[SQL] UNION 함수, DB정규화, JOIN 함수
📁 UNION 함수
- 여러개의 SELECT 문의 결과를 하나의 테이블로 연결하여 보고 싶을 때 사용
ex) union/union all 기본구조
select name, goods_nm, pay_date # 컬럼 순서가 같고, 그 형식이 같아야 함
from 테이블명1
union (all) #수직결합 명시
select name, goods_nm, pay_date # 컬럼 순서가 같고, 그 형식이 같아야 함
from 테이블명 2 ;- UNION 과 UNION ALL 비교
- 공통점: 두 쿼리문을 하나로 수직결합
- 차이점: UNION 은 중복된 행을 하나로 표기하고(중복제거하고 표기), UNION ALL 은 모두 표현(중복을 제거하지 않고 표기)
📁 DB 정규화
< KEY >
- 하나의 테이블에 구성된 여러 컬럼 중에 해당 테이블을 대표할 수 있는 컬럼. (예를 들어 학생 테이블이 있다면 학번이라는 컬럼을 Key로 설정할 수 있음)
- 여러개의 컬럼의 조합(=다중컬럼)으로 KEY를 생성할 수 있고, KEY 설정이 필수적인 것은 아님
< KEY의 종류 >
-
🔔 Primary key(기본키) 🔔
- 테이블을 대표할 수 있는 키. 테이블 당 하나만 지정 가능. NULL 값 허용 안 됨
- ex) 학생 테이블의 ‘학번’
- 헷갈리지 말아야하는 점은 PK값은 하나만 지정 가능하지만 ‘컬럼이 하나’여야하는 것은 아님. → 다중컬럼을 PK값으로 정할 수 있음
- ex) “학년+반+번호”를 묶어서 PK로 지정할 수 있음
-
Candidate key(후보키): 유일성(중복된 행이 없음)과 최소성(최소한의 컬럼으로 유일성을 만족하는 특징)을 만족하는 키
- ex) 학생 테이블의 ‘학번’도 후보키가 될 수 있음
-
Super key(슈퍼키): 유일성은 만족하지만 최소성은 만족하지 않는 키
- ex) 학생 테이블에서 학번으로만 PK OR 후보키 OR 대체키를 구성해도되는데 [학번+이름]으로 구성하는 경우 이때 [학번+이름] 조합의 키는 PK OR 후보키 OR 대체키가 될 수 없고 슈퍼키가 됨
-
Alternate key(대체키): 후보키 중 기본키로 선택되지 못한 키
-
🔔 Foreign Key(외래키) 🔔
- 다른 테이블의 기본키를 참조하는 키
- 다른 테이블의 기본키에 입력된 값만 입력될 수 있음
- ex) 학과 정보 테이블의 PK키인 학과번호 를 학생 테이블의 ‘학과번호’ 컬럼의 FK키로 지정할 수 있음 → 이렇게 되면 학생 테이블의 ‘학과번호’ 컬럼엔 학과정보 테이블에 입력된 ‘학과번호’ 값만 입력할 수 있음
-
학과정보 테이블
| 학과 번호(PK) | 학과 |
|---|---|
| 1 | 국어국문학과 |
| 2 | 컴퓨터공학과 |
- 학생 테이블
| 학번 | 이름 | 학과번호(FK) |
|---|---|---|
| 1234 | 홍길동 | 1 |
| 5678 | 임꺽정 | 2 |
<정규화란>
- 데이터베이스의 데이터 정합성 (데이터의 정확성과 일관성을 유지하고 보장)을 위해 테이블을 작은 단위로 분리하는 과정
- ex) 하나의 테이블에 “학번, 이름, 수강과목, 수강과목의강의실, 수강과목의교수명, 교수전화번호” 이렇게 모든 정보가 있다면 데이터 정합성을 유지하기가 어려움 / 교수전화번호가 바뀌면 그 교수님의 전화번호가 적혔던 모든 행들을 수정해야 함
→ 이런 테이블을 학생/수업/교수 테이블로 나누는 게 정규화
- ex) 하나의 테이블에 “학번, 이름, 수강과목, 수강과목의강의실, 수강과목의교수명, 교수전화번호” 이렇게 모든 정보가 있다면 데이터 정합성을 유지하기가 어려움 / 교수전화번호가 바뀌면 그 교수님의 전화번호가 적혔던 모든 행들을 수정해야 함
- 정규화를 할 경우 데이터 조회 성능은 조회 조건에 따라 향상 되는 경우도 있고 저하되는 경우도 있지만 입력, 수정, 삭제 성능은 일반적으로 향상된다고 볼 수 있음
- 정규화를 하지 않을 경우 이상현상(Abnormality)이 발생할 수 있음
- 불필요한 값까지 계속해서 입력해줘야하는 현상 등 (삽입 이상)
- ex) 사원 정보 테이블에 사번, 이름, 부서 뿐만 아니라 부서 전화번호 등 부서 관련 세부 컬럼까지 있어서 모두 입력해주어야하는 상황을 삽입 이상이라고 함 → 오류 발생 가능성 높아짐
- 그렇다고 모든 테이블을 무작정 분리하면 비효율이 발생할 수 있기 때문에 정규화를 위한 일정한 규칙이 존재
<정규형의 종류>
1. 제1정규형 (1NF): 각 컬럼이 원자값(atomic value)을 가지도록 테이블을 설계
- 원자값: 더 이상 쪼갤 수 없는 값 (하나의 값이라고 생각하면 됨)
- 제2정규형 (2NF): 제1정규형을 만족한 테이블에 대해, 완전 함수 종속을 만들도록 테이블 분해
- “테이블의 모든 일반 속성은 반드시 모든 주식별자에 종속되어야 한다.”
- 주식별자(기본키)가 단일 식별자가 아닌 복합 식별자인 경우 일반속성이 주식별자의 일부에만 종속될 수 있는데 이런 경우는 정규화를 시켜 주어야함
- 완전함수종속: 기본키(PK)를 구성하는 구성하는 모든 컬럼의 값이 다른 컬럼을 결정짓는 상태.
- 기본키가 1개일 때는 완전함수종속을 만족하니 신경 쓸 필요 없음
- 문제는 기본키(PK)가 2개 이상으로 구성된 복합 식별자인 경우 발생
- 기본키(PK)의 부분 집합이 다른 컬럼과 1:1 대응 관계를 갖게 되면 분해해야함
ex)
| 회원번호 | 이름 | 구매상품 | 가격 |
|---|---|---|---|
| 1 | 홍길동 | 샴푸 | 5,000 |
| 1 | 홍길동 | 린스 | 4,000 |
| 2 | 임꺽정 | 우유 | 1,000 |
| 3 | 이순신 | 우유 | 1,000 |
- 기본키(PK)가 [
회원번호+구매상품]인 테이블 - 기본키 중
구매상품에 의해가격이 결정됨 → 완전함수종속성 위배 - 아래와 같이
기본키와 부분함수종속성을 갖는 컬럼(=가격 컬럼)을 다른 테이블로 분해하면 제2정규형을 만족하게 됨
테이블 1
| 회원번호 | 이름 | 구매상품 |
|---|---|---|
| 1 | 홍길동 | 샴푸 |
| 1 | 홍길동 | 린스 |
| 2 | 임꺽정 | 우유 |
| 3 | 이순신 | 우유 |
테이블 2
| 상품명 | 가격 |
|---|---|
| 샴푸 | 5,000 |
| 린스 | 4,000 |
| 우유 | 1,000 |
- 제2정규형을 만족해야하는 이유
- 회원이 구매를 하지 않은 상품의 경우 상품가격을 입력할 수 없는 입력 이상 발생
- 상품 가격이 변경될 경우 해당 상품에 대한 구매 데이터가 모두 변경되어야 하는 수정 이상 발생
- 제3정규형 (3NF): 제2정규형을 만족한 테이블에 대해 이행적 종속을 없애도록 테이블 분리
- 이행적 종속이란 A→B, B→C의 관계가 성립할 때 A→C가 성립되는 것을 말함
- (A, B), (B, C)로 분리하는 것이 제3정규화
- ex)
| 구매번호 | 구매상품 | 가격 |
|---|---|---|
| A1 | 샴푸 | 5,000 |
| A2 | 우유 | 1,000 |
| A3 | 우유 | 1,000 |
| 구매번호 | 구매상품 | 가격 |
|---|---|---|
| A1 | 샴푸, 린스 | 9,000 |
| A2 | 샴푸, 우유 | 6,000 |
구매번호에 의해구매상품이 결정되고,구매상품에 의해가격이 결정 되는데,구매번호에 의해서도가격이 결정되는 상황 (구매 당 상품을 1개만 구입할 수 있어, 구매가 일어나면 해당 상품에 맞는 가격이 매칭되는 구조이기 때문)- 따라서 (구매번호&구매상품)과 (구매상품&가격)으로 분리하는 것이 제3정규화
- 정규화 결과
| 테이블1 | 테이블2 | ||
|---|---|---|---|
| 구매번호 | 구매상품 | 구매상품 | 가격 |
| A1 | 삼푸 | 삼푸 | 5,000 |
| A2 | 우유 | 우유 | 1,000 |
| A3 | 우유 |
- 제5 정규형까지 있지만 잘 사용되지 않음
📌 DB 정리 및 JOIN
- 정규화는 데이터를 중복 없이 체계적으로 저장하기 위해 테이블을 분리하는 과정
JOIN은 정규화로 인해 분리된 테이블에서 필요한 데이터를 결합하여 조회하는 도구
📁 JOIN 함수
- JOIN 함수는 여러 개의 SELECT 문의 결과를 단일 결과 세트로 연결할 때 사용
- 즉 JOIN 함수는 원하는 데이터를 추출하기 위해 두 개의 테이블을 결합하는 역할을 수행
<조인의 첫번째 단계: 공통컬럼 찾기>
- 조인을 위해서는, 공통컬럼을 먼저 찾아야 함
- 공통컬럼 = 두 테이블에서 공통으로 존재하는 컬럼으로 이해
- 꼭 컬럼의 이름이 같지 않아도 괜찮음
<조인의 두번째 단계: 적절한 조인 방식 찾기>
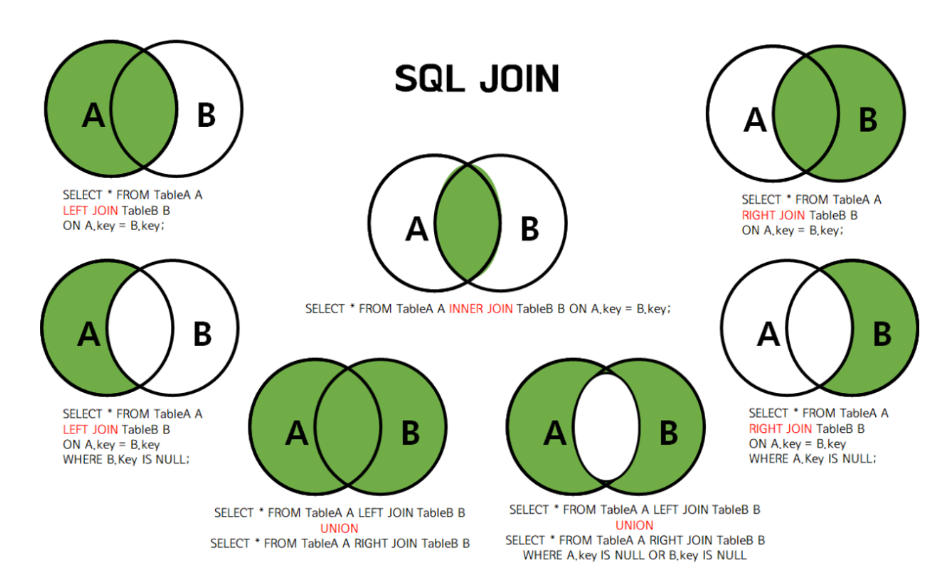
<조인의 종류>
INNER JOIN(가장 많이 사용) : 두 테이블에서 일치하는 값을 가진 행을 출력 (교집합)LEFT JOIN(가장많이사용)- 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환
- 일치하는 항목이 없으면 오른쪽 테이블의 열에 대해 NULL 값이 출력
RIGHT JOIN
-오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행을 반환- 일치하는 항목이 없으면 왼쪽 테이블의 열에 대해 NULL 값이 출력
FULL OUTER JOIN- 모든 데이터를 보고 싶을 때 사용 (용량 이슈로 자주 사용하지 않음)
- MySQL 환경에서는 제공하지 않아 LEFT JOIN 과 RIGHT 조인의 UNION으로 계산해야함 (합집합)
(1) INNER JOIN
- 간단한 INNER JOIN 기본 작성 방법
# INNER JOIN 작성법(기초편)
select 컬럼1, 컬럼2...
from 테이블1 as a
inner join 테이블2 as b
on a.공통컬럼=b.공통컬럼- ex)
-- ANIMAL_INS: 동물 보호소에 들어온 동물의 정보. (I)
-- ANIMAL_OUTS: 동물 보호소에서 입양 보낸 동물의 정보. (O)
-- Where 절을 이용해서 원하는 조건을 설정한다.
SELECT I.ANIMAL_ID, I.NAME FROM ANIMAL_INS I
JOIN ANIMAL_OUTS O
ON I.ANIMAL_ID = O.ANIMAL_ID
WHERE I.DATETIME > O.DATETIME
ORDER BY I.DATETIME;(2) LEFT JOIN
- ex) LEFT JOIN 작성법(기초편)
select 컬럼1, 컬럼2...
from 테이블1 as 테이블명1 -- left에 위치한 테이블. (기준)
left join 테이블2 as 테이블명2 -- right에 위치한 테이블.
on a.공통컬럼=b.공통컬럼- ex)
select *
from basic.s1 a
left join basic.s2 b
on a.name=b.name→ 결과값으로, 기준인 s1 의 모든데이터가 출력
→ right 에 위치한 s2 테이블의 경우, 이름이 같다는 조건을 만족한 경우 데이터를 반환하였고, 만족하지 못한 경우 NULL 값을 반환
(3) RIGHT JOIN (잘 사용하지 않음)
- ex) RIGHT JOIN 작성법(기초편)
select 컬럼1, 컬럼2...
from 테이블1 as 테이블명1 -- left에 위치하는 테이블.
right join basic.theglory2 as 테이블명2 -- RIGHT 에 위치 하는 테이블. (기준)
on a.공통컬럼=b.공통컬럼- ex)
select *
from basic.s1 a
right join basic.s2 b
on a.name=b.name→ 결과값으로, 기준인 s2 의 모든데이터가 출력
→ left에 위치한 s1 테이블의 경우, 이름이 같다는 조건을 만족한 경우 데이터를 반환하였고, 만족하지 못한 경우 NULL 값을 반환
(4) FULL OUTER JOIN
- 모든 데이터의 출력, FULL OUTER JOIN
- 테이블의 모든 데이터를 보고 싶을 때 사용하는 JOIN
- MySQL 환경에서는 FULL OUTER JOIN을 지원하지 않음
ㄴ FULL OUTER JOIN = LEFT JOIN + RIGHT JOIN 으로 표현 가능 - ex) 기본 작성 방법
select 컬럼1, 컬럼2,...
from table1 left join table2
on a.공통컬럼=b.공통컬럼
union
select 컬럼1, 컬럼2,...
from table1 right join table2
on a.공통컬럼=b.공통컬럼- ex) FULL OUTER JOIN 작성법(기초편)
select *
from basic.s1 as a left join basic.s2 as b
on a.name=b.name
union
select *
from basic.s1 as a right join basic.s2 as b
on a.name=b.name- 각 테이블의 모든 값이 출력되었고, 조건에 부합하지 않는 컬럼들이 모두 NULL 값으로 반환됨

원하는 바를 이루고 싶은 사람입니다.