논문 출처: https://arxiv.org/abs/2002.05709
Abstract
-
visual 표현들을 학습하는 contrastive learning 을 위한 SimCLR이라는 프레임워크를 소개함
-
실험한 다양한 components들을 조합하여 이전의 self-supervised/semi-supervised leraning 방법론들의 성능을 뛰어넘음
1. Introduction
-
효과적인 visual 표현들을 사람의 개입 없이 학습시키려는 시도는 오래 전부터 있어왔음
-
이러한 시도는 대게 generative or discriminative한 접근이었지만 연산량이 과하거나 huristic한 design을 요구하는 등 단점이 있음
-
SimCLR의 경우 이전 연구의 성능을 뛰어넘을 뿐만 아니라, 단순하고 메모리 효율적임
2. Method
2.1 The Contrastive Learning Framework
-
N개의 데이터와 각 데이터를 augment한 데이터를 합쳐 총 2N개의 minibatch 데이터
-
한 쌍과 나머지 2(N-1) 개의 데이터는 negative example 관계가 됨
-
SimCLR은 아래의 주요한 구성요소들로 이루어져 있음
1) stochastic data augmentation
기존 이미지와 augmentation로 생성된 이미지를positive pair로 묶음
- random crop + resize
- random color distortion
- random Gaussian blur
2) 신경망 base encoder
augmented된 data example들의 representation 벡터를 추출
3) 신경망 projection head
representation들을 contrastive loss가 적용되는 공간으로 맵핑
4) contrastive loss function
contrastive prediction task를 위해 정의됨
2.2 Traning with Large Batch size
-
batch size를 256부터 8192까지 다양하게 함
-
학습을 안정시키기 위해 LARS optimizer 사용
-
또한, 같은 batch 안의 sample을 통한 cheating을 방지하기 위해 Global batch norm/shuffling data/replacing BN with layer norm 등 적용
2.3. Evaluation Protocol
Dataset and Metrics
-
unsupervised pretraining을 위해 ImageNet을 주로 사용하고 CIFAR-10도 사용
-
pretrained된 결과를 테스트하기 위해 linear evaluation protocol 사용
-
semi-supervised과 transfer learning의 SOTA와 비교
Default setting
-
Base encoder network : RestNet-50
-
Projection head : 2-layer MLP
-
Loss func : NT-Xent
-
Optimizer : LARS
-
learning rate : 4.8(= 0.3 × BatchSize/256)
-
batch size : 4096
-
epochs : 100
-
warmup : linear warmup
-
scheduler : cosine decay schedule without restarts
3. Data Augmentation for Contrastive Representation Learning
-
기존에 data augmentation은 많이 사용되었지만 contrasive prediction task를 위한 체계적인 방법은 아니었음
-
기존 연구들은 contrasive prediction task를 정의하기 위해 대게 architecture을 바꾸는 시도를 하지만 복잡함
-
본 논문은 random crop + resize를 통해 이러한 복잡성을 제거함
-
augmentation family들을 늘리고 확률적으로 구성함으로써 더 많은 contrasive prediction task를 정의할 수 있음
3.1. Composition of data augmentation operations is crucial for learning good representations
-
data augmentation의 결과를 체계적으로 조사하기 위해 다양한 실험을 함
-
ImageNet처럼 이미지 사이즈가 서로 다를 경우 cropping을 하지 않으면 실험이 어려움
-
본 논문의 저자들은 이를 해결하기 위해 random crop 후 이미지들을 동일한 size로 resize함
-
실험 결과, 어떠한 augmentation도 하나로는 충분치 않음
-
augmentation들을 조합할 경우 task는 어려워지지만 representation quality는 올라감
-
random crop + random color distortion이 성능이 좋은데, crop만 할 경우 주변 color가 비슷하기 때문이라고 추측됨
3.2. Contrastive learning needs stronger data augmentation than supervised learning
- unsupervised contrasive learning의 경우 supervised learning에서보다 strong data augmentation을 통해 더 큰 성능향상을 달성함
4. Architectures for Encoder and Head
4.1. Unsupervised contrastive learning benefits (more) from bigger models
- unsupervised contrasive learning의 경우 supervised learning에서보다 bigger model을 통해 더 큰 성능향상을 달성함
4.2. A nonlinear projection head improves the representation quality of the layer before it
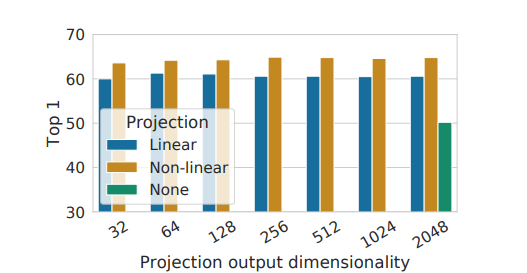
-
projection head 구조를 Linear / Non-Linear / None으로 나누어 실험함
-
Non Linear의 경우 가장 성능이 높았음
-
output dimension과 상관없이 비슷한 결과가 나옴
-
hidden layer가 projection head 앞에 있을 때의 경우 뒤에 있을 때보다 성능 향상에 유리한데, layer가 뒤에 있을 경우 augmentation 등에 의해 정보 손실이 발생하기 때문으로 추측됨
5. Loss Functions and Batch Size
5.1. Normalized cross entropy loss with adjustable temperature works better than alternatives
-
NT-Xent loss func을 다른 loss func들과 비교함
-
l2 norm along with temperature(?)가 다른 example들을 잘 weight하고, 적절한 temperature는 모델이 hard negatives를 통해 더 잘 학습하게 함
-
cross-entropy를 제외한 다른 objective func의 경우, negativs를 상대적 hardness에 따라 weight하지 않아 직접 semi-hard negative mining을 적용해야 함(?)
-
결과적으로 NT-Xent loss를 사용했을 때 가장 성능이 좋았음
-
또한, l2 normalization과 적절한 temperature scaling이 없을 경우 성능이 크게 하락했음
5.2. Contrastive learning benefits (more) from larger batch sizes and longer training
-
unsupervised learning의 경우 batch size가 크고 training time이 길 때 성능 향상폭이 큼
-
이는 negative example들을 늘려주기 때문임
Conclusion
-
본 논문에서는 contrastive visual representation learning을 위한 SimCLR이라는 framework를 소개함
-
실험한 components들을 잘 조합한 결과, self-supervised, semi-supervised, 그리고 transfer learning을 위한 이전 방법론들의 성능을 뛰어넘을 수 있었음
-
기존의 supervised learning과 다른 점은 1) data augmentation 구성, 2) network 끝단에 nonliniear head 사용, 3) NT-Xent loss 함수 등임
