Do it 자료구조와 함께 배우는 알고리즘 입문 - 07. 문자열 검색
문자열 검색이란?
어떤 문자열 안에 특정 문자열이 들어 있는지 조사하고, 들어 있다면 그 위치를 찾는 것이다.
검색할 문자열을 패턴이라 하고 문자열 원본을 텍스트라고 한다.
브루트-포스법
모든 문자가 일치해야 한다. 일치하지 않는 문자를 만나면 패턴 1칸 옮긴 다음 패턴의 처음부터 다시 검사한다. 단순법, 소박법이라 한다.
class BFmatch {
static int bfMatch(String txt, String pat) {
int pt=0; //txt 커서
int pp=0;
while(pt != txt.length() && pp != pat.length()) {
if (txt.charAt(pt) == pat.charAt(pp)) {
pt++; // 일치가 시작된 위치
pp++; // 일치를 확인한 문자열의 길이이다.
} else {
pt = pt - pp + 1; // 일치가 시작된 위치를 나타낸다.
pp = 0;
}
}
if (pp == pat.length()) // 검색 성공
return pt - pp; // 검색이 성공한 위치를 알려준다.
return -1; // 검색 실패
}txt : 텍스트 문자열
pat : 패턴 문자열
pt : 텍스트 커서 (현재 검색 중인 위치)
pp : 패턴 커서 (현재 패턴에서 확인하고 있는 위치)
pt가 txt의 길이에 도달하거나 pp가 pat의 길이에 도달할 때까지 반복한다.
-
일치할 경우
pt와 pp를 각각 한 칸씩 전진시킨다. -
일치하지 않으면
pt를 (pt-pp+1)로 이동시키고 pp를 0으로 초기화한다.
pp가 pat의 길이와 같아지면 해당 위치인 pt-pp를 반환한다.
검색이 실패한 경우 -1를 반환한다.
-
compareTo : 다른 문자여로가 비교
변수 이름.compareTo(s) -
String indexOf / lastIndexOf 메서드로 문자열 검색하기
int indexOf(String str) // 특정한 문자열이 포함되어 있는지 검색한다.
int lastIndexOf(String str)
String.getBytes : 문자열을 바이트 시퀀스로 부호화하여 바이트 배열에 넣어 두는 메서드이다.
부호화(인코딩) : 정보의 모양이나 형식을 다른 모양이나 형식으로 변환하는 것이다.
문자열 -> 바이트시퀀스로 변환하는 것이다.
디코딩 : 바이트시퀀스 -> 문자열로 변환하는 것이다.
class IndexOfTester {
public static void main(String[] args) {
Scanner sc= new Scanner(System.in);
System.out.print("텍스트: ");
String s1=sc.next(); // 텍스트용 문자열
System.out.print("패 턴: ");
String s2=sc.next();
int idx1=s1.indexOf(s2);
int idx2=s1.lastIndexOf(s2);
if(idx1 == -1)
System.out.println("텍스트 안에 패턴이 없다.");
else {
int len1=0;
for (int i=0; i<idx1; i++)
len1 += s1.substring(i, i+1).getBytes().length;
len1 += s2.length();
int len2=0;
for (int i=0; i<idx2; i++)
len2 += s1.substring(i, i+1).getBytes().length;
len2 += s2.length();
패턴용 문자열은 입력할 때 특수문자를 입력하기 때문에 s2.length();로 해당 패컨의 길이만 알면 된다.
인코딩 방식에 따른 문자열 크기 계산
1) str.length() : 문자열 str = "ABC이지12#@$" 특수문자와 같이 있을 때 사용한다.
2) str.getBytes().length : 문자를 내부적으로 저장하는 배열의 크기, 바이트 단위 크기를 반환한다.
영문 euc-kr의 경우 문자 1개에 2바이트
한글이나 한자는 UTF-8인코딩을 사용할 경우 한글은 3바이트로 표현되고, 영문은 1바이트로 표현된다. 이러한 이유로, 멀티바이트 문자를 다루 때 getBytes()를 사용하여 각 문자의 실제 길이를 정확하게 파악하기 위한 것이다.
str.getBytes("euc-kr").length
str.getBytes("utf-8").length처럼 인코딩 방식을 구별하는 것이 좋다.
KMP법
일치하지 않는 문자를 만나면 패턴을 1칸 옮긴 다음, 그때까지 검사한 결과를 활용한다.
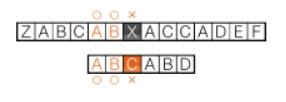
텍스트와 패턴 사이에 겹치는 부분을 찾아내 검사를 다시 시작할 위치를 구하여 패턴을 한번에 많이 옮기는 알고리즘이다.
"ZABCABXACCADEF"에서
"ABCABD"를 검색하는 경우 Z와 일치하지 않기 때문에 A로 한칸 이동한다.
X와 D가 일치하지 않기 때문에 일치하는 ABXACCADEF와 ABCABD를 검사한다.
텍스트와 패턴 사이의 겹치는 부분을 찾아내서 검사를 다시 시작할 위치를 구하여 패턴을 한번에 많이 옮긴다.
"ABCABD" A- B인덱스0
"ABCABD" B인덱스 0, C인덱스 0
"ABCABD" B인덱스 0 C인덱스 0 A인덱스 1 B인덱스 2가 된다.
하지만 최종적으로 패턴을 2칸 뒤로 옮기면 문자가 일치하지 않는다. D의 값을 0으로 한다.
static int kmpMatch(String txt, String pat) {
int pt=1; // txt커서
int pp=0; // pat커서
int[] skip=new int[pat.length()+1]; // 건너뛰기 표
// 건너뛰기 표 만들기
skip[pt]=0;
while(pt != pat.length()) {
if(pat.charAt(pt)==pat.charAt(pp))
skip[++pt]=++pp;
else if(pp==0)
skip[++pt]=pp;
else
pp=skip[pp];
}
pt=pp=0;
while(pt != txt.length() && pp !=pat.length()) {
if(txt.charAt(pt)==pat.charAt(pp)){
pt++;
pp++;
}else if(pp==0)
pt++;
else
pp=skip[pp];
}
