
(2) 데이터 저장소 관리
2-1. 데이터 저장소 선택 요약
다양한 AWS 스토리지 서비스 이해
Amazon S3: 객체 스토리지로 모든 양의 데이터를 저장하고 검색 가능- 사용 사례: 정적 콘텐츠, 백업, 미디어 파일, 데이터 레이크 등
Amazon EFS: 여러 EC2 인스턴스에서 공유할 수 있는 확장 가능한 완전 관리형 파일 스토리지- 사용 사례: 웹 호스팅, 콘텐츠 관리 시스템, 빅 데이터 처리 등
- 추가 파일 스토리지: Windows File Server용 Amazon FSx, Lustre용 Amazon FSx, NetApp ONTAP용 Amazon FSx
Amazon EBS: EC2 인스턴스에 연결된 영구 블록 수준 스토리지 볼륨- 사용 사례: 데이터베이스, 트랜잭션 애플리케이션 등
Amazon RDS: MySQL, PostgreSQL, Oracle, SQL Server 등을 위한 관리형 데이터베이스 서비스- 사용 사례: 관계형 데이터베이스 호스팅 및 관리
DynamoDB: 모든 규모에서 10밀리초 미만의 지연 시간을 제공하는 관리형 NoSQL 데이터베이스 서비스- 사용 사례: 실시간 데이터, 게임, IoT 등
Amazon Redshift: 분석 및 비즈니스 인텔리전스 워크로드를 위한 관리형 페타바이트 규모 데이터 웨어하우스 서비스- 사용 사례: 대용량 데이터 분석 및 고속 쿼리 처리
AWS Lake Formation: 데이터 레이크 구축, 보호 및 관리 서비스- 사용 사례: 구조화된 데이터와 비구조화된 데이터를 중앙 저장소에 통합
스토리지 선택 시 고려 사항
- 성능 요구 사항: IOPS, 확장성, 내구성, 데이터 액세스 패턴 등
- 고성능 파일 시스템: Lustre용 Amazon FSx
- 사용 사례: 고성능 컴퓨팅, 데이터 분석, 기계 학습 워크로드
- 인메모리 캐싱 및 짧은 지연 시간 액세스: ElastiCache
- 사용 사례: 자주 액세스하는 데이터, 세션 스토리지, 실시간 분석
Amazon Redshift 선택 이유
- 요구 사항: 30테라바이트의 비압축 데이터 저장, 매일 수백에서 수천 개의 집계된 쿼리, 여러 복잡한 조인
- 해결책: Amazon Redshift는 병렬 처리 및 열 형식 데이터 스토리지를 통해 최적의 쿼리 성능 제공
데이터 마이그레이션 및 원격 액세스 방법
- 데이터 마이그레이션: Amazon Redshift의 Copy 명령을 사용하여 S3 버킷 또는 Amazon EMR 클러스터에서 데이터를 로드
- 데이터 변환: 기본 변환과 다른 변환을 지정하거나 오류 발생 시 매개변수 설정 가능
특정 성능 요구 사항에 대한 스토리지 서비스 및 구성
- 최적화된 솔루션: 이전 데이터를 Amazon S3로 내보내고, 현재 데이터를 Amazon RDS에서 Amazon Redshift로 내보내는 일일 작업 생성. Redshift Spectrum을 사용하여 이전 데이터와 현재 데이터를 결합하여 보고서 생성
대규모 데이터의 SQL 인터페이스 처리 및 분석
- 솔루션: Amazon EMR에서 Hive를 사용하여 데이터를 SQL과 유사한 인터페이스로 처리 및 관리하고, DynamoDB 테이블에 데이터 저장
데이터 접근 권한 관리
- IAM: 클러스터 및 리소스에 대한 접근 제어
- 보안 그룹: 데이터 보호를 위한 추가 보안 계층
- 암호화 및 키 관리: AWS KMS를 사용한 데이터 암호화 및 키 관리
- 데이터베이스 감사: 데이터베이스 접근 및 변경 사항 추적 및 기록
2-2. 데이터 카탈로그 시스템 이해
- 데이터 카탈로그: 데이터의 위치, 설명, 스키마 및 실행 시간 메트릭에 대한 정보를 저장하는 메타데이터 저장소
- 사용자들은 연합 쿼리 작성, ETL 작업 등을 용이하게 수행할 수 있음
데이터 카탈로그 설정 및 통합
- 데이터 엔지니어는 데이터 카탈로그를 설정하고 데이터 파이프라인 및 스토리지 시스템과의 통합을 유지해야 함
- 데이터가 효과적으로 관리되고 쉽게 검색될 수 있도록 함
데이터 보안 및 거버넌스
- 데이터가 안전하게 보호되고 거버넌스 규정을 준수하는 것이 중요
- 데이터 변환이 빠르고 데이터 소비 도구가 효율적이더라도 데이터가 안전하지 않으면 그 가치는 떨어짐
- 따라서 데이터의 보안 및 규정을 준수하면서 분석 데이터셋이 쉽게 찾고 사용할 수 있도록 보장해야 함
데이터 분류 정책
- 데이터 웨어하우스 또는 데이터 레이크를 생성하려면 데이터를 카탈로그화해야 함
- 데이터 카탈로그는 ETL 작업의 소스 및 대상 데이터에 대한 참조를 포함
- 데이터 카탈로그의 정보는 메타데이터 테이블로 저장되며, 각 테이블은 단일 데이터 저장소를 지정
- 일반적으로 크롤러를 실행하여 데이터 저장소의 데이터를 인벤토리로 만듦
AWS Glue와 Athena
- AWS Glue 크롤러를 사용하여 데이터를 자동으로 데이터 카탈로그에 추가할 수 있음
- Athena는 데이터 카탈로그의 데이터베이스 및 테이블 정의를 사용하여 쿼리를 실행
- Lake Formation은 데이터 카탈로그에 키-값 속성을 추가할 수 있는 인터페이스를 제공
롤 기반 접근 제어
- 중앙 데이터 레이크에 대한 롤 기반 접근 제어를 설정하려면 각 AWS 계정에 데이터 레이크 스토리지를 구축하고 이를 중앙 데이터 레이크 계정에 카탈로그화 함
- 이후 각 계정의 S3 버킷 정책을 업데이트하고 Lake Formation 권한을 사용하여 더 구체적인 접근 권한을 부여
워크플로우 구축
- 데이터가 카탈로그화되고 적절한 메타데이터가 추가되도록 워크플로우를 구축해야 함
- 새로운 데이터가 수집된 후 AWS Glue 크롤러를 실행하여 데이터를 자동으로 데이터 카탈로그에 추가하는 것이 한 가지 방법임
데이터 카탈로그와 파티션 동기화
- 대규모 데이터셋이 특정 기준에 따라 파티션된 경우, 데이터 카탈로그를 최신 상태로 유지하여 효율적인 쿼리 및 분석을 보장해야 함
- AWS Glue는 파티션 동기화를 자동화하는 기능을 제공
소스 및 대상 연결 생성
- AWS Glue에서 소스 또는 대상 연결을 생성하여 다양한 데이터 소스와 타겟에서 데이터를 액세스, 카탈로그화 및 처리할 수 있음
- 예를 들어, S3 버킷을 데이터 소스로 연결하거나 Amazon RDS를 데이터베이스로 연결할 수 있습니다.
메타데이터 및 데이터 카탈로그 구성 요소
- 메타데이터 구성 요소
- 스키마 정보
- 데이터 타입 정보
- 데이터 소스 정보
- 타임스탬프
- 데이터 품질 메트릭
- 데이터 소유권 및 접근 제어
- 데이터 카탈로그 구성 요소
- 테이블 및 데이터베이스
- 테이블 스키마
- 파티션 정보
- 위치 및 저장 정보
- 통계 및 메타데이터 크롤링
- 데이터 계보 및 종속성 정보
- 태그 및 레이블
- 접근 제어 정책
- 분석 및 비즈니스 도구 통합
데이터 분류 및 보안
- 데이터 분류는 데이터의 민감도 또는 중요도에 따라 적절한 보안 통제 및 접근 정책을 적용하는 것을 포함
- IAM을 사용하여 AWS 서비스, 리소스 및 데이터에 대한 접근을 제어
- AWS KMS를 사용하여 데이터 암호화 키를 관리
- Amazon VPC와 보안 그룹을 사용하여 리소스에 대한 접근을 제어
- Amazon Macie를 사용하여 민감한 데이터를 자동으로 발견, 분류 및 보호
2-3. 데이터 수명주기 관리
데이터의 중요성 및 보존 기간
- 데이터의 중요성, 보존 기간, 데이터 접근 빈도는 데이터 관리의 핵심 요소
- 데이터셋의 쿼리 접근 패턴은 데이터 접근 빈도에 따라 달라짐
핫 데이터- 자주 접근되고 실시간으로 처리되는 데이터(실시간 분석, 운영 데이터베이스, 사용자 세션 정보)
- 고성능 스토리지 시스템 사용(Amazon RDS, Amazon Aurora, Amazon DynamoDB)
웜 데이터- 자주는 아니지만 주기적으로 조회되는 데이터, 핫 데이터보다는 접근 빈도가 낮지만 빠른 응답 시간 필요(월간 보고서, 주기적 분석 데이터)
- 중간 성능의 스토리지 시스템 사용(Amazon S3 Standard, Amazon S3 Intelligent-Tiering)
콜드 데이터- 거의 접근되지 않으며, 보관 목적의 저장 데이터(오래된 로그, 아카이브 데이터, 규제 준수를 위한 보관)
- 비용 효율적인 스토리지 시스템 사용(Amazon S3 Glacier, Amazon S3 Glacier Deep Archive)
- 일반적으로 최신 데이터는 오래된 데이터보다 더 자주 접근됨
스토리지 계층 및 비용 최적화
- 데이터의 스토리지 계층을 선택할 때 각 계층의 비용을 고려해야 함
- 모든 데이터를 핫 데이터로 저장하면 높은 저장 비용이 발생하며, 반면 콜드 스토리지에 저장하면 검색 시간이 길어지고 검색 비용이 높아질 수 있음
- Amazon S3를 사용하는 경우 S3 라이프사이클 정책을 통해 데이터의 스토리지 계층을 변경하거나 삭제할 수 있음
- Amazon Redshift의 경우, 클러스터 크기를 조정하여 컴퓨팅 및 스토리지 옵션을 사용할 수 있음
데이터 보존 및 재생성
- 데이터 보존 정책과 아카이브 전략을 통해 데이터를 일정 기간 동안 보관하고 검색할 수 있어야 함
- 일부 규제 및 준수 요구 사항에 따라 데이터를 특정 기간 동안 보관해야 할 수도 있음
- 데이터를 정확하게 분류하는 것이 중요
데이터 보호 및 가용성
- 적절한 복원력과 가용성을 갖춘 데이터를 보호하려면 내구성, 가용성 및 장애 복구를 보장하는 AWS 서비스를 사용해야 함
- Amazon S3는 데이터를 여러 가용 영역에 자동으로 복제하여 높은 가용성과 내구성을 보장함
- Amazon RDS는 다중 AZ 구성을 통해 가용 영역 장애 시 자동 장애 조치를 제공
- 백업 및 복구 전략도 데이터 보호의 중요한 요소
데이터 삭제 및 유지 관리
- DynamoDB의 타임 투 라이브(TTL) 기능을 사용하여 특정 타임스탬프 이후에 항목을 자동으로 삭제할 수 있음
- Amazon Redshift의 경우, 고정된 보존 기간이 있는 데이터를 시간 시퀀스 테이블로 조직하여 쿼리 성능 문제를 해결할 수 있음
- 오래된 테이블을 드롭하면 대규모 삭제 프로세스를 실행하지 않아도 되며, 이는 비용과 시간을 절약할 수 있음
스토리지 비용 최적화
- 여러 소스에서 수집된 대량의 CSV 형식 데이터를 Amazon S3 버킷에 저장하고, Athena를 사용하여 이 데이터를 쿼리하는 경우, 데이터를 압축, 파티셔닝 및 컬럼 형식으로 변환하여 저장 비용을 최적화할 수 있음
- 6개월 후에 데이터를 S3 Standard-Infrequent Access로 전환하고, 2년 후에는 Amazon S3 Glacier로 전환할 수 있음
2-4. 데이터 모델 설계 및 스키마 진화
데이터 모델링의 중요성
- 데이터를 유용한 형태로 변환하여 비즈니스 인사이트 도출
- 다양한 데이터 소스와 사용 사례에 맞는 모델링 적용 필요
AWS 데이터 모델링 지원
-
Amazon Redshift: 스타 스키마, 스노우플레이크 스키마 지원
Star Schema- 단순한 데이터 모델로, 중앙에 하나의 팩트테이블과 이를 둘러싼 여러 디멘전테이블로 구성
- 데이터 웨어하우스의 데이터를 구조화하는데 유용
- Fact Table: 트랜잭션 데이터나 측정값을 저장
- Dimension Table: 사실 테이블의 각 항목을 설명하는 메타데이터를 포함
- 설계 장점: 단순하고 이해하기 쉬우며 쿼리가 빠름
- 사용 예시: 판매 데이터 분석, 재고 관리 등
Snowflake Schema- 스타 스키마의 확장된 형태로, 차원 테이블이 더 작은 하위 차원 테이블로 정규화
- 데이터 중복을 줄이고 저장 공간을 절약
- Category Dimension Table: 각 차원 테이블이 하위 차원 테이블로 나뉘어 정규화됨
- 설계 장점: 데이터 중복 감소, 저장 공간 절약
- 설계 단점: 더 복잡한 쿼리, 조인 연산 증가로 성능 저하 가능성
- 사용 예시: 대규모 데이터 웨어하우스, 복잡한 분석 요구 사항
- Star Schema vs Snowflake Schema
- Star Schema
- 단순하고 직관적이며 쿼리 성능이 뛰어남
- 데이터 중복이 있을 수 있음
- Snowflake Schema
- 정규화를 통해 데이터 중복을 줄이고 저장 공간을 절약
- 쿼리가 복잡하고 조인 연산이 많아질 수 있음
- Star Schema
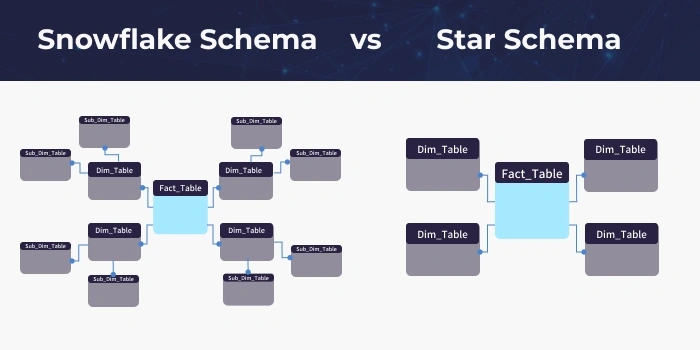
-
Inmon 및 데이터 볼트 모델링 패턴 구현 가능
-
Amazon Redshift Serverless: 데이터 웨어하우스로 데이터를 가져와 쿼리, 스키마 및 테이블 생성, 데이터 시각화 및 탐색
데이터 처리 프레임워크
- Spark: Amazon EMR, Amazon S3, AWS Glue와 결합하여 대규모 데이터 처리 파이프라인 구축
- Amazon EMR: 온디맨드로 Spark 클러스터 실행, 데이터 병렬 처리 및 클러스터 확장
- Amazon S3: 데이터를 직접 Spark DataFrames 또는 RDD로 읽기
- AWS Glue: 데이터 크롤러로 Amazon S3의 구조화된 데이터 스키마 자동 추론 및 데이터 카탈로그에 테이블 생성
데이터 정확성 및 신뢰성 확보
- 데이터 계보(Data Lineage): 데이터의 원천, 변환 및 흐름 추적
- SageMaker ML Lineage Tracking: 기계 학습 관련 데이터 계보 추적
인덱싱, 파티셔닝 전략, 압축 및 최적화
- Amazon RDS: 자주 사용되는 컬럼에 인덱스 생성
- DynamoDB: 효율적인 쿼리 패턴을 지원하는 기본 키 및 보조 인덱스 선택
- Amazon S3: 대규모 데이터셋 파티셔닝
- Amazon Redshift: 분포 키 및 정렬 키 사용
- 압축: gzip, bzip2 등 지원 압축 형식 사용
- 데이터 아카이빙 및 보존 정책: 비용 효율적인 스토리지 계층 사용(Amazon S3 Glacier 등)
스키마 진화 기법
- DynamoDB: 애플리케이션 업데이트를 통해 새로운 속성 또는 스키마 변경 적용
- Amazon RDS 및 Aurora: AWS DMS 사용하여 최소 다운타임으로 스키마 변경 수행
- 데이터 레이크: 스키마 온 리드 접근 방식 사용
- AWS Glue: 자동 ETL 작업을 통해 데이터 스키마 변환 관리
스키마 진화 관련 문제 예방
- 데드 레터 큐: 스키마 진화 문제 해결을 위한 첫 번째 생각
- 스키마 레지스트리: 스키마 검증 및 버전 관리
- 백업 및 모니터링: 스키마 변경 전 백업 수행 및 모니터링 설정
데이터 모델링 및 스키마 진화 최적화
- AWS SCT: 데이터베이스 엔진 간 스키마 변환
- AWS DMS: AWS SCT와 함께 소스 데이터베이스 스키마 변환 지원
Reference
- Exam Prep Standard Course: AWS Certified Data Engineer – Associate (DEA-C01)
- Star Schema vs Snowflake Schema

데이터엔지니어입니다😁