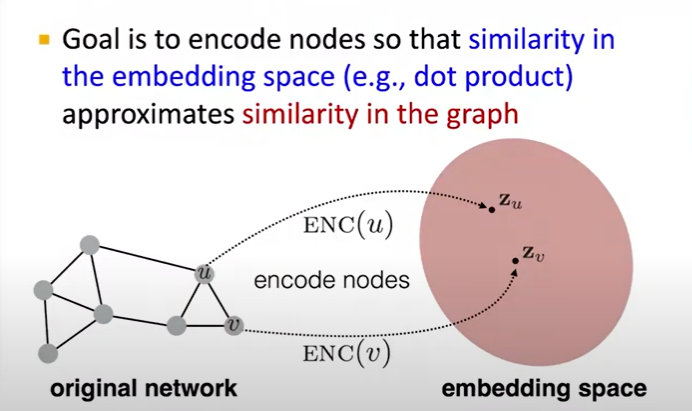
Embedding Nodes
Encoder and Decoder
- Goal: embedding space에서 가깝에 위치하게 embedding하기 위함
"Shallow" Encoding
- Encoder is just an ebmbedding-lookup
- Each node is assigned a unique embedding vector

similarity 를 maximize하는 parameter 를 optimize하는게 목표
Random-Walk Embeddings
$ \bold{Z}{u}^{T}\bold{Z}{v} \approx $ , 가 random walk에서 co-occur 할 확률
- Predicted probability와 실제 random-walk probability와 비슷하게 학습
- Random walk을 했을 때 나타난 neighbor set node들의 확률이 높게 나타나야 함
- Generally work most efficiently
- Expressivity: incorporate high-order, multi-hop info
- Efficiency: only need to consider pairs that co-occur

- 모든 노드를 탐색하는건 expensive
-> Solution: Negative sampling
- Sample k Negative sampling
- Sample k with prob. proportional to is degree
- In practice 5~20 - Optimize embeddings using Stochastic Gradient Descent
Node2Vec
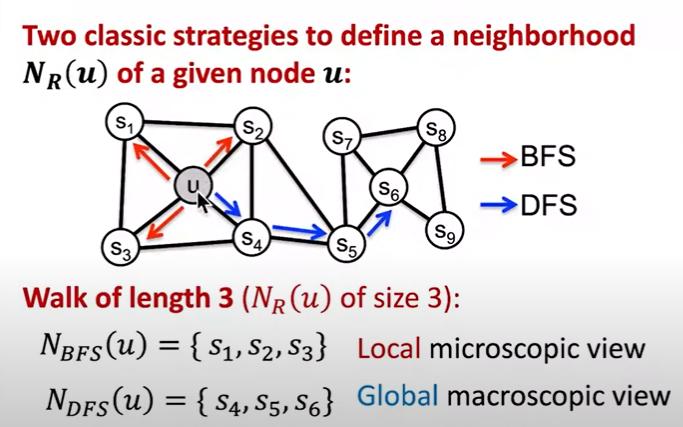
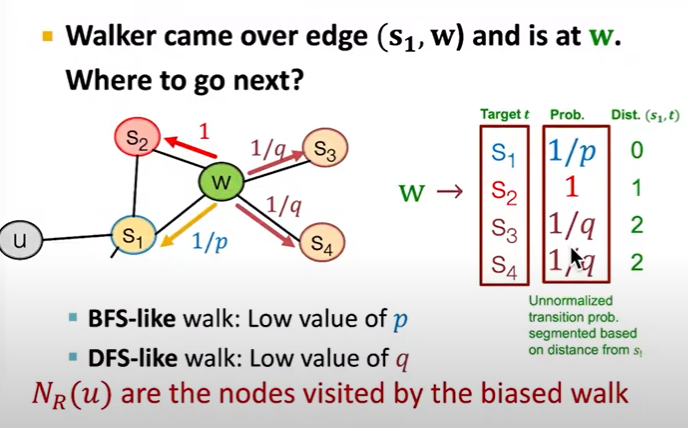
- 그래서 random walk을 어떻게 할건지?
- node2vec은 graph에서 node를 vector로 sampling하는 strategy
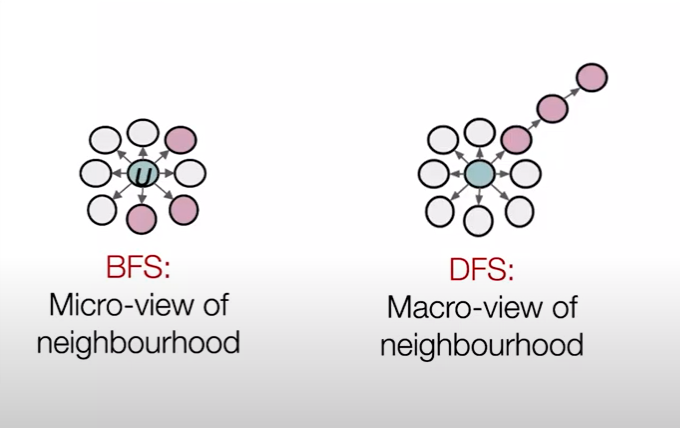
- Breadth-First Search
- Depth-First Search
- Parameters
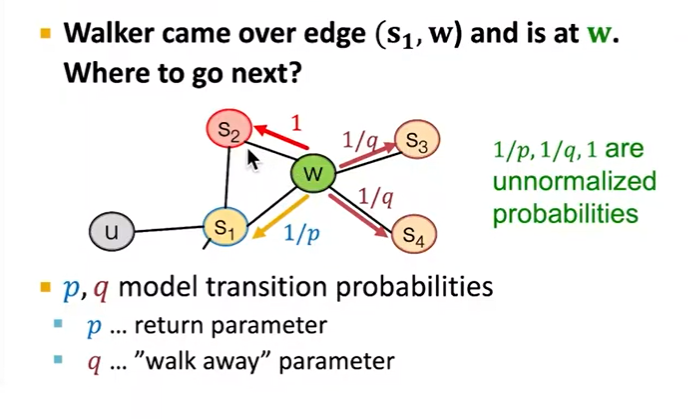
- Return parameter p- In-out parameter q: ratio between BFS and DFS
Embedding Entire Graphs
Approaches
- Node(Sub-graph) embedding을 합함
- Virtual node의 embedding
- Anonymous Walks: 가능한 anonymous walks의 확률 벡터
- Learn Walk Embeddings: Predict the next anonymous walk

General Engineer