
대기 중 오염 물질 농도와 습도는 밀접한 상호작용
(습도 변화 예측을 하면 다양한 분야에 적용 가능)
하지만 기존 시스템은 대기 질 데이터를 잘 활용하지 않아 습도 변화 예측에 한계점 존재
문제 정의
- 다양한 대기질 변수를 이용하여 상대습도 예측
과제
- EDA를 통한 데이터 특성 이해
- 다양한 머신러닝 모델을 이용해 습도 예측 모델 개발
- 변수 중요도 분석 및 인사이트 도출
1. Data set

Data shape
(6293, 12)
feature
dtype='object'
'CO(GT)', 'PT08.S1(CO)', 'NMHC(GT)', 'C6H6(GT)', 'PT08.S2(NMHC)',
'NOx(GT)', 'PT08.S3(NOx)', 'NO2(GT)', 'PT08.S4(NO2)', 'PT08.S5(O3)',
'T', 'RH'
target
RH(Relative Humidity) : 상대습도
(동일한 온도에서의 최대 수증기량(포화 수증기량))

- RH = 20 → 매우 건조한 상태 (호흡기 건조, 정전기 발생 등)
- RH = 50 → 현재 공기는 해당 온도에서 가질 수 있는 수증기의 절반만 포함하고 있음
- RH = 100 → 공기가 포화 상태 (더 이상 수증기를 머금지 못함, 이슬·안개 발생 가능)
2. EDA
2-1. 결측치 처리
결측치가 존재하지 않아서, 처리할 필요가 없음
2-2. Target Distribution 확인
sns.histplot(train_df['RH'], kde=True)
plt.title('Target (Relative Humidity) Distribution')
plt.show()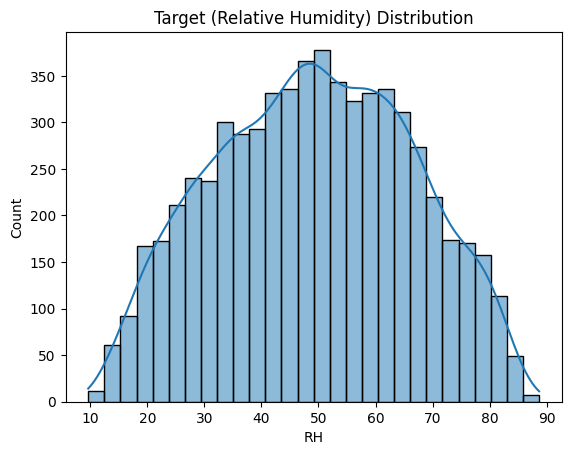
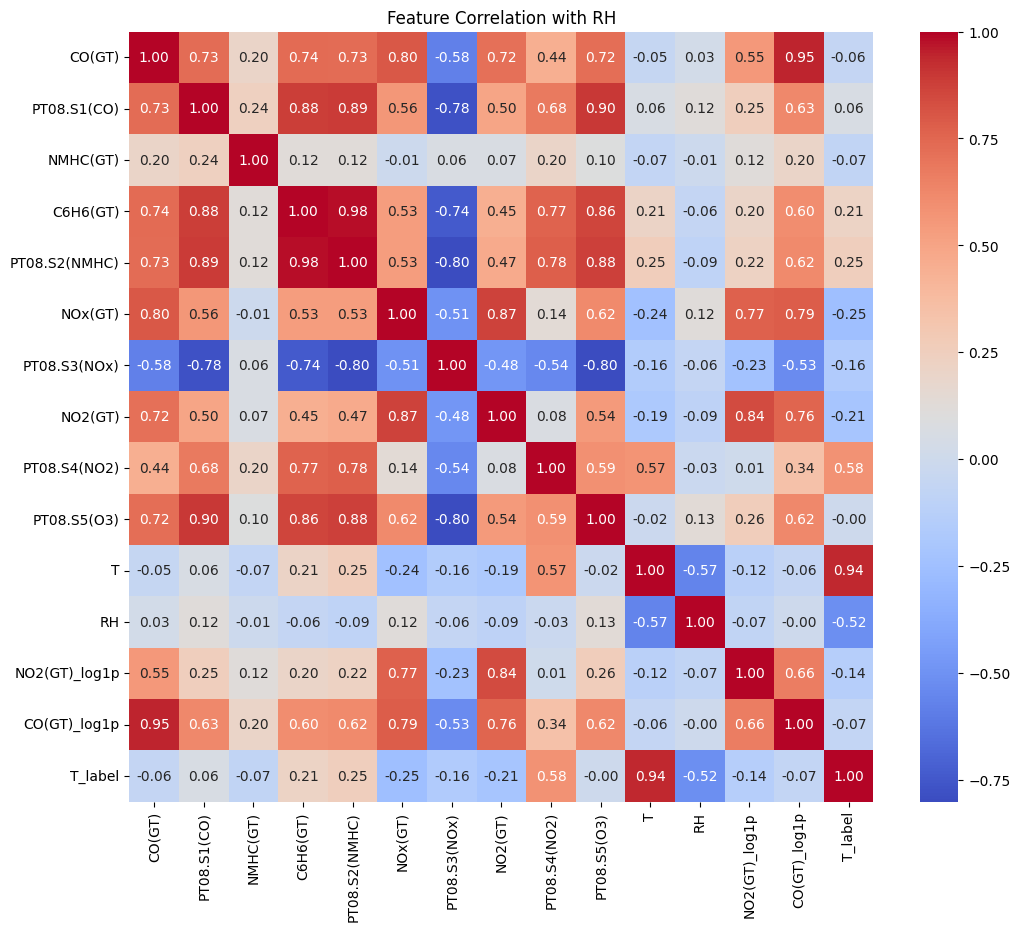
2-3. Correlation 분석
corr = train_df.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm')
plt.title('Feature Correlation with RH')
plt.show()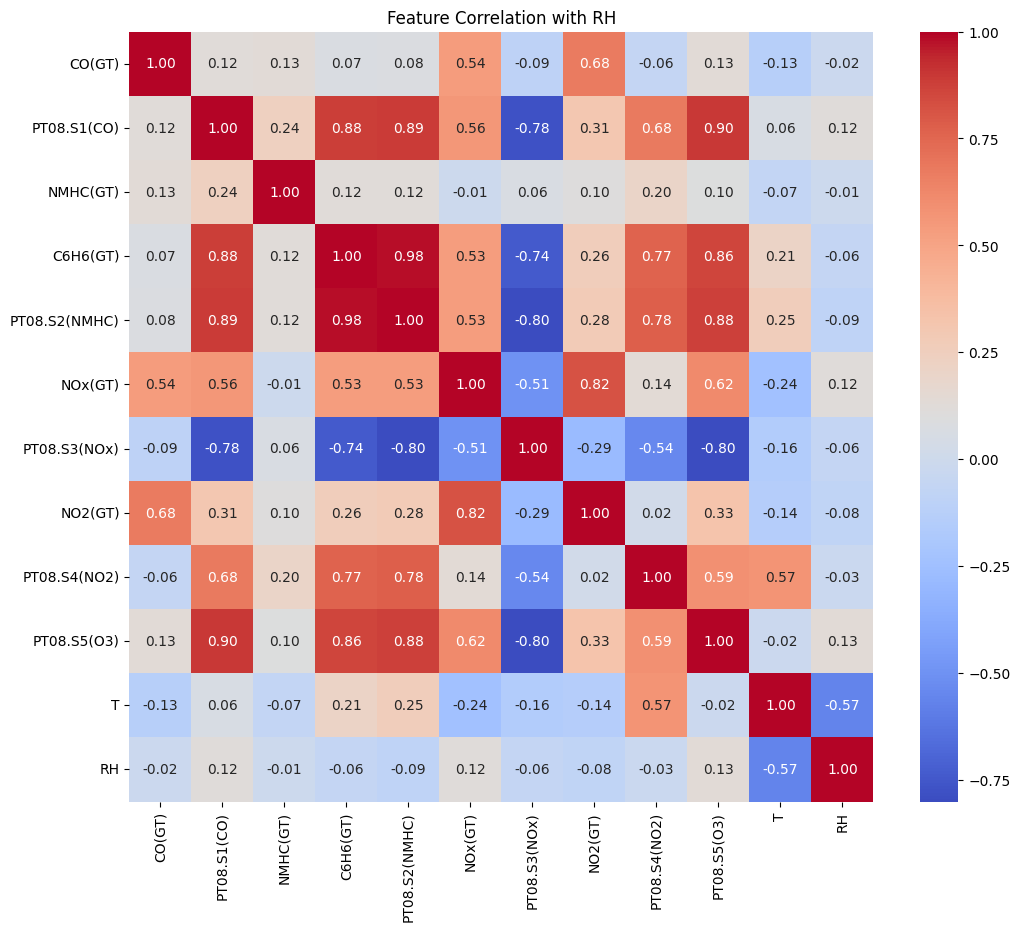
2-4. Feature Extraction
feature들의 분포를 출력한 결과,
상관관계 분석에서 중요했던 'T', 'NO2(GT)', 'CO(GT)' 중
'NO2(GT)', 'CO(GT)'의 분포가 이상함을 확인할 수 있음
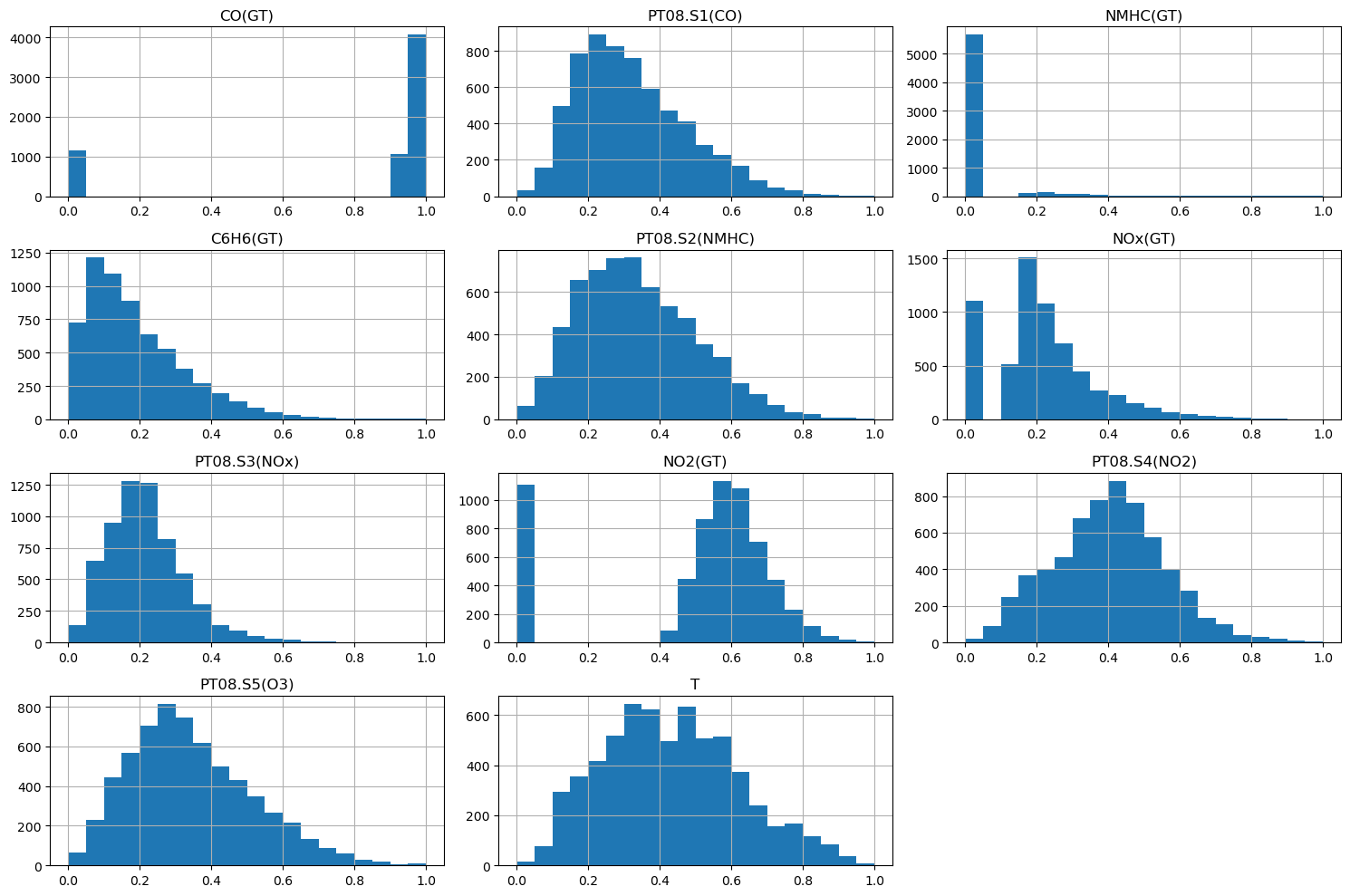
2.4.1 분포가 정상적이지 않은 'NO2(GT)', 'CO(GT)' 처리
‘NO₂(GT)’, ‘CO(GT)’ feature는 한쪽에 몰려 있는 치우친 분포(skewed distribution)
이러한 비정상적인 분포는 모델 학습 시 왜곡된 가중치 학습을 유발할 수 있음
-> 분포를 안정화하기 위해 log(1 + x) 변환(log1p) 을 적용
- 음수 값이나 0에 대해 안정적으로 작동하며, 분포를 정규분포에 가깝게 만들고 이상치를 완화시킴
import numpy as np
def log_transform(train, test):
"""
train, test 데이터에서 NO2와 CO 컬럼을 log1p 변환하여 새로운 변수를 추가하는 함수
(log1p: log(x + 1))
"""
# 변환할 컬럼 리스트
cols_to_transform = ['NO2(GT)', 'CO(GT)']
for col in cols_to_transform:
# 혹시 음수 있으면 0으로 clip
train[col] = train[col].clip(lower=0)
test[col] = test[col].clip(lower=0)
# log1p 변환해서 새로운 컬럼 추가
train[col + '_log1p'] = np.log1p(train[col])
test[col + '_log1p'] = np.log1p(test[col])
return train, test
#NO2, CO log 변환
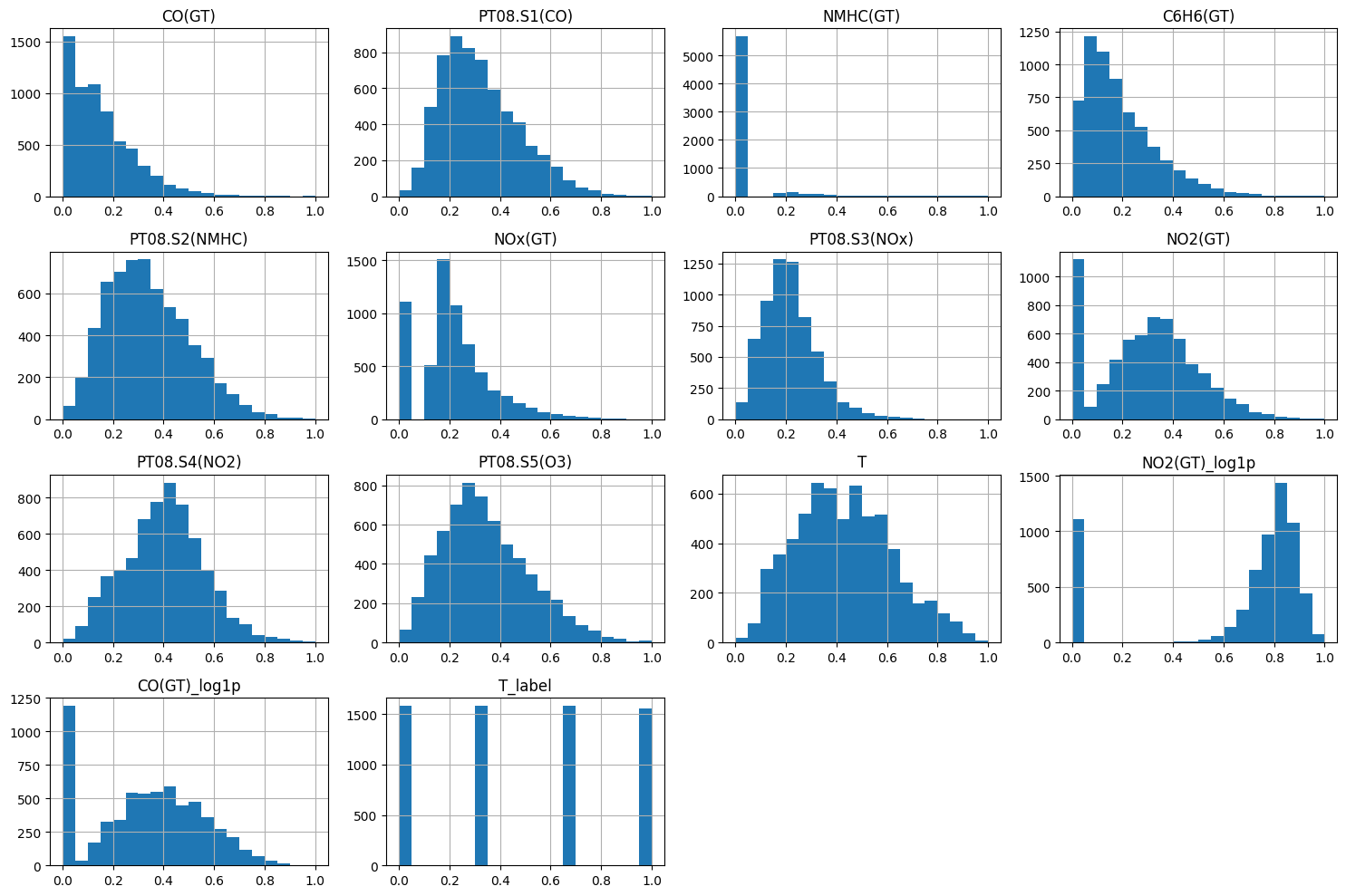
train_df, test_df = log_transform(train_df, test_df)- histogram 출력 결과를 치우친 정도가 완화되었다는 것을 확인할 수 있음

2.4.2 중요한 feature 'T' 처리
'T' feature는 종형 분포, 즉 안정적인 분포
상관관계 분석 중 가장 유의미했기에, 비선형적으로도 feature 만들면 좋음
-> 온도를 구간화(binning)한 후 정수형 label (0, 1, 2, 3)로 부여하여 feature 생성
import pandas as pd
import numpy as np
bins = [-np.inf, 11.6, 17.7, 24.3, np.inf]
labels = [0, 1, 2, 3]
# T 컬럼을 구간에 따라 나누고, 라벨을 부여
train_df['T_label'] = pd.cut(train_df['T'], bins=bins, labels=labels)
test_df['T_label'] = pd.cut(test_df['T'], bins=bins, labels=labels)
2.4.3 최종 Feature Extraction 결과
유의미한 3개의 feature들이 추가된 것을 볼 수 있음
2-5. Scaling
스케일링을 거치기 전에, feature와 target 값 분리
y= train_df['RH']
X = train_df.drop('RH', axis=1)StandardScaler 적용 후, MinMaxScaler 사용
(주의사항 : fit한 것을 train과 test 같이 사용하면 안 됨)
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# StandardScaler객체 생성
scaler = StandardScaler()
scaler.fit(X)
X = scaler.transform(X)
# MinMaxScaler객체 생성
scaler = MinMaxScaler()
scaler.fit(X)
X= scaler.transform(X)2-6. Outlier 제거
각 feature에 대해 boxplot 그리면, 이상치가 많이 존재하는 것을 확인 가능
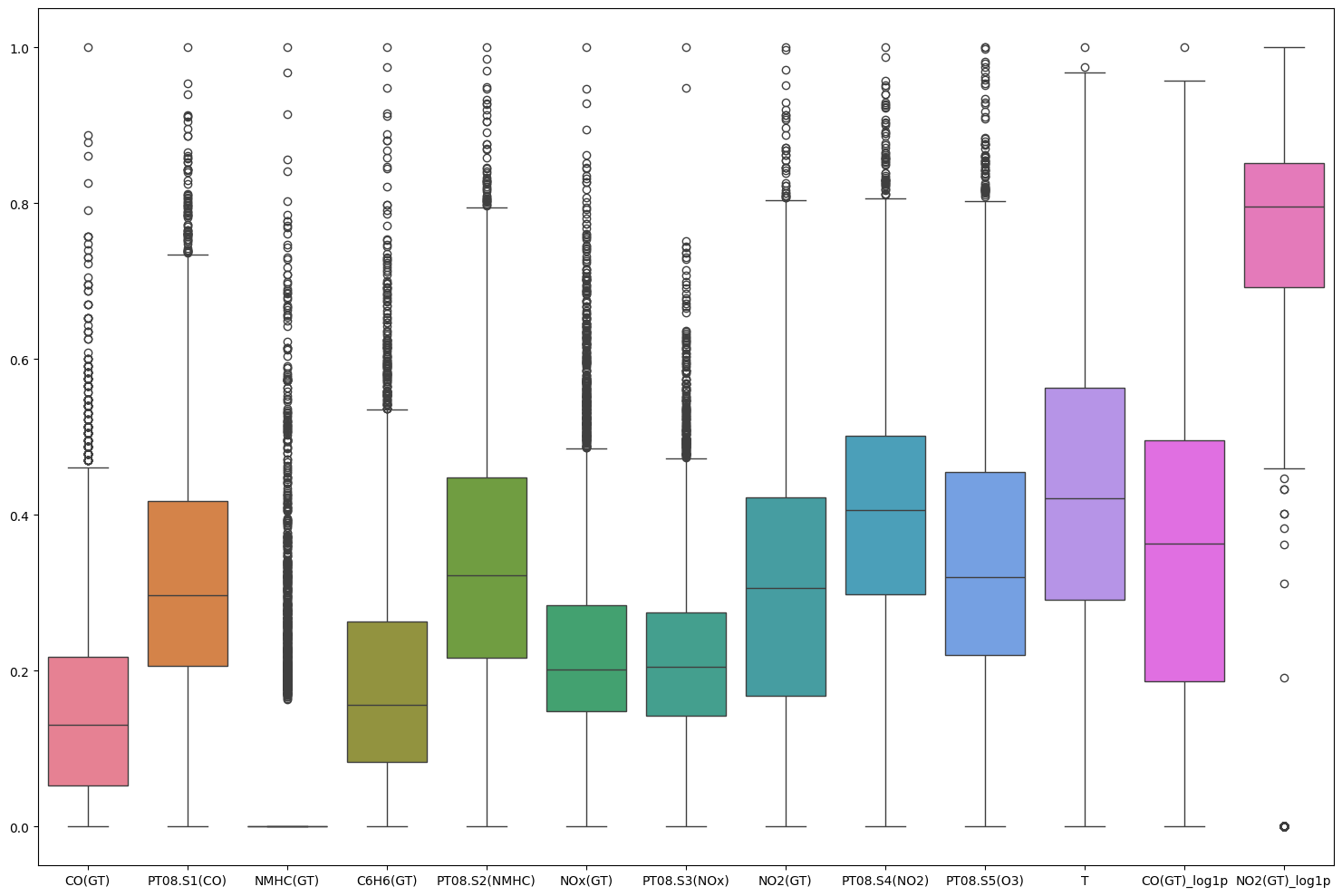
다음과 같은 코드로 이상치 처리
def remove_outliers_iqr(X, y, columns):
mask = pd.Series([True] * len(X), index=X.index) # 전체 True 마스크
for col in columns:
if pd.api.types.is_numeric_dtype(X[col]):
Q1 = X[col].quantile(0.25)
Q3 = X[col].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
# 이상치 여부 마스크 업데이트 (AND 연산)
mask = mask & ((X[col] >= lower) & (X[col] <= upper))
# 이상치 제거된 X, y 반환
return X[mask], y[mask]
numeric_cols = X.select_dtypes(include=[np.number]).columns.tolist()
X, y = remove_outliers_iqr(X, y, numeric_cols)
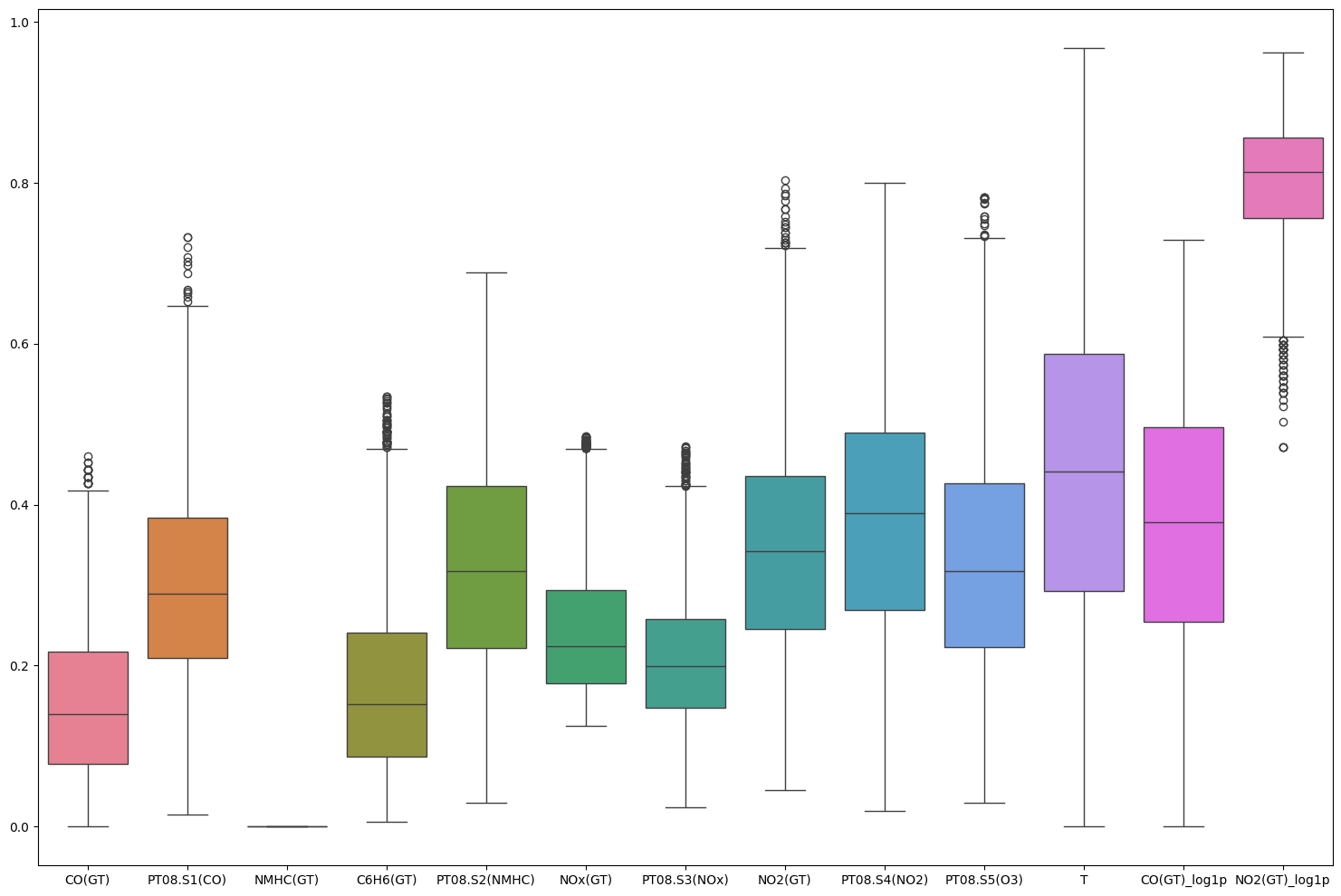
이상치 처리 후 boxplot
3. Model
3-1. data split
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
3-2. Model 학습 및 평가
models = {
'rf': RandomForestRegressor(random_state=42),
'lgbm': LGBMRegressor(random_state=42),
'xgb': XGBRegressor(random_state=42)
}
fitted_models = {} # 학습된 모델 저장
for name, model in models.items():
model.fit(X_train, y_train)
fitted_models[name] = model
for name, model in fitted_models.items():
preds = model.predict(X_val)
rmse = np.sqrt(mean_squared_error(y_val, preds))
print(f'{name} RMSE: {rmse:.4f}')
4. Review
개선이 필요한 부분
- 변수들 이름 통일이 안 되고 중구난방
(팀원들과 사전에 정해놓고 시작할 필요 있음) - Scaling 과정에서 target 분리 안 함
(target값 신경써서 관리하기) - train에 대한 전처리만 수행하고, test에 대해 전처리 안 해서 대시보드에 제 시간 안에 제출 못 함
(협업 과정에서 본인 파트를 할 때, test set 전처리 본인이 잘 담당하기)
Feature Extraction Review
상관관계 분석을 진행하여 loss가 줄어든 걸 확인할 수 있음
하지만, 'NO2(GT)', 'CO(GT)' 를 변환한 'CO(GT)_log1p', 'NO2(GT)_log1p' 는
따로 넣었을 때는 성능이 향상 안 되지만, 2개를 함께 넣었을 때는 성능이 더 좋아짐
(아직 왜 그런지는 파악 안 돼서 추후에 확인할 필요 있음)
-
상관관계 분석 진행 전

-
상관관계 진행 후

Outlier 제거(IQR) Review
이상치 제거를 진행하여 loss가 줄어든 걸 확인할 수 있음
-
이상치 제거 안 한 것

-
이상치 제거 한 것
5. Model 개선을 위한 후속 실험
RFECV
(Recursive Feature Elimination with Cross Validation)
후진 소거법을 사용하면 성능이 올라갈 것 같아서 해봤지만, 성능 개선되지 않음
from sklearn.feature_selection import RFECV
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
estimator = XGBRegressor(random_state=42)
cv = KFold(n_splits=5, shuffle=True, random_state=42)
rfecv = RFECV(
estimator=estimator,
step=1, # 매 스텝마다 하나씩 제거
cv=cv, # 위에서 정의한 KFold
scoring='neg_mean_squared_error', # MSE 기반으로 특성 개수 탐색
min_features_to_select=3 # 남길 최소 특성 수 (옵션)
)
rfecv.fit(X_train, y_train)
print(f'최적 특성 개수: {rfecv.n_features_}')
print('선택된 특성 이름:', list(X_train.columns[rfecv.support_]))
# 선택된 특성만 추출하여 재학습/평가
X_train_sel = rfecv.transform(X_train)
X_val_sel = rfecv.transform(X_val)
estimator.fit(X_train_sel, y_train)
preds = estimator.predict(X_val_sel)
rmse = np.sqrt(mean_squared_error(y_val, preds))
print(f'RFECV RMSE: {rmse:.4f}')
GridSearchCV
모델 부분에 parameter 설정이 되어있지 않아서, GridSearchCV로 하이퍼 파라미터 설정하기
LGBM 성능이 이전보다 개선된 것을 알 수 있음
다음부터는 GridSearchCV 사용해서 파라미터 설정할 필요 있음
from sklearn.model_selection import GridSearchCV
fitted_models = {}
best_scores = {}
for name, (model, params) in models_params.items():
print(f"{name.upper()} GridSearchCV")
grid = GridSearchCV(model, params, cv=3, scoring='neg_root_mean_squared_error', verbose=1, n_jobs=-1)
grid.fit(X_train, y_train)
best_model = grid.best_estimator_
fitted_models[name] = best_model
best_scores[name] = -grid.best_score_ # 음수로 나와서 부호 변경
print(f'{name.upper()} Best RMSE (CV): {best_scores[name]:.4f}')
print(fitted_models)
for name, model in fitted_models.items():
preds = model.predict(X_val)
rmse = np.sqrt(mean_squared_error(y_val, preds))
print(f'{name.upper()} GridSearch RMSE: {rmse:.4f}')
Scaling 수정
기존의 Scaling 과정은 StandardScaler과 MinMaxScaler 둘 다 사용
하지만 이것은 정보의 손실이 일어날 수도 있음
StandardScaler만 사용했을 때 성능이 더 좋았음
StandardScaler만 사용
성능이 기존보다 향상된 것을 확인할 수 있음
- RMSE Loss : 4.3830 -> 4.3640
'lgbm': LGBMRegressor(max_depth=10, min_child_weight=1, n_estimators=500,
random_state=42)
MinMaxScaler만 사용
성능이 기존과 동일한 것을 확인할 수 있음
'lgbm': LGBMRegressor(max_depth=10, min_child_weight=1, n_estimators=500,
random_state=42)
6. Solution
dataset을 잘 살펴봤으면 -200이라는 이상한 값들이 채워져있는 것을 확인할 수 있었음
(센서에서 인식하는 것이 -200이 나올 수 없는데, 이렇게 나온 이유는 따로 회사에서 결측치를 -200으로 채운 경우임)
feature들의 분포를 시각화 했을 때, -200쪽에 몰려있는 것을 보고 이상하다고 생각했어야 했고,
-200을 처리하기 위한 새로운 방식을 생각했어야 함
overfitting
- 데이터 증강 (SMOTE)
- 모델 depth 10 -> 5
