럼 쿼리에서 중요한 데이터 흐름의 구조를 강제적으로 바꾸는 기능을 가지고 있기에 해당 테이블의 높은 이해도 와 SQL에 대한 전문적인 지식을 요구한다. 또한 이러한 배경을 가지고 있다고 해서 끝나는 것이 아니라 Application이나 DB상에서 올바른 데이터인지 검증을 추가적으로 요구한다. 쿼리 실행 계획에 대한 확실한 이해를 가지고 적절한 힌트를 사용하는 것은 확실하게 성능 면에서 도움을 주지만, 단순히 “실행 속도가 더 빠르네?”라는 생각에서 힌트를 남발한다면 Data가 꼬여버리는 최악의 상황을 경험할 수 있다.
오히려 명확한 쿼리 실행 계획을 가지고 있지 않다면,
힌트 사용보다는 기존 자체 옵티마이저를 따라가는 것이 더 효율적일 수 있다.5) 부정형 문법보다는 긍정형 문법을 사용
- 부정형 표현 : <>, NOT BETWEEN, NOT LIKE, NOT IN
- 긍정형 표현 : =, BETWEEN, LIKE, IN
SQL Query Tuning을 하는 관점에서 데이터 집합의 처리 범위가 좁고, 데이터 집합이 작을수록 유리하기 때문에 포괄적인 부정형 표현보다는 한정적으로 처리하는 긍정형 표현이 이에 적합하다.
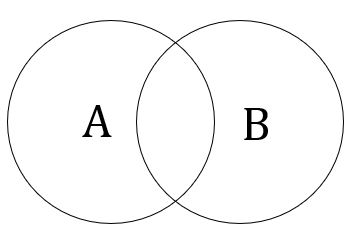
A <> B : A^c = U
A NOT BEWTEEN B AND (B+1) : B^c = U
A NOT LIKE B : B^C = U
A NOT IN B : B^C = U
A = B : A∩B
A BETWEEN B AND (B+1) = ~B
A LIKE B = B
A IN (B) = B식에서와 같이 부정형 표현은 대부분 U = (A∪B)^c에 수렴한다.
반대로 긍정형 표현은 한정된 값에 수렴하는 이를 통해,
포괄적이고 한정적으로 데이터 집합을 표현하는 긍정형 표현이 Tuning하는 과정에 유리하다는 것을 알 수 있다.
6) Scan & Table Access(Random Access) 최소화하기
쿼리 로직을 설계하는 과정에서 필요한 테이블을 스캔하거나 Join하는 경우가 필연적이다.
필요할 때마다 설계시 같은 테이블을 자주 호출할 수 도 있겠지만 SQL Plan을 통해 확인해 본다면 table을 scan또는 Access하는 경우 해당 작업에 대해 Cost가 부여된다.
더 나아가 table 전체에 대해 조건없이 Access하는 경우라면 부여되는 Cost는 더욱 커진다. 이러한 경우 table크기에 따라 처리속도가 느려지는 현상으로 이어진다.
이를 방지하기 위해서 테이블호출은 최소화하여 한번 호출시에 조건과 조인을 통해 필요한 데이터만 추출하는 설계를 계획해 불필요한 Cost와 Run time 낭비를 줄여야한다.
예시를 보자,
아래와 같이 state_idx, total_idx, user_idx의 임시 테이블로 존재하는 경우
Best Case와 Worst Case를 보면 둘다 일자별 사용자 통계, byte처리 통계, 시작 state(std), 종료 state(etd) 통계를 내고 있다.
둘다 같은 결과를 출력하지만 Worst Case는 조인을 제대로 활용하지 못해 서브쿼리상에서 불필요한 테이블 호출이 발생한 경우이다. 반면 Best Case는 테이블을 한번씩 호출 후 필요한 조건처리후 Group by하여 3개의 테이블을 Join후 통계를 내고 있다.
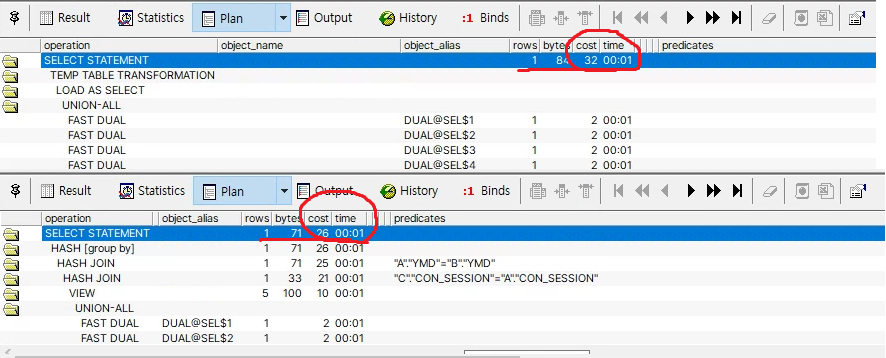
Worst Case(COST/TIME) : 32/00:01
Best Case(COST/TIME) : 26/00:01
→ example table이라서 데이터가 작아 차이가 미미하지만,
Best보다 Worst의 Cost의 수치가 더 높은걸 볼 수 있다.----------------
-- Table part --
----------------
WITH
state_idx AS (
SELECT '20220501' ymd, '31as3-dk21' con_session, 'in' state, 1200 byte, '2022-05-01-14-05-11' sys_time FROM dual UNION ALL
SELECT '20220501' ymd, '10234-em12' con_session, 'out' state, 400 byte, '2022-05-01-14-12-44' sys_time FROM dual UNION ALL
SELECT '20220501' ymd, '12aaa-dbb2' con_session, 'in' state, 1700 byte, '2022-05-01-14-16-05' sys_time FROM dual UNION ALL
SELECT '20220502' ymd, '1ams4-rrg' con_session, 'in' state, 3300 byte, '2022-05-01-08-30-00' sys_time FROM dual UNION ALL
SELECT '20220502' ymd, 'd0120-bbv' con_session, 'in' state, 5900 byte, '2022-05-01-08-31-00' sys_time FROM dual
),
total_idx AS (
SELECT '20220501' ymd, '500' std, 1430 etd, '2022-05-01-16-30-01' last_run_time FROM dual UNION ALL
SELECT '20220502' ymd, '1430' std, 745 etd, '2022-05-02-16-30-00' last_run_time FROM dual
),
user_idx AS (
SELECT 'MANCAE' id, '31as3-dk21' con_session FROM dual UNION ALL
SELECT 'CAEHYUN' id, '10234-em12' con_session FROM dual UNION ALL
SELECT 'JUNGHYEN' id, '12aaa-dbb2' con_session FROM dual UNION ALL
SELECT 'SOMIN' id, '1ams4-rrg' con_session FROM dual UNION ALL
SELECT 'EUNCAE' id, 'd0120-bbv' con_session FROM dual
)
----------------
-- Quert part --
----------------
-- BEST Case
SELECT
To_Char(To_Date(a.ymd),'YYYY-MM-DD') YMD,
Round(Avg(byte),0) avg_byte,
Max(b.std) STD,
Max(b.etd) ETD,
Max(b.last_run_time) LAST_TIME,
Count(c.id) user_cnt
FROM STATE_IDX a, TOTAL_IDX b, USER_IDX c
WHERE 1=1
AND a.ymd = b.ymd
AND c.con_session = a.con_session
GROUP BY a.ymd
--Worst Case
SELECT To_Char(To_Date(a.ymd),'YYYY-MM-DD') YMD, a.avg_byte,
b.std, b.etd, b.last_run_time, c.user_cnt
FROM
( SELECT ymd, Round(Avg(byte),0) avg_byte FROM state_idx GROUP BY ymd ) a
, total_idx b
, (
SELECT a.ymd, Count(b.id) user_cnt FROM state_idx a, user_idx b
WHERE 1=1
AND a.con_session = b.con_session
GROUP BY a.ymd
) c
WHERE 1=1
AND b.ymd = a.ymd
AND c.ymd = a.ymd
;7) Sort, Hash작업은 최소화(상위쿼리에서 한번에 처리)
Sort작업과 Hash작업은 각각 다른의미에서 최소화를 말하고 있다.
Sort 작업을 보면 대표적으로 Order by가 있고, 산술적으로 보면 정렬작업은 O(n)이고, 이는 데이터 보유량에 비례하여 처리시간이 증가한다.
예를 들어 메인쿼리안에 서브쿼리가 있고 각각의 쿼리에서 order by작업을 한다고 생각해보자, 이는 정렬에 의한 순서로만 보면 O(n)+O(n)이고 산출데이터가 적다고 가정하면 처리시간은 >= O(n)+O(n)가 된다. 그렇기에 각 테이블 고유의 인덱스를 이용해 최종적으로 정렬하는 것이 Tuning하는 측면에서 효과적이라 생각한다.
Run Time(처리시간) >= O(n)+O(n) → 메인쿼리안에 서브쿼리가 있고 각각의 쿼리에서 order by작업Hash작업은 해싱을 의미하는데, 이는 해싱이란 임의의 길이의 값을 해시함수(Hash Function)를 사용하여 고정된 크기의 값으로 변환하는 작업을 말한다.
또한 해시함수를 이용한 해시테이블은 해시함수를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장하는 자료구조를 말한다. 기본연산으로는 탐색(Search), 삽입(Insert), 삭제(Delete)가 있다.
우선 해시테이블의 문제는 데이터 베이스의 규모가 커질 경우,
Oracle 기준으로 ORA_HASH 사용시 중복되는 해시가 발생하여
해시 충돌사태가 발생 할 수 있다.
이는 Oracle DB에 국한되어 발생하는 문제가 아닌 Hash작업을 진행하는 RDBMS에서 발생한다.
물론 해시충돌(Hash Collision)을 예방하기 위해 아래와 같은 방법을 사용한다.
[해시 테이블의 구조 개선]
- 체이닝 (Chaining)
- 선형 탐사(Linear Probing)
- 제곱 탐사(Quadratic Probing)
- 이중 해싱(Double Hashing)
[해시 함수 개선]
- 나눗셈 법(Division Method)
- 곱셈법(Multiplication Method)
- Standard_hash와 같은 표준 방식 해시 값 생성함수 사용이러한 Hash처리는 보안측면에서 DB에 좋을 수 있지만, 모든 예외처리에 대응하기 까다롭고 충돌사태도 방지해야하기때문이다. 많은 분석이 이루어지고, 이를 기반으로 Hash작업을 설계하고 예외처리까지 깔끔하게 테스트하지 못한다면 이러한 Hash작업은 지양하는 것이 개인적으로 맞다고 생각한다.
참고자료
https://docs.oracle.com/en/database/oracle/oracle-database/23/tgsql/index.html
https://baeharam.netlify.app/posts/data%20structure/hash-table
https://jaehoney.tistory.com/193
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=platinasnow&logNo=220198302742
