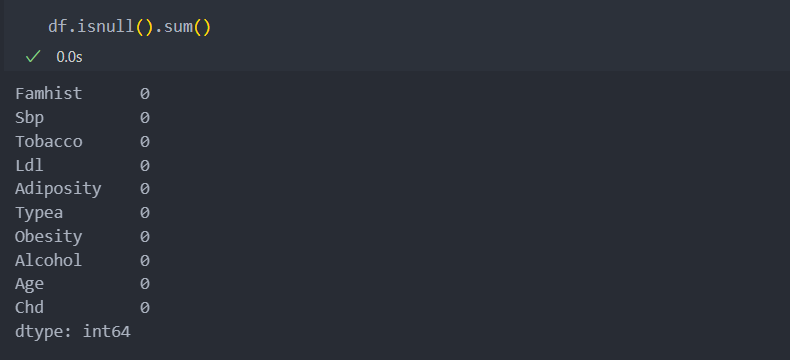
결측치
데이터에 결측치가 있어 모델 학습이 되지 않는 문제가 발생할 때,
- NaN : 값이 없는 결측으로 대체, 추정, 예측으로 처리
- None : '값이 없는 것'이 값인 결측으로 새로운 값으로 정의하는 방식으로 처리
- 해당 도메인 지식이 있으면 좀 더 정확하게 대처 가능.
상황에 따른 처리 방법 : 대표값으로 대체(Simplelmpute)
Simplelmpute를 사용하기 부적절한 경우
- 소수 특징에 결측이 쏠린 경우(ex. 결측이 너무 많아, 결측이 아닌 데이터가 대표성을 띄지 못하는 경우)
- 특징 간 상관성이 큰 경우(ex. XOR 데이터류)
sklearn.impute.Simplelmpute을 이용한 전처리 모델
주요인자
- strategy : 대표 통계량을 지정('mean', 'most_frequent', 'median')
- 주의: 전처리 모델을 이용할 때에도 test data에 fit은 하지 않고 transform만 한다.
모든 특징의 타입이 같은 경우
다음과 같은 데이터가 있다.
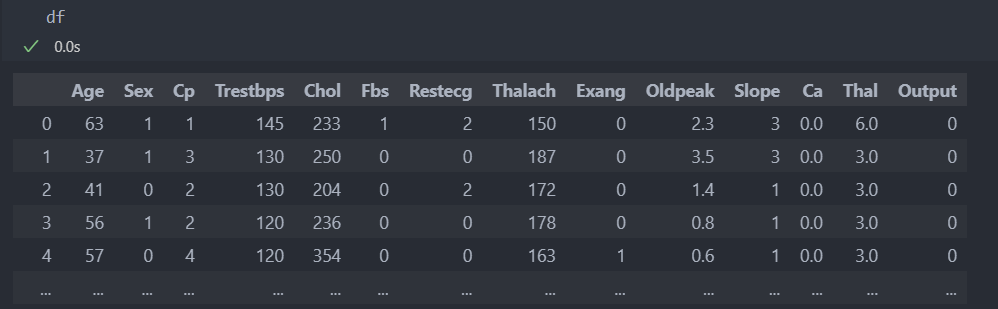
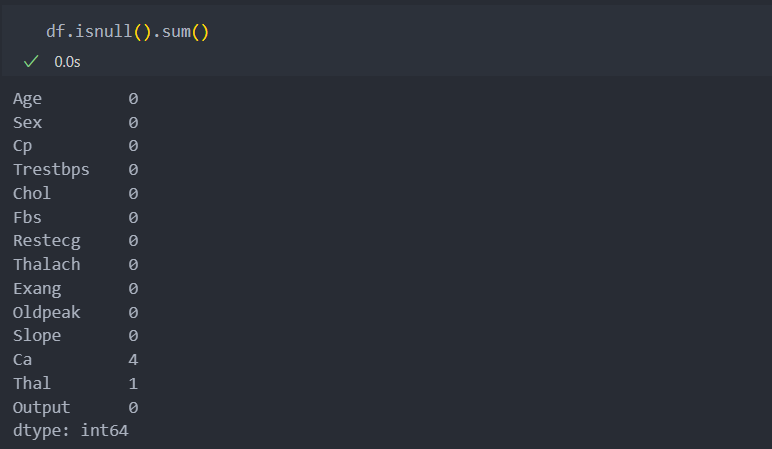
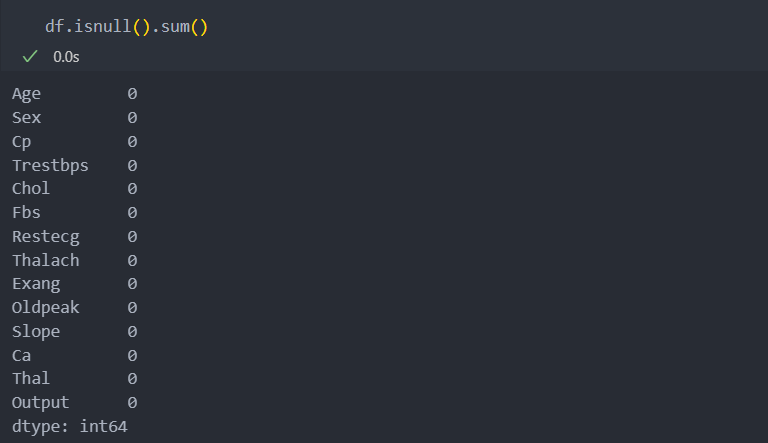
각 컬럼별 결측치를 확인해보자.
컬럼 'Ca'와 'Thal'결측값이 있다는 것을 확인할 수 있다.
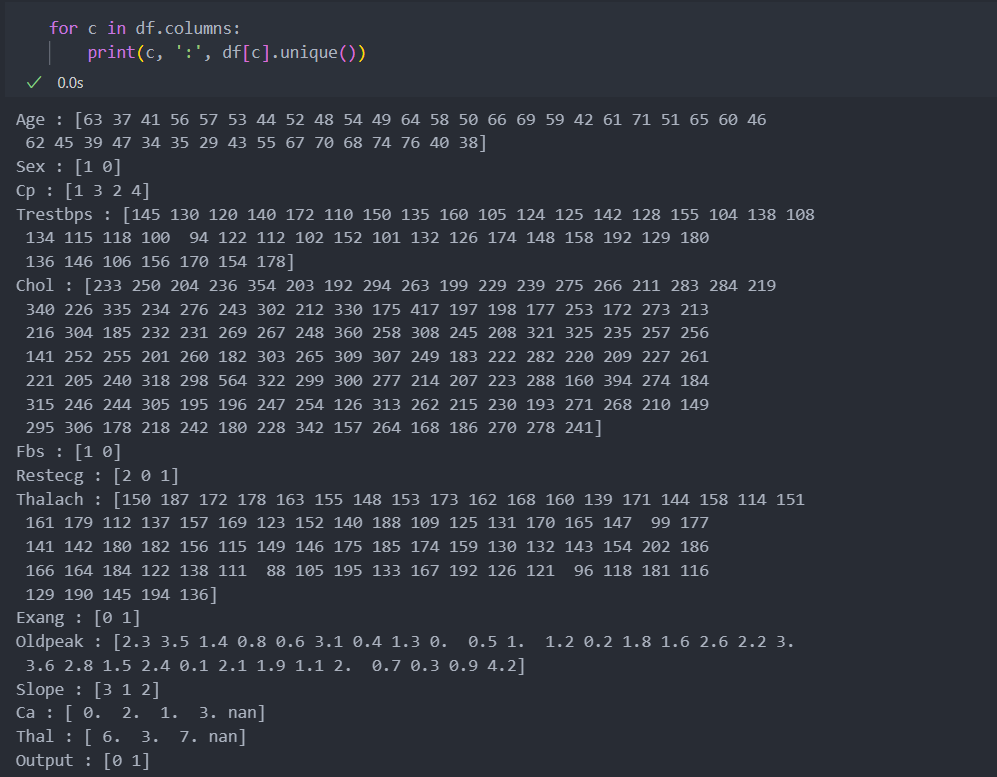
얼마만큼 결측이 되었는지 확인해보자.
많은 결측치가 아니기에 삭제해도 되지만, 이번에는 결측치를 채워보도록 하자.
특징 간 상관성이 있다면 대표값으로 대체하기 어렵다.
먼저 상관 관계를 살펴보고 상관성이 없다면 대표값으로 대체할 것이다.
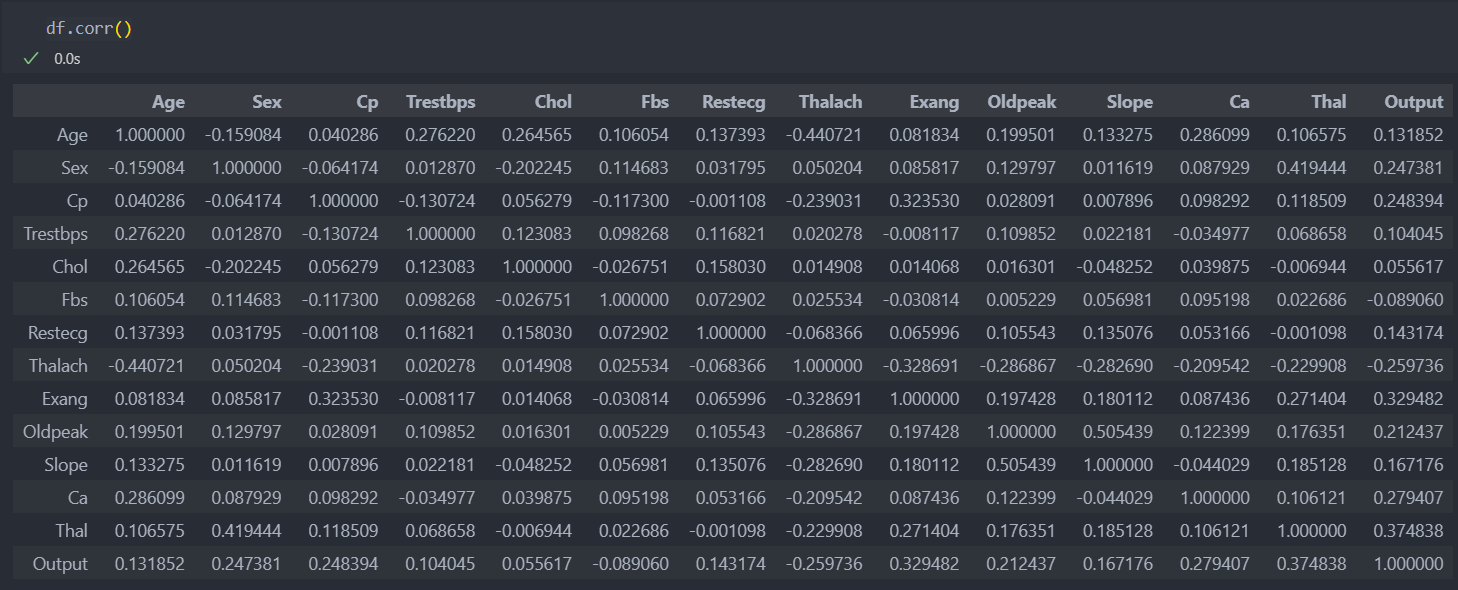
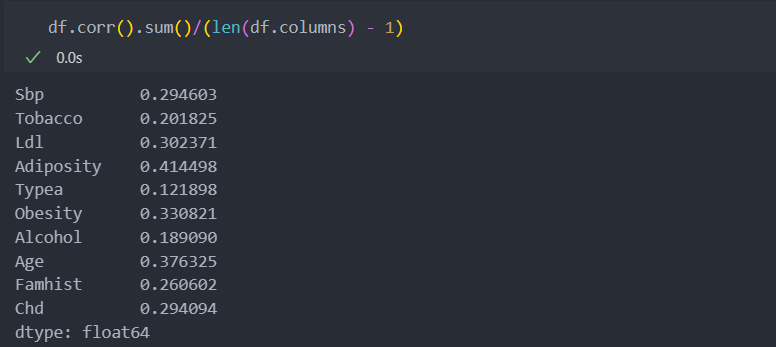
메트릭스는 조금 복잡할 수 있기에 열별로 확인해보자.
상관성이 많지 않다고 판단할 수 있을 것 같다.
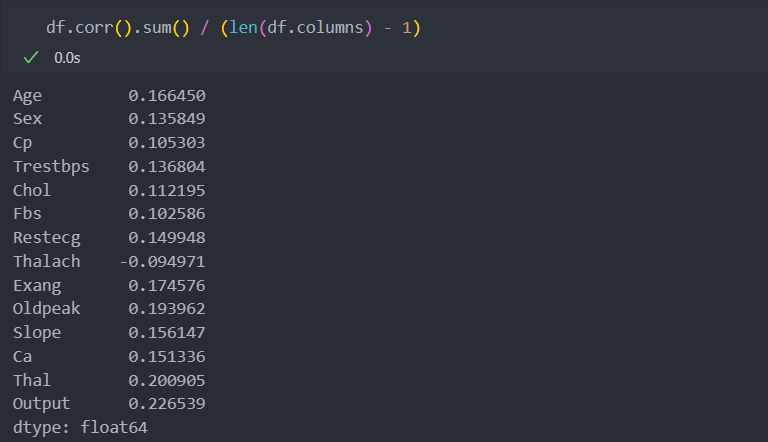
전체 길이에서 -1을 한 이유는 대칭행렬은 1이기 때문이다.
이제 결측치를 sklearn.impute.Simplelmpute을 이용하여 평균값을 대표값으로 하여 결측치를 채워보자.
# 대표값을 활용한 결측치 대체
from sklearn.impute import SimpleImputer
# SimpleImputer 인스턴스화
SI = SimpleImputer(strategy = 'mean')
# 학습
SI.fit(df)학습한 모델을 바탕으로 대표값으로 결측치를 채워넣고 다시 DataFrame로 바꿔보자.
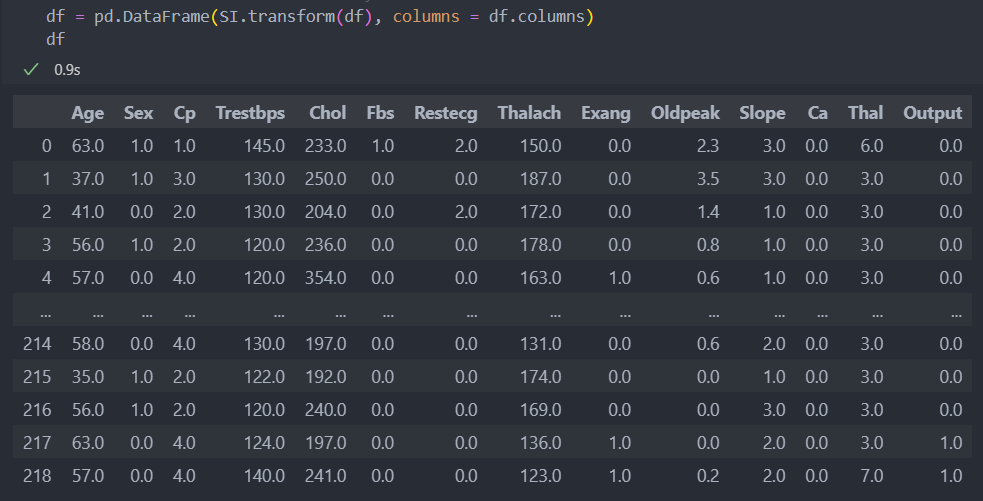
그리고 결측치가 제대로 채워졌는지도 확인해보자.
다른 타입의 특징이 있는 경우
다음과 같은 데이터가 있다.
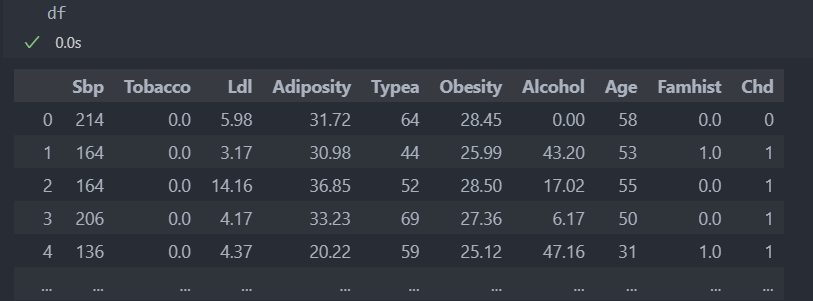
각 컬럼별 결측치를 확인해보자.
컬럼별 unique 값이 많을 경우는 따로 끊어서 보도록 한다.
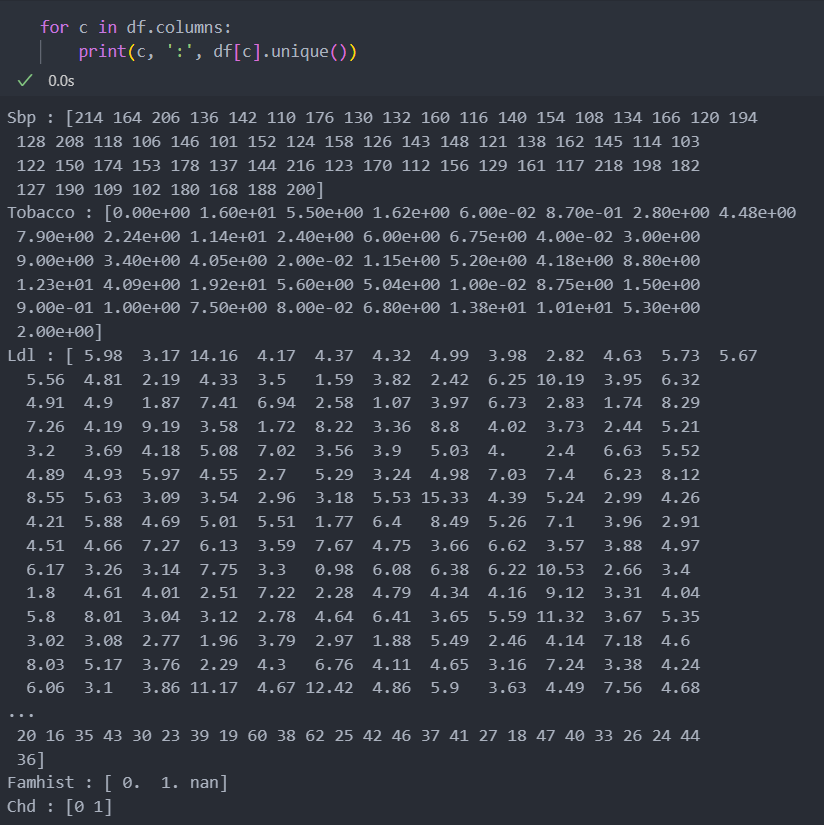
컬럼 'Obesity'와 'Alcohol', 'Famhist'에 결측값이 있다는 것을 확인할 수 있다.
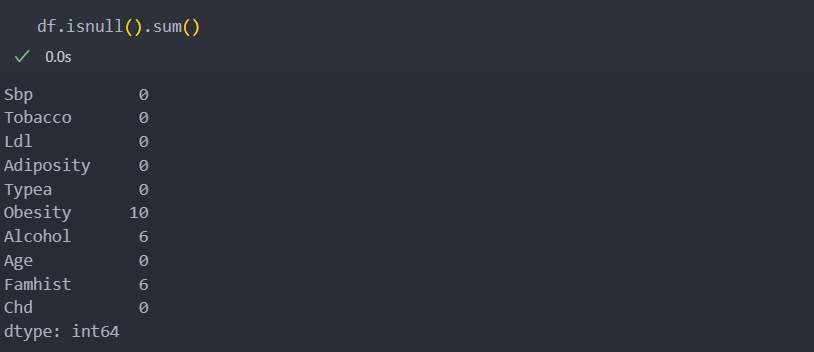
각각의 결측치 비율은 작은 편이기에 삭제해도 무방해 보이지만, 각각의 컬럼이 다른 행에 결측치를 가지고 있다면 30% 넘는 값이므로 좀 더 자세히게 보도록 하자.
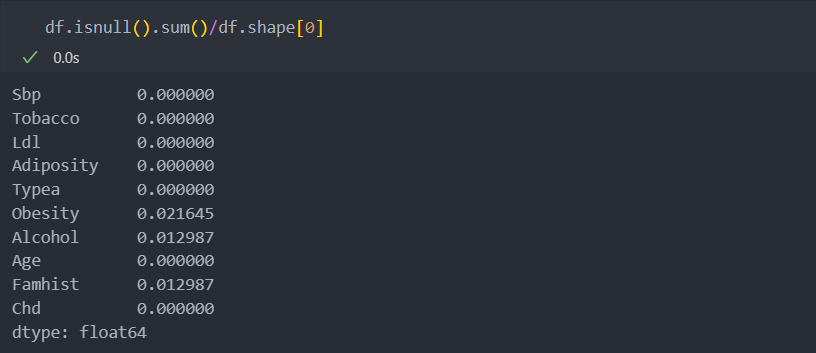
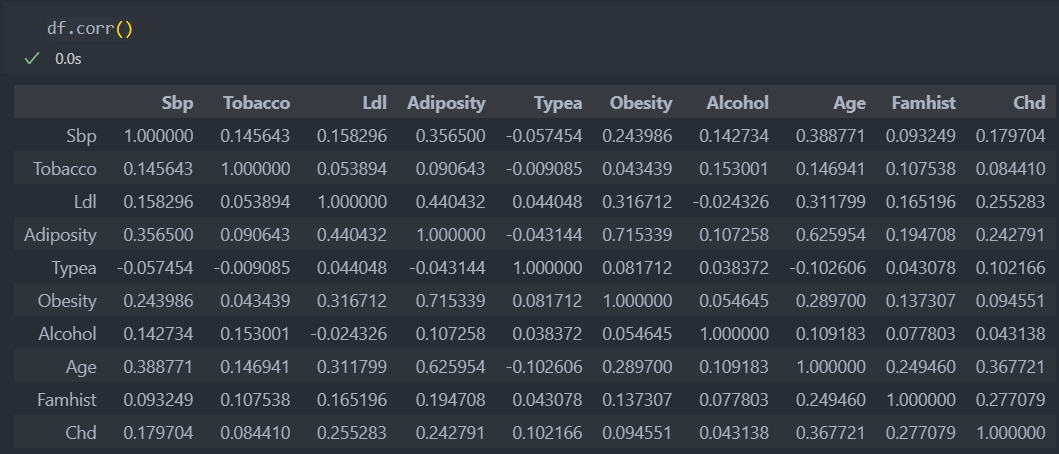
상관성이 있는지 알아보자.
(주의: 변수가 연속형과 범주형이 함께 있기에 상관 분석만으로는 분석이 제대로 진행되지 않을 수 있다.)
이유는 상관성이 크다면 대표값으로 대체하기 어렵기 때문이다.
상관성이 있는 수치가 조금 보이긴 하지만, 상관 관계가 크지 않다고 판단하고 진행해보자.
앞서 데이터를 확인했을 때, 컬럼 'Famhist'은 범주형이기에 컬럼을 나눠서 확인해봐야 한다.
- 대표값으로 보통 범주형은 '최빈값'으로 연속형은 '평균'을 주로 사용한다.
# Famhist: 범주형 변수
# 그 외 변수: 연속형 변수
# 대표값을 평균을 사용할지, 최빈값을 사용할지 결정이 어려움 => 둘 다 사용해야 함
# 따라서 데이터를 분할해야 함
df_cate = df[['Famhist']]
df_cont = df.drop('Famhist', axis = 1)각각의 결측치에 대해 sklearn.impute.Simplelmpute 이용하여 결측치를 채채워보자.
# 대표값을 활용한 결측치 대체
from sklearn.impute import SimpleImputer
# SimpleImputer 인스턴스화
SI_mode = SimpleImputer(strategy = 'most_frequent')
SI_mean = SimpleImputer(strategy = 'mean')
# 학습
SI_mode.fit(df_cate)
SI_mean.fit(df_cont)
# 학습한 모델을 통해서 결측치를 채운 데이터를 다시 생성한다.
# sklearn instance의 출력은 ndarray이므로 다시 DataFrame으로 바꿔줌
df_cate = pd.DataFrame(SI_mode.transform(df_cate), columns = df_cate.columns)
df_cont = pd.DataFrame(SI_mean.transform(df_cont), columns = df_cont.columns)분할한 데이터를 다시 합치는 작업하는데, 단순히 이어붙이기 위해 concat를 사용한다.
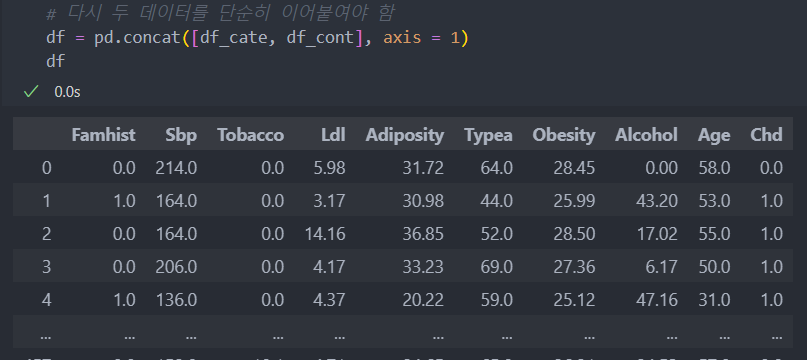
그리고 제대로 결측치가 채워졌는지 확인해보자.