Martin Fowler의 2006년 글 'GUI Architectures'에 대한 번역입니다.
서문
그래픽 사용자 인터페이스(GUI)는 사용자와 소프트웨어 시스템 간에 풍부한 상호작용을 제공합니다. 하지만 이러한 풍부한 상호작용은 관리하기 복잡하기 때문에, 신중한 아키텍처 설계를 통해 복잡성을 제어하는 것이 중요합니다. Forms and Controls 패턴은 단순한 흐름을 가진 시스템에서는 잘 동작하지만, 복잡성이 증가하면 무너지는 경향이 있습니다. 그래서 대부분의 사람들은 “Model-View-Controller” (MVC) 패턴을 선택합니다. 그러나 안타깝게도 MVC는 가장 오해를 많이 받는 아키텍처 패턴 중 하나이며, 이 이름을 사용하는 시스템들은 서로 중요한 차이를 보입니다. 이러한 차이점을 설명하기 위해 Application Model, Model-View-Presenter(MVP), Presentation Model, MVVM 등의 용어가 사용되기도 합니다. MVC를 이해하는 가장 좋은 방법은 그것을 하나의 구체적인 구현이 아니라, "프레젠테이션과 도메인 로직을 분리하는 원칙" 및 "이벤트(옵저버 패턴)를 통해 프레젠테이션 상태를 동기화하는 방식" 으로 보는 것입니다.
Martin Fowler - 18 July 2006
그래픽 사용자 인터페이스(GUI)는 사용자와 개발자 모두에게 익숙한 소프트웨어 환경의 일부가 되었습니다. 디자인 관점에서 보면, GUI는 시스템 설계에서 특정한 문제들을 제기하며, 이러한 문제를 해결하기 위해 여러 가지 유사하지만 서로 다른 해결책들이 등장해 왔습니다.
내 관심사는 리치 클라이언트 개발(Rich-Client Development)을 위한 애플리케이션 개발자들이 활용할 수 있는 공통적이고 유용한 패턴을 식별하는 것입니다. 프로젝트 리뷰를 통해 다양한 설계를 보았고, 보다 공식적으로 문서화된 설계들도 접했습니다. 이러한 설계 안에는 유용한 패턴들이 포함되어 있지만, 이를 명확하게 설명하는 것은 종종 쉽지 않습니다. 예를 들어 Model-View-Controller(MVC)를 생각해 보겠습니다. MVC는 흔히 하나의 패턴이라고 불리지만, 나는 이를 단순한 패턴으로 보기 어렵다고 생각합니다. 왜냐하면 MVC는 여러 가지 다른 개념들을 포함하고 있기 때문입니다. 사람들이 서로 다른 출처에서 MVC에 대해 읽으면서 각기 다른 개념을 받아들이고, 이를 'MVC'라고 설명하는 경우가 많습니다. 여기에 더해 Semantic Diffusion(의미 확산)이라는 현상까지 발생합니다. 즉, 사람들이 MVC를 오해하면서 시간이 지나면서 원래의 개념과는 다른 방식으로 변형되어 사용되는 문제가 생깁니다.
이 글에서 나는 여러 흥미로운 아키텍처를 탐구하고, 그중 가장 흥미로운 특징들에 대한 나의 해석을 설명하고자 합니다. 이를 통해, 내가 설명하는 패턴들을 이해하는 데 도움이 될 수 있는 맥락을 제공하고자 합니다.
어느 정도 이 글을 UI 디자인의 개념이 여러 아키텍처를 거치며 발전해 온 지적 역사(intellectual history)로 볼 수도 있습니다. 하지만 이에 대해 한 가지 주의를 당부하고 싶습니다. 아키텍처를 이해하는 것은 쉽지 않은데, 그 이유는 많은 아키텍처가 변화하거나 사라지기 때문입니다. 아이디어의 확산 경로를 추적하는 것은 더욱 어렵습니다. 같은 아키텍처를 보고도 사람들이 서로 다른 해석을 하기 때문입니다. 특히, 나는 여기서 다루는 아키텍처들에 대해 철저한 조사를 수행한 것이 아닙니다. 대신, 널리 알려진 설명들을 참고하였으며, 만약 그 설명들이 어떤 중요한 요소를 빠뜨렸다면, 나 역시 그것에 대해 전혀 알지 못합니다. 따라서 내가 제공하는 설명을 절대적인 권위(authoritative) 있는 해석으로 받아들이지 마십시오. 또한, 내가 다루는 내용 중 일부는 관련성이 낮다고 판단하면 생략하거나 단순화하였습니다. 왜냐하면, 내 주요 관심사는 이 아키텍처들의 역사 자체가 아니라, 그 속에 담긴 근본적인 패턴들이기 때문입니다.
(여기에는 약간의 예외가 있는데, 나는 Smalltalk-80 환경에서 실행되는 MVC를 직접 살펴볼 기회가 있었습니다. 물론 이 조사 역시 철저한 분석(exhaustive)이라고 할 수는 없지만, 일반적인 설명에서 다루지 않는 요소들을 발견할 수 있었습니다. 이러한 경험은 내가 이 글에서 설명하는 다른 아키텍처들에 대한 묘사에도 더욱 신중해야 함을 깨닫게 해주었습니다. 만약 여러분이 이러한 아키텍처 중 하나에 익숙하고, 내가 중요한 내용을 잘못 설명했거나 누락했다는 점을 발견한다면, 꼭 알려주셨으면 합니다. 또한, 이 주제에 대한 보다 철저한 연구가 학문적으로도 가치 있는 연구 대상이 될 수 있다고 생각합니다.)
Forms and Controls
나는 이 탐구를 단순하면서도 익숙한 아키텍처로부터 시작하려 합니다. 이 아키텍처는 일반적으로 통용되는 이름이 없기 때문에, 이 글에서는 “Forms and Controls”라고 부르겠습니다. 이 아키텍처는 익숙한 방식인데, 그 이유는 1990년대의 클라이언트-서버 개발 환경에서 장려되었기 때문입니다. 예를 들면 Visual Basic, Delphi, PowerBuilder 같은 도구들이 이를 기반으로 했습니다. 이 방식은 여전히 널리 사용되지만, 디자인을 중시하는 사람들(나 같은 디자인 마니아들)에게는 종종 비판을 받기도 합니다.
이 아키텍처를 탐구하는 데 있어, 그리고 이후에 다룰 다른 아키텍처들을 설명하는 데 있어서도 공통된 예제를 사용할 것입니다. 내가 살고 있는 뉴잉글랜드(New England) 지역에는 대기 중의 아이스크림 입자 농도를 모니터링하는 정부 프로그램이 있습니다. 만약 이 농도가 너무 낮다면, 이는 우리가 충분한 아이스크림을 먹고 있지 않다는 신호이며, 이는 경제와 공공 질서에 심각한 위협이 됩니다. (나는 보통 이런 주제의 책에서 나오는 예제만큼 현실적인 예제를 사용하는 걸 좋아합니다.)
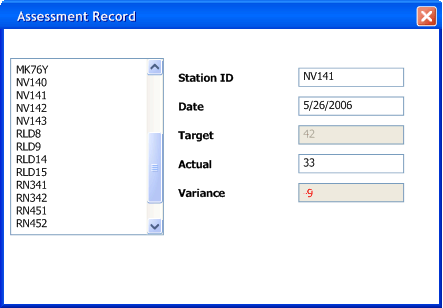
이 화면을 살펴보면, 이를 구성하는 요소들 사이에 중요한 구분이 있다는 것을 알 수 있습니다.
- 폼(Form): 특정 애플리케이션에 맞춰져 있음.
- 컨트롤(Controls): 보다 범용적인 요소들로 구성됨.
대부분의 GUI 환경은 이미 다양한 공통 컨트롤(예: 버튼, 텍스트 입력 필드, 체크박스 등)을 제공하며, 우리는 이를 애플리케이션에서 바로 활용할 수 있습니다. 또한, 필요에 따라 새로운 컨트롤을 직접 만들어 추가하는 것도 가능하며, 이는 종종 바람직한 방법이 되기도 합니다.
그러나 새로운 컨트롤을 만들더라도, "재사용 가능한 컨트롤"과 "특정 폼" 사이에는 여전히 명확한 구분이 존재합니다. 즉, 특별히 작성된 컨트롤이라 하더라도, 여러 개의 폼에서 재사용할 수 있다는 점이 중요합니다.
폼(Form)은 두 가지 주요한 역할을 담당합니다.
- 화면 레이아웃(Screen Layout): 계층적 구조(hierarchic structure)를 설정하여 화면에서 컨트롤들을 어떻게 배치할 것인지 정의합니다.
- 폼 로직(Form Logic): 개별 컨트롤에 직접 프로그래밍하기 어려운 동작을 처리합니다.
대부분의 GUI 개발 환경에서는 그래픽 편집기(Graphical Editor)를 제공하여, 개발자가 드래그 앤 드롭(Drag and Drop) 방식으로 폼에 컨트롤을 배치할 수 있도록 합니다. 이 방식은 폼 레이아웃(Form Layout)을 직관적으로 구성할 수 있게 해주며, 사용자 친화적인 UI를 빠르게 설계하는 데 유용합니다. (그러나, 이 방식이 항상 최선의 방법은 아닐 수도 있습니다. 이에 대해서는 나중에 더 자세히 다룰 것입니다.)
컨트롤들은 데이터를 표시하는 역할을 합니다. 이 경우에는 측정값에 대한 데이터를 표시합니다. 이 데이터는 거의 항상 어딘가에서 가져오는 것이며, 여기서는 대부분의 클라이언트-서버 도구 환경에서 가정하는 것처럼 SQL 데이터베이스에서 온다고 가정하겠습니다. 대부분의 상황에서 데이터의 세 가지 복사본이 존재합니다.
- 데이터의 한 복사본은 데이터베이스 자체에 존재합니다. 이 복사본은 데이터의 영구적인 기록이므로, 이를 레코드 상태(Record State)라고 부릅니다. 레코드 상태는 일반적으로 여러 사람이 다양한 메커니즘을 통해 공유하고 볼 수 있는 데이터입니다.
- 또 다른 복사본은 애플리케이션 내 메모리의 레코드 세트(Record Sets) 안에 존재합니다. 대부분의 클라이언트-서버 환경에서는 이를 쉽게 처리할 수 있도록 도구를 제공합니다. 이 데이터는 애플리케이션과 데이터베이스 간의 특정 세션(session) 동안에만 유효하기 때문에, 나는 이를 세션 상태(Session State)라고 부릅니다. 본질적으로, 세션 상태는 사용자가 데이터를 작업하는 동안 임시 로컬 버전을 제공하며, 사용자가 데이터를 저장(Save)하거나 커밋(Commit)하면, 이 데이터는 다시 데이터베이스와 병합되어 레코드 상태(Record State)로 반영됩니다. (레코드 상태와 세션 상태를 조정하는 문제는 여기서 다루지 않겠습니다. 이와 관련된 다양한 기법들은 [P of EAA]에서 설명했습니다.)
- 마지막 복사본은 GUI 컴포넌트 자체에 존재합니다. 엄밀히 말하면, 이것이 화면에서 사용자에게 보이는 데이터이므로, 나는 이를 스크린 상태(Screen State)라고 부릅니다. UI에서 중요한 점은 스크린 상태와 세션 상태가 어떻게 동기화되는가 하는 것입니다.
스크린 상태(Screen State)와 세션 상태(Session State)를 동기화하는 것은 중요한 작업입니다. 이를 더 쉽게 만들기 위해 사용된 도구 중 하나가 데이터 바인딩(Data Binding)입니다. 데이터 바인딩의 개념은 컨트롤의 데이터 또는 기본 레코드 세트가 변경될 때, 즉시 상대방에도 변경 사항이 반영되는 것입니다. 예를 들어, 사용자가 화면에서 측정값을 변경하면, 텍스트 필드 컨트롤이 자동으로 기본 레코드 세트의 해당 컬럼을 업데이트하는 방식입니다.
일반적으로 데이터 바인딩(Data Binding)은 까다로운 작업이 됩니다. 그 이유는, 컨트롤의 변경이 레코드 세트를 변경시키고, 그 결과로 레코드 세트가 다시 컨트롤을 업데이트하며, 다시 레코드 세트를 업데이트하는 순환(cycle)이 발생할 가능성이 있기 때문입니다. 그러나 사용 흐름(flow of usage)이 이러한 문제를 방지하는 데 도움이 됩니다. 화면을 열 때, 데이터를 세션 상태(Session State)에서 스크린 상태(Screen State)로 로드합니다. 그 이후에는 스크린 상태에서 세션 상태로 변경 사항이 전파됩니다. 화면이 표시된 이후, 세션 상태가 직접 수정되는 경우는 드뭅니다. 이러한 이유로, 데이터 바인딩이 완전히 양방향(Bi-Directional)으로 이루어지는 것은 아닙니다. 대부분의 경우, 데이터 바인딩은 초기 업로드(세션 상태 → 스크린 상태)와 이후 변경 사항 전파(스크린 상태 → 세션 상태)에 한정됩니다.
데이터 바인딩(Data Binding)은 클라이언트-서버 애플리케이션의 많은 기능을 꽤 잘 처리합니다. 실제 값을 변경하면, 컬럼이 업데이트됩니다. 심지어 선택된 측정소(station)를 변경하는 것만으로도 현재 선택된 행이 레코드 세트에서 변경되며, 그 결과 다른 컨트롤들이 새롭게 갱신(refresh)됩니다.
이러한 동작의 대부분은 프레임워크 개발자들이 미리 구현해 둡니다. 그들은 일반적인 요구 사항을 분석하고, 이를 쉽게 해결할 수 있도록 설계합니다. 특히, 이러한 기능은 컨트롤에 값을 설정하는 방식으로 이루어집니다. 이 값들은 일반적으로 속성(Properties)이라고 불립니다. 컨트롤은 속성 편집기(Property Editor)를 통해 특정 레코드 세트(Record Set)의 컬럼(Column)과 연결됩니다. 즉, 컬럼 이름을 간단한 속성으로 설정하면, 해당 컬럼과 컨트롤이 자동으로 바인딩됩니다.
데이터 바인딩을 사용하면, 적절한 매개변수 설정(parameterization)을 통해 많은 작업을 처리할 수 있습니다. 그러나 모든 경우를 처리할 수 있는 것은 아닙니다. 대부분의 경우, 매개변수 옵션으로 해결되지 않는 로직이 일부 존재합니다. 예를 들어, 분산(variance) 계산은 내장된 데이터 바인딩 기능으로 처리할 수 없는 작업입니다. 이것은 애플리케이션에 특화된(application-specific) 로직이므로, 일반적으로 폼(Form) 내에 구현됩니다.
이 기능이 제대로 동작하려면, 폼(Form)은 실제 필드 값이 변경될 때마다 이를 감지해야 합니다. 이를 위해, 범용적인(Generic) 텍스트 필드가 폼 내의 특정 동작을 호출하도록 해야 합니다. 이 과정은 단순히 클래스 라이브러리를 가져와 호출하는 것보다 더 복잡한 작업입니다. 그 이유는 제어의 역전(Inversion of Control, IoC)이 개입되기 때문입니다.
이러한 기능을 구현하는 방법에는 여러 가지가 있습니다. 클라이언트-서버 툴킷에서 일반적으로 사용된 방법은 이벤트(Events) 개념입니다. 각 컨트롤(Control)은 발생시킬 수 있는 이벤트 목록을 가지고 있습니다. 어떤 외부 객체든 특정 이벤트에 관심이 있다고 등록하면, 컨트롤이 그 이벤트를 발생시킬 때 해당 객체를 호출하게 됩니다. 본질적으로, 이것은 옵저버 패턴(Observer Pattern)의 변형입니다. 즉, 폼(Form)이 컨트롤을 관찰(Observe)하는 구조가 됩니다. 프레임워크는 일반적으로, 개발자가 폼 내에서 특정 이벤트가 발생했을 때 실행할 서브루틴(Subroutine) 형태의 코드를 작성할 수 있도록 메커니즘을 제공했습니다. 이벤트와 서브루틴이 어떻게 연결되는지는 플랫폼마다 다르며, 이 글의 논의에서 중요한 부분은 아닙니다. 핵심은, 이러한 기능을 가능하게 하는 어떤 방식이 존재했다는 점입니다.
폼(Form) 내의 서브루틴(Subroutine)이 제어권을 갖게 되면, 필요한 동작을 수행할 수 있습니다. 폼은 특정 동작을 실행하고, 필요한 경우 컨트롤(Control)을 수정할 수 있습니다. 이후, 데이터 바인딩(Data Binding)을 활용하여 변경 사항이 자동으로 세션 상태(Session State)에 반영되도록 합니다.
이것이 필요한 또 다른 이유는 데이터 바인딩이 항상 존재하는 것은 아니기 때문입니다. 윈도우 컨트롤 시장은 크며, 모든 컨트롤이 데이터 바인딩을 지원하는 것은 아닙니다. 만약 데이터 바인딩이 존재하지 않는다면, 폼이 동기화를 수행해야 합니다. 이것은 다음과 같은 방식으로 작동할 수 있습니다.
- 초기에는 레코드 세트에서 데이터를 가져와 위젯(Widgets)에 채웁니다.
- 저장(Save) 버튼이 눌리면, 변경된 데이터를 다시 레코드 세트(Record Set)로 복사(Copy Back) 합니다.
데이터 바인딩이 존재한다고 가정하고, 실제 값(actual value)을 편집하는 과정을 살펴보겠습니다. 폼(Form) 객체는 범용적인(Generic) 컨트롤에 대한 직접적인 참조(Direct References)를 보유하고 있습니다. 화면에 있는 각 컨트롤마다 하나씩 참조가 존재하지만, 여기서는 실제 값(Actual), 분산(Variance), 목표 값(Target) 필드에만 집중하겠습니다.
텍스트 필드는 "텍스트 변경(Text Changed)" 이벤트를 선언합니다. 폼(Form)이 화면을 초기화할 때, 해당 이벤트에 자신을 구독(Subscribe) 시킵니다. 그리고 자신의 특정 메서드(actual_textChanged)에 바인딩합니다.
사용자가 실제 값을 변경하면, 텍스트 필드 컨트롤은 해당 이벤트를 발생시키고, 프레임워크 바인딩의 마법을 통해 actual_textChanged가 실행됩니다. 이 메서드는 실제 값과 목표 값을 텍스트 필드에서 가져와서 빼기를 수행한 후, 그 값을 분산(variance) 필드에 넣습니다. 또한, 그 값이 어떤 색으로 표시되어야 하는지를 결정하고 텍스트 색상을 적절하게 조정합니다.
이 아키텍처를 몇 가지 핵심 문장으로 요약할 수 있습니다.
- 개발자는 애플리케이션에 특화된 폼을 작성하며, 이는 범용적인 컨트롤(Generic Controls)을 사용합니다.
- 폼은 자신 안의 컨트롤들의 레이아웃을 정의합니다.
- 폼은 컨트롤을 관찰(Observe)하며, 컨트롤이 발생시키는 중요한 이벤트에 반응하는 핸들러 메서드(Handler Methods)를 가집니다.
- 단순한 데이터 편집은 데이터 바인딩(Data Binding)을 통해 처리됩니다.
- 복잡한 변경 사항은 폼의 이벤트 핸들링 메서드에서 수행됩니다.
Model View Controller
아마도 UI 개발에서 가장 널리 인용되는 패턴은 모델-뷰-컨트롤러(Model-View-Controller, MVC)일 것입니다. 하지만 동시에 가장 잘못 인용되는 패턴이기도 합니다. MVC라고 설명된 것을 수없이 보았지만, 실제로는 전혀 MVC가 아닌 경우가 많았습니다. 솔직히 말해, 이러한 혼란이 발생하는 주요 이유 중 하나는 고전적인 MVC(Classic MVC)의 일부 개념이 현대의 리치 클라이언트(Rich Client) 환경에서는 잘 맞지 않기 때문입니다. 하지만 지금은 일단 MVC의 기원(Origins)부터 살펴보도록 하겠습니다.
MVC를 살펴볼 때, 이 패턴이 UI 작업을 체계적으로 수행하려는 최초의 시도 중 하나였다는 점을 기억하는 것이 중요합니다. 1970년대에는 그래픽 사용자 인터페이스(GUI) 자체가 흔하지 않았습니다. 앞서 설명한 폼과 컨트롤(Forms and Controls) 모델은 MVC 이후에 등장했습니다. 이를 먼저 설명한 이유는 더 단순하기 때문이며, 단순하다고 해서 항상 좋은 것은 아닙니다. 다시 한 번, Smalltalk-80의 MVC를 평가(Assessment) 예제를 통해 설명하겠습니다. 다만, 이를 설명하는 과정에서 실제 Smalltalk-80의 세부 사항과는 다소 차이가 있을 수 있습니다. 예를 들어, Smalltalk-80은 기본적으로 모노크롬(monochrome, 흑백) 시스템이었습니다.
MVC의 핵심 개념이자 이후의 다양한 프레임워크에 가장 큰 영향을 준 아이디어는 "분리된 프레젠테이션(Separated Presentation)"입니다. 분리된 프레젠테이션(Separated Presentation)의 개념은, 현실 세계를 모델링하는 도메인 객체(Domain Objects)와 화면에서 보이는 GUI 요소인 프레젠테이션 객체(Presentation Objects)를 명확하게 분리하는 것입니다. 도메인 객체(Domain Objects)는 완전히 독립적(self-contained)이어야 하며, 프레젠테이션과의 직접적인 참조 없이 동작 가능해야 합니다. 또한, 여러 개의 프레젠테이션을 동시에 지원할 수 있어야 합니다. 이러한 접근 방식은 유닉스(Unix) 문화에서도 중요한 개념이었으며, 오늘날에도 많은 애플리케이션이 GUI와 명령줄 인터페이스(Command-Line Interface, CLI)를 동시에 지원할 수 있도록 합니다.
MVC에서 도메인 요소(Domain Element)는 모델(Model)이라고 불립니다. 모델 객체(Model Objects)는 UI에 대해 완전히 무지(ignorant)해야 합니다. 우리의 평가 UI(Assessment UI) 예제를 시작하기 위해, 모델을 측정값(Reading)으로 가정하고, 이 객체가 관련 데이터를 저장하는 필드(fields)를 가진다고 하겠습니다. (잠시 후에 설명하겠지만, 리스트 박스(List Box)의 존재로 인해 "모델이 무엇인가?"라는 질문이 더 복잡해질 것입니다. 하지만 지금은 리스트 박스를 무시하고 논의를 진행하겠습니다.)
MVC에서는 도메인 모델(Domain Model)을 일반적인 객체(Regular Objects) 기반으로 가정합니다. 이는 앞서 설명한 폼과 컨트롤(Forms and Controls) 모델의 "레코드 세트(Record Set)" 개념과는 다릅니다. 이러한 차이는 각 모델이 전제하는 기본 가정의 차이를 반영합니다. 폼과 컨트롤(Forms and Controls)은 대부분의 사람들이 관계형 데이터베이스(Relational Database)의 데이터를 쉽게 조작하는 것을 원한다고 가정합니다. MVC(Model-View-Controller)는 우리가 조작하는 것이 일반적인 Smalltalk 객체(Smalltalk Objects)라고 가정합니다.
MVC의 프레젠테이션(Presentation) 부분은 남은 두 요소인 뷰(View)와 컨트롤러(Controller)로 구성됩니다. 컨트롤러(Controller)의 역할은 사용자의 입력(User Input)을 받아 이를 어떻게 처리할지 결정하는 것입니다.
이 시점에서 강조해야 할 점은, 뷰(View)와 컨트롤러(Controller)가 단 하나만 존재하는 것이 아니라는 것입니다. 화면의 각 요소마다 뷰-컨트롤러(View-Controller) 쌍이 존재합니다. 즉, 각 컨트롤(Control)과 전체 화면(Screen)에도 개별적인 뷰와 컨트롤러가 할당됩니다. 따라서 사용자의 입력(User Input)에 반응하는 첫 번째 단계는 여러 컨트롤러들이 협력하여 어느 컨트롤이 편집되었는지를 확인하는 과정입니다. 이 예제에서는 "실제 값(Actuals)" 텍스트 필드가 편집되었기 때문에, 이제 해당 텍스트 필드의 컨트롤러가 다음 동작을 처리하게 됩니다.
다른 이후의 환경들과 마찬가지로, Smalltalk도 재사용 가능한(Generic) UI 컴포넌트가 필요하다는 점을 깨달았습니다. 이 경우, 재사용 가능한 컴포넌트는 "뷰-컨트롤러(View-Controller) 쌍"이 됩니다. 두 요소 모두 범용적인(Generic) 클래스이므로, 이를 애플리케이션별(Application-Specific) 동작에 맞게 연결해야 합니다. 평가 화면(Assessment View)은 전체 화면을 나타내며, 하위 컨트롤들의 레이아웃을 정의합니다. 이 점에서 보면, 이는 폼과 컨트롤(Forms and Controls) 모델에서의 "폼(Form)"과 유사합니다. 그러나 폼과 달리, MVC에서는 평가 컨트롤러(Assessment Controller)가 하위 구성 요소들의 이벤트 핸들러(Event Handlers)를 포함하지 않습니다.
텍스트 필드의 설정은 모델인 reading과의 링크를 제공하고, 텍스트가 변경될 때 호출할 메서드를 지정하는 것에서 시작됩니다. 화면이 초기화될 때, 이 메서드는 #actual:로 설정됩니다. (앞에 붙은 # 기호는 Smalltalk에서 기호(Symbol) 또는 내부 문자열(Interned String)을 의미합니다.) 텍스트 필드 컨트롤러는 reading 객체에서 해당 메서드를 반사적 호출(Reflective Invocation)하여 변경 사항을 적용합니다. 본질적으로, 이 방식은 데이터 바인딩(Data Binding)과 동일한 메커니즘을 따릅니다. 즉, 컨트롤은 기본 객체(행, Row)에 연결되며, 해당 객체에서 조작할 메서드(열, Column)를 지정받는 구조입니다.
따라서 전체적인 객체가 하위 위젯(Low-Level Widgets)을 관찰하는 것이 아니라, 하위 위젯들이 모델(Model)을 관찰하며, 모델 자체가 폼(Form)이 수행해야 할 많은 결정을 처리하게 됩니다. 이 경우, 분산(Variance)을 계산하는 작업은 reading 객체 자체가 수행하는 것이 자연스럽습니다.
MVC에서 옵저버(Observer)는 중요한 역할을 하며, 실제로 MVC가 발전시키는 데 기여한 개념 중 하나로 여겨집니다. 이 경우, 모든 뷰(Views)와 컨트롤러(Controllers)는 모델(Model)을 관찰(Observe)합니다. 즉, 모델이 변경되면, 뷰가 이에 반응합니다. 예를 들어, 실제 값(Actual) 텍스트 필드 뷰는 reading 객체의 변경 사항을 감지하고, 해당 텍스트 필드의 속성(Aspect)으로 정의된 메서드(#actual)를 호출하여 그 결과를 자신의 값(Value)으로 설정합니다. (이와 유사한 방식으로 색상(Color)도 업데이트되지만, 이 과정에는 별도의 문제가 발생할 수 있으며, 이에 대해서는 곧 다루겠습니다.)
여기서 주목해야 할 점은, 텍스트 필드 컨트롤러가 직접 뷰(View)의 값을 설정하지 않았다는 것입니다. 대신 모델(Model)을 업데이트한 후, 옵저버(Observer) 메커니즘이 변경 사항을 처리하도록 맡겼습니다. 이것은 폼과 컨트롤(Forms and Controls) 방식과 상당히 다른 접근 방식입니다. 폼과 컨트롤(Forms and Controls) 방식에서는 폼이 컨트롤(Control)의 값을 직접 업데이트하고, 데이터 바인딩(Data Binding)이 이를 기본 레코드 세트(Record Set)로 반영합니다. 이 두 가지 방식을 각각 "흐름 동기화(Flow Synchronization)"와 "옵저버 동기화(Observer Synchronization)" 패턴(Pattern)으로 설명해 보겠습니다. 이 패턴들은 스크린 상태(Screen State)와 세션 상태(Session State)의 동기화를 트리거(Trigger)하는 서로 다른 방법을 설명합니다.
- 폼과 컨트롤(Forms and Controls) 방식
- 애플리케이션의 흐름(Flow)에 따라 업데이트가 필요한 여러 컨트롤을 직접 조작하는 방식을 사용합니다.
- MVC(Model-View-Controller) 방식
- 모델(Model)에 변경 사항을 적용하고, 이를 관찰하는(Observing) 뷰(View)가 자동으로 업데이트되도록 합니다.
흐름 동기화(Flow Synchronization)는 데이터 바인딩이 존재하지 않을 때 더욱 뚜렷하게 나타납니다. 애플리케이션이 직접 동기화(Synchronization)를 수행해야 할 경우, 보통 애플리케이션 흐름(Flow)에서 중요한 지점에서 동기화가 이루어집니다. 예를 들면, 화면을 열 때(Screen Opening), 저장 버튼을 눌렀을 때(Hitting the Save Button) 등의 시점에서 애플리케이션이 데이터를 동기화하는 방식이 일반적입니다.
옵저버 동기화(Observer Synchronization)의 결과 중 하나는, 컨트롤러(Controller)가 사용자가 특정 위젯을 조작할 때 다른 위젯들이 어떻게 변경되어야 하는지 거의 알 필요가 없다는 것입니다. 폼과 컨트롤(Forms and Controls) 방식에서는 폼(Form)이 변경 사항을 추적하고, 화면 전체의 상태(Screen State)가 일관성을 유지하도록 직접 조정해야 합니다. 특히 화면이 복잡할수록(Form이 관리해야 할 요소가 많아질수록) 이 과정은 더욱 복잡해집니다. 반면, 옵저버 동기화 방식에서는 컨트롤러는 이 모든 것을 신경 쓰지 않아도 됩니다. 변경 사항이 모델(Model)에 반영되면, 옵저버 패턴(Observer Pattern)에 의해 필요한 뷰(View)들이 자동으로 업데이트됩니다.
이러한 "유용한 무지(Useful Ignorance)"는 하나의 모델 객체(Model Object)를 여러 개의 화면(Screen)에서 동시에 보고 있을 때 특히 유용합니다. 클래식한 MVC의 예제(Classic MVC Example)로는 스프레드시트(Spreadsheet) 스타일의 데이터 화면과 동일한 데이터를 시각화하는 여러 개의 그래프 창을 예로 들 수 있습니다. 이러한 경우, 스프레드시트 창은 자신과 함께 열려 있는 다른 창들을 신경 쓸 필요가 없습니다. 그저 모델만 변경하면, 옵저버 동기화(Observer Synchronization)에 의해 자동으로 다른 뷰들이 업데이트됩니다. 반면, 흐름 동기화(Flow Synchronization) 방식에서는 현재 열려 있는 다른 창들을 파악할 방법이 필요하며, 각 창에 직접 "새로고침(Refresh)"을 요청해야 합니다.
옵저버 동기화(Observer Synchronization)는 편리하지만, 단점도 존재합니다. 옵저버 동기화의 문제점은 옵저버 패턴(Observer Pattern) 자체의 근본적인 문제와 동일합니다. 즉, 코드를 읽는 것만으로는 무슨 일이 일어나고 있는지 파악하기 어렵다는 점입니다. 나는 과거에 Smalltalk-80에서 특정 화면들이 어떻게 동작하는지 분석하려고 했을 때, 이 문제를 매우 강하게 실감했습니다. 코드를 읽는 것만으로는 어느 정도까지만 이해할 수 있었습니다. 하지만 옵저버 메커니즘이 작동하는 순간부터, 더 이상 코드만으로는 무엇이 일어나는지 알 수 없었습니다. 결국 디버거와 Trace Statements을 사용해야만 실제 동작을 파악할 수 있었습니다. 이처럼 옵저버 기반 동작(Observer Behavior)은 "암묵적 동작(Implicit Behavior)"이기 때문에 이해하고 디버깅하기 어렵습니다.
동기화(Synchronization)에 대한 접근 방식의 차이는 시퀀스 다이어그램(Sequence Diagram)을 보면 특히 두드러지지만, MVC와 폼과 컨트롤(Forms and Controls) 방식 간의 가장 중요한 차이점이자 가장 큰 영향력을 가진 요소는 "분리된 프레젠테이션(Separated Presentation)"입니다. 예를 들어, 실제 값(Actual)과 목표 값(Target)의 차이를 계산하는 분산(Variance) 연산은 도메인(Domain) 로직이며, UI와는 관련이 없습니다. 따라서 "분리된 프레젠테이션(Separated Presentation)" 원칙을 따르면, 이 연산은 시스템의 도메인 계층(Domain Layer)에 위치해야 합니다. 그리고 바로 이 역할을 수행하는 것이 reading 객체입니다. 실제로 reading 객체를 살펴보면, 그 안의 "분산(Variance) 계산 기능"은 UI와는 무관하게 도메인 로직으로서 완전히 자연스럽게 존재합니다.
그러나 이제부터 몇 가지 복잡한 문제들을 살펴볼 수 있습니다. MVC 이론을 적용하는 데 방해가 되는 두 가지 난해한 부분이 있으며, 지금까지 이를 생략해 왔습니다. 첫 번째 문제는 분산(Variance)의 색상을 설정하는 것입니다. 값을 어떤 색으로 표시할지는 도메인의 일부가 아니므로, 이는 도메인 객체(Domain Object)에 포함되기 어렵습니다. 이를 해결하는 첫 번째 단계는, 논리의 일부가 도메인 로직(Domain Logic)에 속한다는 점을 인식하는 것입니다. 우리가 하는 작업은 분산 값(Variance)에 대한 정성적 판단(Qualitative Assessment)입니다. 예를 들어,
- 좋음(Good) → 목표보다 5% 이상 초과
- 나쁨(Bad) → 목표보다 10% 이상 미달
- 보통(Normal) → 그 외의 경우
이처럼 분산을 평가(Assessment)하는 것은 도메인 로직의 일부입니다. 하지만,
- 이 평가 결과를 색상(Color)으로 매핑하는 것
- 화면의 분산 필드(Variance Field) 색상을 변경하는 것
이 과정은 뷰 로직(View Logic)에 속합니다. 문제는 이 뷰 로직을 어디에 배치할 것인지입니다. 이 기능은 표준적인 텍스트 필드(Standard Text Field)의 일부가 아니므로, MVC 구조에서 이를 적절히 배치할 방법을 고민해야 합니다.
이러한 문제는 초기 Smalltalk 개발자들도 직면했던 문제이며, 그들은 이를 해결하기 위한 몇 가지 방법을 고안했습니다. 앞서 설명한 방식은 비교적 "지저분한(dirty)" 해결책으로, 즉, 도메인의 순수성을 일부 타협하여 문제를 해결하는 방법입니다. 나 또한 가끔은 이러한 "순수하지 않은(Impure) 방식"을 사용할 때가 있지만, 이를 습관처럼 사용하지 않도록 노력합니다.
우리는 폼과 컨트롤(Forms and Controls) 방식과 유사한 방법을 사용할 수도 있습니다. 즉, 평가 화면 뷰(Assessment Screen View)가 분산 필드 뷰(Variance Field View)를 관찰(Observe)하도록 설정하고, 분산 필드가 변경될 때 평가 화면이 반응하여 해당 필드의 텍스트 색상을 설정하는 방식입니다. 그러나 이 접근 방식에는 몇 가지 문제가 있습니다. 옵저버(Observer) 메커니즘을 더욱 많이 사용해야 하며, 옵저버를 많이 사용할수록 구조가 기하급수적으로 복잡해집니다. 또한, 여러 뷰(View) 간의 결합도(Coupling)가 증가하여 유지보수가 어려워질 수 있습니다.
내가 선호하는 방법은 새로운 유형의 UI 컨트롤을 만드는 것입니다. 본질적으로 우리가 필요한 것은, 도메인 객체에 질의하여 정성적(qualitative) 값을 가져오고, 내부에 저장된 값과 색상의 매핑 테이블과 비교한 후, 그에 따라 폰트 색상을 설정하는 UI 컨트롤입니다. 이 접근 방식에서는, 평가 화면 뷰(Assessment View)가 UI 컨트롤을 조립하는 과정에서, 이 컨트롤이 참조할 값-색상 매핑 테이블과 도메인 객체에 보낼 메시지를 함께 설정하면 됩니다. 이는 마치 모니터링할 필드의 속성(Aspect)을 설정하는 방식과 유사합니다. 이 방식은 특히 텍스트 필드(Text Field)를 쉽게 서브클래싱(Subclassing)하여 추가 동작을 구현할 수 있다면 효과적으로 작동할 수 있습니다. 물론, 이 접근 방식의 실현 가능성은 UI 컴포넌트가 서브클래싱을 얼마나 쉽게 허용하는지에 따라 달라집니다. Smalltalk 환경에서는 서브클래싱이 매우 용이했지만, 다른 환경에서는 구현이 더 어려울 수도 있습니다.
마지막 방법은 새로운 유형의 모델 객체(Model Object)를 만드는 것입니다. 이 모델 객체는 화면(Screen)을 중심으로 동작하지만, 개별 위젯(Widgets)에는 독립적인 구조를 가집니다. 즉, 화면 전체의 모델 역할을 수행하는 객체가 되는 것입니다. 이 모델 객체는 reading 객체와 동일한 메서드(Method)를 가지되, 내부적으로 해당 요청을 reading 객체로 위임(Delegate)합니다. 하지만, 추가적으로 UI에만 관련된 동작(예: 텍스트 색상 변경)을 지원하는 메서드도 포함할 수 있습니다.
이 마지막 방법은 여러 경우에서 효과적으로 작동하며, 실제로 Smalltalk 개발자들 사이에서 널리 사용된 방식이 되었습니다. 나는 이 개념을 프레젠테이션 모델(Presentation Model)이라고 부릅니다. 왜냐하면 이 모델은 UI(프레젠테이션 계층)에 맞춰 설계되었으며, 그 일부로 동작하기 때문입니다. (이 패턴은 MVVM(Model-View-ViewModel)이라는 이름으로도 알려져 있습니다.)
프레젠테이션 모델(Presentation Model)은 또 다른 프레젠테이션 로직 문제, 즉 프레젠테이션 상태(Presentation State)를 해결하는 데도 유용합니다. 기본적인 MVC 개념에서는, 뷰(View)의 모든 상태는 모델(Model)의 상태로부터 유도될 수 있다고 가정합니다. 하지만, 리스트 박스(List Box)에서 선택된 측정소(Station)를 어떻게 추적할 것인가? 같은 문제가 발생합니다. 프레젠테이션 모델은 이러한 문제를 해결하는 방법을 제공합니다. 즉, 이러한 상태를 저장할 적절한 위치를 제공하는 것입니다. 비슷한 문제는 "저장(Save) 버튼이 데이터가 변경되었을 때만 활성화되는 경우"에서도 발생합니다. 이 버튼이 활성화되는지 여부는 도메인 모델의 상태가 아니라, 모델과의 상호작용(Interaction)에서 발생하는 상태(State)입니다. 프레젠테이션 모델은 이러한 UI 관련 상태를 관리할 수 있는 공간을 제공하여 문제를 해결합니다.
이제 MVC에 대한 핵심 원칙(Soundbites)을 정리해 보겠습니다.
- 프레젠테이션(View & Controller)과 도메인(Model)을 강력하게 분리합니다 – Separated Presentation
- GUI 위젯을 컨트롤러(사용자 입력 반응)와 뷰(모델의 상태 표시)로 나눕니다. 컨트롤러와 뷰는 직접적으로 통신하지 않고, 모델을 통해 간접적으로 상호작용해야 합니다.
- 뷰(View)와 컨트롤러(Controller)는 모델(Model)을 관찰(Observe)하여 변경 사항을 반영해야 합니다. 이를 통해 여러 위젯이 직접 통신할 필요 없이 동기화(Synchronization)될 수 있습니다 – Observer Synchronization
VisualWorks Application Model
앞서 논의했듯이, Smalltalk-80의 MVC는 매우 영향력이 컸으며 훌륭한 기능들을 갖추고 있었지만, 몇 가지 단점도 존재했습니다. 1980~1990년대 동안 Smalltalk이 발전하면서, 고전적인 MVC(Classic MVC) 모델에서 중요한 변형(Variations)이 등장하게 되었습니다. 실제로, MVC라는 개념이 거의 사라졌다고 말할 수도 있습니다. 특히, "MVC에서 뷰(View)와 컨트롤러(Controller)의 분리가 필수적인 요소"라고 본다면, 이는 MVC라는 이름 자체가 암시하는 구조와도 어긋나기 때문입니다.
MVC에서 확실히 효과적이었던 개념은 "분리된 프레젠테이션(Separated Presentation)"과 "옵저버 동기화(Observer Synchronization)"였습니다. 그렇기 때문에, Smalltalk이 발전하면서도 이 두 가지 개념은 유지되었습니다. 사실, 많은 사람들에게 이 개념들이 MVC의 핵심 요소라고 여겨졌습니다.
이 시기에 Smalltalk은 여러 갈래로 분화됩니다. Smalltalk의 기본 개념과 (최소한의) 언어 정의(Language Definition)는 그대로 유지되었지만, 서로 다른 라이브러리를 가진 다양한 Smalltalk 버전들이 등장하게 되었습니다. 특히 UI 관점에서 이러한 변화는 중요한 의미를 가졌습니다. 몇몇 Smalltalk 라이브러리는 네이티브 위젯(Native Widgets)을 사용하기 시작했으며, 이는 폼과 컨트롤(Forms and Controls) 스타일에서 사용되던 컨트롤(Control)과 유사한 방식이었습니다.
Smalltalk은 원래 Xerox PARC 연구소에서 개발되었으며, 이후 ParcPlace라는 별도의 회사가 분사하여 Smalltalk의 개발과 상업화를 진행했습니다. ParcPlace Smalltalk는 VisualWorks라고 불렸으며, 크로스플랫폼(Cross-Platform) 지원을 핵심 목표로 삼았습니다. 즉, Windows에서 작성한 Smalltalk 프로그램을 그대로 Solaris에서 실행할 수 있었습니다. (이는 Java보다 훨씬 이전부터 가능했던 기능이었습니다.) 이러한 특성 때문에, VisualWorks는 네이티브 위젯을 사용하지 않았으며,GUI를 완전히 Smalltalk 내에서 자체적으로 구현했습니다.
내가 MVC에 대해 논의하면서 마지막으로 지적한 문제점들은 특히 뷰 로직(View Logic)과 뷰 상태(View State)를 어떻게 다룰 것인가에 대한 문제였습니다. VisualWorks는 이러한 문제를 해결하기 위해 "애플리케이션 모델(Application Model)"이라는 개념을 도입하여 이를 프레임워크에 통합하는 방향으로 발전시켰습니다. 이 개념은 프레젠테이션 모델(Presentation Model)과 유사한 방향으로 나아가는 구조였습니다. 사실, 프레젠테이션 모델과 유사한 접근 방식은 VisualWorks에서 새롭게 등장한 개념이 아니었습니다. 원래 Smalltalk-80의 코드 브라우저(Code Browser)도 이와 매우 유사한 구조를 가지고 있었습니다. 하지만 VisualWorks의 애플리케이션 모델은 이를 프레임워크 내에서 완전한 형태로 정착시켰습니다.
이러한 종류의 Smalltalk에서 핵심 요소(Key Element) 중 하나는 속성(Properties)을 객체(Objects)로 변환하는 개념이었습니다. 우리는 일반적으로 객체(Object)가 속성을 가진다고 생각합니다. 예를 들어, 사람(Person) 객체는 이름(Name)과 주소(Address) 같은 속성을 가질 수 있습니다. 이러한 속성들은 필드(Fields)일 수도 있지만, 다른 방식으로 구현될 수도 있습니다. 속성에 접근하는 방식은 보통 언어별 표준 관례(Convention)를 따릅니다. 예를 들어,
- Java에서는
temp = aPerson.getName(); aPerson.setName("martin"); - C#에서는
temp = aPerson.name; aPerson.name = "martin";
이처럼 속성 접근 방식은 언어마다 차이가 있지만, 기본적으로 객체가 내부 데이터를 제공하는 역할을 합니다.
속성 객체(Property Object)는 기존 방식과 다르게, 속성이 실제 값을 직접 반환하는 것이 아니라 실제 값을 감싸는 객체(Wrapping Object)를 반환합니다. 따라서 VisualWorks에서는 이름(Name) 속성을 요청하면, 실제 값이 아니라 래핑된 객체(Wrapping Object)를 받게 됩니다. 그리고, 실제 값을 얻으려면 이 래핑 객체에 다시 값을 요청해야 합니다. 예를 들어, 사람(Person) 객체의 이름(Name) 속성에 접근하는 방식은 다음과 같습니다.
temp = aPerson name value. "이름 속성의 실제 값을 가져옴"
aPerson name value: 'martin'. "이름 속성의 값을 'martin'으로 설정"즉, aPerson name은 이름 값을 포함하는 래핑 객체를 반환하고, value 메시지를 보내면 그 래핑 객체로부터 실제 값이 반환됩니다. 마찬가지로 value: 메시지를 사용하면 새로운 값을 설정할 수 있습니다. 이 방식은 기존의 속성 접근 방식과는 다르게, 속성을 단순한 값이 아니라 객체로 다룸으로써 보다 유연한 동작이 가능하도록 합니다.
속성 객체(Property Objects)는 위젯(Widget)과 모델(Model) 간의 매핑을 보다 쉽게 만들어 줍니다. 이 방식에서는, 위젯에 "어떤 메시지를 보내야 해당 속성을 가져올 수 있는지"만 지정하면 됩니다. 위젯은 속성 객체에서 value와 value: 메시지를 사용하여 올바른 값을 가져오거나 설정할 수 있습니다. 또한, VisualWorks의 속성 객체(Property Objects)는 옵저버(Observer)를 설정할 수 있도록 지원합니다. onChangeSend: aMessage to: anObserver 메시지를 사용하면, 속성이 변경될 때 특정 메시지를 지정된 옵저버(Observer) 객체에 보낼 수 있습니다. 즉, 속성 객체는 위젯과 모델 간의 연결을 단순화할 뿐만 아니라, 변화 감지(Observation) 기능까지 제공하는 구조입니다.
VisualWorks에서 Property Object라는 이름의 클래스를 직접 찾을 수는 없습니다. 대신, value / value: / onChangeSend: 프로토콜을 따르는 여러 클래스들이 존재합니다. 가장 단순한 형태는 ValueHolder입니다. ValueHolder는 단순히 값을 저장하고 관리하는 역할을 합니다. 하지만 이번 논의와 더 관련이 깊은 클래스는 AspectAdaptor입니다. AspectAdaptor는 다른 객체의 속성을 완전히 감싸(Property Wrapping) 속성 객체처럼 사용할 수 있도록 해줍니다. 이를 활용하면, PersonUI 클래스에서 Person 객체의 속성을 감싸는 속성 객체를 정의할 수 있습니다. 예를 들어, 다음과 같은 코드로 구현할 수 있습니다.
adaptor := AspectAdaptor subject: person.
adaptor forAspect: #name.
adaptor onChangeSend: #redisplay to: self.이제, 이 애플리케이션 모델(Application Model)이 우리가 사용하고 있는 예제에서 어떻게 적용될 수 있는지 살펴보겠습니다.
애플리케이션 모델과 클래식 MVC의 가장 큰 차이점은, 도메인 모델 클래스(Reader)와 위젯(Widget) 사이에 중간 계층(Intermediate Layer)으로서의 애플리케이션 모델 클래스가 추가되었다는 점입니다. 즉, 위젯(Widgets)은 더 이상 도메인 객체(Domain Objects)에 직접 접근하지 않습니다. 위젯의 모델(Model)은 애플리케이션 모델입니다. 이처럼 애플리케이션 모델이 중간 계층으로 작동함으로써, UI와 도메인 로직 간의 결합도(Coupling)를 낮추고, 보다 유연한 데이터 바인딩을 가능하게 합니다. 여전히 위젯들은 뷰(View)와 컨트롤러(Controller)로 구분되지만, 새로운 위젯을 직접 개발하지 않는 이상, 이 구분은 크게 중요하지 않습니다.
UI를 구성할 때는 UI 페인터(UI Painter)를 사용하며, 이 과정에서 각 위젯의 애스펙트(Aspect)를 설정합니다. 애스펙트는 애플리케이션 모델의 특정 메서드와 연결되며, 이 메서드는 속성 객체(Property Object)를 반환합니다.
그림 10(Figure 10)은 기본적인 업데이트 순서가 어떻게 작동하는지를 보여줍니다. 텍스트 필드에서 값을 변경하면, 해당 필드는 애플리케이션 모델(Application Model) 내부의 속성 객체(Property Object)를 업데이트합니다. 그런 다음, 이 업데이트는 기본 도메인 객체(Domain Object)로 전파되어, 실제 값(Actual Value)이 변경됩니다.
이 시점에서 옵저버(Observer) 관계가 작동하기 시작하며, 실제 값(Actual Value)이 변경될 때 reading 객체가 변경되었음을 알릴 수 있도록 설정해야 합니다. 이를 위해, actual 값을 수정하는 수정자(Modifier) 메서드에서 reading 객체가 변경되었음을 표시하는 호출을 추가하며, 특히 분산(Variance) 애스펙트가 변경되었음을 명확히 해야 합니다. 분산의 AspectAdaptor를 설정할 때 이를 reading 객체를 관찰하도록 지정하면, reading이 변경될 때 업데이트 메시지를 수신하고 이를 다시 텍스트 필드로 전달하게 되며, 텍스트 필드는 AspectAdaptor를 통해 새로운 값을 가져오는 과정을 시작합니다.
이처럼 애플리케이션 모델과 속성 객체(Property Objects)를 활용하면, 많은 코드를 작성하지 않고도 업데이트를 연결(Wire Up)할 수 있습니다. 또한, 세밀한(Fine-Grained) 동기화(Synchronization)를 지원하지만, 개인적으로 이것이 꼭 좋은 방식이라고 생각하지는 않습니다.
애플리케이션 모델(Application Models)은 UI에 특화된 동작(Behavior)과 상태(State)를 실제 도메인 로직(Domain Logic)과 분리할 수 있도록 해줍니다. 예를 들어, 앞서 언급한 문제 중 하나인 리스트(List)에서 현재 선택된 항목을 유지하는 문제는, 도메인 모델의 리스트(List)를 감싸면서, 현재 선택된 항목도 함께 저장하는 특정 유형의 AspectAdaptor를 사용하여 해결할 수 있습니다.
그러나 이러한 방식의 한계(Limitation)는 더 복잡한 동작(Behavior)을 구현하려면 특별한 위젯(Widgets)과 속성 객체(Property Objects)를 추가로 만들어야 한다는 점입니다. 예를 들어, 기본적으로 제공되는 객체들만으로는 분산(Variance)의 정도에 따라 텍스트 색상을 변경하는 기능을 구현할 수 없습니다. 애플리케이션 모델(Application Model)과 도메인 모델(Domain Model)을 분리하면, 올바른 방식으로 의사 결정을 구조화할 수 있습니다. 하지만, 위젯이 AspectAdaptor를 관찰(Observe)하도록 하려면 새로운 클래스를 만들어야 합니다.이 과정이 너무 많은 작업(Too Much Work)처럼 느껴지는 경우가 많았으며, 이를 더 쉽게 해결하는 방법으로 애플리케이션 모델이 위젯(Widgets)에 직접 접근할 수 있도록 허용하는 방식이 있었습니다. 그림 11(Figure 11)은 이러한 구조를 보여줍니다.
이처럼 애플리케이션 모델(Application Model)이 위젯(Widgets)을 직접 업데이트하는 방식은 프레젠테이션 모델(Presentation Model)의 개념과 일치하지 않습니다. 즉, VisualWorks의 애플리케이션 모델은 엄밀한 의미에서 프레젠테이션 모델이 아닙니다. 위젯을 직접 조작해야 하는 필요성은 많은 사람들에게 일종의 "지저분한 우회 방법(Dirty Workaround)"으로 여겨졌으며, 이러한 문제를 해결하기 위해 모델-뷰-프레젠터(Model-View-Presenter, MVP) 아키텍처가 발전하는 계기가 되었습니다.
애플리케이션 모델에 대한 핵심 원칙(Soundbites)
- MVC와 마찬가지로 "분리된 프레젠테이션(Separated Presentation)"과 "옵저버 동기화(Observer Synchronization)"를 따릅니다.
- 프레젠테이션 로직과 상태를 관리하는 중간 계층으로 애플리케이션 모델을 도입하였으며, 이는 프레젠테이션 모델의 부분적 발전으로 볼 수 있습니다.
- 위젯(Widgets)은 도메인 객체(Domain Objects)를 직접 관찰하지 않고, 애플리케이션 모델을 관찰합니다.
- 속성 객체(Property Objects)를 광범위하게 활용하여 레이어 간 연결을 돕고, 옵저버를 통한 세밀한 동기화(Fine-Grained Synchronization)를 지원합니다.
- 애플리케이션 모델이 위젯을 직접 조작하는 것이 기본 동작(Default Behavior)은 아니었지만, 복잡한 경우에는 흔히 사용되었습니다.
Model-View-Presenter (MVP)
MVP(Model-View-Presenter)는 1990년대 IBM에서 처음 등장했으며, Taligent에서 더욱 두드러지게 발전한 아키텍처입니다. 이 개념은 주로 Potel 논문(Potel Paper)을 통해 알려졌으며, 이후 Dolphin Smalltalk 개발자들에 의해 더욱 대중화되고 체계적으로 설명되었습니다. 그러나, MVP에 대한 Potel 논문과 Dolphin Smalltalk의 설명은 완전히 일치하지 않으며, 그럼에도 불구하고 기본적인 개념 자체는 널리 확산되며 인기를 얻게 되었습니다.
MVP(Model-View-Presenter)를 이해하는 데 있어, UI 설계에서 나타나는 두 가지 주요 흐름 간의 불일치(Mismatch)를 고려하는 것이 도움이 됩니다. 한편으로는 폼과 컨트롤(Forms and Controls) 아키텍처가 있으며, 이는 UI 설계의 주류 접근 방식으로, 이해하기 쉽고 재사용 가능한 위젯과 애플리케이션 특화 코드(Application-Specific Code)를 효과적으로 분리합니다. 반면, MVC 및 그 변형들(MVC and its Derivatives)은 폼과 컨트롤 방식이 부족한 "분리된 프레젠테이션(Separated Presentation)"을 강력하게 지원하며, 도메인 모델(Domain Model) 기반 프로그래밍을 수행할 수 있는 구조적 맥락을 제공합니다. 나는 MVP를 이 두 흐름을 통합하려는 시도로 보며, 각 접근 방식의 장점을 결합하여 최적의 설계를 만들고자 하는 과정이라 생각합니다.
Potel의 MVP에서 첫 번째 요소는 뷰(View)를 위젯(Widgets)들의 구조(Structure)로 취급하는 것입니다. 여기서 위젯(Widgets)은 폼과 컨트롤(Forms and Controls) 모델의 컨트롤(Controls)에 해당하며, MVC에서의 뷰/컨트롤러(View/Controller) 분리를 제거합니다. 즉, MVP의 뷰(View)는 단순히 위젯들로 구성된 구조일 뿐이며, 사용자 상호작용(User Interaction)에 대한 반응을 정의하는 동작(Behavior)은 포함하지 않습니다.
사용자 행동(User Acts)에 대한 실제 반응(Active Reaction)은 별도의 프레젠터(Presenter) 객체에서 처리됩니다. 기본적인 사용자 입력 핸들러는 여전히 위젯 내에 존재하지만,이 핸들러들은 단순히 프레젠터에게 제어권(Control)을 넘기는 역할만 수행합니다.
프레젠터는 이벤트에 대한 반응(Reaction)을 결정하는 역할을 합니다. Potel은 이 상호작용을 주로 모델(Model)에 대한 액션(Actions) 관점에서 설명하며, 이를 위해 명령(Commands)과 선택(Selections) 시스템을 활용합니다. 특히 주목할 만한 점은, 모델에 대한 모든 수정 작업(Edits to the Model)을 하나의 명령(Command)으로 포장하는 방식으로, 이러한 구조는 실행 취소(Undo) 및 다시 실행(Redo) 기능을 구현하는 데 매우 유용한 기반을 제공합니다.
프레젠터가 모델을 업데이트하면, MVC에서 사용했던 것과 동일한 옵저버 동기화(Observer Synchronization) 방식을 통해 뷰도 함께 업데이트됩니다.
Dolphin의 MVP 설명도 유사한 구조를 따릅니다. 가장 큰 공통점은 역시 프레젠터의 존재입니다. 하지만 Dolphin에서는 프레젠터가 명령(Commands)과 선택(Selections)을 통해 모델에 작용하는 구조가 명확히 정의되지 않았습니다. 또한, 프레젠터가 뷰를 직접 조작하는 것에 대해 명시적으로 다루고 있습니다. Potel의 설명에서는 프레젠터가 뷰를 직접 조작해야 하는지에 대해 언급이 없지만, Dolphin에서는 이 기능이 필수적이며, 특히 애플리케이션 모델에서 분산(Variance) 필드의 텍스트 색상을 변경하는 것이 어려웠던 문제를 해결하는 데 중요한 역할을 한다고 보았습니다.
MVP를 바라보는 다양한 관점 중 하나는 프레젠터가 뷰의 위젯을 얼마나 제어하는가에 대한 정도의 차이입니다. 한쪽에서는 모든 뷰 로직(View Logic)을 뷰 자체에 남겨두고, 프레젠터는 모델을 렌더링하는 과정에 관여하지 않는 방식이 있습니다. 이 스타일은 Potel이 암시한 방식에 가깝습니다. 반면, Bower와 McGlashan이 제시한 방향은 내가 "감독 컨트롤러(Supervising Controller)"라고 부르는 스타일입니다. 여기서는 뷰가 선언적으로 표현할 수 있는 뷰 로직을 직접 처리하며, 프레젠터는 보다 복잡한 경우만 개입하는 방식입니다.
프레젠터가 모든 위젯의 조작을 담당하는 방식으로 확장할 수도 있습니다. 이러한 스타일을 나는 "패시브 뷰(Passive View)"라고 부릅니다. 패시브 뷰는 MVP의 원래 설명에는 포함되지 않았지만, 테스트 가능성(Testability) 문제를 탐구하는 과정에서 발전한 개념입니다. 이 방식에 대해서는 나중에 더 자세히 다룰 예정이지만, 패시브 뷰 역시 MVP의 한 가지 변형(Flavor of MVP)으로 볼 수 있습니다.
MVP를 이전에 논의한 개념들과 비교하기 전에, 우선 여기서 다루는 두 MVP 논문(Potel과 Dolphin)이 기존 개념들과 비교를 시도했다는 점을 언급할 필요가 있습니다. 그러나, 그 해석 방식은 내가 보는 관점과는 다소 차이가 있습니다. Potel은 MVC의 컨트롤러(Controller)를 전체적인 조정자(Coordinator)로 암시하고 있지만, 나는 그렇게 보지 않습니다. Dolphin에서는 MVC의 문제점에 대해 많이 다루고 있지만, 여기서 말하는 MVC는 내가 설명한 "고전적인 MVC(Classic MVC)"가 아니라, VisualWorks의 애플리케이션 모델 설계를 의미합니다. (이 부분에 대해서는 그들을 탓할 수는 없습니다.고전적인 MVC에 대한 정보를 찾는 것은 지금도 쉽지 않지만, 당시에는 더욱 어려웠기 때문입니다.)
이제 MVP와 기존 아키텍처들을 비교(Contrasts)해 보겠습니다.
- 폼과 컨트롤(Forms and Controls):
- MVP는 모델을 중심으로 동작하며, 프레젠터는 모델을 조작하고, 옵저버 동기화(Observer Synchronization)를 통해 뷰를 업데이트합니다. 위젯에 직접 접근하는 것이 허용되긴 하지만, 이것은 보조적인 방식이며, 모델을 통해 동작하는 것이 우선시되어야 합니다.
- MVC:
- MVP에서는 "감독 컨트롤러(Supervising Controller)"가 모델을 조작합니다. 위젯은 사용자 입력(User Gestures)을 감독 컨트롤러로 전달합니다. MVP에서는 위젯을 뷰와 컨트롤러로 분리하지 않습니다. 프레젠터는 컨트롤러와 유사하지만, 사용자 입력을 직접 처리하지 않습니다. 프레젠터는 일반적으로 위젯 수준이 아니라 폼(Form) 수준에서 동작하며, 이것이 MVC와의 가장 큰 차이점 중 하나입니다.
- 애플리케이션 모델(Application Model):
- 뷰는 이벤트를 프레젠터에게 전달하는 방식이 애플리케이션 모델과 유사합니다. 하지만, 뷰는 도메인 모델(Domain Model)로부터 직접 업데이트를 받을 수도 있습니다. 즉, 프레젠터가 "프레젠테이션 모델(Presentation Model)"처럼 동작하지 않습니다. 프레젠터는 옵저버 동기화(Observer Synchronization) 방식에 맞지 않는 경우, 위젯을 직접 조작할 수도 있습니다.
MVP의 프레젠터와 MVC의 컨트롤러 사이에는 분명한 유사점이 있으며, 프레젠터는 느슨한 형태의(More Flexible) MVC 컨트롤러라고 볼 수 있습니다. 그 결과, 많은 설계에서 MVP 스타일을 따르면서도 "프레젠터" 대신 "컨트롤러"라는 용어를 동의어처럼 사용하기도 합니다. 또한, "사용자 입력(User Input) 처리"를 논의할 때,일반적으로 "컨트롤러(Controller)"라는 용어를 사용하는 것이 합리적인 주장이라고 볼 수도 있습니다.
MVP(감독 컨트롤러, Supervising Controller) 방식의 아이스크림 모니터 구현(Figure 12)를 살펴보겠습니다.이 방식은 폼과 컨트롤(Forms and Controls) 방식과 유사하게 시작됩니다.
- 실제 값(Actual Value) 텍스트 필드에서 텍스트가 변경되면 이벤트가 발생합니다.
- 프레젠터는 이 이벤트를 감지(Listens)하고, 변경된 필드 값을 가져옵니다.
- 이 시점에서 프레젠터는 reading 도메인 객체를 업데이트합니다.
- 분산(Variance) 필드는 reading을 옵저버(Observer)로 등록하고 있으므로, 업데이트된 값을 감지하고 자신의 텍스트를 변경합니다.
- 마지막 단계는 분산 필드의 색상(Color)을 설정하는 것입니다.
- 프레젠터가 reading에서 카테고리(Category)를 가져오고,
- 그에 따라 분산 필드의 색상을 업데이트합니다.
이 방식에서 주목할 점은, 모델의 변경 사항은 옵저버 동기화(Observer Synchronization)를 통해 자동으로 뷰에 반영되지만, 뷰의 일부 요소(예: 색상 변경)는 프레젠터가 직접 처리한다는 점입니다.
MVP의 핵심 원칙(Soundbites)
- 사용자 입력(User Gestures)은 위젯에서 "감독 컨트롤러(Supervising Controller)"로 전달됩니다.
- 프레젠터는 도메인 모델(Domain Model)의 변경을 조정(Coordinate)합니다.
- MVP의 다양한 변형(Variants)은 뷰 업데이트를 처리하는 방식이 다릅니다. 옵저버 동기화(Observer Synchronization)를 사용하는 방식부터, 프레젠터가 모든 업데이트를 직접 처리하는 방식까지 다양한 스펙트럼이 존재합니다.
Humble View
지난 몇 년 동안 자체 테스트 가능한 코드(Self-Testing Code)를 작성하는 것이 강력한 흐름이 되었습니다. 나는 패션 감각에 대해 조언할 마지막 사람이지만, 이런 흐름에 깊이 몰입하고 있으며, 적극적으로 참여하고 있습니다. 내 동료들 중 다수는 xUnit 프레임워크, 자동 회귀 테스트(Automated Regression Tests), 테스트 주도 개발(Test-Driven Development, TDD), 지속적 통합(Continuous Integration, CI) 등과 같은 개념의 열렬한 지지자들입니다.
자체 테스트 가능한 코드(Self-Testing Code)를 논의할 때, 사용자 인터페이스(UI)는 빠르게 문제점으로 떠오릅니다. 많은 사람들이 GUI 테스트는 어렵거나, 거의 불가능하다고 느낍니다. 그 주된 이유는, UI가 전체 UI 환경과 강하게 결합(Tightly Coupled)되어 있으며, 이를 분리하여 개별적으로 테스트하기가 매우 어렵기 때문입니다.
때때로 GUI 테스트의 어려움은 과장되기도 합니다. 실제로, 위젯을 생성하고 테스트 코드에서 이를 조작하는 방식만으로도 상당한 수준까지 테스트할 수 있습니다. 그러나, 중요한 사용자 상호작용(Interactions)을 놓치거나 스레딩(Threading) 문제 발생, 테스트 실행 속도가 지나치게 느려지는 등의 문제들로 인해 이 접근 방식이 불가능하거나 비효율적인 경우도 존재합니다.
그 결과, 테스트하기 어려운 객체(Object)의 동작을 최소화하는 방식으로 UI를 설계하려는 움직임이 꾸준히 이어져 왔습니다. Michael Feathers는 이러한 접근 방식을 "The Humble Dialog Box"에서 명확하게 정리했으며, Gerard Meszaros는 이를 확장하여 "Humble Object" 개념을 제시했습니다. 즉, 테스트하기 어려운 객체는 가능한 한 최소한의 동작(Behavior)만 가져야 한다는 것입니다. 이렇게 하면, 해당 객체를 테스트 스위트(Test Suite)에 포함할 수 없더라도, 미처 감지하지 못한 실패(Undetected Failure) 가능성을 최소화할 수 있습니다.
"The Humble Dialog Box" 논문에서는 프레젠터(Presenter)를 훨씬 더 적극적으로 활용하는데, 이는 원래의 MVP보다 훨씬 깊이 있는 방식입니다. 프레젠터는 단순히 사용자 이벤트(User Events)에 반응하는 역할뿐만 아니라, UI 위젯에 데이터를 채우는 작업(Population of Data)까지 담당합니다. 이러한 접근 방식의 결과, 위젯들은 더 이상 모델에 대한 접근 권한(Visibility)을 가지지 않으며, 가질 필요도 없습니다. 즉, 위젯들은 완전히 "패시브 뷰(Passive View)" 형태를 가지게 되며, 프레젠터가 UI를 조작하는 유일한 엔티티(Manipulator) 역할을 수행합니다.
이것이 UI를 "겸손하게(Humble)" 만드는 유일한 방법은 아닙니다. 또 다른 접근 방식으로는 프레젠테이션 모델을 활용하는 방법이 있습니다. 그러나 이 방식에서는 위젯이 약간 더 많은 동작(Behavior)을 필요로 합니다. 즉, 위젯이 스스로 프레젠테이션 모델과 어떻게 매핑(Map)되는지를 이해할 수 있어야 합니다.
이 두 가지 접근 방식(패시브 뷰와 프레젠테이션 모델)의 핵심은, 프레젠터(Presenter) 또는 프레젠테이션 모델을 테스트함으로써 직접 테스트하기 어려운 위젯에 손대지 않고도 UI의 대부분의 위험 요소를 검증할 수 있다는 점입니다.
프레젠테이션 모델(Presentation Model)에서는 모든 의사 결정을 프레젠테이션 모델이 담당하도록 설계합니다. 모든 사용자 이벤트(User Events)와 화면 표시 로직(Display Logic)이 프레젠테이션 모델로 전달되며, 위젯은 단순히 프레젠테이션 모델의 속성(Properties)과 매핑(Map)하는 역할만 수행합니다. 이 방식에서는, 위젯 없이도 프레젠테이션 모델의 대부분의 동작(Behavior)을 테스트할 수 있습니다. 유일한 남은 위험 요소는 위젯과 프레젠테이션 모델 간의 매핑이 올바르게 이루어지는지 여부입니다. 그러나 이 매핑이 단순한 구조라면 굳이 직접 테스트하지 않아도 충분히 관리할 수 있습니다. 즉, 이 방식에서는 화면이 패시브 뷰 방식만큼 "겸손(Humble)"하지는 않지만, 그 차이는 크지 않습니다.
패시브 뷰(Passive View)는 위젯을 완전히 겸손하게(Humble) 만들기 때문에, 매핑조차 존재하지 않으며, 프레젠테이션 모델에서 발생할 수 있는 작은 위험조차 제거합니다. 그러나, 그 대가로 테스트 실행중 화면을 모방(Mimic)할 테스트 더블(Test Double)이 필요하며,이는 추가적으로 구축해야 하는 추가적인 기계적 장치(Extra Machinery)입니다.
감독 컨트롤러(Supervising Controller) 방식에서도 유사한 트레이드오프(Trade-Off)가 존재합니다. 뷰가 단순한 매핑(Mapping)을 수행하도록 하면 약간의 위험이 따르지만, 프레젠테이션 모델과 마찬가지로, 단순한 매핑을 선언적으로 지정할 수 있다는 장점이 있습니다. 그러나, 감독 컨트롤러의 경우 매핑의 범위가 프레젠테이션 모델보다 더 작아지는 경향이 있습니다. 프레젠테이션 모델은 모든 복잡한 업데이트를 결정하고 매핑을 통해 전달하지만, 감독 컨트롤러는 복잡한 경우 직접 위젯을 조작하므로 매핑 없이도 해결할 수 있습니다.
감사의 말(Acknowledgements)
Vassili Bykov께서 Smalltalk-80 버전 2(1980년대 초반)의 구현인 Hobbes를 제공해 주신 덕분에, 최신 VisualWorks 환경에서 실행할 수 있었습니다. 이를 통해, Model-View-Controller의 실제 예제를 직접 살펴볼 수 있었으며, MVC가 기본 이미지(Default Image)에서 어떻게 동작하고 사용되었는지에 대한 세부적인 질문들을 해결하는 데 큰 도움이 되었습니다. 그 당시에는 가상 머신(Virtual Machine)을 사용하는 것이 비현실적이라고 생각하는 사람들이 많았지만, 지금 돌아보면, 과거의 우리가 Ubuntu에서 실행되는 VMware 가상 머신 속에서 Windows XP가 실행되고, 그 위에서 VisualWorks 가상 머신이 실행되며, 그 위에서 다시 VisualWorks로 작성된 Smalltalk-80 가상 머신이 돌아가는 모습을 본다면 어떤 반응을 보였을지 궁금합니다.
