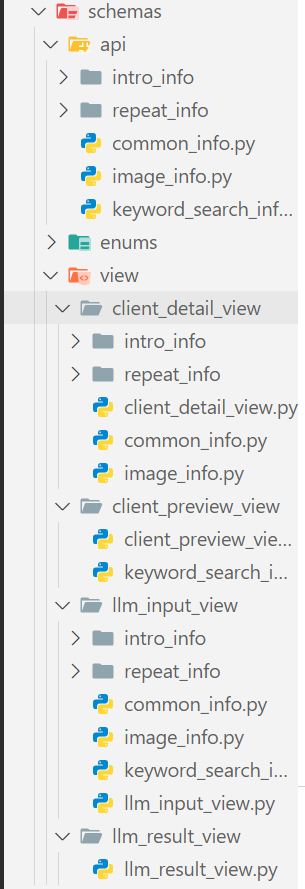
🟥 나는 아래와 같이 스키마들을 설계했다.
내가 설계한 스키마는 크게 3가지로 나눌 수 있다.
API 수신 스키마, View 전처리 스키마, 최종 View 조립 스키마이다.
-
① API 수신 스키마
schemas/api/하위의 파일들 (api/intro_info/festival.py,api/repeat_info/course.py,api/keyword_search_info.py,api/common_info.py등)에 위치하며, TourAPI 응답 데이터를 그대로 매핑 받는다. -
② View 전처리 스키마
view/llm_input_view/intro_info/festival.py,view/llm_input_view/repeat_info/default.py,view/llm_input_view/keyword_search_info.py,view/client_preview_view/keyword_search_info.py,view/client_detail_view/repeat_info/course.py,view/client_detail_view/common_info.py등에 위치한다.
이스키마들은 ① API 수신 스키마에서 필요한 필드만 정의하여, 이후 ③ 최종 View 조립 스키마의 필드로 사용된다. -
③ 최종 View 조립 스키마
client_detail_view.py,llm_input_view.py,client_preview_view.py,llm_result_view.py총 4개가 존재하며, 여러 스키마들을 하나로 통합한 스키마이다.
🟥 detailCommon1 API로 어떤 흐름으로 스키마들이 사용되는지 설명해 보겠다!
1. TourAPI 응답 수신 → Pydantic 변환
위치: schemas/api/common_info.py
이 클래스는 TourAPI의 detailCommon1 응답 원형을 그대로 받음.
2. 최종 통합 View 스키마의 필드 만들기
위치: schemas/view/client_detail_view/common_info.py
위 API 응답의 일부 필드만 정의 되어 있다.
schemas/api/common_info.py의 데이터를 받아서 일부만 사용함
이 클래스는 다음 스키마의 필드로 쓰임
3. 최종 통합 View 스키마로 포장
위치: schemas/view/client_detail_view/client_detail_view.py
클래스: ClientDetailView
이전 스키마 타입의 필드도 포함되어 있다.
프론트엔드에서는 이 구조를 그대로 받음
🟥 따라서 plango 프로젝트에서는 dict를 Pydantic 스키마로 어떻게 받을지, 하나의 스키마를 다른 하나의 스키마로 어떻게 받을지, 여러 스키마들을 하나의 스키마로 어떻게 받을지 고민해 봐야 됐다!
Q. dict를 Pydantic 스키마로 어떻게 받을까?
1. 기본 개념: dict → Pydantic 모델 변환
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
# 외부에서 온 dict 데이터
data = {"name": "성민", "age": 25}
# dict를 Pydantic 모델로 변환
user = User(**data)
print(user.name) # "성민"
print(user.age) # 252. 중첩된 dict도 가능
class Address(BaseModel):
city: str
zip_code: str
class User(BaseModel):
name: str
address: Address
# 외부에서 온 중첩된 dict 데이터
data = {
"name": "성민",
"address": {
"city": "서울",
"zip_code": "12345"
}
}
user = User(**data)
print(user.address.city) # "서울"- 중첩된 dict 구조도 자동으로 내부 모델로 매핑된다!
3. 리스트 안에 dict가 있을 때
from typing import List
class Item(BaseModel):
name: str
price: float
class Cart(BaseModel):
items: List[Item]
data = {
"items": [
{"name": "사과", "price": 1.2},
{"name": "바나나", "price": 0.8}
]
}
cart = Cart(**data)
print(cart.items[0].name) # "사과"- 리스트 안의 dict도 자동으로 각각
Item모델로 변환됨
Q. dict 필드수와 스키마의 필드수가 달라도 될까?
A:
결론부터 말하면:
항상 같을 필요 없습니다.
1. dict에 필드가 더 많아도 괜찮다
from pydantic import BaseModel
class User(BaseModel):
name: str
# 외부에서 온 dict 데이터
data = {"name": "성민", "age": 25} # dict는 더 많은 필드 포함
user = User(**data) # ✅ OK
print(user) # → name='성민'age는User스키마에 정의되어 있지 않기 때문에 무시됨- 기본적으로 Pydantic은
extra = "ignore"설정이 적용됨
2. dict에 필수 필드가 빠지면 → ❌ 오류
class User(BaseModel):
name: str
age: int
data = {"name": "성민"} # age 빠짐
user = User(**data) # ❌ ValidationError 발생- 필수 필드(
age)가 없으면 오류 발생 - 선택 필드(
Optional)는 없어도 OK
3. 선택 필드인 경우는 없어도 된다
from typing import Optional
class User(BaseModel):
name: str
age: Optional[int] # 선택
data = {"name": "성민"} # age 없음
user = User(**data) # ✅ OK
print(user.age) # → None
Optional[int]는 사실상int | None과 동일하다. v2에서는 후자가 더 선호된다.
# v1 from typing import Optional age: Optional[int]# v2 age: int | None
Q. a스키마를 b스키마로 받을 수 있을까?
a스키마와 b스키마가 있을때, a스키마를 b스키마로 받을 수 있을까?
이때 B스키마는 A스키마의 일부 필드만 사용한 것이다.
예제: A 스키마에서 B 스키마로 매핑
from pydantic import BaseModel
# A스키마: 원본
class A(BaseModel):
id: int
name: str
age: int
email: str
# B스키마: A스키마의 일부 필드만 사용
class B(BaseModel):
id: int
name: str
a = A(id=1, name="성민", age=26, email="test@example.com")
# ✅ A → B 스키마로 매핑 (필드 겹치는 것만 복사됨)
b = B(**a.dict()) # or B.parse_obj(a)
print(b)결과
id=1 name='성민'Pydantic v1에서는
.dict()사용, v2부터는.model_dump()사용 권장# v1 b = B(**a.dict())# v2 b = B(**a.model_dump())
Q. dict() 왜 사용하는거지?
A:
B(**a.dict()) 는 A스키마의 값을 dict로 변환해서, B스키마에 맞는 필드만 골라서 생성하는 방식이다.
dict()는 바로 그 중간 단계를 수행하는 함수이다 !!!
왜 a.dict()를 쓰는가?
1. a는 Pydantic 모델 → **a는 불가능
a는 BaseModel의 인스턴스이기 때문에, 바로 B(**a)처럼 언패킹해서 넣으면 에러가 난다.
대신a를 a.dict()를 사용하여 일반적인 dict 형태로 변환한 후,
그것을 언패킹(**)해서 넘기는 것은 가능하다.
a.dict()
# 👉 {"id": 1, "name": "성민", "age": 26, "email": "test@example.com"}이걸 B(**...)로 넘기면 B의 필드(id, name)만 추려서 자동으로 매핑된다.
Q. 언패킹은 뭐지?
언패킹(unpacking)은 묶여 있는 값을 하나씩 풀어서 사용하는 것이다.
Python에서 *(리스트, 튜플), **(딕셔너리)에 주로 쓰인다.
간단한 예시
1. 리스트 언패킹 (*)
numbers = [1, 2, 3]
print(*numbers) # 👉 1 2 3*numbers는 리스트 [1, 2, 3]을 각각 1, 2, 3으로 풀어줍니다.
2. 딕셔너리 언패킹 (**)
data = {"name": "성민", "age": 6}
def show_info(name, age):
print(f"{name}은 {age}살입니다.")
show_info(**data)
# 👉 성민은 6살입니다.**data는 name="성민", age=6처럼 키=값 형태로 풀어줍니다.
아까전 위에서
B(**a.dict())도 딕셔너리 언패킹의 한 예!
즉,{"id":1, "name":"성민"}→id=1, name="성민"으로 풀어서 전달하는 것!
Q. a,b,c,d 스키마를 e 스키마로 받을 수 있을까?
A:
a,b,c,d 스키마를 e 스키마로 받을 수 있을까?
이때 e 스키마에는 a,b,c,d 타입의 필드 총 4개가 정의되어 있다.
from pydantic import BaseModel
class A(BaseModel):
name: str
class B(BaseModel):
age: int
class C(BaseModel):
email: str
class D(BaseModel):
active: bool
class E(BaseModel):
a: A
b: B
c: C
d: D예제1: A, B, C, D → E로 조립
a = A(name="성민")
b = B(age=26)
c = C(email="test@example.com")
d = D(active=True)
e = E(a=a, b=b, c=c, d=d) # ✅ 스키마 객체 조립
print(e)예제2: dict로 조립해도 OK
e = E(
a={"name": "성민"},
b={"age": 26},
c={"email": "test@example.com"},
d={"active": True}
)- Pydantic은 내부적으로 타입 검사해서,
dict→해당 스키마로 자동 변환
예제3: A, B, C, D가 이미 존재할 때
e = E(a=a_obj, b=b_obj, c=c_obj, d=d_obj)이미 각 스키마 인스턴스를 들고 있다면 그냥 그대로 넘기면 된다.
Q. 리스트 안에 dict 데이터들, 스키마로 받을 수 있을까?
외부에서 리스트 안에 dict 데이터들이 있는 형식으로 들어올 때, 이를 Pydantic 스키마로 처리하는 방법에 대해 알아 보자.
상황 가정
# Pydantic 모델 정의
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int외부에서 받는 데이터 예시
# 리스트 형태의 dict들
data = [
{"name": "성민", "age": 25},
{"name": "세민", "age": 24},
{"name": "정후", "age": 26}
]방법 1: 리스트 안에 각각 Pydantic 모델로 변환하기
# 각 dict를 User 모델로 변환
users = [User(**item) for item in data]
# 확인
for user in users:
print(user.name, user.age)**item을 통해 dict 데이터를User모델에 언패킹해서 각각 변환
방법 2: 전체를 감싸는 스키마로 정의해서 받기
리스트 자체를 하나의 필드로 가진 스키마를 만들 수도 있다.
from typing import List
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
class UsersPayload(BaseModel):
users: List[User]외부에서 오는 데이터
incoming_data = {
"users": [
{"name": "성민", "age": 25},
{"name": "혜민", "age": 24}
]
}사용
payload = UsersPayload(**incoming_data)
# 접근 방법
for user in payload.users:
print(user.name, user.age)방법 3: FastAPI에서 요청 바디로 받을 경우 예시
from fastapi import FastAPI
from typing import List
from pydantic import BaseModel
app = FastAPI()
class User(BaseModel):
name: str
age: int
@app.post("/users/")
async def create_users(users: List[User]):
for user in users:
print(f"이름: {user.name}, 나이: {user.age}")
return {"message": f"{len(users)}명의 유저 정보가 출력되었습니다."}클라이언트가 보내는 JSON
[
{"name": "성민", "age": 25},
{"name": "혜민", "age": 24}
]