
📌 컬렉션 프레임워크
자바 개발도구인 JDK(Java Development Kit)의 1.2버전 이전까지는 다수의 데이터를 저장할 수 있는 클래스들, 즉 컬렉션 클래스들을 각자 다른 방식으로 처리해야 했다. 하지만 JDK1.2부터 컬렉션 프레임워크가 등장하면서 모든 컬렉션 클래스를 표준화된 방식으로 다룰 수 있게 되었다.
컬렉션 프레임워크는 다수의 데이터를 저장하는 클래스들을 표준화한 설계를 의미한다. 컬렉션 프레임워크는 컬렉션을 다루는 데에 필요한 다양하고 풍부한 클래스를 제공하기 때문에 프로그래머들의 짐을 덜어주었으며, 인터페이스와 다형성을 이용한 객체지향적 설계를 통해 표준화 되어 있기 때문에 사용법을 익히기에도 편리하고 재사용성이 높은 코드를 작성할 수 있도록 한다.
인터페이스
컬렉션을 표현하는 추상적인 데이터 타입이다.
컬렉션 프레임워크에서는 컬렉션 데이터 그룹을 크게 List, Set, 그리고 Map 타입으로 분류하였고, 이 중 List와 Set의 공통된 부분을 다시 뽑아와서 새로운 인터페이스인 Collection을 추가 정의했다.
CollectionvsMap
Map은Collection을 상속받지 않는다. 공식 페이지에서는 이를 디자인 차이라고 설명한다.
Map이Collection을 상속한다면Collection의Element에 해당하는 것은Map의'key-value' 쌍이라고 말할 수도 있을 것이다.
하지만, 이 경우에key를 통한 데이터의 탐색이 불가능하기 때문에Map의 추상화에 한계가 발생한다.- 반대로
Collection이Map이라고 가정해보자.Map은 기본적으로'key-value' 쌍으로 구성되기 때문에Collectoin에서Key에 해당하는 것은 무엇인가? 라는 의문을 제기할 수 있다.- 위와 같은 이유로,
Map과Collection은 독립적이다.
Generics
다양한 객체를 다루는 메소드나 컬렉션 클래스를 컴파일할 경우, 타입 체크를 해주는 기능이다.class Box<T> { T item; void setItem(T item) { this.item = item; } T getItem() { return item; } }위의 코드에서처럼 클래스명 뒤에 꺾쇠 기호와 함께 타입 변수를 선언한다. 이후 Box 클래스의 객체를 생성할 경우, 참조 변수와 생성자에 타입변수 T 대신 실제 들어갈 자료형을 지정해야 한다.
Box<String> b = new Box<String>(); b.setItem(new Object()); // 오류 b.setItem("ABC"); // 정상작동
1. List
List 인터페이스는 다음과 같은 특징이 있다.
- 데이터의 중복을 허용한다.
- 저장순서를 유지한다.
1-1. ArrayList
컬렉션 프레임워크에서 가장 많이 사용되는 클래스 중 하나로, 기존의 Vector를 개선한 것이다.
ArrayList는 Object 배열을 이용해서 데이터를 순차적으로 저장한다. 배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성한 뒤, 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장한다.
활용
ArrayList는 java.util 패키지에 소속되어 있기 때문에 java.util.* 혹은 java.util.ArrayList를 임포팅 해주어야 한다.
- 데이터를 삭제하고자 하는 경우, 데이터가 삭제될 때마다 빈 공간을 채우기 위해 나머지 요소들이 자리이동을 하여 인덱스의 값이 바뀔 수 있다. 때문에 시작 인덱스를 List의 크기로 지정하고, 값을 하나씩 줄여가는 것이 좋다.
// list1: [5, 4, 3, 2, 1, 9, 8, 7]
// list2: [5, 66, 55, 2, 1, 9, 8, 7]
// list3: [5, 66, 55, 2, 1, 9, 8, 7]
for (int i = list2.size() - 1; i >= 0; i--) {
if (list1.contains(list2.get(i)))
lsit2.remove(i);
}
// 출력 결과
list1: [5, 4, 3, 2, 1, 9, 8, 7]
list2: [66, 55]
for (int i = 0; i <= list3.size(); i++) {
if (list1.contains(list3.get(i)))
list3.remove(i);
}
// 출력 결과
list1: [5, 4, 3, 2, 1, 9, 8, 7]
list3: [66, 55, 1, 8]- 기존의 크기보다 더 많은 값을 저장하게 되면 자동으로
ArrayList의 크기가 늘어나긴 하지만, 이 과정에서 처리시간이 많이 소요된다. 그렇기 때문에 처음ArrayList를 생성할 시에는 저장할 요소의 개수보다 약간 여유 있는 크기로 하는 것이 좋다.
단점
데이터를 저장하고 읽어오는 데에는 좋은 효율을 보여주지만, 용량을 변경해야 하는 경우에는 새로운 배열을 생성하고 값을 복사해야 하기 때문에 효율이 떨어진다. 때문에 처음 인스턴스를 생성할 때 데이터의 개수를 잘 고려하여 충분한 용량의 인스턴스를 생성해야 한다.
1-2. LinkedList
배열의 크기가 불가변하다는 점과, 배열의 내부에서 원소의 변화가 일어나는 경우 시간이 많이 걸린다는 점을 보완하기 위해 등장한 자료구조이다.
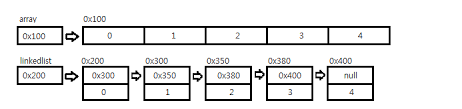
LinkedList의 데이터는 불연속적으로 존재하며, 모든 데이터가 서로 연결되어 있다는 것이 가장 큰 특징이다.
데이터를 삭제하고자 한다면, 이전의 요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경하기만 하면 된다.
생성의 경우에도 마찬가지로, 추가하고자 하는 위치의 이전 요소가 새로운 요소를 참조하도록 하고 새로운 요소가 그 다음 요소를 참조하도록 변경하기만 하면 된다.
결국 데이터를 복사하지 않아도 되기 때문에 매우 빠른 처리 속도를 갖는 것이다.
하지만, 이동 방향이 단방향이기 때문에 이전 요소에 대한 접근이 어렵다는 단점이 있다. 이를 보완하기 위해 고안된 것이 Double LinkedList이다.
기본적인 개념은 LinkedList와 동일하지만, 이전 요소에 대한 참조가 가능하도록 했다.
ArrayListvsLinkedList
- 순차적으로 추가 / 삭제하는 경우에는
ArrayList가 효율적이다.- 중간 데이터를 추가 / 삭제하는 경우에는
LinkedList가 효율적이다.LinkedList는 저장하는 데이터가 많아질수록 접근시간이 길어진다는 단점이 있다.
따라서 다루고자 하는 데이터에 맞게 적절한 클래스를 사용하는 것이 중요하다.
1-3. Stack과 Queue
Stack
LIFO(Last In First Out)- 결과가 데이터를 넣은 순서 그대로 출력된다.
- 자료를 순차적으로 추가하고 삭제하기 때문에
ArrayList기반의 클래스가 적합하다.
Queue
FIFO(First In First Out)- 결과가 데이터를 넣은 순서의 반대로 출력된다.
- 데이터를 꺼낼 때 항상 첫번째 저장된 데이터를 삭제하기 때문에
LinkedList로 구현하는 것이 적합하다.
Priority Queue
- Queue 인터페이스의 구현체 중 하나로, 저장한 순서가 아닌 우선순위에 따라 출력 순서가 결정된다.
- null을 저장하면 NullPointerException이 발생하므로, null을 저장할 수 없다.
import java.util.*
class PriorityQueueEx {
public static void main(String[] args) {
Queue pq = new PriortyQueue();
pq.offer(3);
pq.offer(1);
pq.offer(2);
pq.offer(5);
pq.offer(4);
// [3, 1, 2, 5, 4]
Object obj = null;
while ((obj = pq.poll() != null)
System.out.println(obj);
}
}위와 같은 경우, 입력 순서와 관계 없이 오름차순으로 배열의 내용이 출력되는데, 이는 Integer와 같은 Number 클래스의 자손들은 자체적으로 숫자를 비교하는 방법을 갖고 있기 때문이다.
Deque
Queue의 변형으로, 양 쪽 끝에 추가 / 삭제가 가능하다.
1-4. Iterator, ListIterator, Enumeration
컬렉션에 저장된 요소에 접근하는 데에 사용되는 인터페이스이다.
Iterator
Iterator는 Collection에 지정된 각 요소에 접근하는 인터페이스다. 컬렉션 인터페이스에는 Iterator를 반환하는 iterator() 메서드가 정의되어 있다. 그래서 컬렉션 인터페이스의 자손인 List와 Set 인터페이스에서도 Iterator를 사용하여 내부 항목에 접근할 수 있다.
List list = new ArrayList();
Iterator itr = list.Iterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}위와 같은 방법으로 ArrayList에 저장된 요소들을 출력할 수 있다.
Enumeration
Enumeration은 컬렉션 프레임워크가 만들어지기 이전에 사용하던 것으로, Iterator의 구버전이다. 따라서 Enumeration보다는 Iterator를 사용하는 것이 좋다.
ListIterator
ListIterator는 Iterator에서 양방향으로의 이동이 가능해진 버전이다. 하지만 이는 ArrayList나 LinkedList와 같이 List 인터페이스를 구현한 컬렉션에서만 사용가능하다.
ListIterator의 메서드 중 add(Object o), remove(), set(Object o)의 경우에는 필요에 따라 반드시 구현하지 않아도 된다. 하지만 인터페이스로부터 상속받은 메서드는 추상메서드기 때문에 메서드의 몸통(body)을 반드시 만들어 주어야 한다.
public void remove() {
throw new UnsupportedOperationException();
}위와 같이 예외처리 해주는 이유는, 선언되지 않은 메서드를 사용했을 때 메서드를 호출한 쪽에 메서드가 구현되지 않았다는 것을 알리기 위함이다.
IteratorvsFor / While
컬렉션 안의 데이터에 접근하는 것은 반복문을 통해서도 충분히 가능하다.
하지만Iterator를 사용하면 반복을 진행하는 동안 요소를 삭제한다거나, 이전 항목으로 돌아가는 등 추가적인 기능을 구현할 수 있다. 또한, 컬렉션 자체에iterator()메서드가 존재하여Iterator를 반환하기 때문에 주어진 컬렉션의 요소를 반복하는 가장 효율적인 방법을 제공한다.
1-6. Arrays
toString과 deepToString
deepToString()은 배열의 모든 요소를 재귀적으로 접근하여 문자열을 구성하기 때문에 2차원 이상의 배열에도 작동한다.
int[] arr = {0, 1, 2, 3, 4};
int[][] arr2D = {{0, 1}, {2, 3}, {4}};
System.out.println(Arrays.toString(arr)); // [0, 1, 2, 3, 4]
System.out.println(Arrays.toString(arr2D)); // [[I@36baf30c, [I@7a81197d, [I@5ca881b5]
System.out.println(Arrays.deepToString(arr)); // error
System.out.println(Arrays.deepToString(arr2D)); // [[0, 1], [2, 3], [4]]equals와 deepEquals
deepToString()과 마찬가지로 2차원 이상의 배열에서는 deepEquals()를 사용해야 한다.
String[][] str2D = new String[][]{{"aaa", "bbb"}, {"AAA", "BBB"}};
String[][] str2D2 = new String[][]{{"aaa", "bbb"}, {"AAA", "BBB"}};
System.out.println(Arrays.equals(str2D, str2D2)); // false
System.out.println(Arrays.deepEquals(str2D, str2D2)); // trueasList
배열을 List 컬렉션에 담아서 반환한다.
하지만 asList()가 반환한 List는 크기를 변경할 수 없기 때문에 추가 또는 삭제가 불가능하다. 크기를 변경할 수 있는 List가 필요하다면 다음과 같이 처리할 수 있다.
List list = new ArrayList(Arrays.asList(1, 2, 3, 4, 5));1-7. Comparator와 Comparable
정렬 수행 시, 기본적으로 적용되는 정렬 기준이 되는 메서드를 정의하는 인터페이스다. Java에서 제공하는 정렬 가능한 모든 클래스는 Comparable을 구현하고 있다.
Comparable을 구현하는 클래스들은 기본적으로 오름차순으로 정렬된다. 이 때, 정렬 기준을 변경하고자 할 경우에 Comparator를 구현해서 새로운 정렬 기준을 제공할 수 있다.
2. Set
- 데이터의 중복을 허용하지 않는다.
- 저장순서가 유지되지 않는다.
2-1. HashSet
Set 인터페이스를 구현한 가장 대표적인 컬렉션으로, 데이터의 중복을 허용하지 않는다. 그렇기 때문에 이미 저장되어 있는 요소를 추가하려는 경우에 false를 반환하여 추가에 실패했다는 것을 알린다.
저장 순서를 유지하고자 한다면 HashSet 대신 LinkedHashSet을 사용할 수 있다.
LinkedHashSet
Set인터페이스를 구현하고HashSet클래스를 상속 받은LinkedList이다.HashSet과 마찬가지로 데이터의 중복은 허용하지 않지만, 입력된 순서대로 데이터를 관리할 수 있다.
HashSet에 각 데이터를 연결해주는 변수를 추가하여 구현할 수 있다.
HashSet에 데이터를 추가하기 위해서는 기존에 저장된 요소와 같은 것이 있는지 판별하기 위해 equals()와 hashCode()를 호출한다. 따라서 equals()와 hashCode() 메서드를 목적에 맞게 오버라이딩 해야 한다. 이 때, 오버라이딩을 통해 작성된 hashCode()는 세가지 조건을 만족해야 한다.
- 실행 중인 애플리케이션 내의 동일한 객체에 대해서 여러 번
hashCode()를 호출해도 동일한int값을 반환해야 한다. equals()메서드를 이용한 비교에 의해서true를 얻은 두 객체에 대해 각각hashCode()를 호출해서 얻은 결과는 반드시 같아야 한다.equals()메서드를 호출했을 때false를 반환하는 두 객체는hashCode()호출에 대해 같은int값을 반환하는 경우가 있어도 괜찮지만,hashing을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른int값을 반환하는 것이 좋다.
2-2. TreeSet
TreeSet은 이진 검색 트리라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스로, 정렬, 검색, 범위 검색에 높은 성능을 보인다. TreeSet은 이진 검색 트리의 성능을 향상시킨 레드-블랙 트리로 구현되어 있다.
TreeSet에 객체를 저장할 때는 Comparable을 구현하도록 하던가, Comparator를 제공해서 두 객체를 비교할 방법을 알려줘야 한다.
장점
왼쪽 노드 - 부모 노드 - 오른쪽 노드 순으로 오름차순으로 정렬된 순서를 얻을 수 있기 때문에 단일 값 검색과 범위 검색에 유리하다.
단점
데이터를 순차적으로 저장하는 것이 아니라 정해진 위치를 찾아서 저장하고, 삭제의 경우에는 트리의 일부를 재구성해야 한다. 따라서 Linked List보다 데이터의 추가 / 삭제에 걸리는 시간이 크다.
3. Map
key와value를 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스를 구현하는 데에 사용된다.key는 중복을 허용하지 않고, 반대로value는 중복을 허용한다.
3-1. HashMap과 Hashtable
Hashtable과 HashMap의 관계는 Vector와 ArrayList의 관계와 같아서, HashMap을 사용할 것을 권한다.
HashMap은 key와 value를 묶어서 하나의 데이터로 저장하고, 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데에 효율적이다.
HashMap은 Entry라는 내부 클래스를 정의하고, 다시 Entry 타입의 배열을 선언한다. key와 value가 개별적인 값이 아니기 때문에 하나의 클래스로 정의해서 배열로 다루는 것이 데이터의 무결성적인 측면에서 더욱 바람직하기 때문이다.
무결성
데이터베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제값이 일치하는 정확성을 의미한다.
3-2. 해싱과 해시함수
해싱이란 해시함수를 이용해서 데이터를 해시테이블에 저장하고 검색하는 기법을 뜻한다. 해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 쉽게 찾을 수 있다.
해싱을 구현한 컬렉션 클래스로는 HashSet, HashMap, Hashtable 등이 있다. 하지만 앞서 언급했듯이 Hashtable은 HashMap의 구버전에 해당하므로 웬만하면 HashMap을 사용하도록 하자.
해싱에서 사용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어 있다.
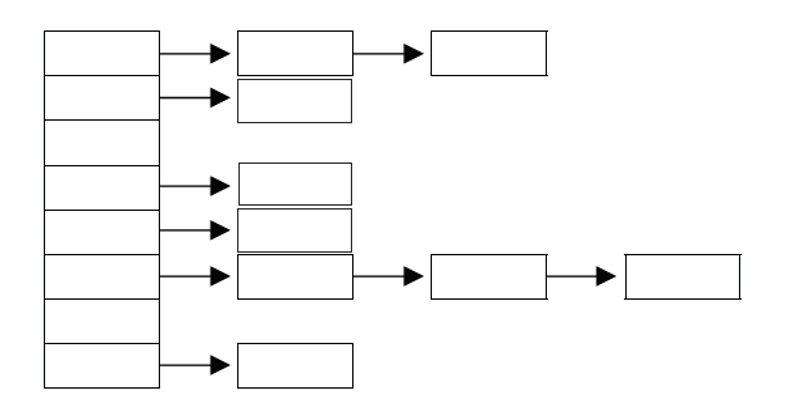
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하는 방식이다.
이 때, 링크드 리스트는 크기가 커질수록 자료 검색에 훨씬 많은 시간을 소모하게 된다. 따라서 하나의 배열에 여러 데이터를 링크드 리스트로 연결하기 보다는 최소한의 데이터만 저장하는 것이 더 효율적이다.
그러기 위해서 해시함수의 알고리즘을 잘 작성하는 것이 중요하다.
3-3. TreeMap
이진탐색트리의 형태로 key와 value를 저장한다. 그렇기 때문에 데이터의 탐색과 정렬에 적합한 컬렉션 클래스이다.
검색에 관한 대부분의 경우에는 HashMap이 TreeMap보다 빠르지만, 범위검색이나 정렬이 필요한 경우에는 TreeMap이 더 빠르기 때문에, 데이터의 종류에 맞는 클래스를 사용하는 것이 중요하다.
3-4. Properties
HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로, (Object, Object) 형식으로 key와 value를 저장하는 것이 아닌 (String, String)의 형식으로 데이터를 저장하는 컬렉션 클래스이다.
주로 애플리케이션의 환경설정과 관련한 속성을 저장하는 데에 사용되며, 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다.
4. Collections
컬렉션과 관련된 메서드를 제공한다.
4-1. 컬렉션의 동기화
Vector나 Hashtable 등의 구버전 클래스들은 멀티쓰레스 프로그래밍(Multi-Thread) 시에 자체적으로 동기화 처리를 해왔다. 하지만, 멀티쓰레드 프로그래밍이 아닌 경우에는 불필요한 기능이 되어 성능을 떨어뜨리는 요인이 된다.
그래서 새로 추가된 컬렉션은 동기화를 자체적으로 처리하지 않고, 필요한 경우에만 컬렉션 클래스의 synchronizedXXX() 메서드를 통해 동기화 처리를 할 수 있도록 변경했다.
4-2. 변경불가 컬렉션 만들기
unmodifiableXXX() 메서드를 활용한다면 멀티쓰레드 프로그래밍에서 여러 쓰레드가 하나의 클래스를 공유할 때, 데이터의 손상을 방지하기 위해서 컬렉션을 변경할 수 없는, 즉 읽기 전용으로 만들 수 있다.
4-3. 싱글톤 컬렉션 만들기
단 하나의 객체를 저장하는 컬렉션을 생성하고 싶을 때, singletonXXX() 메서드를 활용할 수 있다. 해당 메서드로 생성된 컬렉션은 이후 변경이 불가하다.
4-4. 한 종류의 객체만 저장하는 컬렉션 만들기
컬렉션에 지정된 종류의 객체만을 저장하도록 제한하고 싶을 때 checkedXXX() 메서드를 활용한다. 두 번째 매개변수에 저장할 객체의 클래스를 할당하면 된다.
지네릭스가 도입되기 전 JDK1.5 이전에 작성된 코드를 사용할 때 해당 메서드가 필요할 수 있다.
--
참고도서
🙇🏻♂️ 남궁 성, 자바의 정석
