범주형 변수 문제
범주형 변수는 상태 공간의 크기가 유한한 변수를 의미하며, 반드시 도메인이나 변수의 상태 공간을 바탕으로 판단.
- 단순히 문자형은 범주형, 숫자형이면 연속형이라고 판단하면 위험할 수 있으며, 변수의 상태 공간 확인 작업을 해야한다.(ex. 5(월))
데이터에 범주형 변수가 포함되어 있어, 대다수의 지도 학습 모델이 학습되지 않거나 비정상적으로 학습되는 문제.
- str 타입의 범주형 변수가 포함되면 대다수의 지도 학습 모델 자체가 학습이 되지 않음.
- int/float 타입의 변수형 변수는 모델 학습은 되나, 비정상적으로 학습이 됨.
모델 학습을 위해 변주형 변수는 반드시 숫자로 변환.
- ex. 초등학생=1, 중학생=2, 고등학생=3, 대학생=4 는 '배수'의 관계가 아님.
더미화
가장 일반적으로 범주형 변수를 변환하는 방법.
- 간편히 쓸 수 있다.
- 범주 변수가 많으면 컬럼이 많아질 수 있다.
- 희소성 : 한 변수가 가지는 변수가 많아지면 변수가 희소해진다.
연속형 변수로 치환
- 범주형 변수의 상태 공간 크기가 클 때, 더미화는 과하게 많은 변수를 추가해서 차원의 저주 문제로 이어질 수 있음.
- 라벨 정보를 활용하여 범주 변수를 연속형 변수로 치환하면 기존 변수가 가지는 정보가 일부 손실될 수 있고 활용이 어려움.
- 차원의 크기가 변하지 않으며 더 효율적인 변수로 변환 가능.
OneHotCategoricalEncoder
from feature_engine.categorical_encoders import OneHotCategoricalEncoder as OHE
에러 발생 시, feature_engine 지우고 0.6.1버전으로 다시 다운로드 해야한다.
# 삭제
pip uninstall feature_engine
# 다시 설치
pip install feature_engine==0.6.1더미화를 하기 위한 함수로 sklearn의 인스턴스의 방법과 유사
주요인자
- variables : 더미화 대상이 되는 범주형 변수의 이름 목록(해당 변수는 str 타입)
- drop_last : 한 범주 변수로부터 만든 더미 변수 가운데 마지막 더미 변수를 제거할지 결정
- top_categories : 한 범주 변수로부터 만드는 더미 변수 개수를 설정, 빈도 기준으로 슬라이싱
- pandas.get_dummies() : 인스턴스로 만들지 않기 때문에 새로운 데이터에 대해서 같은 방식으로 적용이 불가능
실습
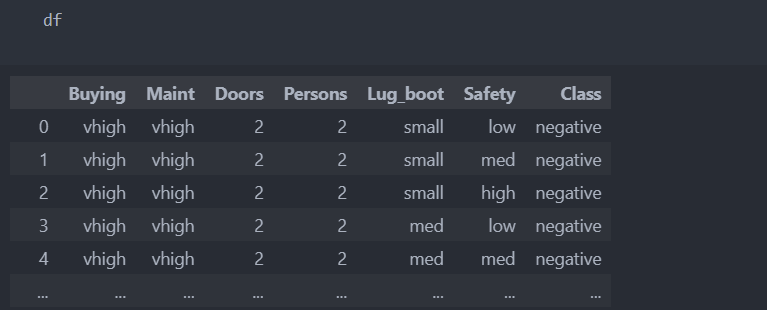
다음과 같은 데이터가 있다.
분리
데이터를 데이터와 라벨로 나누고 학습/평가 데이터로 분리시키자.
# 특징과 라벨 분리
X = df.drop('Class', axis = 1)
Y = df['Class']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)라벨 데이터 확인
분리시킨 데이터의 '라벨'을 확인해보니 P/N로 되어 있다.
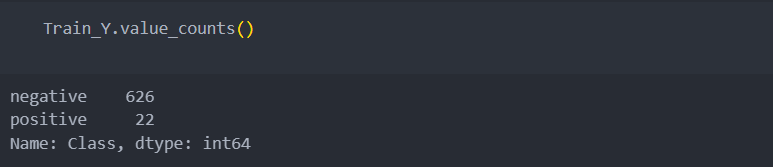
더미화가 아닌 숫자로 대체하도록 하자.
# 문자 라벨을 숫자로 치환
Train_Y.replace({"negative":-1, "positive":1}, inplace = True)
Test_Y.replace({"negative":-1, "positive":1}, inplace = True)data 확인
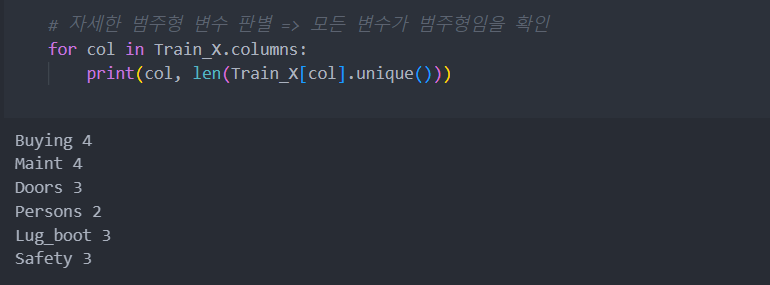
위에서 보았듯이 data는 범주형 변수로 보이는데 확인해 보면, 모든 변수가 범주형임을 알 수 있다.
더미화
더미화를 위해 str 타입으로 바꿔주자.(OneHotCategoricalEncoder는 str 타입에서만 작동)
Train_X = Train_X.astype(str) # 모든 변수가 범주이므로, 더미화를 위해 전부 string 타입으로 변환그리고 OneHotCategoricalEncoder 불러와서 학습하여 적용시켜 보자.
from feature_engine.categorical_encoders import OneHotCategoricalEncoder as OHE
# 인스턴스화
dummy_model = OHE(variables = Train_X.columns.tolist(), # variables : 리스트 형태로 컬럼을 입력을 받는다.
drop_last = True)
# 학습
dummy_model.fit(Train_X)
# 적용
d_Train_X = dummy_model.transform(Train_X)
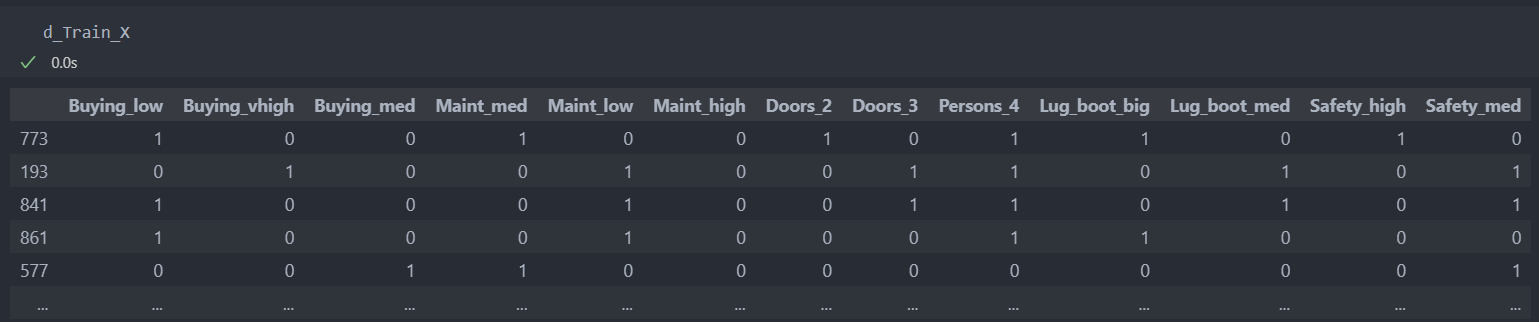
d_Test_X = dummy_model.transform(Test_X)적용된 데이터를 확인해 보면 더미화가 적용된 것을 볼 수 있다.
이제 새로운 데이터가 추가되더라도 이 더미 모델을 활용하여 똑같은 방식으로 더미화를 할 수 있게 된다.
연속형 변수로 치환
class 컬럼을 기준으로 범주형 변수를 연속형 변수로 치환해보자.
'data'와 'label'로 나눈 데이터를 다시 합쳐주고,
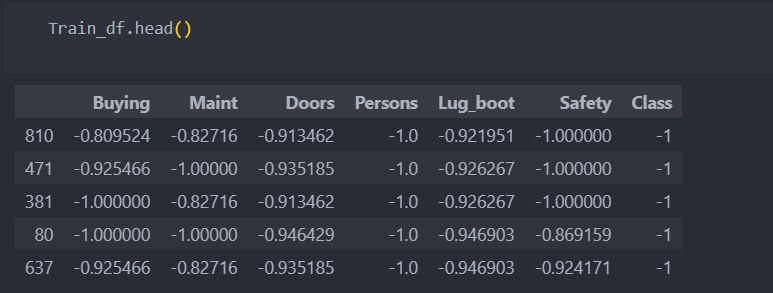
Train_df = pd.concat([Train_X, Train_Y], axis = 1) # 옆으로 이어붙임각 컬럼의 해당 변수들에 대한 class의 평균값으로 바꿔준다.
for col in Train_X.columns: # 보통은 범주 변수만 순회
temp_dict = Train_df.groupby(col)['Class'].mean().to_dict() # 해당 col의 변수에 따른 Class의 평균을 나타내는 사전 (replace를 쓰기 위해, 사전으로 만듦)
Train_df[col] = Train_df[col].replace(temp_dict) # 변수 치환
Test_X[col] = Test_X[col].astype(str).replace(temp_dict) # 테스트 데이터도 같이 치환해줘야 함 (나중에 활용하기 위해서는 저장도 필요)