response자체와 BeauitfulSoup자체를 거친 내용물 자체는 동일.
import requests
from bs4 import BeautifulSoup
url="http://www.daum.net"
response=requests.get(url)
print(type(response.text))
print(type(BeautifulSoup(response.text,'html.parser')))의 결과물
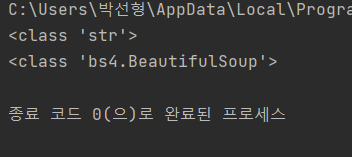
이를 통해 내용물 자체는 같지만 type이 다르다는 것을 알 수 있다.
file=open("naver.html","w",encoding="utf-8")
file.write(response.text)
file.close()
작업을 하다보니 html파일이 깨지는 것을 확인할 수 있었다. 그전에
file=open("naver.html","w")만했을 때는 encoding이 제대로 되지 않아 글자가 깨져 보여 encoding="utf-8"을 추가하였다. html이 저런식으로 되어 있을 때 정렬하기 위한 단축키를 구글링 해보니 원하는 블록만큼 지정(나 같은 경우는 ctrl+a) 하고 ctrl+k, ctrl+p를 하면 깔끔하게 정렬되는 것을 볼 수 있다.
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://datalab.naver.com/keyword/realtimeList.naver?age=20s"
response = requests.get(url,headers=headers)위의 코드는 네이버 같은 사이트에서 한 개인이 크롤링을 하기 위해 로봇(?) 이 아니라는 것을 인증하기 위한 코드이다. headers에 저런 정보들을 포함시켜서 요청을 하면 값이 잘 나오는 것을 확인할 수 있다.

모든 생각을 구현해내기 위해 노력하는 개발자