강의 영상 주소 : https://www.youtube.com/watch?v=0nqvO3AM2Vw&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=2
해당 슬라이드 : https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture02.pdf
✍️[67p~88p]요약정리

< Hyperparameters >
- Hyperparameter는 학습을 통해 최적화하는 변수가 아니고 사전에 미리 정하는 매개변수입니다.
- 예를 들어 K-Nearest Neighbor의 경우 K 값과 distance metric이 Hyperparameter입니다.
- Hyperparameter를 정할 때는 여러가지 값이나 방식을 적용해보고 가장 적절한 것을 선택해야 합니다.

- 전체 데이터셋에대해 가장 적합한 값을 선택
- k=1일때 학습데이터를 가장 완벽하게 분류하지만 앞에 예제에서처럼 k를 더 큰 값으로 선택하게 되면 학습데이터에서 몇개를 잘 못 분류할 수 있음에도 학습데이터에 없던 데이터에 대해서는 좋은 성능을 보일 수 있기때문에 트레이닝 셋 한개만을 설정하는 것은 정말 좋지 않은 방법이고 절대로 해서는 안됩니다.
- 궁극적으로 머신러닝에서는 학습데이터를 얼마나 잘 맞추는지에 대한 정확성보다는 한번도 보지 못한(unseen)데이터를 얼마나 잘 예측하는지가 중요하기 때문에 학습데이터에만 신경쓰는 첫 번째 아이디어는 최악의 방식이라고 볼 수 있습니다.

- 전체 데이터 중 훈련용(train)데이터의 일부를 쪼개서 테스트용(test)데이터로 나눈 다음 학습데이터로 다양한 hyperparameter값을 학습시키고 테스트 데이터에 적용시켜 본 다음에 적절한 hyperparamter를 선택하는 방법입니다.
이 아이디어가 첫 번째에 비해 합리적인 방법이라고 생각 할 수 있는데 이 아이디어 또한 좋지 않은 방법입니다. - 위에 언급했던 것처럼 unseen데이터에서도 잘 동작해야하는 것이 중요한데 지금 이 방식으로는 테스트 셋에서만 잘 동작되는 hyperparamter를 고를 수 밖에 없어 새로운 데이터에서의 알고리즘 성능을 측정할 수 없을 수 있기 때문입니다.
- 테스트 셋에서 잘 동작한다고 해서 unseen데이터에서도 잘 동작한다고 장담할 수 없습니다.

- 이 방법은 훨씬 일반적인 방법인데 데이터 대부분을 훈련용(train)으로 나누고 나머지 부분을 각각 검증용(validataion),테스트용(test)으로 나눈다음 검증 셋에서 가장 좋았던 분류기를 선택하고 테스트 셋에서 오직 한번만! 수행합니다.
- 1번,2번 아이디어보다 더 나은 방법이고 해당 알고리즘이 unseen데이터에 얼마나 잘 동작해주는 지 알아 볼 수 있습니다.
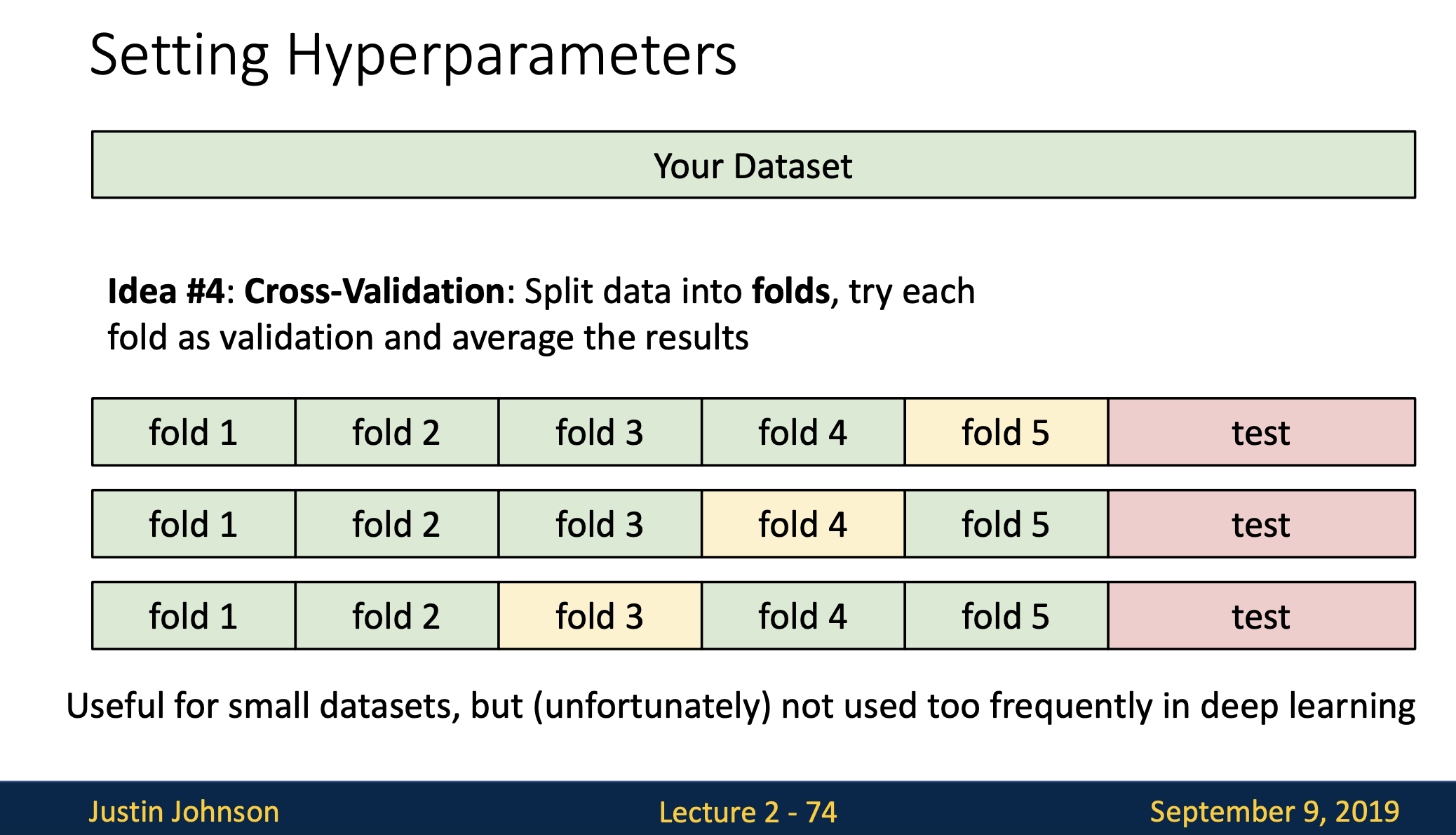
- 4번째는 교차검증(Cross-Validation)입니다.
- 이 아이디어는 아주 마지막에 사용할 테스트 데이터를 가장 먼저 정해놓은다음 학습 데이터와 검증 데이터를 나누는데 대신 학습데이터를 여러개의 덩어리(fold)로 분할하고 번갈아 가면서 검증 셋을 지정해줍니다.
- 이 예제는 5-fold cross validation을 사용하고 있고
처음 4개의 fold에서 하이퍼파라미터를 학습시키고 남은 한 fold에서 알고리즘을 평가합니다. - 이 방법은 데이터가 적을 때 사용하고 딥러닝같이 큰 모델을 학습시킬때는 잘 사용하지 않습니다.
교차검증을 사용하는 이유?
-
샘플 수가 충분하지 않을 경우에 우연히 데이터를 어떻게 나눴는지에 따라서 성능의 차이가 많이 날 수 있습니다.
-
데이터를 나누는 작업에 의해 모델 성능 결과가 크게 변동되지 않게 하기 위해 K-Fold 교차검증을 사용합니다.
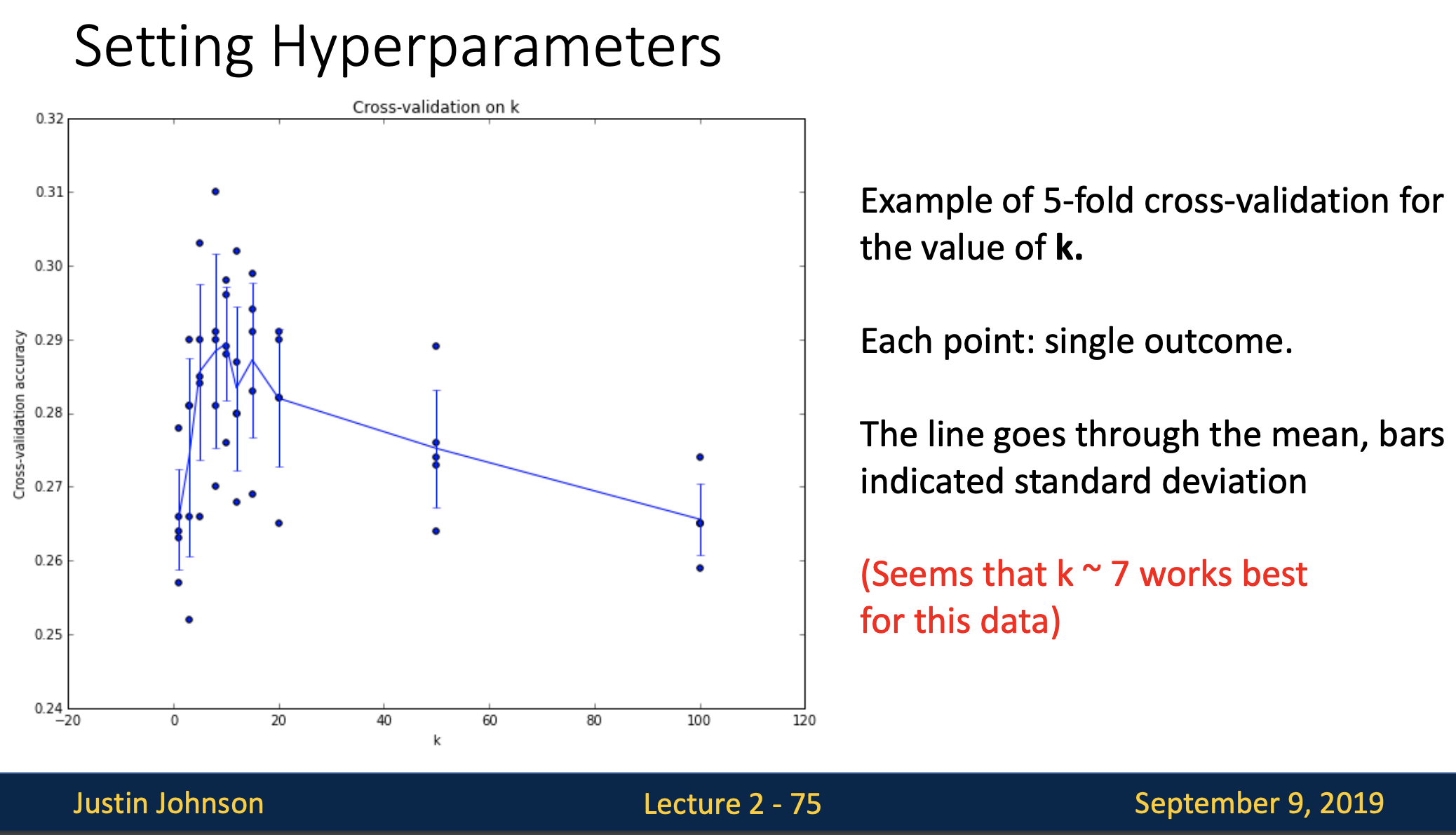
- 교차검증을 수행하고 나면 위와 같은 그래프를 볼 수 있습니다.
- x축은 knn의 k, y축은 분류 정확도입니다. 결과는 각 점으로 표시
- 이 그래프는 앞 예제의 5fold cross-validation을 수행한 결과물입니다. 우리가 머신러닝모델을 학습시키는 경우에도 이런 모습의 그래프를 그리게 될텐데 hyperparameter에 따라서 해당모델의 정확도와 성능을 이 그래프를 통해 평가할 수 있습니다.
- 그래프에서 선은 각 k에서의 결과의 평균으로 그려져 있으며 이 예제의 경우 k=7일 때 가장 좋은 것을 볼 수 있습니다.
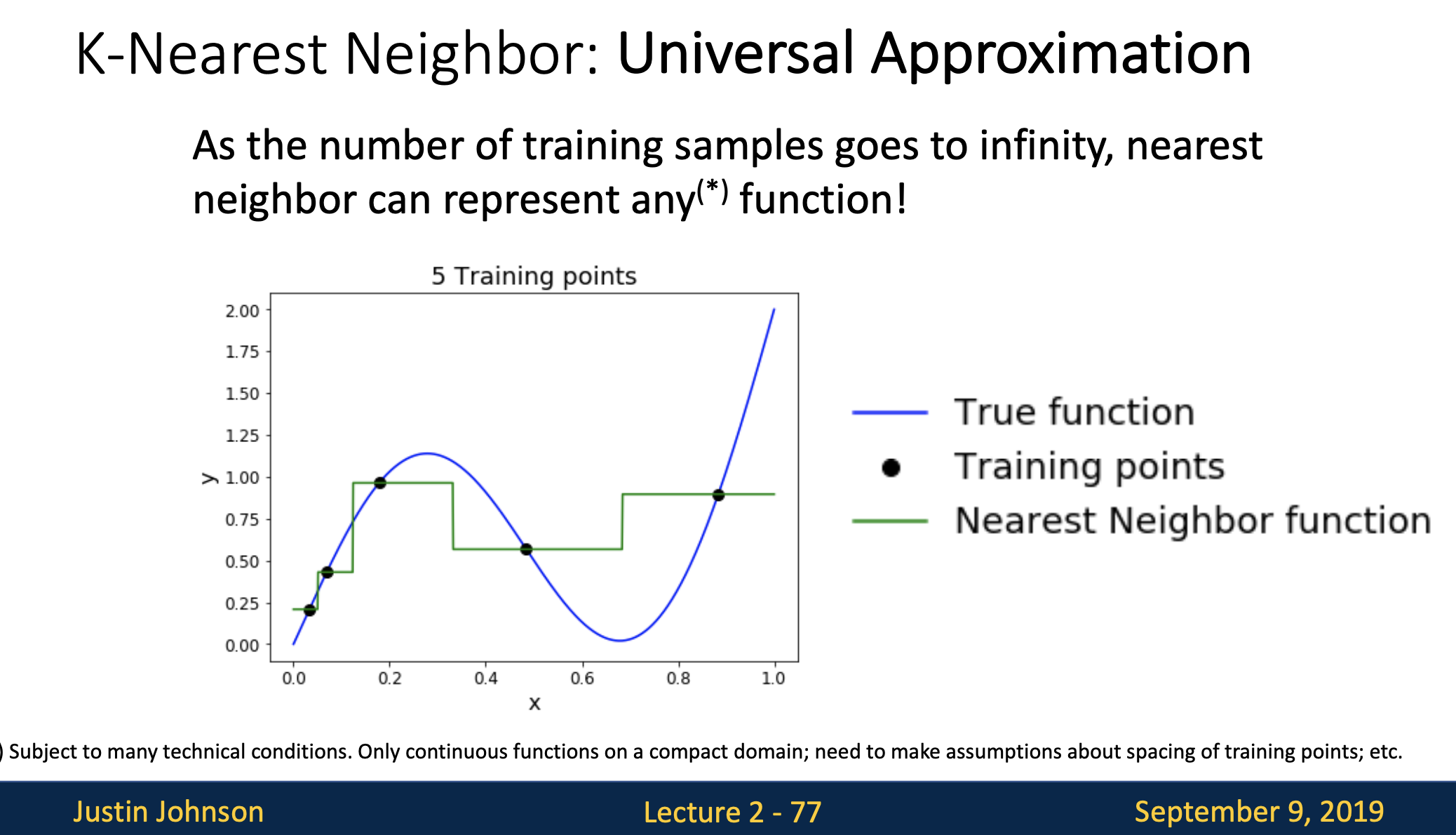
다음으로는 knn의 특성으로 universal approximation이 나왔는데 초록색으로 보이는 nearest neighbor function이 그림에서 보이는 검은점(training points)들 즉, 트레이닝된 샘플들의 수가 점점 무한이 늘어날수록 true function에 근사할 수 있는 특성이 있습니다.
- 첫번 째 그림에서 보면 검은점(training points)이 5개일 때 초록색선인 nearest neighbor function과 대비돼 아직은 계단식 함수처럼 보입니다.
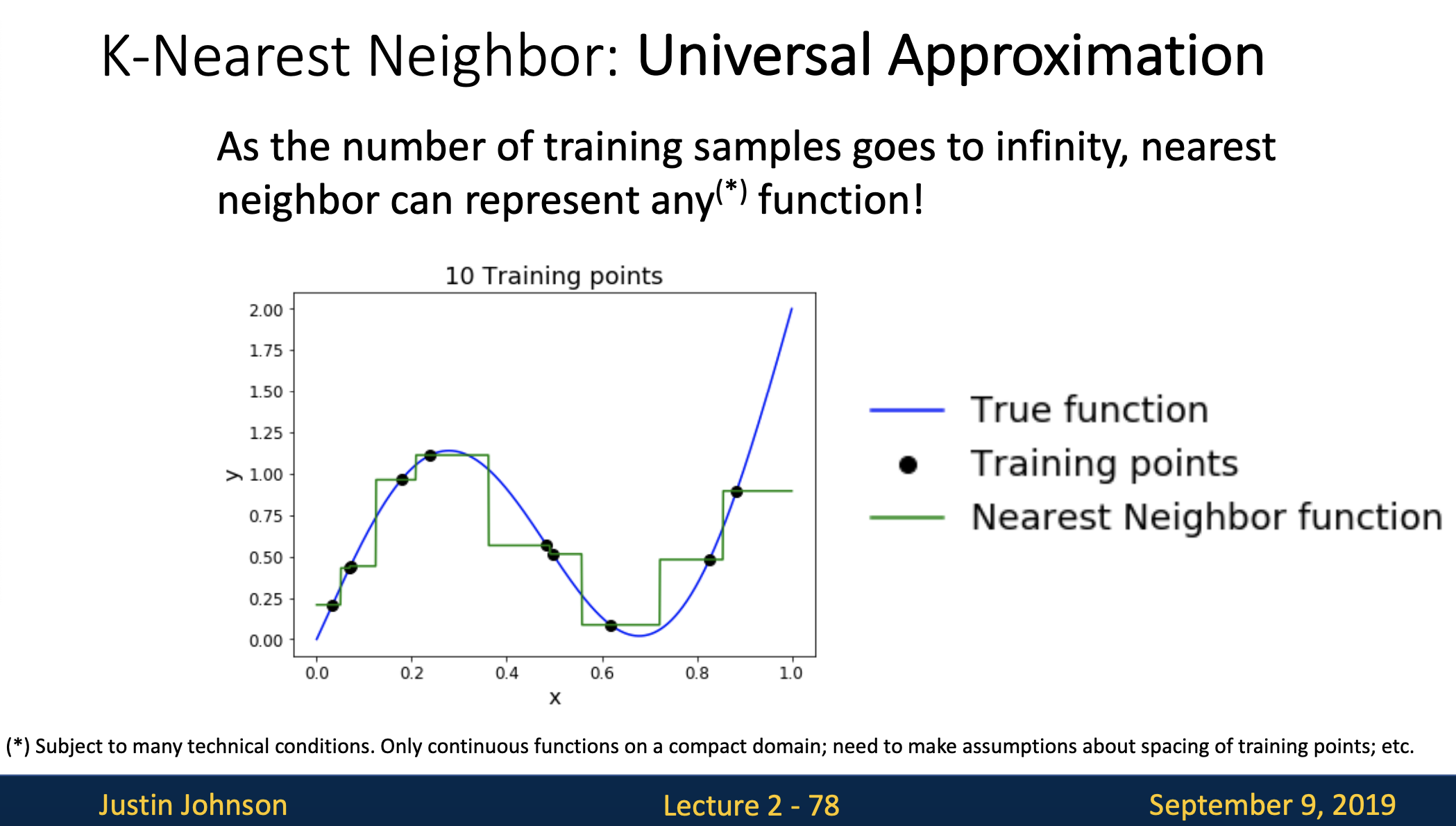
- 위 그림처럼 5개에서 10개로 트레이닝 포인트를 늘려봤는데 nearest neighbor함수가 전 보다는 true function에 가까워지는 것을 볼 수 있습니다.
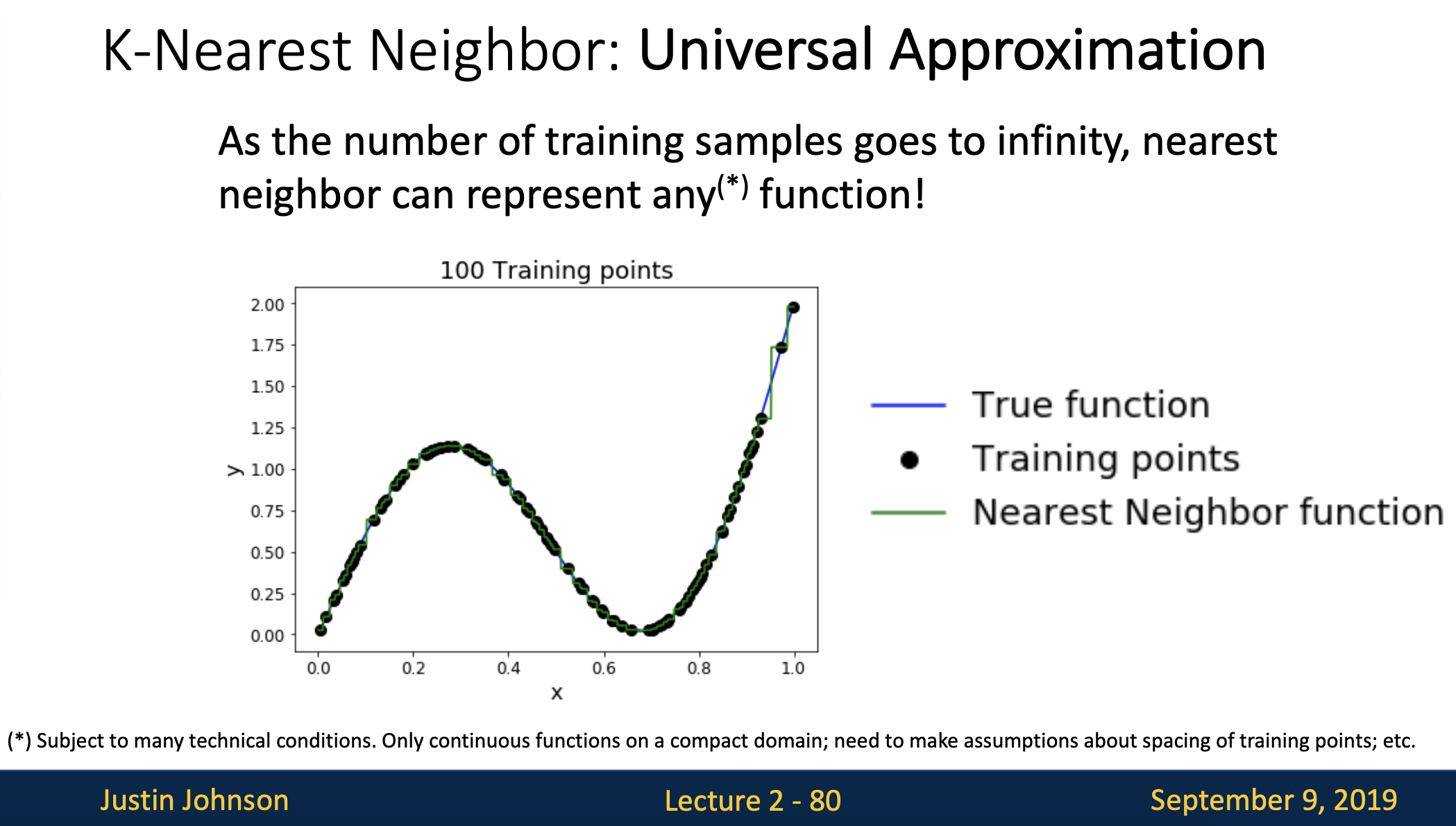
- 계속해서 트레이닝 포인트를 점점 20개, 100개까지 늘려봤는데 이제는 true function의 형태로 nearest neighbor function이 근사해 가는 것을 알 수 있습니다.

<차원의 저주>
-
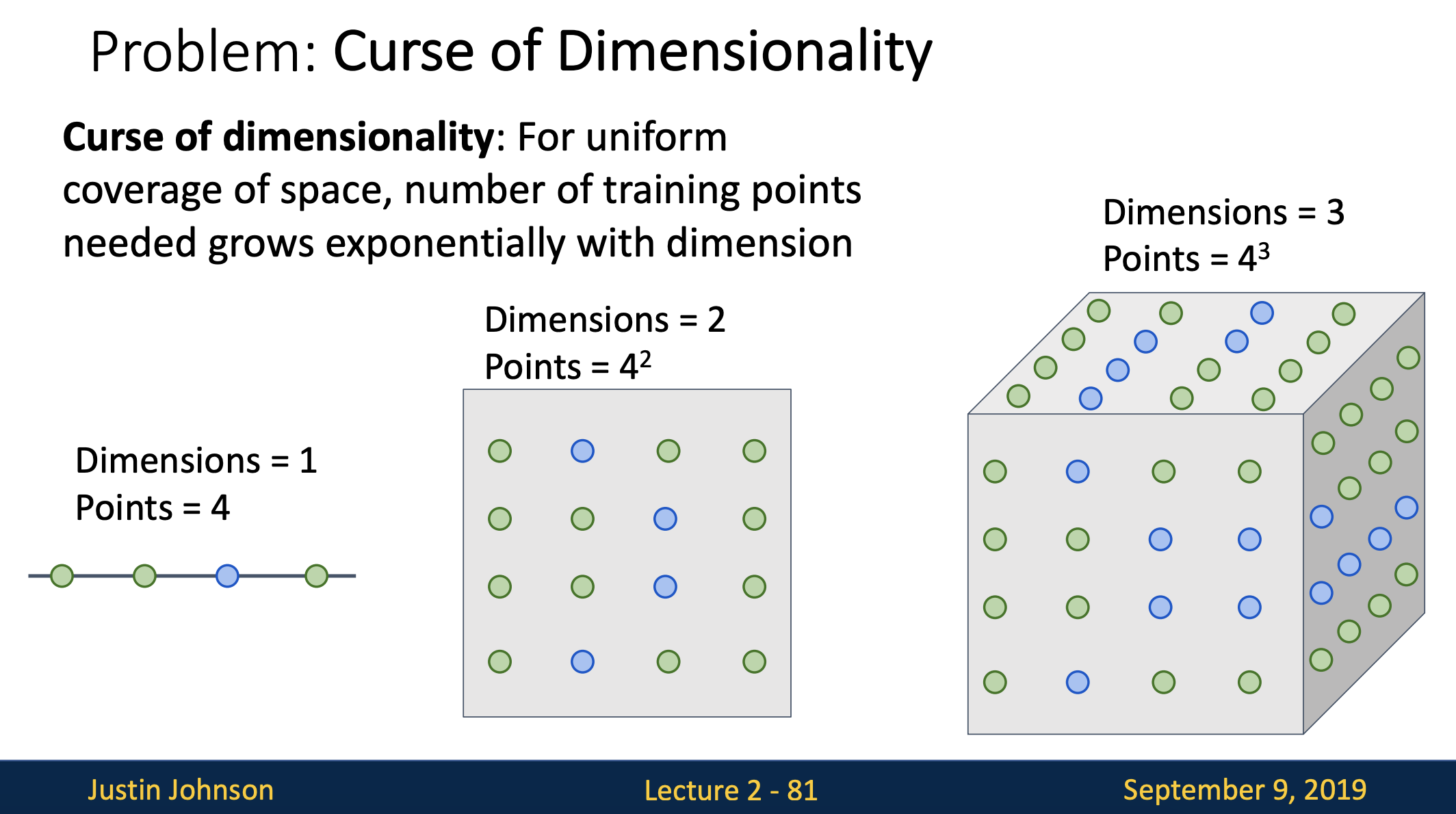
이 페이지에서는 k-nn의 문제점 중 하나인 차원의 저주(curse of dimensionality)에 대해서 설명하고 있습니다.
간단하게 말하면 데이터의 특징(feature)이 너무 많아서 알고리즘의 성능 저하가 일어나는 현상입니다. -
knn에대해 다시 한번 정리해보자면 knn이 하는 일은 트레이닝 데이터를 이용해서 공간을 분할하는 일이였습니다. 이는 knn이 잘 동작하려면 전체공간을 조밀하게 커버할 만큼의 충분한 트레이닝 샘플이 필요하다는 것을 의미합니다. 그렇지 않으면 테스트 이미지를 정확하게 분류하지 못합니다.
-
위 첫번 째 그림을 보면 점 하나는 트레이닝 샘플입니다. 그리고 각 점의 색은 트레이닝 샘플이 속한 카테고리를 나타낸다고 볼 수 있습니다.
-
왼쪽에 1차원 공간을 보면 이 공간을 조밀하게 채우려면 4개의 트레이닝 샘플이면 충분한데 그 옆에 2차원 공간을 다 채우려면 16개가 필요합니다. 이렇게 3차,4차,5차...로 늘어나게 되면 각 공간을 조밀하게 하기 위해선 필요한 트레이닝 샘플의 수는 기하급수적으로 증가하게 되는데 이는 좋지 않은 현상입니다.
-
왜냐하면 고차원의 이미지의 경우 모든 공간을 조밀하게 채울만큼의 데이터를 모으는 일은 현실적으로 불가능하고
차원의 저주의 가장 직접적인 영향은 feature의 개수/차원이 늘어날수록 필요한 계산량과 메모리 사용량은 그보다 더 빠르게 증가하게 돼 계산 불가 상태에 빠지기 때문에 knn을 사용할 때에는 이 점을 유의해서 사용해야 합니다.
* 차원의 저주를 해결하는 방법은?
[차원의 축소]
- 차원의 수를 줄이는 것, 변수의 수를 줄이는 것
- 차원의 축소를 통해서 모형의 정확도를 높일 수 있고 모델학습 속도가 향상될 수 있을 뿐더러 데이터를 시각화하기 좋습니다.
- 차원의 축소방법 중 1) Feature Selection 과 2) Feature Extraction 두가지방법이 있습니다.
1) Feature Selection(변수 선택)
-
중요한 변수를 찾는 과정으로써 가지고 있는 변수들 중 중요하다고 생각하는 변수 몇 개만 고르고 나머지는 다 버리는 방법입니다.
-
그렇기 때문에 어떠한 변수가 중요한 변수인지를 분석하는 과정이 중요한데 예를 들어 변수간에 중첩이 있는지 어떤 변수가 타겟에 큰 영향을 주는 지 등을 분석하여 중요한 변수를 찾습니다.
2) Feature Extraction(변수 추출)
-
모든 변수를 조합해서 데이터를 잘 표현할 수 있는 중요한 성분의 새로운 변수를 추출하는 방법입니다.
-
예를 들어 1,2,3,4,5는 변수가 있다고하면 이 1,2,3,4,5를 조합해서 새로운 A,B,C,D,E ..... 가 된다는 뜻 입니다.
-
변수추출을 할 때 주로 사용하는 방법은 주성분 분석(Principal component analysis; PCA)이고 잘 알려져있는 방법이기는 하지만 PCA로 모든 차원의 축소를 커버할 수 는 없습니다.
참고:
https://kkokkilkon.tistory.com/127
https://bahnsville.tistory.com/1198

-
앞에서 얘기한 문제때문에 입력이 이미지인 경우에는 k-nn분류기를 잘 사용하지 않습니다. 우선 테스트 시간이 너무 오래걸리고, L1,L2 distance가 이미지간의 거리를 측정하기에는 적절하지 않기 때문입니다.
-
위 이미지들을 보면 원본 이미지에 박스로 눈,입을 가려도 보고 살짝 이동도 시켜보고 파란색조도 추가해보기도 했는데 각 이미지들을 원본이미지와 비교해봤을 때 변형시킨 3개의 이미지와 원본이미지의 L2 distance가 동일하다고 합니다.
-
고차원의 공간에서 '거리'는 매우 직관적이지 않는 경우가 많습니다.
-
시각적으로 봤을 때 세번 째 이미지가 그나마 원본이랑 유사하긴 하지만 거리값에 이런 정보가 반영되지 않기때문에 별 의미가 없게 됩니다.


-
합성곱 신경망(ConvNet, Convolutional Neural Network)
-
주로 음성 인식이나 시각적 이미지를 분석하는데 사용
-
물체의 위치와 방향에 관계없이 물체의 고유한 특징을 학습할 수 있습니다.
-
ConvNet을 이미지에 적용시켜서 구한 feature vector를 가지고 knn을 적용하면 괜찮은 결과를 얻을 수 있다고 합니다.
-
Image Captioning : 이미지를 설명하는 문장으로 변환시켜주는 방법
* feature vector : 특징이 하나 이상의 수치 값을 가질 경우, d-차원의 열 벡터로 표현
