
산포란 데이터가 얼마나 퍼져있는지를 나타내며 산포 통계량은 산포를 나타내는 통계량이다.
- 편차 : 한 샘플이 평균으로부터 떨어진 거리 i번째 관측치 - 평균
- 분산 : 편차들의 합은 항상 0이되어 계산이 되지 않기에, 각각의 편차에 제곱하여 관측치 개수 - 1로 나눈 값
- 표준 편차 : 분산에 루트, 즉 1/2를 제곱한 값.
- 변동 계수 : 분산과 표준편차는 데이터들의 스케일값에 크게 영향을 받기에 변수를 스케일링 한 후 분산과 표준편차 계산(단, 값 >= 0)
분산
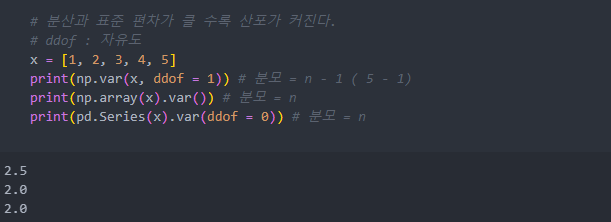
평소에 접하는 대부분의 데이터는 모집단이 아니기에 분산도 모분산(자유도=0)이 아닌 표본분산인 자유도 1로 계산한다.
var()로 분산을 계산하며, ddof는 자유도로 1로 두고 표본분산으로 계산한다.
표준 편차
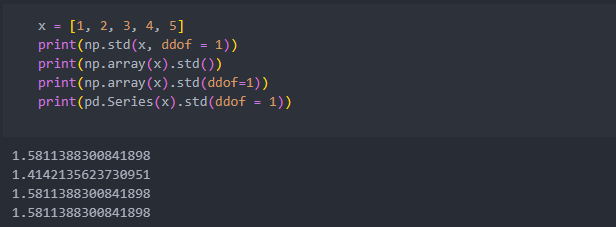
std()로 계산하며, ddof를 1로 둔다.
변동 계수
표준 편차는 스케일링을 하기 전에 데이터의 스케일에 영향을 크게 받는다.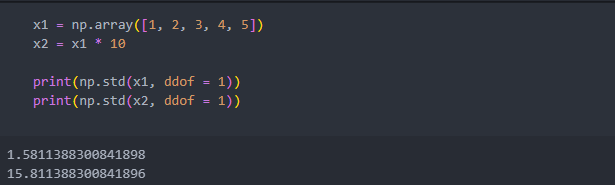
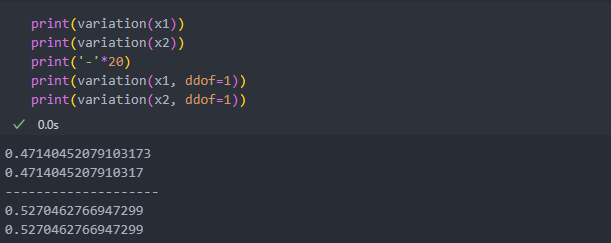
변동 계수는 표준편차/평균으로 variation()을 사용하여 변동 계수를 확인한다. 단 변수는 양수여야 한다.
스케일링
-
Standard Scaling
변수 - 평균 / 표준 편차로 계산한다.
다음과 같은 분포를 이룰 때,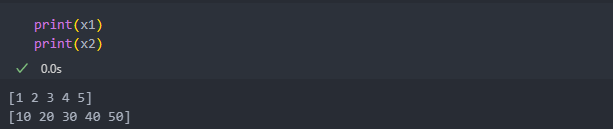
Standard Scaling을 활용하면 데이터의 분포를 파악하기에 좋을 수 있다.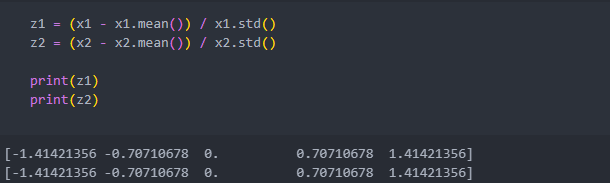
머신러닝에서 매우 많이 사용되기에 사이킷런에서 함수를 제공한다.
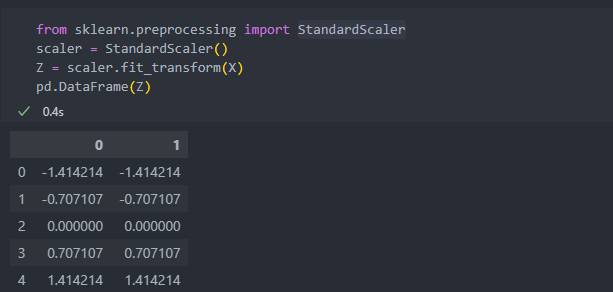
-
Min-Max Scaling
변수 - 최소값 / 변수 - 최대값으로 계산하며 0과 1사이의 값을 가지게 된다.
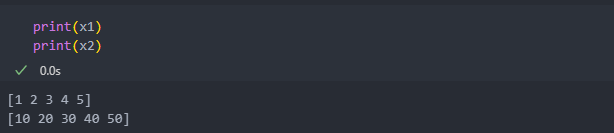
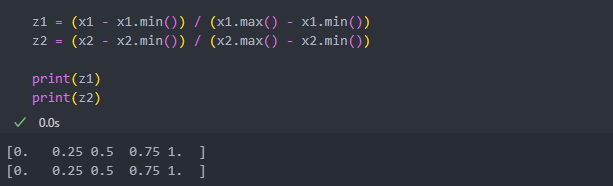
사이킷런에서 함수를 제공한다.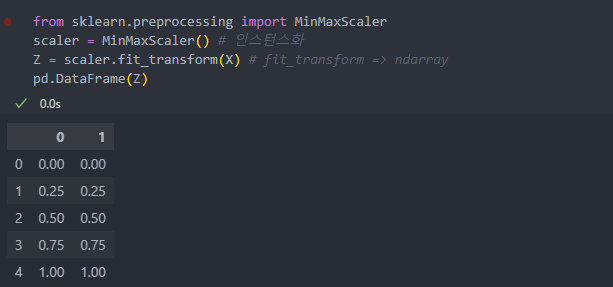
사분위 범위
기존의 범위인 최소값(0%)에서 최대값(100%)에서 사분위의 범위는 1사분위수(25%)에서 3사분위수(75%)사이의 값을 가진다.
사분위 범위(IQR)라고 하며 이상치에 영향을 덜 받기에 이상치를 탐지할 때 자주 사용된다.
평균이 100이고 표준편차가 20인 데이터를 생성하고 알아보자.
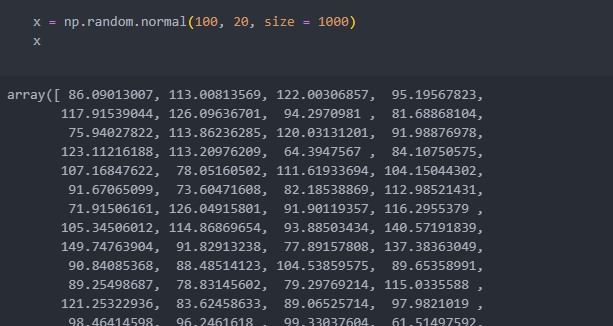
가장 작은 값과 큰 값을 확인하고
범위는 다음과 같고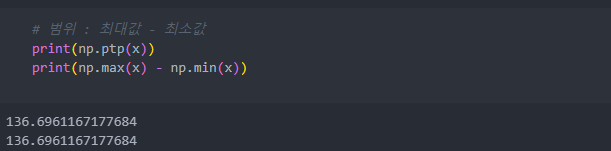
사분위 범위는 다음과 같다.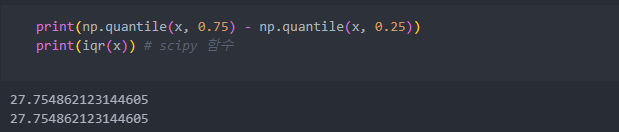

데이터 굽는 타자기