
시작하기 전에...
먼저 파이프라이닝에 대해 자세히 알아보기 전에, 파이프라이닝이 무엇때문에 나왔는지 감을 잡기위해 거슬러 올라가서 살펴보자. 때는 바야흐로 단일 사이클.. 단일 사이클은 이름 그대로 하나의 명령어 처리를 위해서 한 사이클만 사용하게 된다. 명령어 하나를 실행하기 위해서는
- 명령어 분석
- 연산
- 레지스터에 저장
크게 이렇게 세가지로 나눌 수 있다. 단일 사이클은 이 세가지를 한 사이클에 해결하게 된다. 장단점이 있다.
장점은
1. 구조가 간단하다
2. 만들기 쉽다
3. 레지스터가 필요없다
단점은
1. 속도가 느리다
2. 가장 긴 명령어 시간에 모든 명령어 시간을 맞춰야 한다.
단일 사이클은 장점보다 사실 단점이 조금 크다. 한 사이클 안에 돌아가야하기 때문에 구조가 쉽고 만들기 쉽긴 하지만, 한 사이클에 모든 명령어를 들어가게 해야하기 때문에 한 사이클이 무척 길어질 수 있다. 그럼 이 명령어들을 꼭 한 사이클안에서 순차적으로 실행되어야할까? 이 문제를 어떻게 해결할 수 있을까?
그래서 사용하는 기술이 파이프라이닝이다.
파이프라이닝?
파이프라이닝은 여러 명령어가 중첩되어 실행되는 구현 기술이다. 병렬성을 이용하는 것이다. 물론 이것으로 각 명령어의 실행시간을 개선할 수는 없다. 하지만 처리량을 개선할 수 있다. 이게 무슨 말이냐면, 1시간 동안 6개의 일을 하는 것을, 1시간 동안 12개의 일을 하게 한다는 것이다. 1개의 일당 시간이 짧아지는 것은 아니다. 어떻게 하느냐? 예시를 보자.

세탁기와 건조기로 예시를 들어보겠다. 세탁기에 들어 갈 수 있는 옷 양 최대로 넣는다. 세탁기 작동이 끝나고나면 젖은 옷을 건조기에 넣는다. 건조기 작동이 끝나면 보송보송해진 옷을 갠다. 모두 다 갰으면 옆에 누워있던 친구에게 옷을 옷장에게 넣어달라고 부탁한다.
이렇게 한가지 일이 끝나기까지 기다려 차례차례 진행하는 것은 너무 시간에 비해 처리량이 적다. 이 작업을 처리량을 늘리는 파이프라이닝을 적용한다면 이렇게 된다.

첫번째 빨래가 다 돌아가면 건조기에 빨래를 넣고, 나는 다시 세탁기에 옷을 집어넣는다. 건조기와 세탁기가 다 돌아가면 건조된 옷을 개고, 세탁이 된 빨래를 건조기에 넣고, 새로운 빨래를 세탁기에 넣는다. 다 갠 옷을 친구에게 넣어달라고 하고, 다시 건조기에서 옷을 꺼내와 개고, 건조기에 세탁이 된 옷을 넣고, 새로운 빨래를 세탁기에 넣는다. 이렇게 계속 동시에 할 수 있는 일을 처리함으로써 처리량을 올리는 것이 파이프라이닝이다. 여기서 아까 그 말을 이해할 수 있다. 세탁기가 돌아가고 건조기가 돌아가는 시간은 줄일 수 없지만 병렬적으로 처리함으로써 쉬는시간을 없애 전체 처리량을 올리는 것이다.
여기서 자세히 봐야할 부분은 각 단계별로 걸린 시간이다. 세탁기 돌리기, 건조기 돌리기, 빨래 개기, 옷장에 넣기 이 4가지 작업을하는 각 단계별로 걸리는 시간은 전부 다르다. 그래서 우린 제일 빠른 단계의 작업이 끝나도 전체 작업이 다 끝나기를 기다렸다가 다음 단계로 갈 수 있다. 건조기가 빨리 끝나도 세탁기가 덜 돌아갔으면 건조기에 옷을 넣을 수 없는 것처럼 말이다.
컴퓨터 시스템에서 이러한 한 단계를 처리하는 시간을 컴퓨터의 클럭사이클이라고 한다. 파이프라이닝에서 클럭 사이클은 가장 오래걸리는 단계의 시간을 기준으로 한다.
이 클럭 사이클이 진행되면서 각 명령어가 다음 클럭 사이클에 실행되지 못하는 상황이 있는데, 이 상황을 파이프 라인 해저드라고 한다. 쉽게 말해서 파이프라인의 속도가 저하되는 현상이다.
파이프라인 해저드
파이프라인 해저드는 크게 3개가 있다.
첫번째는 구조적 해저드이다. 이 구조적 해저드는 말 그대로 설계할때 구조에 신경써야한다. 구조적 해저드는 클럭 사이클에 실행하기를 원하는 여러 명령어들의 수행을 하드웨어가 지원할 수 없기 때문에 발생하는 것이다. 이게 무슨 말이냐면, 각 파이프라인의 단계는 자신이 맡은 동작을 실행하기 위해서 메모리나 레지서트 등의 구성 요소를 사용하게 되는데, 같은 파이프라인 단계에 있는 명렁어들이 동시에 하나의 자원을 같이 사용하려고 하면 파이프라인이 지연될 수 있다. 이게 구조적 해저드의 예시다. 그렇기 때문에 파이프라인을 설계할 때 구조적 해저드를 피하도록 유의해야한다.
그럼 만약 구조적 해저드가 발생했다면 어떻게 해결해야할까?
구조적 해저드의 해결방법은 두가지가 있다.
첫번째는 해당 기능을 사용할 수 있을 때까지 계속 지연시키는 것이다.
두번째로 하버드 구조이다. 애초에 하버드 구조는 폰 노이만 구조에서 파이프라이닝 시 구조적 해저드 문제가 발생했을 때 해결하기 위한 컴퓨터 구조이다. 하버드 구조는 메모리를 프로그램과 데이터를 저장할 영역을 분리하고 별도의 버스를 사용해서 병렬 처리를 지원한다. 이 하버드 구조를 사용해 데이터 처리부분과 명령어 처리부분을 분리해서 동시에 처리할 수 있게한다.
다음 해저드는 데이터 해저드이다. 데이터 해저드는 전의 명령이 write back 단계에서 레지스터 파일에 값을 반영 하기 전에 후속 명령이 그 값을 읽거나 쓰려고 할때 발생한다. 데이터 해저드는 또 세가지로 나눌 수 있다.
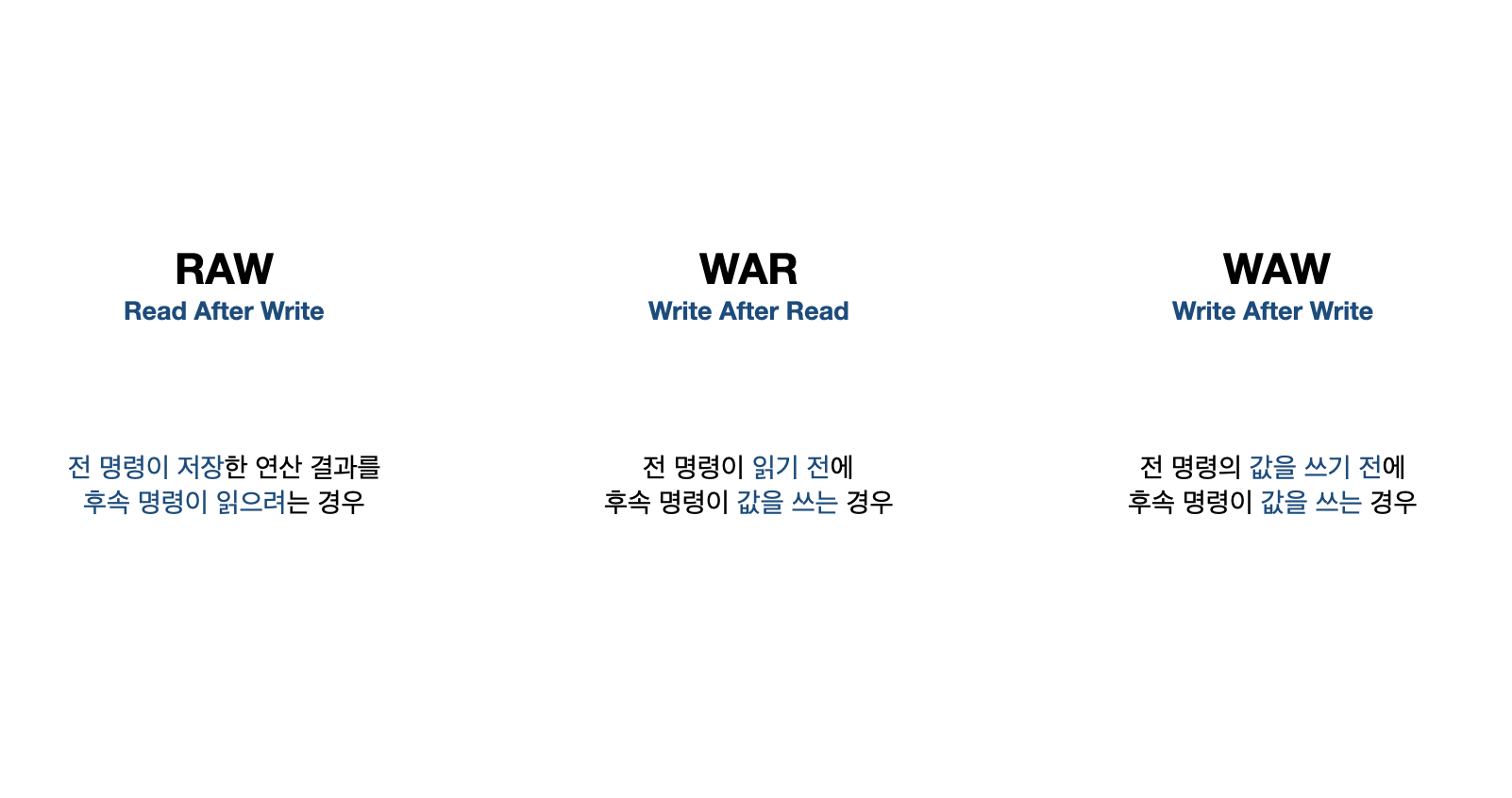
RAW(Read After Write), WAR(Write After Read), WAW(Write After Write)로 나눌 수 있는데, 약자 그대로 해석하면 된다. raw는 이전 명령이 저장한 연산 결과를 후속 명령이 읽으려고 할 때 발생하는 것이고, WAR는 이전 명령이 읽기 전에 후속 명령이 값을 쓰는 경우, WAW 이전 명령의 값을 쓰기 전에 후속 명령이 값을 쓰는 경우 이다.
데이터 해저드는 포워딩을 통해 해결할 수 있다. 포워딩은 ALU(산술 논리장치)로부터 나온 값을 버스에서 MUX, 멀티플렉서로 연결해서 해당 레지스터 값을 선택할 수 있도록 해주는 것이다. 즉 모든 절차가 끝나기를 기다기리 전에 실행할 때 ALU에서 계산된 데이터를 가져와 사용한다. 쉽게 말하면 이미 계산되어 나온 데이터를 저장하기 전에 바로 써버리는 것이다.
세번째 헤저드는 제어 해저드이다. 제어 해저드는 분기 명령에서 분기가 결정되는 시점에 이미 파이프라인에 후속 명령들이 채워져 있어서 발생한다. 예시의 경우는 인출 단계에서 이미 인출한 명령어를 버리고 새로 파이프라인을 채우는 동작을 수행하는 경우가 있다.
제어 해저드의 해결 방법에는 분기 예측이 있다. 분기 명렁어를 실행하기 전에 목적지 주소를 예측함으로써 분기 명렁어로 인한 파이프 라인 지연을 줄이는 것이다. 이 방법에서 조건 경우는 두가지가 있는데, taken 과 not taken이다.

taken은 조건 분기 명령어의 조건이 참으로 판정되어 분기 목적지로 이동하는 경우이다. Not taken은 그의 반대로 조건이 거짓으로 판정되어 다음 명령어를 실행하는 경우이다. 이 방법의 특징은 taken 혹은 not taken으로 예측하여 실행하기 때문에 실행 결과를 갱신하지 않는다는 것이다. 예측 실패시 원래의 상태로 빠르게 복구하기 위해서이다. 예측에 성공하면 실행 결과를 갱신하고, 예측이 실패하면 예측 결과를 버리고 PC를 다시 복구하고 다시 실행한다. 제어 해저드는 이 분기 에측으로 해결할 수 있다.
