컴포넌트 다시 생각하기
FEConf
영상을 보고 정리한 글입니다.
의존성이란.
케이크로 빗대서 생각하기
케이크를 만들려면 밀가루, 설탕, 계란이 필요
=> 케이크는 밀가루, 섩캉, 계란에 의존한다
= 케이크의 의존성: 밀가루, 설탕, 계란
리액트의 컴포넌트의 의존성? === 컴포넌트를 만들려면 뭐가 필요할까
컴포넌트의 의존성은 기능적(Type), 특징적(Feature) 을 기준으로 분류 할수 있다
-
기능적 분류
props, hooks, import -
특징적 분류
- ul 조작에 필요한 커스컴 로직( ): UI를 동작하는 특정한 동작을 하거나,컴포넌트에 의도한 사이트 이펙트를 주거나 할 때 사용된다.
- 스타일: css e등 파일을 외부에 작성해서 컴포넌트 내부에 import 해오는 경우 스타일은 컴포넌트의 필요한 의존성이다
- 전역 상태
- 리모트 데이터 스키마: api서버에서 내려주는 데이터의 모양
컴포넌트의 숨은 의존성
리액트 컴포너트에 새로운 정보를 추가해보면?
-> 다른 수정을 해야한다!
=>정보를 받기위해 리액트 컴포넌트의 숨은 의존성: 다른 수정!아래의 예시로 봐보자!
<PageArticleList> // 아티클 리스트 페이지
<ArticleList> // 아티클 리스트
<Article /> // 아티클 컴포넌트
</ArticleList>
</PageArticleList> Article컴포넌트를 수정하기 위해선 루트 컴포넌트와 중간 컴포넌트를 수정하게 되는데 이를 리모트 데이터 스키마가 가지는 숨은 의존성!

새로운 정보를 수정하기에 루트 컴포넌트 중간 컴포넌트 까지 수정하게 하는데 -> props drilling -> 피하기 위해서 데이터 저장소를 따로 두더라도 페이지 기반 라우팅을 한다면 결국 루트 컴포넌트에 의존!
페이지 기반 라우딩을 한되면 루트 컴포넌트에 의존할수 밖에 없다
이런 의존성들을 어떻게 하야할까!
- 함께 두기(co-locate, co-location)
- 비숫한 관심사라면 가까온곳에
비숫한 같은 파일 안에 두거나 바로 옆에 두는게 좋다
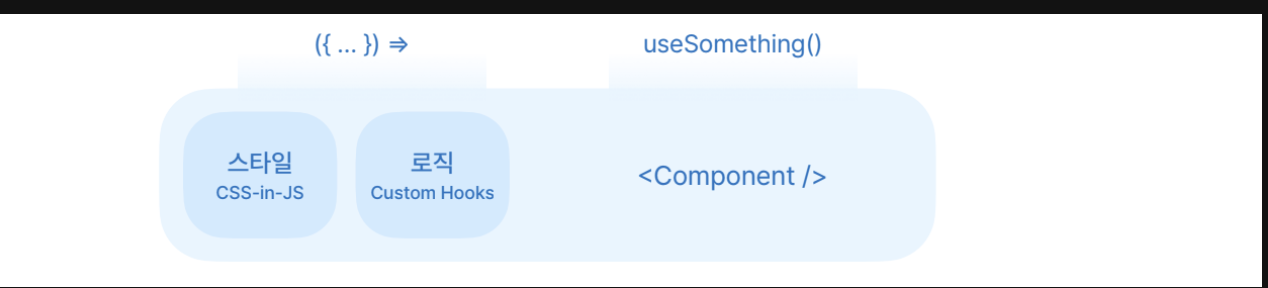
1-1) 스타일과 로직을 컴포넌트 안에 두기: 파일이 커지는 것이 염려된다면, 같은 폴더안에!
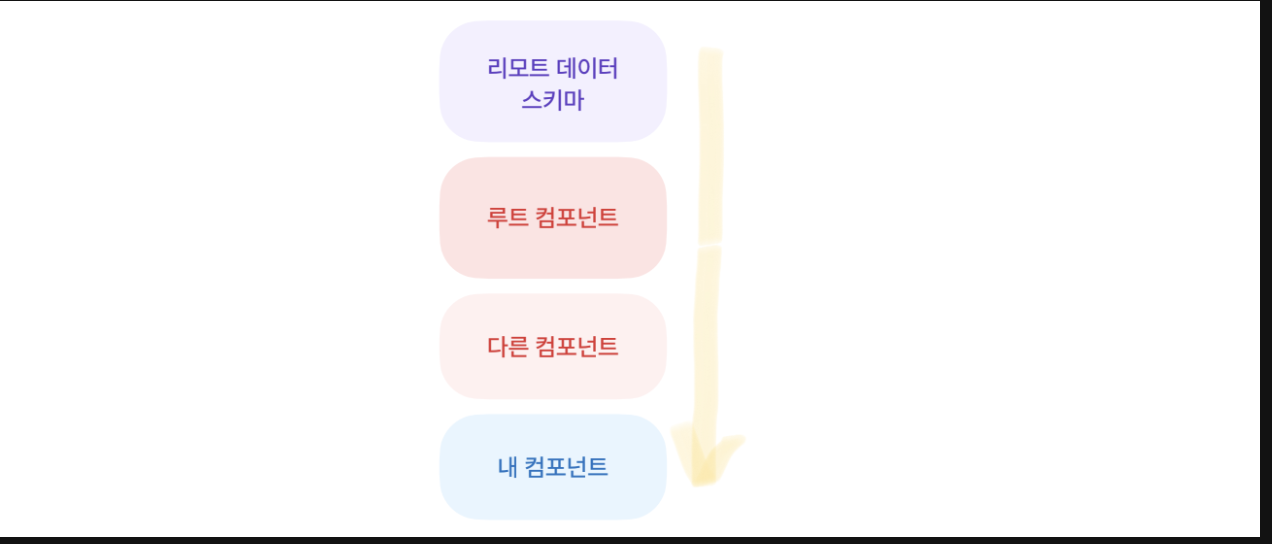
- 리모트 데이터 스키마 함께두기
api 서버로 부터 리모트 데이터 스키마가 내려오는 모습을 살펴보면 루트 컴포넌트와 다른 컴포넌트들을 타고 내 컴포넌트까지 오게 된다
위에 그림처럼 props를 통해 데이터 스키마를 받게 된다면 루트컴포넌트에 강한 의존성이 생기는데 ->
- props를 통해 ID받고
- 데이터 저장소에서 ID를 통해 해당 데이터를 받아올 수 있게 해서 의존성을 끊어낼 수 있다
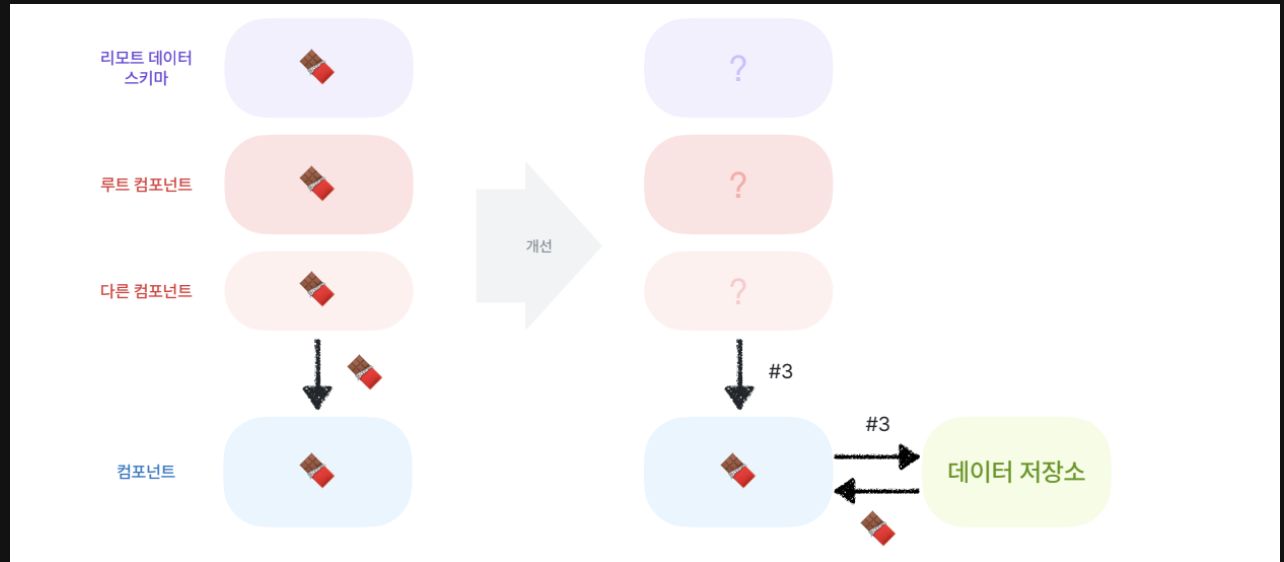
리펙토링 원칙, 두 번째: 데이터를 ID 기반으로 정리하기
- 데이터를 아이디 기반으로 정리하기 nomalization 정규화
📌 참고! 데이터 정규화(nomalization)를 도와주는 라이브러리
yarn add nomalizer
이름 짓기
의존한다면 그대로 드러내기
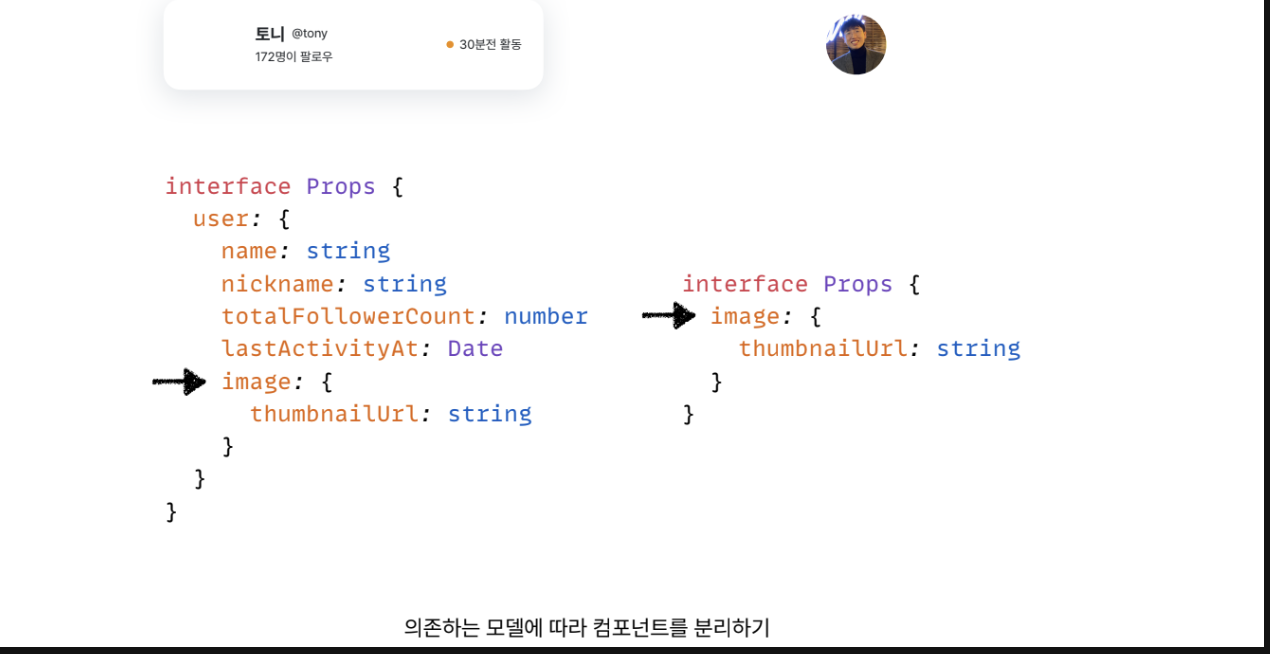
한컴포넌트에서 여러모델의 정보를 표현하는 것은 관심사 분리가 제대로 되지 않은것
사진처럼 되면 상위 컴포넌트가 해당 모양을 정확하게 맞춰야 하기 때문에
상위 컴포넌트와의 의존성이 생길 것이다 => 재사용성 떨어짐
재사용하기
컴포넌트를 재사용하는 이유를
개발할 때 편함보다 유지보수할 때 편함으로 바라보자
변경될 만한 부분을 미리 예측하고 준비하기!!! => 대부분은 리모트 데이터 스키마가 변화하는 방향을 따라 움직인다.
두 컴포넌트닌 비슷하게 생겻지만 의존하고 있는 리모트 데이터 스키마는 user와 page로 각가 다르다
이때 기존에 있던 컴포넌트를 재사용할지? 복사해서 새컴포넌트로 분리 할지 고민하게 되는데...
같은 모델을 의존하는 컴포넌트: 재사용
다른 모델을 의존하는 컴포넌트 : 분리
기준으로 나누자!
해당 영상의 결론은!

