[DCAI] Special Topic 4. Data Privacy and Security

데이터 프라이버시와 보안
머신러닝 모델은 종종 의료 기록과 같은 민감한 데이터를 학습한다. 이러한 모델은 일반적으로 공개적으로 이용 가능하게 제공되며, 모델의 아키텍처나 가중치를 다운로드하거나, 추론 엔드포인트를 통해 블랙박스 방식으로 예측을 할 수 있다. 하지만, 이러한 모델이 학습된 데이터가 민감할 경우 이를 공개하는 것이 적절하지 않을 수 있다.
따라서 중요한 질문이 생긴다: 공개된 모델이 학습 데이터에 포함된 개인 정보를 누설할 수 있는가? 실제로 그러하며, 이는 여러 머신러닝 모델에 대한 다양한 공격을 초래한다. 대표적인 공격 유형은 다음과 같다:
- 멤버십 추론 공격(membership inference attacks): 주어진 데이터 포인트가 모델의 학습 세트에 포함되었는지를 추론하는 공격이다. 예를 들어, HIV 환자의 데이터셋으로 학습된 머신러닝 모델을 생각해보자. 만약 공격자가 특정 사람이 학습 세트에 포함되었는지 확인할 수 있다면, 그 사람의 HIV 상태를 유추할 수 있다.
- 데이터 추출 공격(data extraction attacks): 주어진 모델에서 학습 데이터를 직접 추출하는 공격이다. 예를 들어, GitHub Copilot으로 작동하는 OpenAI Codex같은 대형 언어 모델이 프로덕션 시크릿을 포함한 개인 저장소의 코드로 학습되었다고 가정해보자. 공격자가 모델을 통해 일부 학습 데이터를 추출한다면, 공격자는 중요한 API 키나 기타 민감한 정보를 알아낼 수 있을 것이다.
이 외에도 다음과 같은 공격 유형들이 존재한다:
적대적 예제(Adversarial Examples, Szegedy et al., 2013)
데이터 중독 공격(Data Poisoning Attacks, Chen et al., 2017)
모델 인버전 공격(Model Inversion Attacks, Fredrikson et al., 2014)
모델 추출 공격(Model Extraction Attacks, Tramèr et al., 2016)
머신러닝 보안은 활발한 연구 분야로, 현재까지 수천 편의 논문이 출판되었다. 여기에 더해 최근에 발견된 LLM의 프롬프트 인젝션(prompt injection in LLMs)과 같은 새로운 이슈들 역시 체계적으로 다뤄지지 않은 상태이다.
이 포스팅에서는 머신러닝 보안에 대해 다루며, 특히 추론 및 추출 공격에 초점을 맞춘다. 마지막으로, 경험적 방어 기법과 차분 프라이버시(Differential Privacy)와 같은 프라이버시 공격에 대한 방어 전략을 논의할 것이다.
보안 정의: 보안 목표와 위협 모델(Defining security: security goals and threat models)
시스템이 보안적인지 판단하기 위해서는 먼저 보안 목표와 위협 모델을 정의해야 한다.
- 보안 목표: 시스템이 달성해야 할 것과 발생하지 않아야 할 것을 정의한다. 즉, 어떤 상황이 발생해야 하며, 어떤 상황이 발생하지 않아야 하는지를 명확히 규정하는 것이다.
- 위협 모델: 공격자가 할 수 있는 것과 할 수 없는 것을 정의한다. 공격자가 알고 있는 정보, 모르는 정보, 그리고 공격자가 가진 계산 능력과 시스템에 대한 접근 권한을 제한한다.
이 정의를 통해, 위협 모델에 따른 모든 가능한 공격자(any possible adversary)가 보안 목표를 위반할 수 있는지를 평가한다. 그 결과가 "아니오"인 경우에만 해당 시스템은 보안적이라고 말할 수 있다.
보안이 어려운 이유는 모든 공격자를 정량화하는 과정에서 발생하는 복잡성 때문이다. 특히, 적절한 위협 모델을 설정하지 않으면 대부분의 보안 목표는 성취될 수 없다.
이미지 예측 API
Google Cloud Vision API와 같은 클라우드 기반 이미지 예측 API를 예로 들어보자. 이 API는 이미지를 입력받아 해당 이미지에 대한 예측 레이블과 확률 분포를 반환한다.
이 시스템에서의 보안 목표는 공격자가 ML 모델을 추출할 수 없도록 하는 것이다. 모델은 독점적 자산이며, 대량의 데이터와 비용을 투자하여 학습된 모델이기 때문에 클라우드 제공자는 공격자가 모델의 아키텍처나 가중치를 추출하지 않기를 원할 것이다.
위협 모델링에서 다음과 같은 가정을 할 수 있다:
- 공격자는 API에 쿼리를 수행하여 자신이 선택한 입력에 대해 출력 클래스의 확률 분포를 얻을 수 있다. 이때 입력은 자연스러운 이미지일 필요는 없으며, 임의의 색상의 직사각형 픽셀로 이루어진 이미지도 유효하다.
- 공격자는 모델의 아키텍처를 알고 있다. 클라우드 제공자가 최신 신경망 모델에 대한 논문을 작성했을 가능성이 있기 때문이다.
반면, 클라우드 제공자는 공격자가 할 수 없다고 가정하는 항목도 있다:
- 공격자는 모델의 중간 활성화 계층에 접근할 수 없다. API는 예측 결과만 노출하며 중간 활성화 계층은 비공개다.
- 공격자는 모델의 그라디언트를 계산할 수 없다.
- 공격자는 시간당 1000개 이상의 쿼리를 수행할 수 없다. API에는 속도 제한이 걸려있다.
- 이상의 계산 자원을 사용할 수 없다. 이 이상 계산을 수행하면 모델을 추출하는 것이 경제적으로 의미가 없다.
환자 위험 예측 모델
한 병원이 환자 데이터를 사용해 집중 치료가 필요한 환자를 예측하는 머신러닝 모델을 학습했다고 가정해보자. 이 모델은 다른 병원이나 연구자들이 활용할 수 있도록 공개되었다. 이 시스템의 보안 목표는 특정 환자의 정보가 누출되지 않는 것이다. 즉, 공격자가 특정 환자가 학습 데이터셋에 포함되었는지를 알 수 없어야 한다.
이 경우 위협 모델은 다음과 같다:
- 공격자는 모델에 대한 완전한 화이트박스 접근 권한을 가진다. 즉, 아키텍처와 가중치에 대한 완전한 지식을 가지고 있다.
- 공격자는 공개적으로 이용 가능한 의료 데이터를 통해 특정 특징의 분포나 범위를 대략적으로 파악하고 있다.
하지만 병원은 다음과 같은 사항을 가정할 수 있다:
- 공격자는 병원의 서버를 손상시켜 환자 데이터에 접근할 수 없다.
- 공격자는 학습 중 생성된 중간 체크포인트의 가중치에 접근할 수 없다.
이와 같은 사례를 통해 시스템의 보안 목표와 위협 모델을 적절하게 정의하는 것이 보안의 핵심임을 알 수 있다.
멤버십 추론 공격(Membership Inference Attacks)
멤버십 추론 공격은 주어진 데이터 포인트가 머신러닝(ML) 모델의 학습 세트에 포함되었는지를 결정하는 공격이다. 예를 들어, 데이터 포인트 로 구성된 데이터셋 로 학습된 ML 모델 을 고려해보자. 여기서 은 레이블의 집합에 대한 확률 분포를 생성하며, 이다. 멤버십 추론 공격의 목표는 주어진 데이터 포인트 에 대해, 인지 여부를 모델 에 대한 접근을 통해 결정하는 것이다.
다양한 공격 시나리오에서 공격자는 에 대한 접근 권한에 따라 설정이 달라진다. 이번 글에서는 블랙박스 접근에 중점을 두며, 여기서 공격자는 자신이 선택한 입력에 대해 에 쿼리를 수행하고, 모델의 출력(예: 각 클래스에 대한 예측 확률)을 얻는다.
Shadow training (Shokri et al., 2016)
이 공격 기법은 머신러닝을 이용해 타깃 모델의 학습 세트에 특정 데이터 포인트가 포함되었는지 추론하는 모델을 학습한다. 공격자는 공격 모델 를 학습시켜 데이터 포인트의 레이블 와 타깃 모델의 출력 를 바탕으로 이진 분류를 수행하여 해당 데이터 포인트가 학습 세트에 포함되었는지를 결정한다: . 이 공격 모델의 학습 데이터는 여러 "shadow models"을 사용해 수집한다.
Step 1: 학습 데이터 수집 (Collecting Training Data)
이 공격은 공격자가 타깃 모델과 동일한 형식의 추가 데이터셋 에 접근할 수 있다고 가정한다. 예를 들어, 타깃 모델이 이미지 분류기라면, 공격자는 많은 이미지 데이터에 접근할 수 있어야 한다. 공격자는 shadow model을 학습시키고 이를 이용해 공격 모델의 학습 데이터를 생성한다.
- 데이터셋 를 과 로 분할한다.
- 모델 아키텍처를 선택하고, shadow model 를 에서 학습한다.
- 각 에 대해, 를 계산하여 에 대한 모델 출력을 얻고, 이를 통해 학습 데이터 포인트 를 생성한다.
- 각 에 대해, 를 계산하여 에 대한 모델 출력을 얻고, 이를 통해 학습 데이터 포인트 를 생성한다.
이 과정을 여러 번 반복하여 의 다른 분할과 다른 shadow model을 사용해 이라고 부르는 큰 학습 데이터셋을 만들 수 있다.
Step 2: 공격 모델 학습 (Train the Attack Model)
다음으로, 이 공격은 을 사용해 이진 분류기 를 학습한다. 공격 모델 는 어떤 분류 알고리즘으로도 학습할 수 있으며, 다층 퍼셉트론(multi-layer perceptron) 등이 사용될 수 있다.
Step 3: 공격 수행 (Perform the Attack)
새로운 데이터 포인트 가 주어졌을 때, 공격자는 타깃 모델 에 이 데이터를 입력하여 를 계산하고, 를 평가하여 해당 데이터 포인트가 학습 세트에 포함되었는지를 예측한다.
Metrics-based Attacks
이진 분류기를 학습시키는 공격과 달리, Metrics-based attacks는 구현이 훨씬 간단하고 계산 비용이 적다.
Prediction correctness based attack (Yeom et al., 2017)
이 방법은 주어진 데이터 포인트 에 대해, 모델 이 예측한 결과가 실제 레이블 와 일치하는지를 확인한다. 만약 이면, 해당 데이터 포인트는 학습 세트에 포함되었다고 판단하여 을 반환한다.
직관: 이 공격은 학습 데이터와 테스트 데이터 간의 정확도 차이를 활용한다. 모델은 일반적으로 학습 데이터에 대해서는 매우 정확하게 예측하지만, 테스트 데이터에서는 오차가 발생할 수 있다. 따라서 학습 데이터는 더 자주 올바르게 분류되는 경향이 있다.
Prediction loss based attack (Yeom et al., 2017)
이 방법은 주어진 데이터 포인트 에 대해 모델이 계산한 손실 을 사용하여 점수를 할당한다. 모델이 해당 데이터 포인트에 대해 산출한 손실이 미리 설정한 임계값 보다 낮으면, 을 반환한다. 즉, 손실 값이 낮으면 해당 데이터가 학습 세트에 포함되었다고 판단하는 방식이다.
임계값 를 설정하는 방법으로는 모델의 학습 데이터에 대한 평균 손실이나 최대 손실을 사용할 수 있다. 이는 학습 데이터에서의 손실 분포를 바탕으로 임계값을 정하는 방식이다.
직관: 모델은 학습 데이터에 대해 손실을 최소화하도록 학습되며, 학습 데이터에 대해 매우 작은 손실을 보일 수 있다. 이는 모델이 학습 데이터에서 높은 예측 정확도를 달성할 수 있음을 의미한다.
Prediction confidence based (Salem et al., 2018)
이 방법은 모델이 예측한 클래스에 대한 신뢰도 를 바탕으로 데이터 포인트에 점수를 할당한다. 모델이 특정 클래스에 대해 높은 신뢰도를 보인다면, 해당 데이터가 학습 세트에 포함되었을 가능성이 크다고 판단할 수 있다. 임계값을 설정하는 방법으로는 학습 데이터에 대한 평균 또는 최소 신뢰도를 사용할 수 있다.
직관: 모델은 학습 데이터에 대해 더 높은 신뢰도를 보이는 경향이 있다. 비록 예측이 실제 레이블과 일치하지 않더라도, 학습 데이터에서는 모델의 예측이 더 확신에 찬 경우가 많다.
Prediction entropy based (Salem et al., 2018)
이 방법은 모델의 출력 확률 분포 의 엔트로피를 이용해 데이터 포인트의 학습 여부를 판단한다. 엔트로피는 다음과 같이 계산된다:
엔트로피 값이 낮을수록 모델이 해당 데이터 포인트에 대해 확신을 가지고 있다는 뜻이며, 이는 해당 데이터가 학습 세트에 포함되었을 가능성이 크다는 것을 의미한다.
직관: 학습 데이터에 대해 모델은 더 낮은 엔트로피를 보이는 경향이 있다. 이는 모델이 학습 데이터에서 더 명확한 예측을 하기 때문이다.
데이터 추출 공격(Data extraction attacks)
데이터 추출 공격은 학습된 모델로부터 학습 데이터를 직접적으로 추출하는 것을 목표로 한다. 신경망은 종종 입력 데이터를 암기하는 경향이 있으며 (Carlini et al., 2019), 이를 이용한 추출 공격 기법이 존재한다. 예를 들어, 대형 언어 모델(LLM)에서의 추출 공격 사례가 있다 (Carlini et al., 2021).
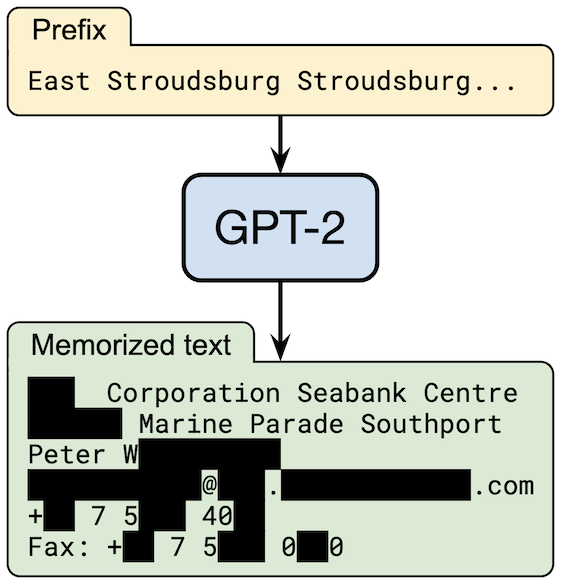
이것은 실제 사례이다. 일부 텍스트는 피해자의 프라이버시 보호를 위해 가려져 있다.
이 공격의 핵심 과정은 다음과 같다:
- 시퀀스 샘플링: 모델로부터 많은 시퀀스를 샘플링한다. 이를 위해 모델을 문장의 시작 토큰으로 초기화하고, 이후 반복적으로 자동회귀 방식을 통해 시퀀스를 생성한다.
- 멤버십 추론 공격 수행: 샘플링된 시퀀스 중에서 어떤 것이 학습 세트에 포함되었는지 결정하기 위해 멤버십 추론 공격을 수행한다. 기본적인 멤버십 추론 공격은 시퀀스의 퍼플렉서티(perplexity, PPL, '(무언가를 이해할 수 없어) 당혹스러운 정도)를 사용하여, 모델이 해당 시퀀스를 얼마나 잘 "예측"하는지를 평가한다. 주어진 토큰 시퀀스 과 모델 가 다음 단어의 확률을 예측할 때, 퍼플렉서티는 다음과 같이 정의된다:
이 기본 공격의 더욱 정교한 버전은 Carlini et al. (2021)에서 제시되었으며, 이를 통해 GPT-2에서 수백 개의 암기된 예제를 성공적으로 추출할 수 있었다.
프라이버시 누출에 대한 방어: 경험적 방어와 평가(Defending Against Privacy Leaks: Empirical Defenses and Evaluation)
프라이버시 공격에 대응하기 위한 여러 가지 방어 기법들이 제안되었다. 예를 들어, 멤버십 추론 공격을 방어하기 위해 다음과 같은 방법들이 시도될 수 있다:
- 상위 개의 클래스에 대한 예측만 출력하기
- 모델의 출력을 양자화하여 정밀도를 낮추기
- 모델 출력에 랜덤 노이즈 추가
- 확률 대신 클래스들을 순서대로 출력
- 학습 과정에서 정규화를 추가하기 (오버피팅이 프라이버시 누출의 원인일 가능성이 있음)
이러한 방어 방법 중 많은 것들이 제안되었지만, 실제로는 그 중 일부만이 효과적이다. 그렇다면 위의 방법들 중 일부를 어떻게 무력화할 수 있을까?
보안 분야에서 특히 경험적 방어는 "캣앤마우스" 게임과 유사한 양상을 띨 수 있다. 방어 기법을 평가하는 방법에 대해 생각해볼 필요가 있다.
방어 평가(Evaluating Defenses)
방어 기법을 평가하기 위한 첫 번째 단계는 보안 목표, 위협 모델, 그리고 평가 지표(evaluation metric, 예: 멤버십 추론 공격의 경우 F1-score)을 명확히 고정하는 것이다.
경험적 방어를 평가할 때, 커크호프의 원칙(Kerckhoffs’s principle)을 고려하는 것이 중요하다. 이 원칙에 따르면, 방어 기법은 공격자가 해당 방어에 대한 정보를 알고 있다고 가정하더라도 효과적이어야 한다. 이는 "비밀을 통한 보안"의 개념과는 반대되는 개념이다.
견고한 방어 기법은 위협 모델 내의 모든 공격자에 대해 보안 목표를 만족해야 한다. 하지만 실제로는 모든 가능한 공격자를 고려해 평가하는 것이 불가능하므로, 방어를 평가할 때는 공격자의 관점에서 가능한 한 방어를 깨뜨리려 시도한다. 이 시도가 실패할 때만 해당 방어 기법이 효과적이라고 결론지을 수 있다.
솔루션을 향하여: 차분 프라이버시(Towards a solution: differential privacy)
머신러닝에서 데이터 프라이버시 문제를 해결하기 위해, 경험적 방어와 같은 캣앤마우스 게임을 피할 수 있는 유망한 접근법으로 차분 프라이버시(Differential Privacy, DP)가 제안되었다 (Dwork et al., 2006).
차분 프라이버시는 알고리즘의 출력이 개별 데이터 포인트에 얼마나 의존할 수 있는지를 제한하는 프라이버시 정의이다. 데이터셋 에서 작동하는 랜덤화된 알고리즘 가 -차분 프라이버시를 만족하려면, 다음을 충족해야 한다:
여기서 는 의 가능한 출력 집합을 의미하며, 와 는 단 하나의 요소만 다른 두 데이터셋이다.
머신러닝의 맥락에서, 알고리즘 는 모델 학습 알고리즘이며, 입력은 데이터셋 이다. DP의 정의에 따라 학습 알고리즘은 데이터셋의 개별 데이터 포인트가 추가되거나 제거되더라도 출력 결과가 크게 변하지 않도록 보장된다. 즉, 모델은 특정 데이터 포인트에 지나치게 의존하지 않게 된다.
예를 들어, 차분 프라이버시 학습 알고리즘 중 하나인 DP-SGD(Abadi et al., 2016)는 모델이 학습 데이터에 대해 지나치게 의존하지 않도록 학습 절차를 설계하여 프라이버시를 보장한다.
그러나 DP를 실제로 적용하는 데는 어려움이 있다. 첫 번째 문제는 DP 정의에 포함된 매개변수 과 를 적절히 설정하는 것이 쉽지 않다는 것이다. 특정 데이터셋에 대해 이 두 매개변수를 설정했을 때, 그 값이 실제로 프라이버시 측면에서 어떤 의미를 가지는지 명확히 이해하기 어려울 수 있다. 또한, 과 값을 프라이버시 측면에서 유리하게 선택할 경우, 모델의 성능이 낮아지는 문제가 발생할 수 있다.
Resources
- Membership Inference Attacks on Machine Learning: A Survey
- A Survey of Privacy Attacks in Machine Learning
- Awesome Attacks on Machine Learning Privacy (big list of papers)
References
- Lecture (ver.2024): https://dcai.csail.mit.edu/2024
- Lab: Membership Inference (ipynb)
- Lecture (ver.2023): https://dcai.csail.mit.edu/2023
- Lab Session (ver.2023): https://github.com/dcai-course
- P.S. 본 포스팅 작성에는 OpenAI의 GPT-4o와 o1-preview가 활용되었습니다
