[머신러닝] 머신러닝 프로세스
📁 예측 모델링 프로세스
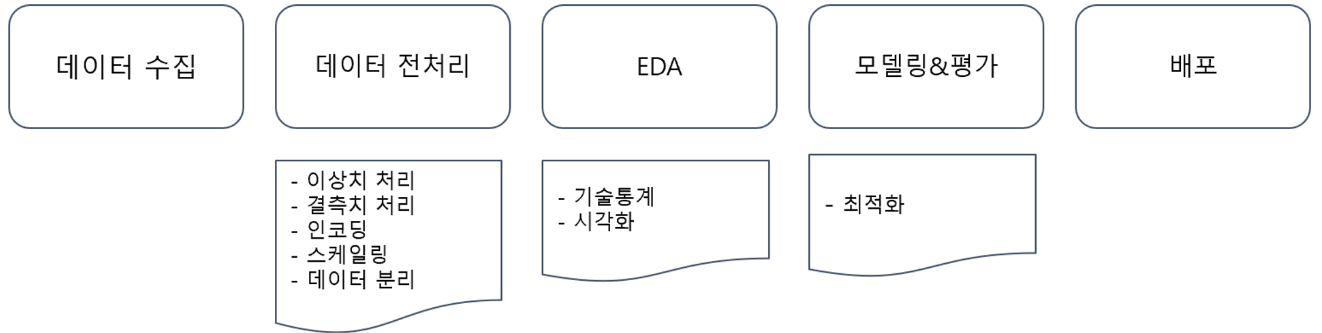
📁 데이터 수집
- 데이터 분석가는 이미 존재하는 데이터를 SQL 혹은 Python을 통해 추출하고 리포팅 혹은 머신러닝을 통한 예측을 담당
<실제 데이터 수집>
- 회사 내 데이터가 존재한다면
- SQL 혹은 Python 을 통해 데이터 마트를 생성
- 회사 내 Data가 없다면 → 데이터 수집 필요
- 방법1 : CSV, EXCEL 파일 다운로드
- 방법2 : API를 이용한 데이터 수집
- 방법3 : Data Crawling
📁 탐색적 데이터 분석(EDA)
- 탐색적 데이터 분석은 데이터의 시각화, 기술 통계 등의 방법을 통해 데이터를 이해하고 탐구하는 과정
- 이 과정에서 데이터에 대한 정보를 얻을 수도 있고, 적절한 모델링에 대한 정보도 얻을 수 있음
- 예측 모델링이 아니더라도 데이터 분석에서는 반드시 필요한 과정
ex) 기술 통계를 통한 EDA 예시
tips.describe()include='all'옵션을 통해 범주형 데이터도 확인 가능
ex) 시각화를 이용한 EDA 예시
- tips 데이터
-
countplot : 범주형 자료의 빈도 수 시각화
- 방법: 범주형의 데이터의 각 카테고리별 빈도수를 나타낼 때
- ex) 상점에서 판매되는 제품의 카테고리별 판매수 파악
- x축: 범주형 자료
- y축: 자료의 빈도수
- 방법: 범주형의 데이터의 각 카테고리별 빈도수를 나타낼 때
-
barplot : 범주형 자료의 시각화
- 방법: 범주형 데이터의 각 카테고리에 따른 수치 데이터의 평균을 비교
- ex) 다양한 연령대별 평균소득을 비교할 때
- x축: 범주형 자료
- y축: 연속형 자료
- 방법: 범주형 데이터의 각 카테고리에 따른 수치 데이터의 평균을 비교
-
boxplot : 수치형 & 범주형 자료의 시각화
- 방법: 데이터의 분포, 중앙값, 사분위 수, 이상치 등을 한눈에 표현하고 싶을 때
- ex) 여러 그룹간 시험 점수 분포를 비교할 때
- x: 수치형 or 범주형
- y: 수치형 자료
- 방법: 데이터의 분포, 중앙값, 사분위 수, 이상치 등을 한눈에 표현하고 싶을 때
-
histogram : 수치형 자료 빈도 시각화
- 방법: 연속형 분포를 나타내고 싶을 때, 데이터가 몰려있는 구간을 파악하기 쉬움
- ex)고객들의 연령 분포를 파악 할 때
- x축: 수치형 자료
- y축: 자료의 빈도수
- 방법: 연속형 분포를 나타내고 싶을 때, 데이터가 몰려있는 구간을 파악하기 쉬움
-
scatterplot : 수치형끼리 자료의 시각화
- 방법: 두 연속형 변수간의 관계를 시각적으로 파악하고 싶을 때
- ex) 키와 몸무게 간의 관계를 나타낼 때
- x축: 수치형 자료
- y축: 수치형 자료
- 방법: 두 연속형 변수간의 관계를 시각적으로 파악하고 싶을 때
-
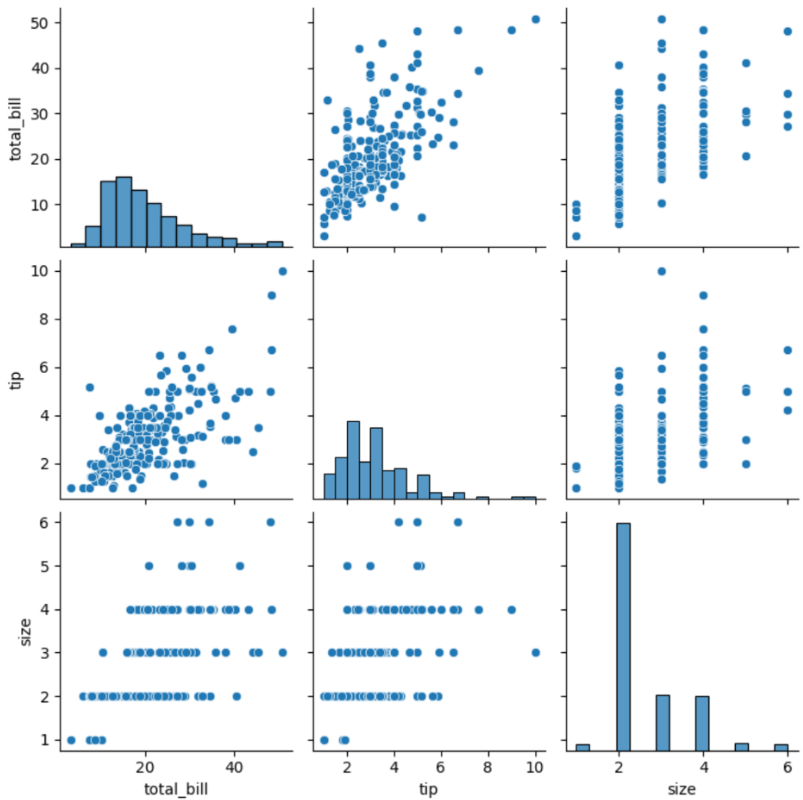
pairplot : 전체 변수에 대한 시각화
- 방법: 한 번에 여러 개의 변수를 동시에 시각화 하고 싶을 때
- x축: 범주형 or 수치형 자료
- y축: 범주형 or 수치형 자료
- 대각선: 히스토그램(분포)
📁 데이터 전처리
- 이는 전체 분석 프로세스에서 90%를 차지 할 정도로 노동, 시간 집약적인 단계
<이상치(Outlier)>
- 이상치란 보통 관측된 데이터 범위에서 많이 벗어난 아주 작은 값 혹은 큰 값
-
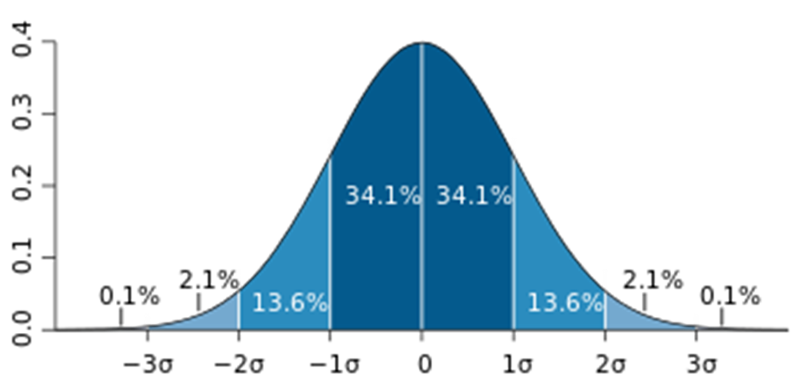
Extreme Studentized Deviation(ESD) 이용한 이상치 발견
- 데이터가 정규분포를 따른다고 가정할 때, 평균에서 표준편차의 3배 이상 떨어진 값
- 모든 데이터가 정규 분포를 따르지 않을 수 있기 때문에 다음 상황에서는 제한됨
- 데이터가 크게 비대칭일 때( → Log변환 등을 노려볼 수 있음)
- 샘플 크기가 작을 경우
-
IQR(Inter Quantile Range)를 이용한 이상치 발견
-
ESD와 동일하게 데이터가 비대칭적이거나 샘플사이즈가 작은 경우 제한됨
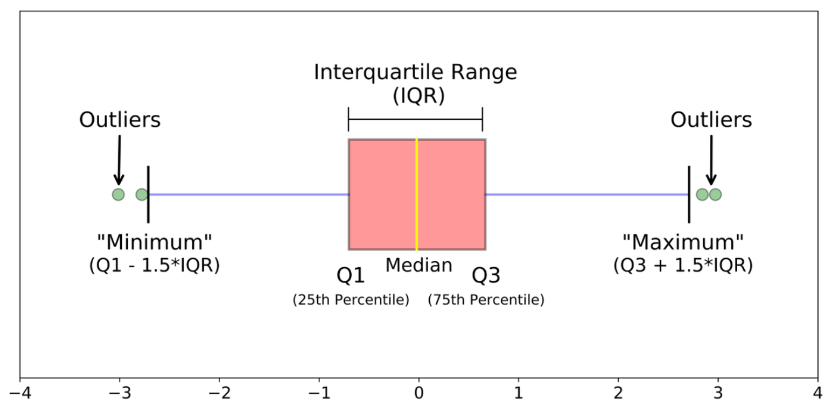
-
Box plot: 데이터의 사분위 수를 포함하여 분포를 보여주는 시각화 그래프, 상자-수염 그림이라고도 함
- 사분위 수: 데이터를 순서에 따라 4등분 한 것
-
- 이상치 발견 방법
# ESD를 이용한 처리
import numpy as np
mean = np.mean(data)
std = np.std(data)
upper_limit = mean + 3*std
lower_limit = mean - 3*std# IQR을 이용한 처리(box plot)
Q1 = df['column'].quantile(0.25)
Q3 = df['column'].qunatile(0.75)
IQR = Q3 - Q1
uppper_limit = Q3 + 1.5*IQR
lower_limit = Q1 - 1.5*IQR-
조건필터링을 통한 삭제(a.k.a. boolean Indexing):
df[ df['column'] > limit_value] -
이상치는 사실 주관적인 값(데이터를 삭제할지 말지는 분석가가 결정할 몫)
-
다만, 도메인과 비즈니스 맥락에 따라 그 기준이 달라지며, 데이터 삭제시 품실은 좋아질 수 있지만 정보 손실을 동반하기 때문에 이상치 처리에 주의해야 함(단지, 통계적 기준에 따라서 결정할 수도 있음)
-
또한, 이상 탐지(Anomaly Detection)이라는 이름으로 데이터에서 패턴을 다르게 보이는 개체 또는 자료를 찾는 방법으로도 발전할 수 있음
→ ex) 사기 탐지, 사이버 보안 등
<결측치(Missing Value)>
- 이상치가 분포에 크게 어긋나는 특이한 데이터라면, 결측치는 존재하지 않는 데이터
- 결측치 처리 방법
- 수치형 데이터
- 평균 값 대치: 대표적인 대치 방법
- 중앙값 대치: 데이터에 이상치가 많아 평균 값이 대표성이 없다면 중앙 값을 이용
ex) 이상치는 평균 값을 흔들리게 함
- 범주형 데이터
- 최빈값 대치
- 사용 함수
- 간단한 삭제 & 대치
df.dropna(axis = 0): 행 삭제df.dropna(axis = 1): 열 삭제- Boolean Indexing
df.fillna(value): 특정 값으로 대치(평균, 중앙, 최빈값)
- 알고리즘을 이용
sklearn.impute.SimpleImputer:평균, 중앙, 최빈값으로 대치SimpleImputer.statistics_: 대치한 값 확인 가능
sklearn.impute.IterativeImputer: 다변량대치(회귀 대치)sklearn.impute.KNNImputer: KNN 알고리즘을 이용한 대치
- 간단한 삭제 & 대치
- 수치형 데이터
→ 📌 위와 같이 간단하게 결측치를 대치할 수도 있지만, 알고리즘을 이용해 대치할 수도 있음
<범주형 데이터 전처리 - 인코딩(Encoding)>
- 인코딩의 사전적 뜻은 어떤 정보를 정해진 규칙에 따라 변환하는 것
- 반면 우리가 만든 머신러닝 모델은 숫자를 기반으로 학습하기 때문에 반드시 인코딩 과정이 필요
- 레이블 인코딩(Label Encoding)
- 정의: 문자열 범주형 값을 고유한 숫자로 할당
- 1등급 → 0
- 2등급 → 1
- 3등급 → 2
- 특징
- 장점: 모델이 처리하기 쉬운 수치형으로 데이터 변환
- 단점: 실제로는 그렇지 않은데, 순서 간 크기에 의미가 부여되어 모델이 잘못 해석 할 수 있음
- 사용 함수
sklearn.preprocessing.LabelEncoder- 메소드
fit: 데이터 학습transform: 정수형 데이터로 변환fit_transform: fit과 transform을 연결하여 한번에 실행inverse_transform: 인코딩된 데이터를 원래 문자열로 변환
- 속성
classes_: 인코더가 학습한 클래스(범주)
- 정의: 문자열 범주형 값을 고유한 숫자로 할당
- 원-핫 인코딩(One-Hot Encoding)
- 정의: 각 범주를 이진 형식으로 변환하는 기법
- 빨강 → [1,0,0]
- 파랑 → [0,1,0]
- 초록 → [0,0,1]
- 특징
- 장점: 각 범주가 독립적으로 표현되어, 순서가 중요도를 잘못 학습하는 것을 방지, 명목형 데이터에 권장
- 단점: 범주 개수가 많을 경우 차원이 크게 증가(차원의 저주) , 모델의 복잡도를 증가, 과적합 유발
- 사용 함수
pd.get_dummiessklearn.preprocessing.OneHotEncoder- 메소드(LabelEncoder와 동일)
categories_: 인코더가 학습한 클래스(범주)get_feature_names_out(): 학습한 클래스 이름(리스트)
- 정의: 각 범주를 이진 형식으로 변환하는 기법
# CSR 데이터 데이터프레임으로 만들기
csr_df = pd.DataFrame(csr_data.toarray(), columns = oe.get_feature_names_out())
# 기존 데이터프레임에 붙이기(옆으로)
pd.DataFrame([titaninc_df,csr_df], axis = 1) <수치형 데이터 전처리 - 스케일링(Scaling)>
- 인코딩이 범주형 자료에 대한 전처리라고 한다면, 스케일링은 수치형 재료에 대한 전처리
- 머신러닝의 학습에 사용되는 데이터들은 서로 단위 값이 다르기 때문에 이를 보정하는 것
-
표준화(Standardization)
- 각 데이터에 평균을 빼고 표준편차를 나누어 평균을 0 표준편차를 1로 조정하는 방법
- 수식
- 함수:
sklearn.preprocessing.StandardScaler- 메소드
fit: 데이터학습(평균과 표준편차를 계산)transform: 데이터 스케일링 진행
- 속성
mean_: 데이터의 평균 값scale_,var_: 데이터의 표준 편차,분산 값n_features_in_: fit 할 때 들어간 변수 개수feature_names_in_: fit 할 때 들어간 변수 이름n_samples_seen_: fit 할 때 들어간 데이터의 개수
- 메소드
- 특징
- 장점
- 이상치가 있거나 분포가 치우쳐져 있을 때 유용
- 모든 특성의 스케일을 동일하게 맞춤 / 많은 알고리즘에서 좋은 성능
- 단점
- 데이터의 최소-최대 값이 정해지지 않음.
- 장점
-
정규화(Normalization)
- 정의: 데이터를 0과 1사이 값으로 조정(최소값 0, 최대값 1)
- 수식
- 함수:
sklearn.preprocessing.MinMaxScaler- (표준화와 공통인 것은 제외)
- 속성
data_min_: 원 데이터의 최소 값data_max_: 원 데이터의 최대 값data_range_: 원 데이터의 최대-최소 범위
- 특징
- 장점
- 모든 특성의 스케일을 동일하게 맞춤
- 최대-최소 범위가 명확
- 단점:
- 이상치에 영향을 많이 받을 수 있음(반대로 말하면 이상치가 없을 때 유용)
- 장점
-
로버스트 스케일링(Robust Scaling)
- 정의: 중앙값과 IQR을 사용하여 스케일링
- 수식
- 특징
- 장점: 이상치의 영향에 덜 민감
- 단점: 표준화와 정규화에 비해 덜 사용됨
- 함수:
sklearn.preprocessing.RobustScaler- 속성
center_: 훈련 데이터의 중앙값
- 속성
📁 데이터 분리
<과적합은 머신러닝의 적>
-
국소적인 문제를 해결하는 것에 집중한 나머지 일반적인 문제를 해결하지 못하는 현상을
과대적합 이슈라고 함 -
즉,
과대적합(Overfitting)이란 데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상
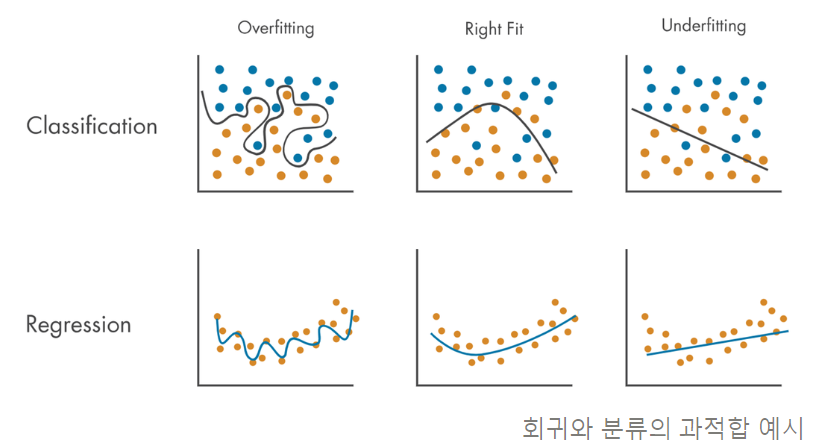
-
예측 혹은 분류를 하기 위해서 모형을 복잡도를 설정
- 모형이 지나치게 복잡할 때 : 과대 적합이 될 수 있음
- 모형이 지나치게 단순할 때: 과소 적합이 될 수 있음
-
과적합의 원인
- 모델의 복잡도(상기의 예시)
- 데이터 양이 충분하지 않음
- 학습 반복이 많음(딥러닝의 경우)
- 데이터 불균형(정상환자 - 암환자의 비율이 95: 5)
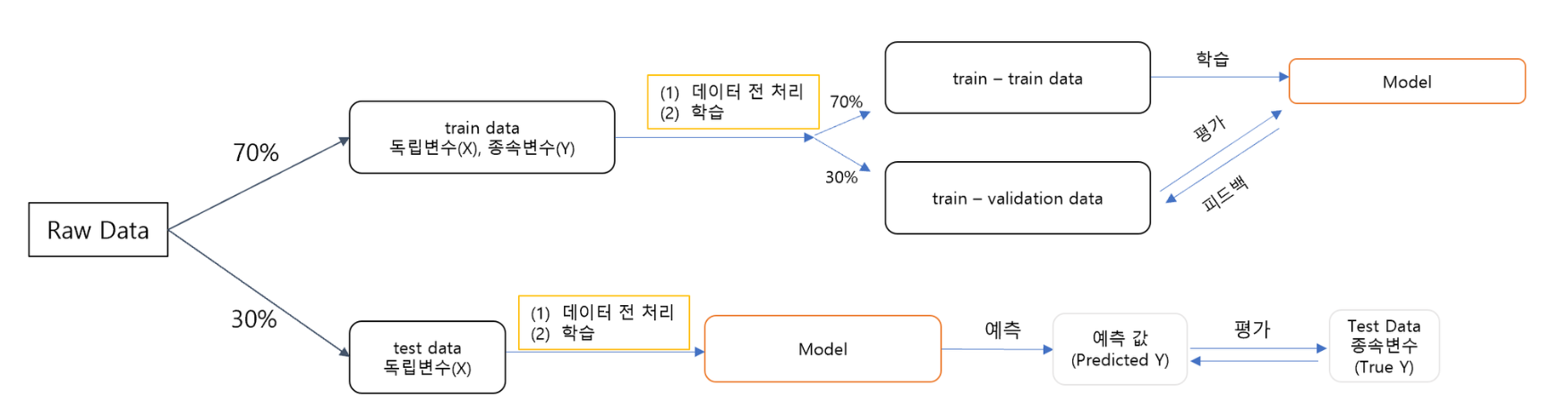
<과적합 해결 - 테스트 데이터의 분리>
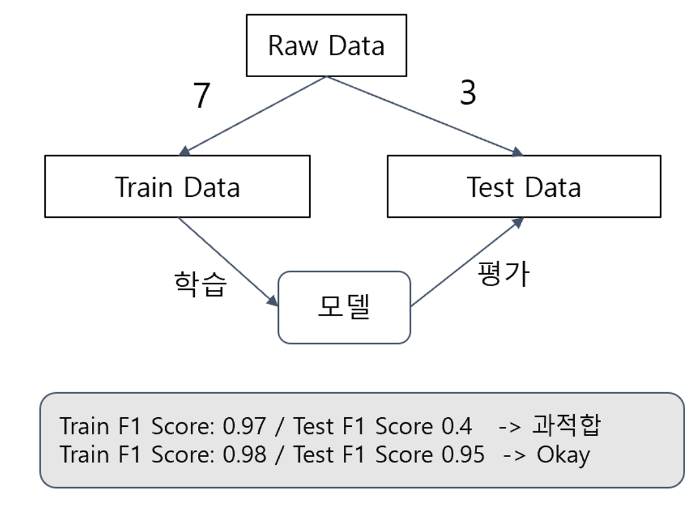
- 학습 데이터(Train Data) : 모델을 학습(
fit)하기 위한 데이터 - 테스트 데이터(Test Data) : 모델을 평가 하기 위한 데이터
- 함수 및 파라미터 설명
sklearn.model_selection.train_test_split- 파라미터
test_size: 테스트 데이터 세트 크기train_size: 학습 데이터 세트 크기shuffle: 데이터 분리 시 섞기random_state: 호출할 때마다 동일한 학습/테스트 데이터를 생성하기 위한 난수 값. 수행할 때 마다 동일한 데이터 세트로 분리하기 위해 숫자를 고정 시켜야 함
- 반환 값(순서 중요)
X_train,X_test,y_train,y_test
- 파라미터
📁 데이터 전체 프로세스 적용 과정 예시
- 데이터 로드 & 분리
- train / test 데이터 분리
- 탐색적 데이터 분석(EDA)
- 분포확인 & 이상치 확인
- 데이터 전처리
- 결측치 처리
- 수치형: Age
- 범주형: Embarked
- 삭제 : Cabin, Name
- 전처리
- 수치형: Age, Fare, Sibsp+Parch
- 범주형
- 레이블 인코딩: Pclass, Sex
- 원- 핫 인코딩: Embarked
- 결측치 처리
- 모델 수립
- 평가
📁 교차 검증과 GridSearch
<교차 검증(Cross Validation)>
- 모델을 평가하기 위한 별도의 테스트 데이터로 평가하더라도 고정된 테스트 데이터가 존재하기 때문에 과적합에 취약한 단점이 있음
- 이를 피하기 위한 교차검증방법이 있음
→ 📌교차 검정이란 데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용하는 방법 - K-Fold Validation
- Train Data를 K개의 하위 집합으로 나누어 모델을 학습시키고 모델을 최적화 하는 방법
- 이때 K는 분할의 갯수
- Split 1: 학습용(Fold 2~5), 검증용(Fold1)
- Split 2: 학습용(Fold1, 3~5), 검증용(Fold2)
- Split 5까지 반복 후 최종 평가
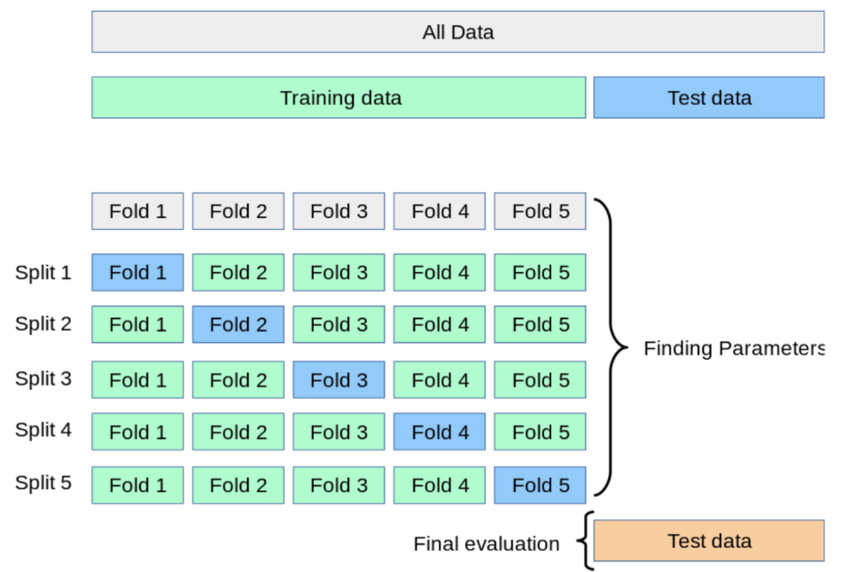
- 특징
- 데이터가 부족할 경우 유용합니다.(반복 학습)
- 함수
skelarn.model_selection.KFoldsklearn.model_selection.StrifiedKFold: 불균형한 레이블(Y)를 가지고 있을 때 사용
<하이퍼 파라미터 자동적용하기 - GridSearchV>
하이퍼 파라미터(Hyper Parameter): 모델을 구성하는 입력 값 중 사람이 임의적으로 바꿀 수 있는 입력 값- 다양한 값을 넣고 실험할 수 있기 때문에 이를 자동화해주는
Grid Search를 적용해볼 수 있음
💡 데이터 분석 프로세스 총 정리(전체 데이터 프로세스)