Presto란
- 고성능 ANSI SQL 엔진
- 모든 연결된 데이터 소스에 대한 SQL 지원
- 비용 기반 쿼리 최적화 프로그램
- 입증된 수평 확장성
- 컴퓨팅과 스토리지의 분리
- 쿼리 처리 및 데이터 확장 독립적으로 소스
- 스토리지 직접 쿼리
- ETL 또는 데이터 통합이 필수가 아님
Presto 장점
- 빠른 접근성
- 고성능 쿼리 처리
- 사용자의 진입 장벽이 낮음
- 대규모 확장성
- 높은 동시성
- 스토리지에 직접 액세스
- 비용 절감
- 복사 필요성 및 데이터 이동 감소
- 복잡한 데이터 처리 방지
- 스토리지 확장 및 컴퓨팅 독립실행
- 실행은 쿼리 처리 중에만 계산
- 하나의 데이터 소비층
- 데이터 잠김 방지
- 데이터 사일로 X
- 가지고 있는 스택과 툴로 쿼리 처리(SQL + BI)
- 어떤 데이터 소스도 쿼리 처리
- 데이터 이동
- 선택적 테이블 생성
쿼리 수명주기(Query lifecycle)
Parsing
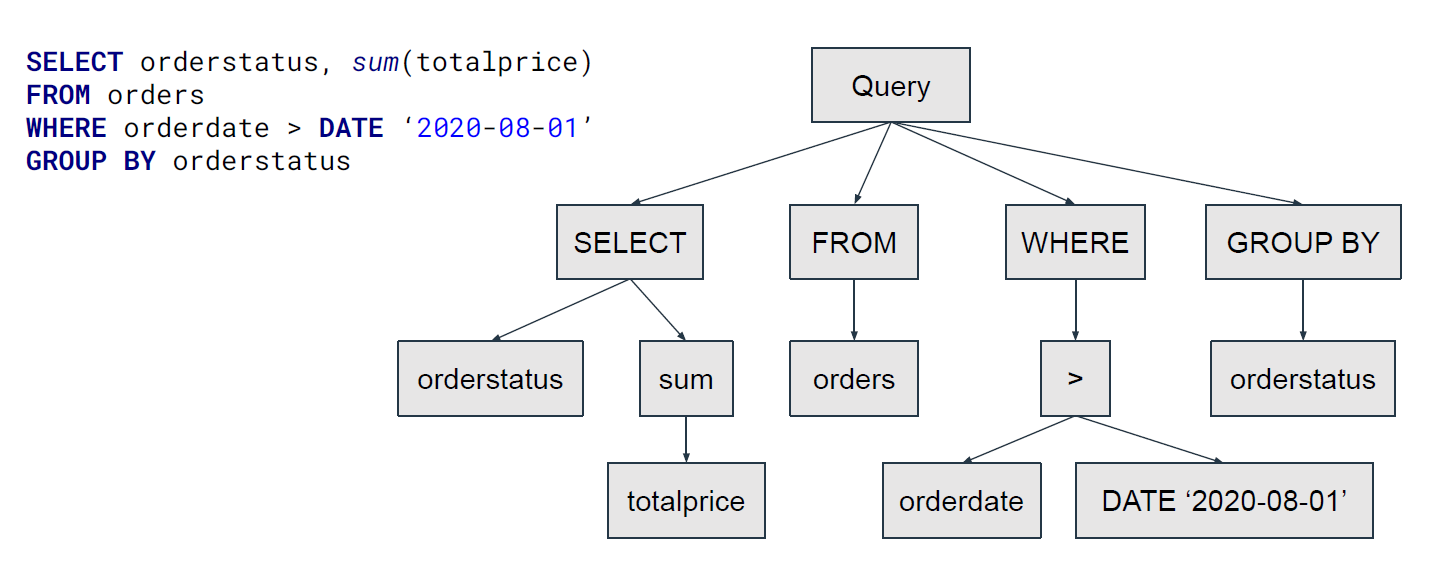
Analysis
쿼리 계획(Planning)
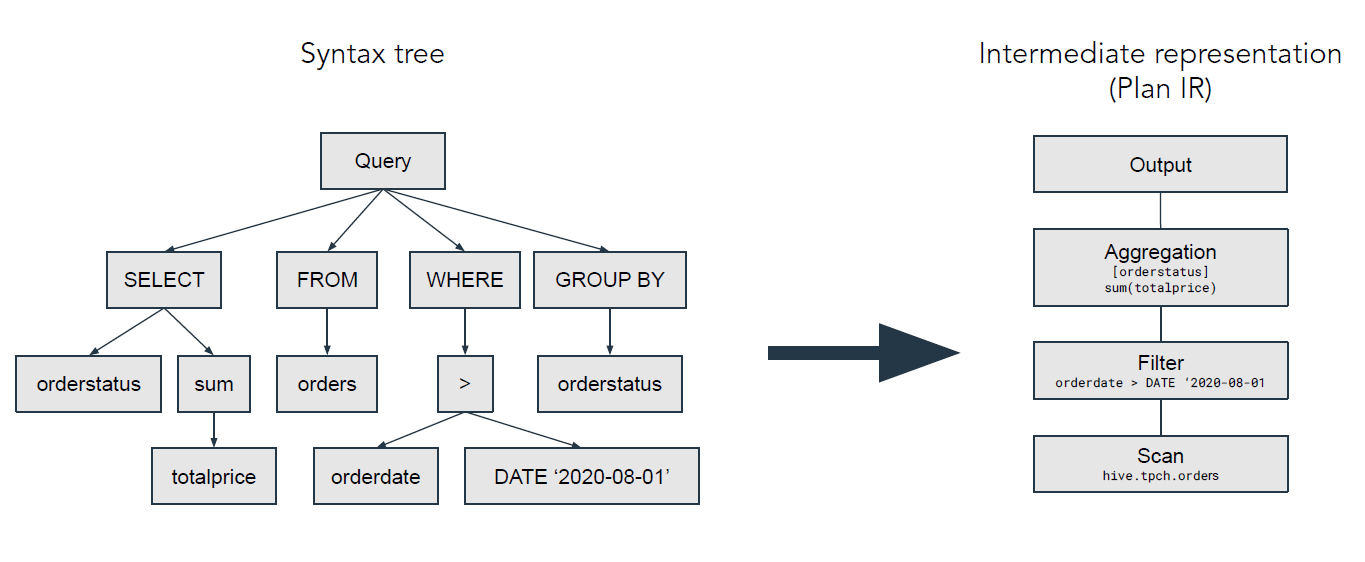
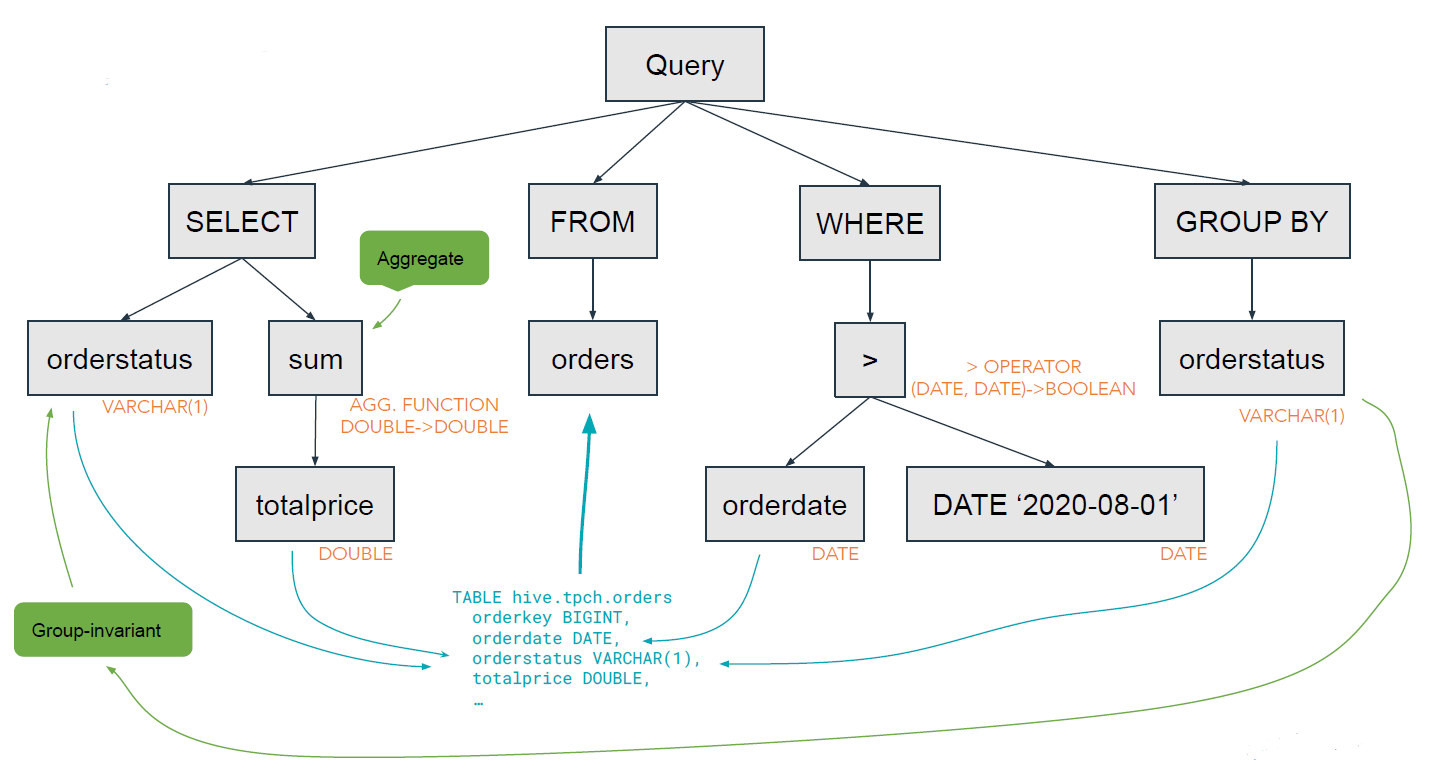
- Output
- CSV, JSON, XML과 같은 형식을 사용하며 최종 결과를 표현
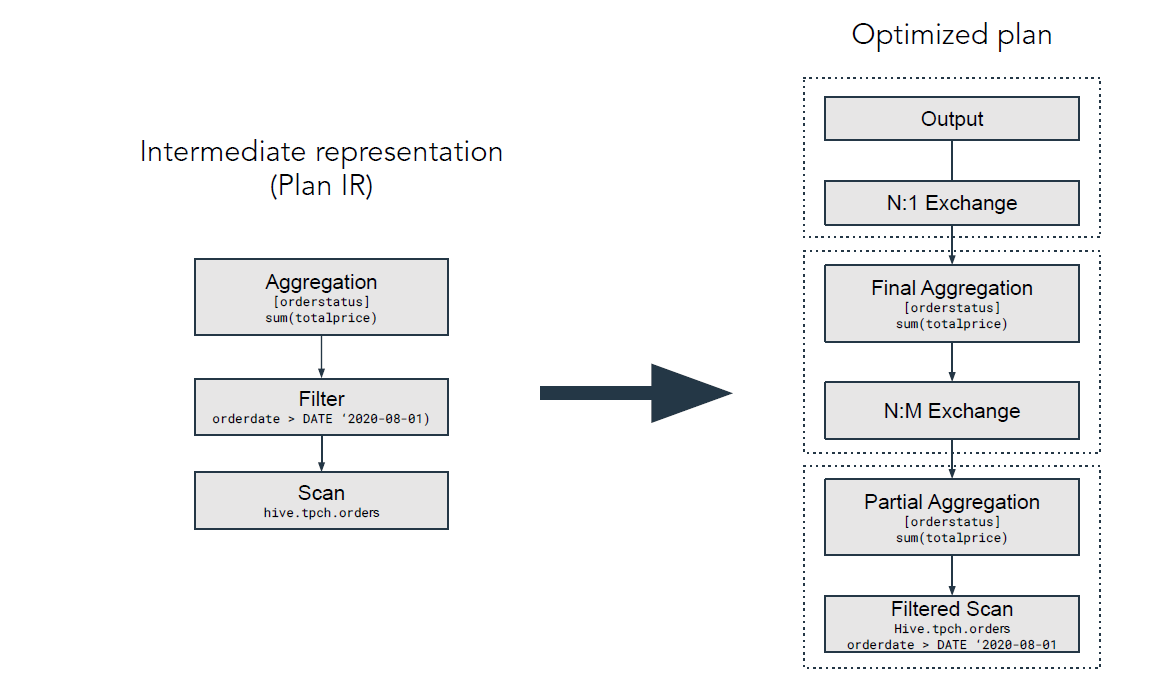
- Aggregation
- 집계 COUNT, SUM, AVG, MIN, MAX 등
- Filter
- 만족하는 조건만 선택하는 프로세스: =, !=, >, <, >=, <=
- Scan
- 데이터를 읽는 프로세스
- 다양한 DB 프로토콜을 지원하며 JDBC, ODBC를 일반적으로 사용
쿼리 최적화(Optimization)
스케줄링과 실행(Scheduling and execution)
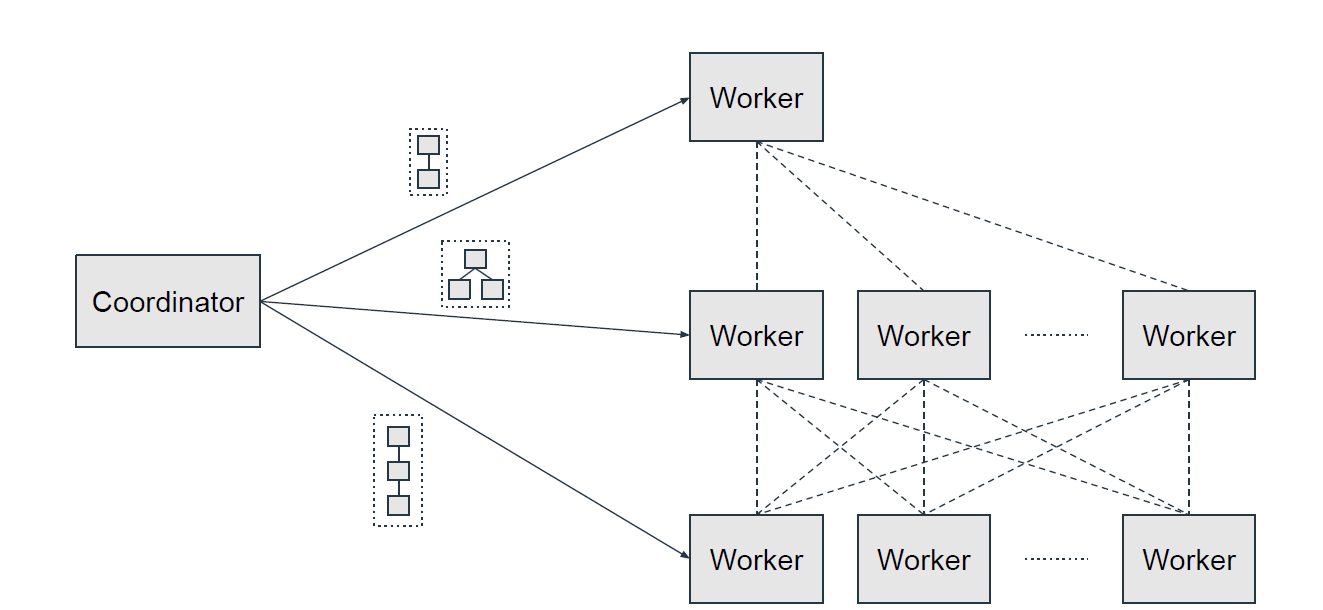
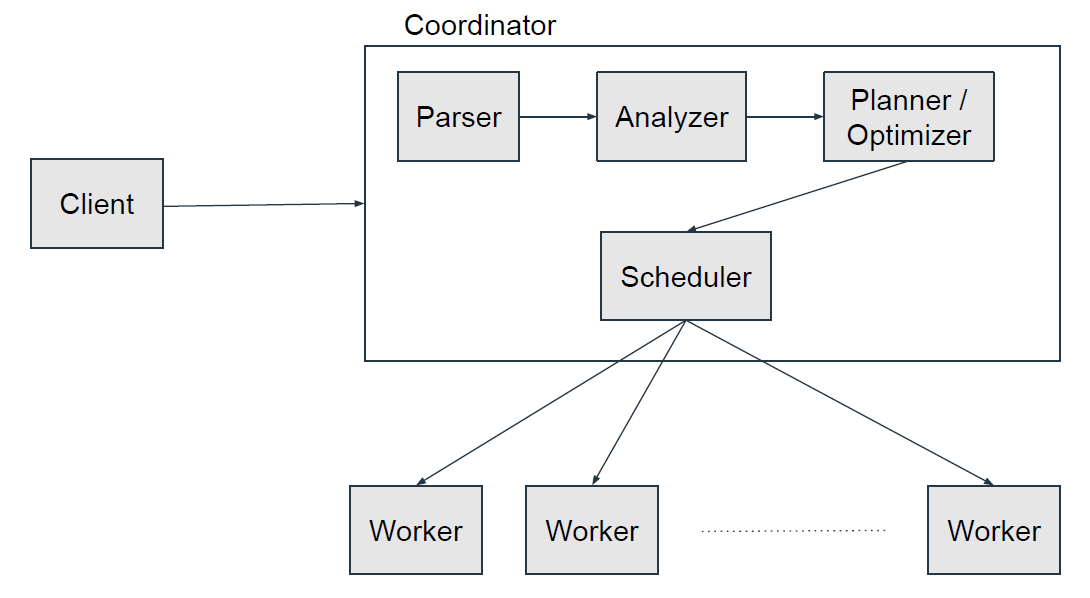
- Coordinator
- 명령문 구문 분석, 쿼리 계획 및 worker 노드 관리를 담당하는 서버
- 클라이언트가 실행을 위해 명령문을 제출하기 위해 연결하는 노드
- 모든 Presto 설치에는 1개 이상의 worker와 coordinator가 있어야 함
- Presto의 단일 인스턴스가 두 역할을 모두 수행하도록 구성할 수 있음
- worker의 활동을 추적 쿼리 실행을 조정함
- 쿼리의 논리적 모델을 생성한 다음 Presto worker 클러스터에서 실행되는 일련의 연결 작업으로 변환
- Coordinator는 REST API를 사용하여 worker 및 클라이언트와 통신
- Worker
- 작업 실행 및 데이터 처리를 담당하는 Presto 설치의 서버
- Worker 노드는 커넥터에서 데이터를 가져오고 서로 중간 데이터를 교환
- Coordinator는 Worker로부터 결과를 가져오고 최종 결과를 클라이언트에게 반환
- Worker 노드의 프로세스가 시작되면 Coordinator의 검색 서버에 자신을 알리고, 이를 통해 Presto Coordinator에서 작업 실행을 사용할 수 있게 됨
- Worker는 REST API를 사용하여 다른 Worker 및 Presto Coordinator와 통신
Reference

데이터엔지니어입니다😁