4.1 사라진 SQLException
4.1.1 초난감 예외처리
예외 블랙홀
try {
...
} catch(SQLException e) {
}모든 예외는 적절하게 복구되든지 혹은 작업을 중단시키고 운영자 또는 개발자에게 분명하게 통보되어야 한다.
굳이 예외를 잡아서 취할 조치가 없다면, 메소드 밖으로 throw하고 자신을 호출한 코드에 예외처리 책임을 전가하라.
무의미하고 무책임한 throws
public void method1() throws Exception {
method2();
...
}
public void method2() throws Exception {
method3();
...
}
public void method3() throws Exception {
...
}적절한 처리를 통해 복구될 수 있는 예외상황도 제대로 다룰 수 있는 기회를 박탈당한다.
4.1.2 예외의 종류와 특징
■ Error
java.lang.Error클래스의 서브클래스- 시스템에 뭔가 비정상적인 상황이 발생했을 경우
- 주로 자바 VM에서 발생
- 애플리케이션 코드에서는 잡을 수 없음
■ Exception과 체크 예외
java.lang.Exception의 클래스와 그 서브클래스- 개발자들이 만든 애플리케이션 코드의 작업 중에 예외상황이 발생했을 경우
- 체크 예외
Exception클래스의 서브클래스이면서RuntimeException클래스를 상속하지 않은 것- 반드시
catch문으로 잡든지,throws를 정의하여 메소드 밖으로 던져야 한다.
- 언체크 예외
RuntimeException을 상속한 클래스
- 체크 예외
■ RuntimeException과 언체크/런타임 예외
- 주로 프로그램의 오류가 있을 때 발생하도록 의도된 것들
- 피할 수 있지만 개발자가 부주의해서 발생할 수 있는 경우에 발생하도록 만든 것
4.1.3 예외처리 방법
예외 복구
예외상황을 파악하고 문제를 해결해서 정상 상태로 돌려놓는 것
체크 예외들은 예외를 어떤 식으로든 복구할 가능성이 있는 경우에 사용
int maxretry = MAX_RETRY;
while(maxretry -- > 0) {
try {
...
return;
} catch(SomeException e) {
// 로그 출력, 정해진 시간만큼 대기
} finally {
// 리소스 반납, 정리 작업
}
}
throw new RetryFailedException();예외처리 회피
예외처리를 자신이 담당하지 않고 자신을 호출한 쪽으로 던져버리는 것
public void add() throws SQLException {
// JDBC API
}public void add() throws SQLException {
try {
// JDBC API
} catch(SQLException e) {
// 로그 출력
throw e;
}
}콜백/탬플릿처럼 긴밀한 관계에 있는 다른 오브젝트에게 예외처리 책임을 분명히 지게 하거나, 자신을 사용하는 쪽에서 예외를 다루는 게 최선의 방법이라는 분명한 확신이 있어야 함
예외 전환
발생한 예외를 그대로 넘기는 게 아니라 적절한 예외로 전환해서 던진다.
- 내부에서 발생한 예외를 그대로 던지는 것이 그 예외상황에 대한 적절한 의미를 부여해주지 못하는 경우
public void add(User user) throws DuplicateUserIdException, SQLException { try { // logic } catch(SQLException e) { if (e.getErrorCode() == MysqlErrorNumbers.EP_DUP_ENTRY) throw DuplicateUserIdException(); else throw e; } }- 중첩 예외
catch(SQLException e) { ... throw DuplicateUserIdException().initCause(e);
- 예외를 처리하기 쉽게 단순하게 만들기 위해 포장
- 예외처리를 강제하는 체크 예외를 언체크 예외인 런타임 예외로 바꾸는 경우
try { OrderHome orderHome = EJBHomeFactory.getInstance().getOrderHome(); Order order = orderHome.findByPrimaryKey(Integer id); } catch (NamingException ne) { throw new EJBException(ne); } catch (SQLException ne) { throw new EJBException(ne); } catch (NamingException ne) { throw new EJBException(ne);- 체크 예외를 계속해서 던지지 않고, 가능한 빨리 런타임 예외로 포장해 던지게 해서 다른 계층의 메소드를 작성할 때 불필요한 throws 선언이 들어가지 않도록
4.1.4 예외처리 전략
런타임 예외의 보편화
자바 환경이 서버로 이동하면서 체크 예외의 활용도와 가치는 떨어지는 중
대응이 불가능한 체크 예외라면 빨리 런타임 예외로 전환해서 던지는 것이 좋음
add() 메소드의 예외처리
public class DuplicateUserIdException extends RuntimeException {
public DuplicateUserIdException(Throwable cause) {
super(cause);
}
}SQLException을 직접 메소드 밖으로 던지지 않고, 런타임 예외로 전환하여 throw
→ throws에 포함시킬 필요가 없음
→ DuplicatedUserIdException은 명시적으로 throws에 선언
public void add(User user) throws DuplicateUserIdException {
try {
// logic
} catch(SQLException e) {
if (e.getErrorCode() == MysqlErrorNumbers.EP_DUP_ENTRY)
throw new DuplicateUserIdException(e);
else
throw new RuntimeException(e);
}
}애플리케이션 예외
애플리케이션 예외: 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에 의해 의도적으로 발생시키고, 반드시 catch해서 무엇인가 조치를 취하도록 요구하는 예외
예외상황에 대해 체크 예외로 만들어놓아 예외상황에 대한 로직 구현을 강제하도록
try {
BigDecimal balance = account.withdraw(amount);
...
} catch(InsufficientBalanceException e) {
BigDecimal availFunds = e.getAvailFunds();
...
// 잔고 출력
}4.1.5 SQLException은 어떻게 됐나?
SQLException은 복구가 가능한가?
→ 99%의 SQLException은 코드 레벨에서는 복구 불가 (원인: SQL 문법 오류, 제약조건 위반, DB서버 문제 등)
스프링 JdbcTemplate 템플릿과 콜백 안에서 발생하는 모든 SQLExcpetion을 런타임 예외인 DataAccesssException으로 포장해서 throw하여 애플리케이션 레벨에서는 신경 쓰지 않도록
→ JdbcTempate를 사용하는 UserDao 메소드에선 꼭 필요한 경우에만 런타임 예외인 dataAccessException을 사용, 그 외에는 무시
스프링 API 메소드에 정의되어 있는 대부분의 예외는 런타임 예외
4.2 예외 전환
예외 전환의 목적
1. 런타임 예외로 포장하여 굳이 필요하지 않은 catch/throws를 줄여주는 것
2. 로우레벨의 예외를 좀 더 의미 있고 추상화된 예외로 바꿔서 던지기
4.2.1 JDBC의 한계
JDBC는 자바를 이용해 DB에 접근하는 방법을 추상화된 API 형태로 정의해놓고, 각 DB업체가 JDBC 표준을 따라 만들어진 드라이버를 제공
DB를 자유롭게 바꾸어 사용할 수 있는 DB 프로그램을 작성하는 데는 두가지 걸림돌이 있다.
1. 비표준 SQL
대부분의 DB는 표준을 따르지 않는 비표준 문법과 기능도 제공
해결책
- 호환 가능한 표준 SQL만 사용하는 방법
- DB별로 별도의 DAO를 만들거나 SQL을 외부에 독립시켜서 DB에 따라 변경해 사용하는 방법
2. 호환성 없는 SQLException의 DB 에러정보
JDBC는 데이터 처리 중에 발생하는 다양한 예외를 SQLException 하나에 모두 담아버린다.
→ SQLException 안에 담긴 에러 코드와 SQL 상태 정보를 참조
But, DB별로 에러 코드는 모두 다르다.
→ getSQLState() 메소드로 예외상황에 대한 표준화된 상태 정보 확인, 하지만 신뢰할만 하지 않음
4.2.2 DB 에러 코드 매핑을 통한 전환
DB별 에러 코드를 참고해서 발생한 예외의 원인이 무엇인지 해석
스프링은 DB별 에러 코드를 분류해서 스프링이 정의한 예외 클래스와 매핑해놓은 에러 코드 매핑정보 테이블을 만들어두고 활용
<bean id="DB2" class="org.springframework.jdbc.support.SQLErrorCodes">
<property name="databaseProductName">
<value>DB2*</value>
</property>
<property name="badSqlGrammarCodes">
<value>-007,-029,-097,-104,-109,-115,-128,-199,-204,-206,-301,-408,-441,-491</value>
</property>
<property name="duplicateKeyCodes">
<value>-803</value>
</property>
<property name="dataIntegrityViolationCodes">
<value>-407,-530,-531,-532,-543,-544,-545,-603,-667</value>
</property>
<property name="dataAccessResourceFailureCodes">
<value>-904,-971</value>
</property>
<property name="transientDataAccessResourceCodes">
<value>-1035,-1218,-30080,-30081</value>
</property>
<property name="deadlockLoserCodes">
<value>-911,-913</value>
</property>
</bean>JdbcTemplate에서는 DataAccessException의 서브클래스인 DuplicateKeyException 등을 활용해 계층구조의 예외로 포장
public void add() throws DuplicateKeyException {
// logic..
}체크 예외인 DuplicateUserIdException으로 바꾸고 싶을 경우
public void add() throws DuplicateUserIdException {
try {
// logic..
} catch(DuplicateKeyException e) {
// logic
throw new DuplicateUserIdException(e);
}
}4.2.3 DAO 인터페이스와 DataAccessException 계층구조
DataAccessException은 의미가 같은 예외라면 데이터 액세스 기술의 종류와 상관없이 일관된 예외가 발생하도록
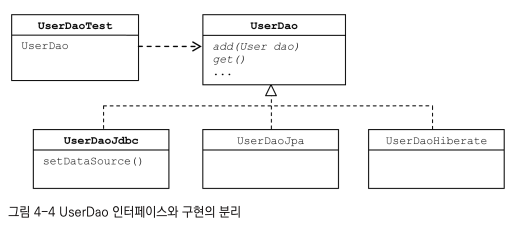
DAO 인터페이스와 구현의 분리
DAO 구현 기술마다 던지는 예외가 다른 문제점
→ DAO에서 모든 SQLException을 런타임 예외로 포장
But, 데이터 엑세스 기술이 달라지면 다른 종류의 예외 throw
데이터 액세스 예외 추상화와 DataAccessException 계층구조
스프링은 자바의 다양한 데이터 액세스 기술을 사용할 때 발생하는 예외들을 추상화하여 DataAccessException 계층구조 안에 정리
낙관적인 락킹: 같은 정보를 두 명 이상의 사용자가 동시에 조회하고 순차적으로 업데이트를 할 때, 뒤늦게 업데이트한 것이 먼저 업데이트한 것을 덮어쓰지 않도록 막아주는 기능
다음과 같이 어떤 데이터 액세스 기술을 사용했는지에 상관없이 낙관적인 락킹을 처리
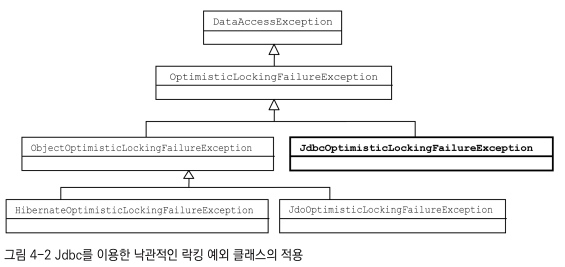
DataAccessException 예외 추상화를 적용하면 데이터 액세스 기술과 구현 방법에 독립적인 이상적인 DAO를 만들 수 있다.
4.2.4 기술에 독립적인 UserDao 만들기
인터페이스 적용
public interface UserDao {
void add(User user);
User get(String id);
List<User> getAll();
void deleteAll();
int getCount();
}setDataSource() 메소드는 UserDao 구현 방법에 따라 변경될 수 있고, 클라이언트가 알 필요가 없으므로 포함시키지 않음
public class UserDaoJdbc implements UserDao {<bean id="userDao" class="...UserDaoJdbc">
<property name="dataSource" ref="dataSource" />
</bean>빈의 이름은 클래스의 구현 인터페이스 이름을 따르는 경우가 일반적
테스트 보완
DataAccessException 활용 시 주의사항
DuplicateKeyException은 JDBC를 활용하는 경우에만 발생
SQLErrorCodeSQLExceptionTranslator를 사용하여 SQLException을 코드에서 직접 전환
public class UserDaoTest {
@Autowired UserDao dao;
@Autowired DataSource dataSource;@Test
public void sqlExceptionTranslate(0 {
dao.deleteAll();
try {
dao.add(user1);
dao.add(user1);
} catch(DuplicateKeyException ex) {
SQLException sqlEx = (SQLException) ex.getRootCause();
SQLExceptionTranslator set = new SQLErrorCodeSQLExceptionTranslator(this.dataSource);
assertThat(set.translate(null, null, sqlEx), is(DuplicateKeyException.class));
}
}