
결측치
데이터에 결측치가 있어 모델 학습이 되지 않는 문제가 발생할 때,
- NaN : 값이 없는 결측으로 대체, 추정, 예측으로 처리
- None : '값이 없는 것'이 값인 결측으로 새로운 값으로 정의하는 방식으로 처리
- 해당 도메인 지식이 있으면 좀 더 정확하게 대처 가능.
상황에 따른 처리 방법 : 결측치 예측 모델
- 결측이 발생되지 않은 컬럼을 바탕으로 결측치를 예측하는 모델을 학습하고 활용.
- 결측치가 있는 컬럼에서 같은 인덱스행에 결측치가 없는 컬럼 참조
- 결측치가 없는 컬럼을 바탕으로 모델 생성
- 생성된 모델로 결측치 예측
- 주의점
- 결측이 소수 컬럼에 쏠리면 안 된다.(한 두 컬럼에 결측값이 몰려있는 경우 -> 라벨 값(결측 컬럼) 자체가 부족) 쏠리더라도 결측치를 제외하더라도 데이터가 매우 많다면 사용 가능.
- 특징 간 관계가 존재해야 한다.(컬럼 사이가 완전히 독립이라면 의미가 없다)
- 다른 결측치 처리 방법에 비해 시간이 오래 소요된다.
- sklearn.impute.KNNImputer
결측이 아닌 값만 사용하여 이웃을 구한 뒤, 이웃들의 값의 대표값으로 결측을 대체하는 결측치 예측 모델
주요인자 : n_neighbors=이웃수(5가 적당)
다음과 같은 데이터를 가지고 결측치를 채워보자.
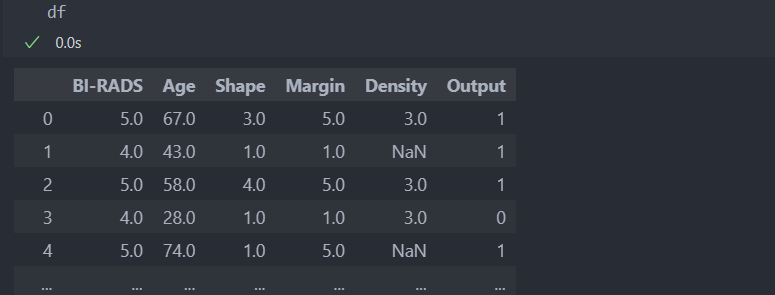
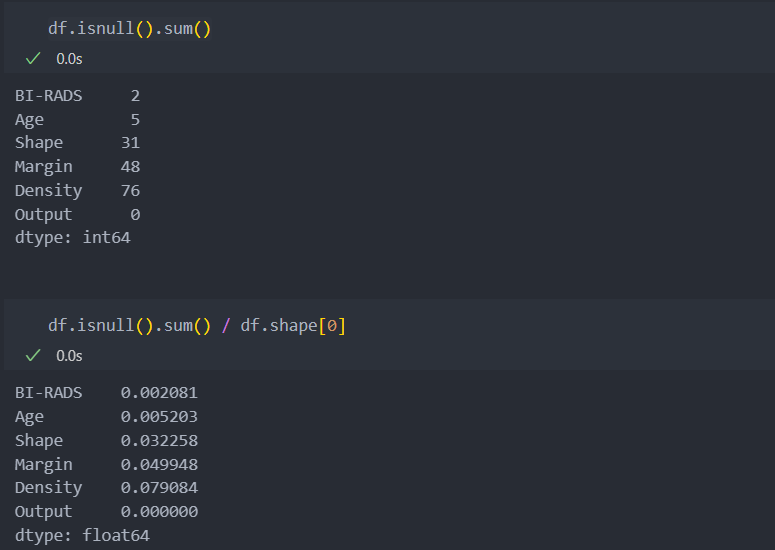
결측치 수와 비율을 확인해보자.
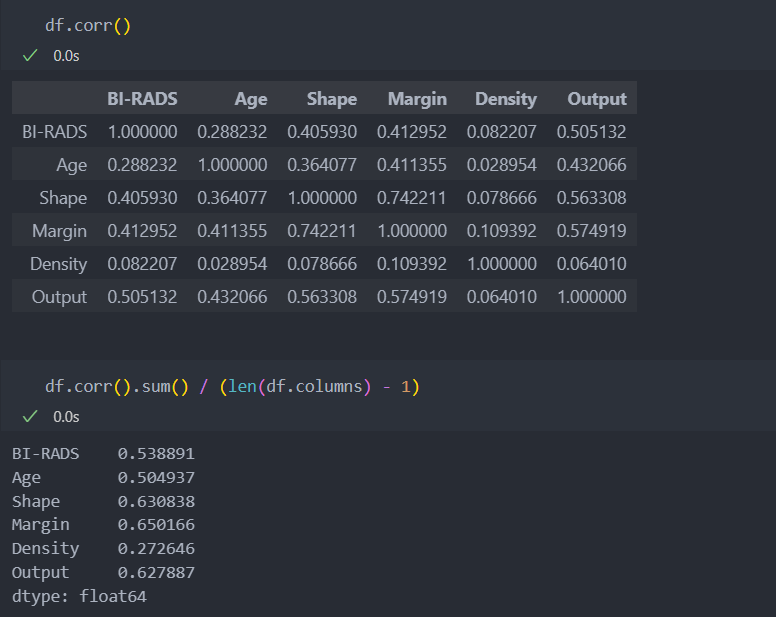
그리고 데이터 컬럼 간 상관성이 있어야 적용할 수 있으니, 컬럼별 상관 관계를 살펴보자.
다음과 같이 컬럼별로 관계성이 있다고 판단할 수 있다.
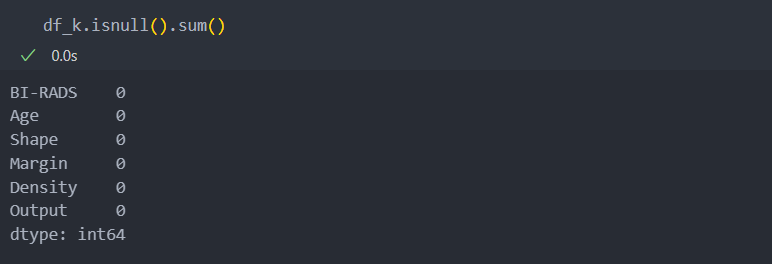
이제 예측 모델을 활용하여 결측치에 값을 채워보자.
# 결측치 예측 모델
rom sklearn.impute import KNNImputer
# KNN Imputer 인스턴스화
KI = KNNImputer(n_neighbors = 5)
# KNN Imputer 학습
KI.fit(df)
# 결측 대체를 한 후 다시 DataFrame화
df_k = pd.DataFrame(KI.transform(df), columns = df.columns)결측치에 값이 제대로 채워졌는지 확인해보자.

데이터 굽는 타자기