Do it 자료구조와 함께 배우는 알고리즘 입문 - 07. 문자열 검색
문자열 검색이란?
어떤 문자열 안에 특정 문자열이 들어 있는지 조사하고, 들어 있다면 그 위치를 찾는 것을 말한다.
브루트-포스법
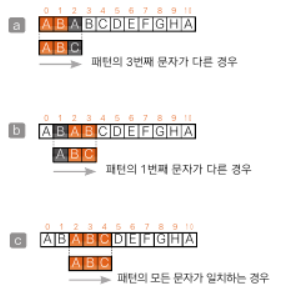
패턴의 1번째 문자가 다른 경우 1칸 뒤로 옮긴다. 일치하는게 없을 경우 또 다시 뒤로 옮긴다.
패턴의 위치는 뒤로 물러나서 다시 1부터 검사하기 때문에 효율이 좋지 못하다.
문자열과 String 클래스
String s = "ABC";
-
문자열 안에서 특정 문자를 꺼내는 메서드 charAt
변수 이름.charAt(i) -
부분 문자열을 꺼내는 메서드 substring
변수 이름.substring(begin, end) -
다른 문자열과 내용이 같은지 equals
변수 이름.equals(s) -
다른 문자열과 비교(대소 관계 판단)하는 메서드 compareTo
변수 이름.compareTo(s)
String.indexOf 메서드로 문자열 검색하기
- int indexOf(String str)
- int indexOf(String str, int fromIndex)
- int lastIndexOf(String str)
- int lastIndexOf(String str, int fromIndex)
public class BFmatch {
static int bfMatch(String txt, String pat) {
int pt=0; //txt
int pp=0; //pat 커서
// txt의 길이와 pat길이가 맞지 않다면 계속
while(pt != txt.length() && pp != pat.length()) {
if(txt.charAt(pt)==pat.charAt(pp)){
pt++;
pp++; // 둘 다 증가시킨다.
}else {
pt=pt-pp+1;
pp=0;
}
}
if(pp==pat.length()) // 검색 성공
return pt-pp;
return -1; // 검색 실패
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
System.out.print("텍스트 : ");
String s1=sc.next();
System.out.print("패 턴 : ");
String s2=sc.next();
int idx=bfMatch(s1, s2);
if (idx == -1)
System.out.println("텍스트에 패턴이 없습니다.");
else {
// 일치하는 문자 바로 앞까지의 문자 개수를 반각 문자로 환산하여 구한다.
int len=0;
for(int i=0; i<idx; i++)
// 바이트 단위로 문자열을 자른다.
len+=s1.substring(i, i+1).getBytes().length;
len+=s2.length();
System.out.println((idx + 1) + "번째 문자부터 일치한다."); // 문자부터 일치한다.
System.out.println("텍스트: " + s1);
System.out.printf(String.format("패 턴: %%%d\n", len), s2);
}
}
}
KMP
일치하지 않는 문자를 만난 단계에서 버리지 않고 효과적으로 활용하는 알고리즘이다.
"ZABCABXACCADEF"에서
"ABCABD"를 검색하는 경우
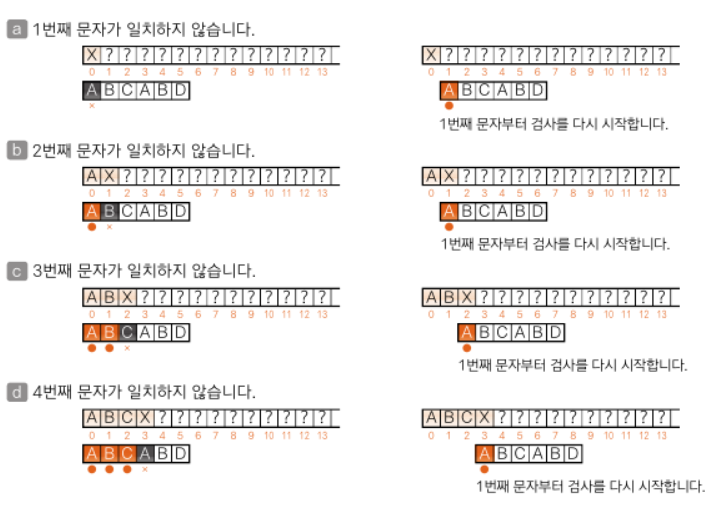
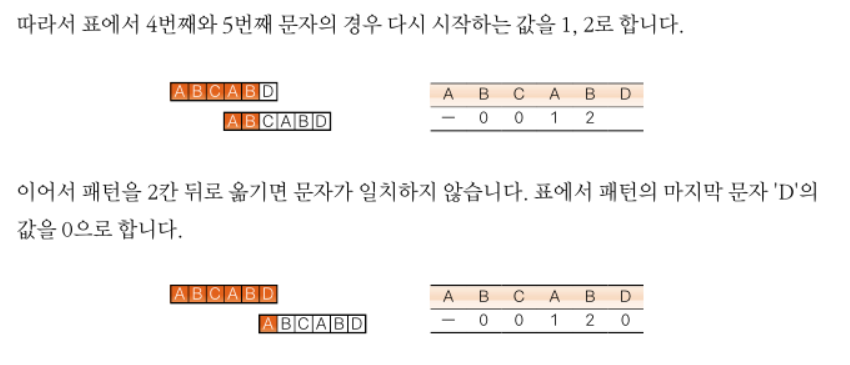
책의 내용을 조금 가져와보면 일치하지 않는다면 버리지 않고 건너 뛸 수 있다.
public class kmpMatch(String txt, String pat) {
int pt=1; // txt 커서
int pp=0; // pat 커서
int[] skip=new int[pat.length()+1]; // 건너뛰기 표
// 건너뛰기 표 만들기
skip[pt]=0;
while(pt != pat.length()) {
if(pat.charAt(pt) == pat.charAt(pp)) // pt, pp커서 커서가 같다면
skip[++pt]=++pt;
else if (pp == 0)
skip[++pt]==pp;
else
pp=skip[pp];
}
if(pp==pat.length()) // 패턴의 모든 문자 대조
return pt-pp;
return -1; // 검색 실패
}보이어-무어법
KMP법보다 효율이 더 좋기 때문에 실제 문자열 검색 프로그램에서 널리 사용하는 알고리즘이다.
이론과 실제 모두에서 더 우수한 알고리즘이다. 이 알고리즘은 패턴의 마지막 문자부터 앞쪽으로 검사를 진행하면서 일치하지 않는 문자가 있으면 미리 준비한 표에 따라 패턴을 옮길 크기를 정한다.
비교 범위의 텍스트에 패턴에 없는 문자가 있다면 그 위치까지 건너뛸 수 있다.
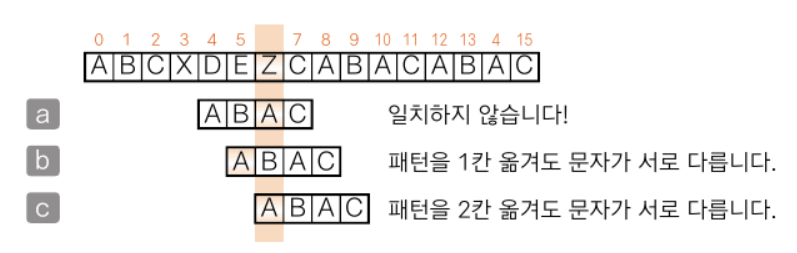
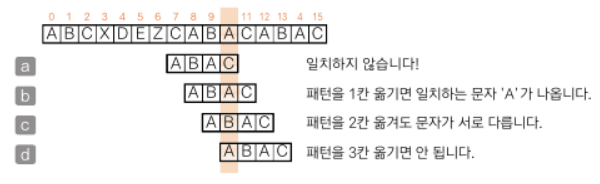
패턴의 마지막 문자가 같을때까지 패턴을 1칸 옮긴다.
패턴을 옮길 크기를 알려 주는 표(건너뛰기 표)를 미리 만들어두어야 한다.
1) 패턴에 들어 있지 않은 문자를 만난 경우
패턴을 옮길 크기는 n이다. x는 패턴에 없으므로 4만큼 옮긴다.
2) 패턴에 들어 있는 문자를 만난 경우
해당 문자의 마지막 인덱스가 k이면 패턴을 옮길 크기는 n-k-1이다.
- 패턴의 마지막 문자가 패턴 안에 중복해서 들어 있지 않은 경우 패턴을 옮길 크기를 n으로 한다.
텍스트에서 C를 만날 경우 이동하지 않고 바로 앞 문자를 비교한다. 이동할 필요가 없으므로 사용하지 않지만 편의상 n이라고 하는 것이다.
건너뛰기 표의 요솟수는 Character.MAX_VALUE+1 이다.
문자열 검색 알고리즘 시간 복잡도
1) 브루트-포스법
시간 복잡도 O(mn) 단순한 알고리즘이지만 속도가 빠르다. = O(n)
2) KMP법
시간 복잡도 O(n)으로 매우 빠르다. 검색하는 과정에서 선택한 요소를 다시 앞쪽으로 되돌릴 필요가 없다. 파일에서 순서대로 읽어 들이면서 검색하는 경우에 알맞다.
처리하기 복잡하고, 패턴안에 반복하는 요소가 없다면 효율이 떨어진다.
3) 보이어무어법
시간복잡도 O(n) 매우 빠르다.
2개 배열을 사용할 경우 처리하기 복잡하므로 효과가 상쇄된다.
프로그램을 작성할 때 String.indexOf 메서드를 사용한다. 표준 라이브러리를 사용하지 않을 경우 간략한 보이어무어법을 사용하고 경우에 따라 브루트-포스법을 사용한다.
요약
브루트포스 : 패턴 한칸씩 계속 움직여서 일치하는 값을 찾을 때 까지 찾는다.
int pt=0; // txt커서
int pp=0; //pat 커서
while (pt != txt.length() && pp != pat.length()) {
일치하면 pt++ 해서 길이에 맞추고,
else
pt = pt-pp+1;
pp = 0;
if(pp==pat.length()) // 검색 성공
return pt-pp; //txt 에서 pp;를 빼고
return -1; KMP : 패턴이 일치하는 문자부터 이동하여 검사한다.
검사를 하다가 일치하지 않는 값이 나온다면 패턴이 일치했던 것은 건너뛰고 일치하지 않았던 문자부터 검색한다. = 패턴 안의 값을 최대한 활용
int pt=1; // txt
int pp=0; // pattern
int[] skip=new int[pat.length()+1]; // 건너뛰기 표
skip[pt]=0;
while(pt != pat.length()) {
if(pat.charAt(pt) == pat.charAt(pp))
skip[++pt] = ++pp; // 두개 다 증가시켜준다.
else if(pp==0) // pat커서가 0이라면
skip[++pt]=pp; // pt만 증가시킨다.
else
pp=skip[pp]; // skip을 한다.
}
if (pp == pat.length()) // 패턴의 모든 문자 대조
return pt-pp;
return -1; // 검색 실패
}보이어무어 : 패턴의 오른쪽 끝(접미사)부터 텍스트를 비교한다. 오른쪽에서 왼쪽으로, 일치하지 않는 경우, 패턴 내에서 해당 문자가 텍스트 내에서의 위치로 이동한다.
