
가설 검정
수집된 데이터를 바탕으로 모집단의 특성의 가설에 대한 통계적 유의성을 검정하는 일련의 과정.
- 수집된 데이터는 대부분 샘플이며(모집단의 부분집합) 모집단 전체를 알 수 없는 경우가 대부분.
- 통계적 유의성 : 수집된 데이터가 확률적으로 의미가 있는 경우.
- 단계 : 영 가설(귀무가설) & 대립 가설 설정 -> 검정 통계량 설정 -> 기각역 설정 -> 검정통계량 계산 -> 의사 결정
영 가설(귀무 가설)과 대립 가설
- 영 가설 : 특정 데이터가 없으면 '참'으로 추정(ex. 무죄 추정의 원칙)
- 대립 가설 : 특정 데이터가 없으면 '거짓'으로 추정하며 관심 대상인 가설.
카이제곱 검정
두 변주형 변수가 서로 독립적인지 검정(영 가설: 두 변수가 서로 독립)
남/여 만족도 데이터를 가지고 살펴보자.
교차 테이블과 기대값
- 교차 테이블(contingency table)은 두 변수가 취할 수 있는 값의 조합의 출현 빈도
- 기대값 : (값 i를 갖는 샘플 수 * 값 j를 갖는 샘플 수) / 전체 샘플 수
pandas 모듈인 crosstab(변수A, 변수B)로 교차 테이블을 사용하여 실제값을 확인해보자.
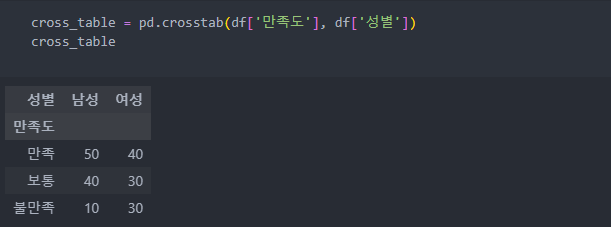
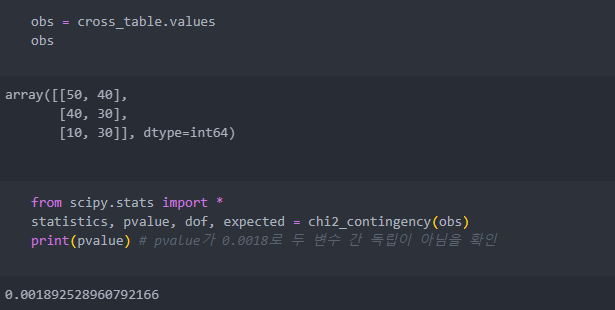
교차테이블을 통해 얻은 수치를 scipy 모듈을 사용하여 검증하기 위해서 value값만 가져와서 서로 독립인지 확인하자.
p-value(유의 수준: 0.05)가 낮은 수준인 것으로 보아 서로 독립적이지 않다는 것을 예측할 수 있다.
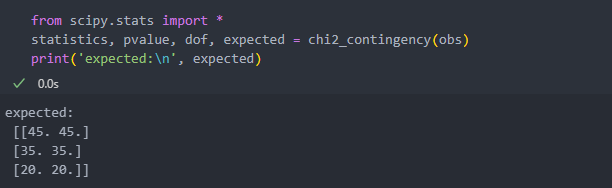
카이제곱 검증을 통한 기대값은 expected를 통해 확인할 수 있는데, p-value에서 확인했듯 실제값과 기대값의 차이가 발생한 것을 확인할 수 있다.
카이제곱 통계량
기대값과 실제값 차이를 바탕으로 정의.
기대값과 실제값의 차이가 클수록 통계량이 커지며, 통계량이 커질수록 영 가설이 기각될 가능성이 높음
실제값과 기대값을 비교하기 위해서 기대값 expected를 데이터 프레임으로 만든 후
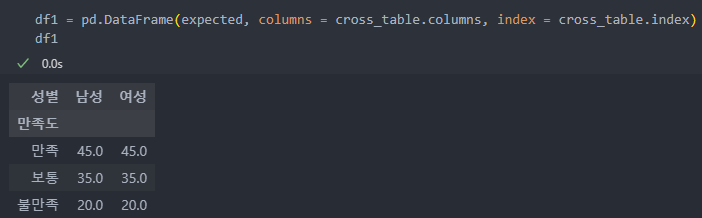
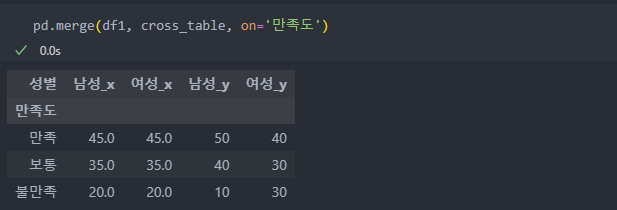
실제값과 merge하여 확인해보자.
_x가 기대값이고 _y가 실제값이다.
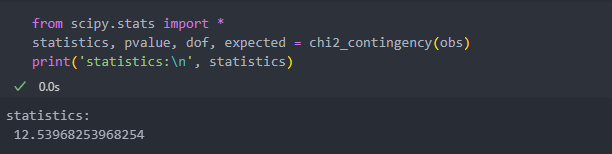
그리고 카이제곱 통계량은 아래와 같다.

데이터 굽는 타자기