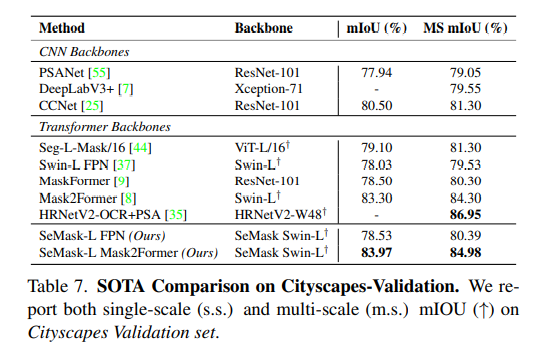
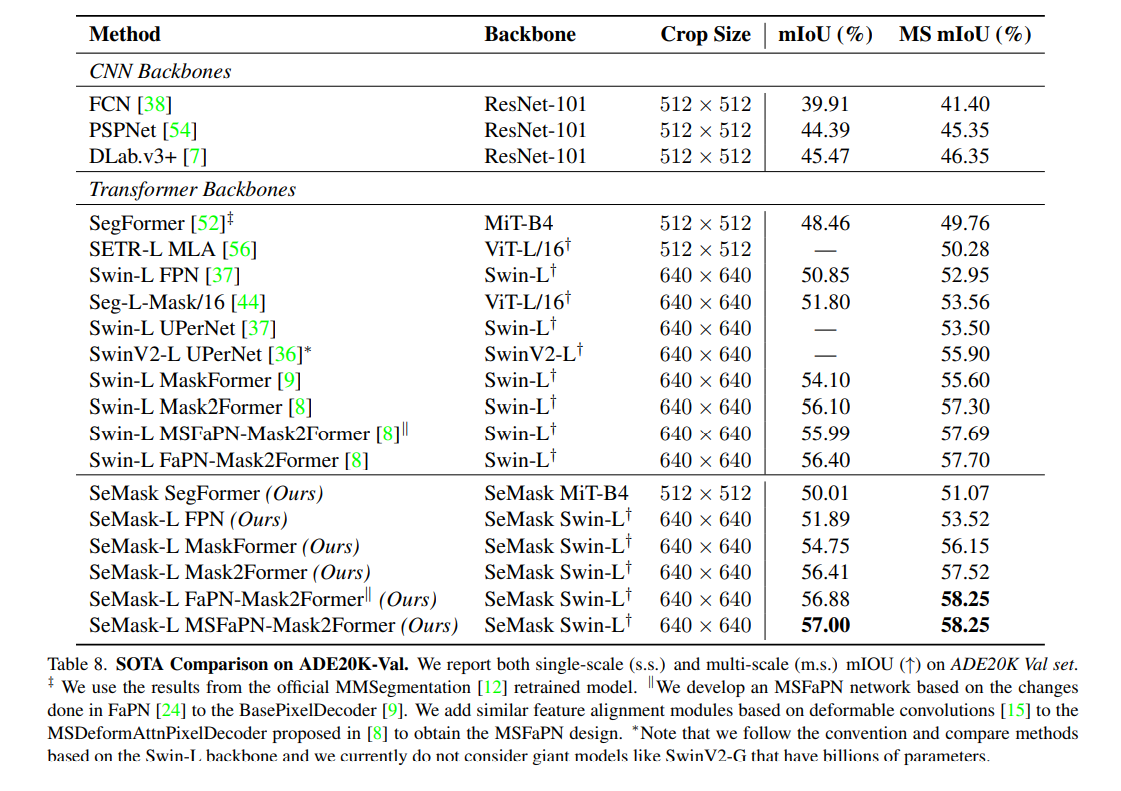
논문 출처: https://arxiv.org/abs/2112.12782
Abstract
-
Semantic segmentation task에서 transformer 구조를 사용할 경우, encoder 부분에 pretrained backbone을 가져와 finetuning하는 것이 일반적이었음
-
하지만 그럴 경우 이미지가 제공하는 semantic context가 손실될 우려가 있다고 함
-
본 논문에서는, semantic attention 연산을 통해 semantic 정보를 통합하는 SeMask라는 프레임워크를 제안함
Introduction
-
Semantic segmentation의 encoder로 pretrained된 vision transformers를 finetuning하여 사용할 경우, 초기의 attention layers가 local information을 잘 통합할 수 있음
-
하지만 finetuning 시
dataset의 크기가 줄어든다는 점과, classification task와 segmentation task에서semantic classes의 양과 특성이 다르다는 점 때문에semantic context를 이용할 수는 없음 -
기존 연구들이 많이 있었지만 한계가 존재했음
-
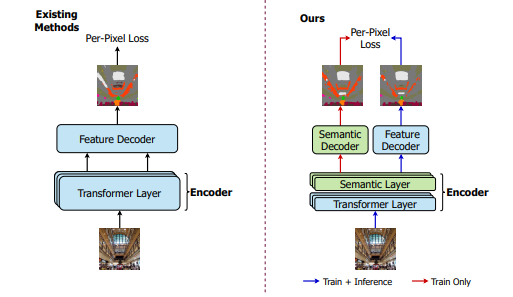
본 논문에서 제안하는 SeMask 프레임워크는 ImageNet에서 pretrained된 transfomer model을 encoder로 사용하는데, 각 transformer layer 위에
sematic layer를 추가로 두어 semantic 정보를 통합함 -
또한,
semantic segmentation에 특화된 decoder를 사용하며,별도의 decoder를 추가적으로 사용하여 모든 stage에서의semantic maps을 저장함
Method
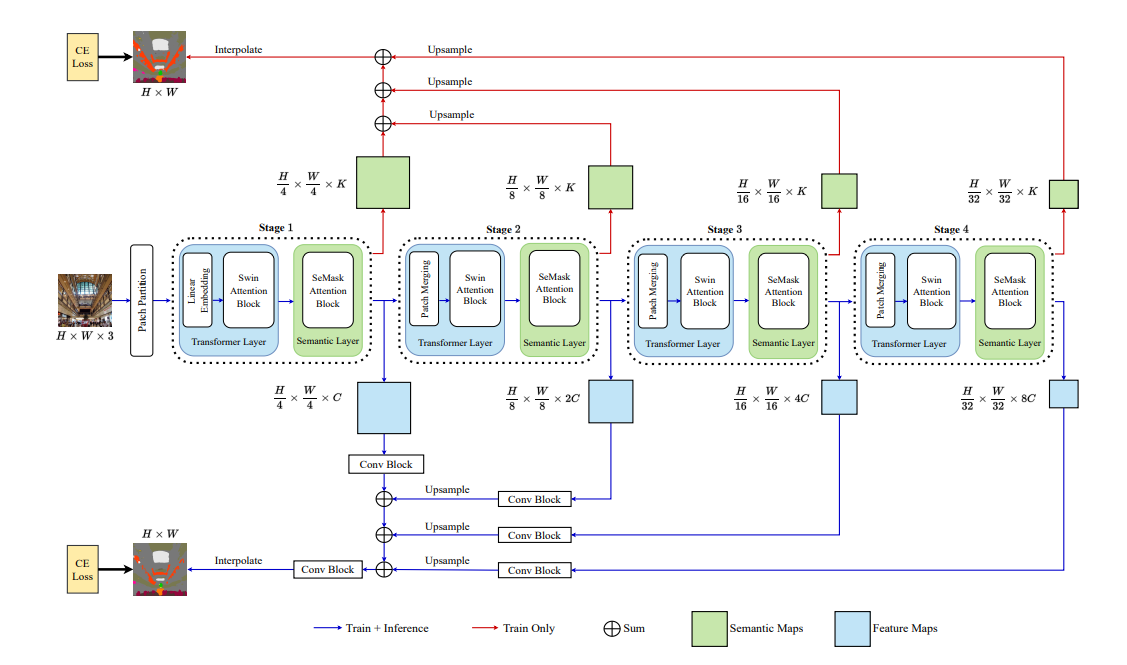
-
input으로 HxWx3의 image가 들어가고, 4x4 사이즈의 patch로 나뉘어짐
-
patch들은 hierarchical vision transformer(본 논문에서는 swinT) encoder에 token으로 들어감
-
encoding은 총 4 steps를 거치는데, 각 step에서는 개의 swin transformer block을 가진
transformer layer와 개의 SeMask Attention block을 가진Semantic layer로 이루어짐 -
각 Semantic layer는
transformer layer의 결과를 input으로받아intermediate semantic-prior map과 semantically masked features를 반환함 -
두 layer를 합쳐 SeMask block으로 부르며, 각 feature과 semantic-prior maps는 patch merging layer를 통과하며 사이즈가 1/4부터 1/32까지 1/2씩 줄어듬
-
각 단계의
features는 semantic-FPN decoder을 활용해 aggregate 되어 최종적으로dense-pixel prediction을 수행함 -
각 단계의
semantic-prior map은 별도의 light weightsemantic decoder에 의해 aggregate 되어 학습 중에network의 semantic-prior을 예측하고, feature extraction를 도와 결과적으로 성능 향상에 기여함 -
두 가지 decoder의 결과는 모두
weighted per-pixel cross-entropy loss를 적용받음
Semask Encoder
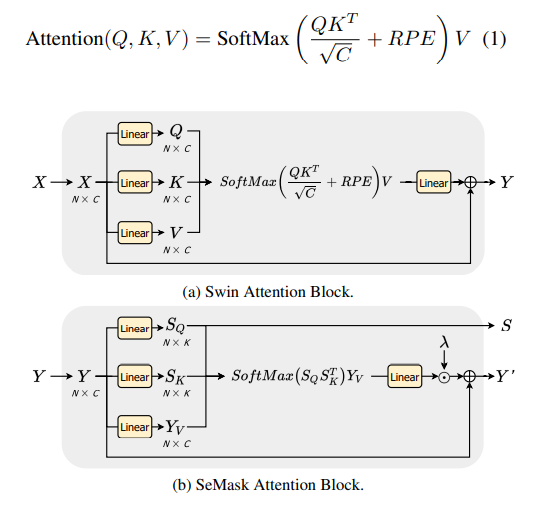
Transformer layer
-
image에서
image-level context 정보를 추출 -
encoder의 첫 단계에는 linear embedding을 두어 patch token의 feature dimension을 맞춤
-
위 이미지에서 는 transformer layer block의 input feature를 나타내며 Q, K, V는 각각 query, key, value를 의미
-
RPE는 Relative Positional Embedding으로 NxN 크기이고, N은 window size ** 2임
-
transformer layer로부터 나온 feature 는 같은 stage의 semantic layer의 input으로 들어감
Semantic layer
-
feature에서
semantic 정보를 추출하여semantic-priors를 만들고 그것을 토대로features를 업데이트함 -
input feature 를 Semantic Query(), Semantic Key(), Feature Value()로 나눔
-
다음 식을 통해 segmentation score를 계산함
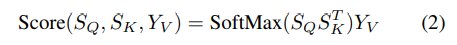
-
score에 SoftMax를 취한 뒤 linear layer을 거치고 를 곱해주어, semantic 정보가 풍부한
SEmanticallyMasked feature로 업데이트함 -
는 이후에 semantic-prior map을 예측하는 데 사용됨
Decoder
-
각 단계의 features들을 일련의 연산(convolution, bilinear upsampling, sum)을 통해 합쳐 segmentation에 적절한 decoder을 만듬
-
추가적으로 경량의 decoder를 사용해 학습 시 encoder의 각 단계에 존재하는 semantic-prior map에 ground truth supervision을 제공함
-
이는 semantic-prior map를 예측하고 성능을 개선하는데 도움을 줌
Loss function
-
Total Loss는 로 계산됨
-
는 main decoder인 Semantic-FPN decoder에서의 예측으로부터 계산됨
-
는 경량의 decoder에서의 semantic-prior 예측으로부터 계산됨
Experiments
Transformer models
-
Swin Tiny/Small/Base/Large 사용
-
22k pretrained on ImageNet
-
resolution : 224x224 or 384x384
Data Augmentation
-
mean subtraction image scaling(0.5, 0.75, 1.0, 1.25, 1.5, 1.75 중 임의 추출한 비율로)
-
random left-right flipping
-
color jittering
Training setting
-
optimizer :
AdamW -
base learning rate : or
-
learing rate scheduler :
poly -
learning rate decay
-
linear warmupfor 1,500 iterations -
batch size 16 or 8
Others
-
ADE20K과 Cityscapes dataset 사용
-
mIOU 사용