[ Paper Review ] Understanding Convolutional Neural Networks with Information Theory : An Initial Exploration
Paper Review

Introduction
정보 이론을 통한 DNN 이해의 배경
최근 DNN과 정보이론을 매핑하여 해석하려는 관심이 높아지고 있음.
Information Plane(IP) : 얼마나 입력 정보를 유지하면서 원하는 출력 정보도 얻을 수 있는지 나타내는 것
(네트워크 학습의 두 단계를 설명)
SGD 최적화 과정 중
- Fitting phase : 빠르게 증가 (iteration에 따라)
- Compression phase : 감소하는 현상 관측
(이것이 복잡한 네트워크 또한 일반화 가능한지는 후속 연구에서 의문 제기됨)
Compression 단계의 조건
이전 연구에서는 stacked autoencoder에 대해, 새로운 matrix-based Rényi α-entropy 추정기 이용해 정보 흐름을 분석
Compression 단계의 유무
Bottleneck(병목층) 크기 와 데이터의 내재 차원 간의 관계에 달려있음
- : 정보량이 증가했다 다시 감소(Compression)
- : 정보량이 계속 증가
내재 차원 는 데이터가 실제로 퍼져 있는 실질적 차원수를 의미하며, 병목층의 크기가 충분히 크지 않으면 정보 손실없이 학습만 일어남
CNN에 적용할 때 고려할 점
1) MMI(Multivariate Mutual Information) 추정하기
convolution layer에서 여러 개의 feature map으로 표현되기에, 단일 변수 간 다변수 상호 정보를 측정해야되는 상황
(-> 계산 매우 어려움)
2) 세부적인 특성 고려 필요
Feedforward를 마르코츠 체인으로 보면 Data Processing Inequality(DPI)가 성립된다고 할 수 있지만, 그 외의 층 표현들을 나타내기에는 부족
(-> DPI 이상의 추가 이론적 분석 수단 필요함)
본 논문의 주요 기여
1) 다변수 Rényi α-entropy 확장 정의를 도입
복잡한 PDF 추정 없이도 CNN의 MMI(Multivariate Mutual Information) 측정 가능
- 고차원 데이터를 작은 수치 연산으로 다루게 함
2) Partial Information Decomposition(PID)
DPI 이상의 프레임 워크로, feature map 간 시너지, 중복성을 직접 추정할 필요 없이, 네트워크 depth, width, pruning에 대한 통찰 제공
- 층 내 필터 간 정보 상호작용을 효율적으로 해석(->네트워크 설계에 활용 가능)
II. Information Quantity Estimation In CNNs
A. Matrix-based Rényi’s α-entropy functional and its multivariate extension
Rényi α-entropy의 정의
: Shannon Entropy의 확장으로, 확률 밀도 함수 를 가진 확률 변수 에 대해 다음과 같이 정의
Gram matrix 계산의 필요성
하지만 실제 데이터에서 를 직접 추정하는 것은 어렵기에, Gram 행렬의 고윳값 분포를 이용해 Entropy 계산
(어려운 이유(논문에 나온 내용 X) : 차원의 저주 문제)
Gram Matrix에 대한 설명 참고
Sample들의 inner product를 담고 있는 행렬
단일 변수 α-entropy 함수
양의 정부호 커널 로부터 를 계산하고,
정규화된 행렬 를 다음과 같이 정의
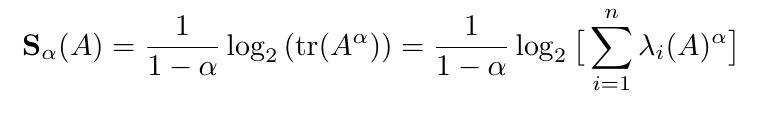
다변량 α-entropy 함수
Hadamard 곱을 사용해서 '모든 feature map이 비슷한 정도'를 측정하는 합성(simultaneous) 유사도 행렬을 구함
(=Joint entropy 개념)
Hadamard 곱에 대한 설명 참고
이 합성 행렬을 다시 trace=1로 정규화
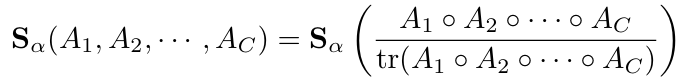
다변량 α-entropy의 bound
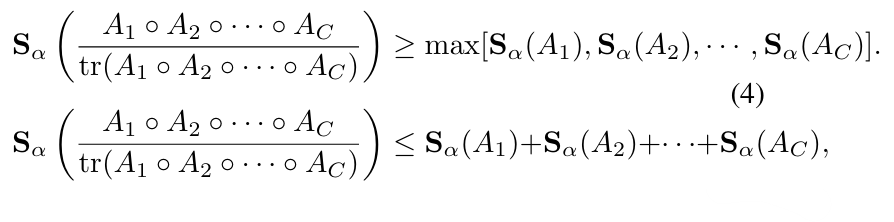
B. Multivariate mutual information estimation in CNNs
앞에서 지적했던 것과 같이 convolution layer에서는 입력 가 라는 개의 feature map으로 표현됨.
(이때 다변량 상호 정보를 추정해야 되지만 현실적으로 불가능)
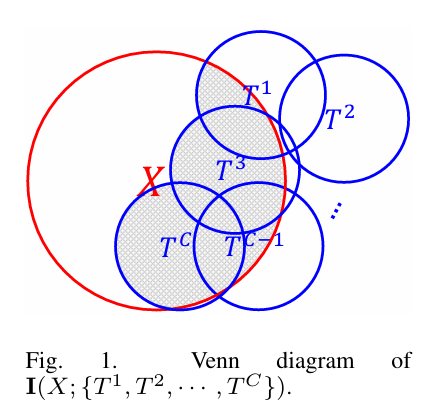
그래서 벤다이어그램에서 빨간 원 (input data) , 파란원들이 (convolution layer)를 나타낼 때, 다음과 같이 계산
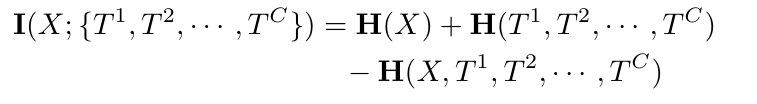
이것을 matrix 관점으로 다시 해석한 식은 다음과 같음
(layer 진행 정도에 따라 input과 feature map이 다르기에 다음과 같이 표현)
- Input Tensor :
- C feature map tensors :
(mini batch size : n)
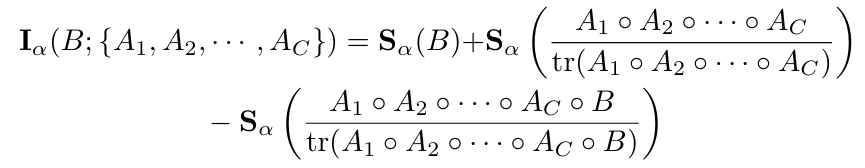
III. Main Results
A. Experimental Validation of Two DPIs
순방향과 역방향 체인에서 두 개의 데이터 처리 과정이 DPI(Data Process Inequality)를 만족하는지 확인
실험 설정
- dataset : MNIST, Fashion-MNIST / HASYv2, Fruits 360
- Network :
LeNet-5 : 2 Conv + 2 Pool + 2 FC
AlexNet : 4 Conv + 3 FC - training : SGD(momentum 0.95), batch size=128
- estimation of MMI :
RBF kernel 사용
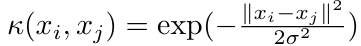
파란 곡선은 순방향 체인으로 input layer -> out layer로 가는 관점에서 정보량이 감소하는 성질 확인 가능
초록 곡선은 역방향 체인으로 outlayer -> input layer로 가는 관점에서도 정보량이 감소하는 성질 확인 가능
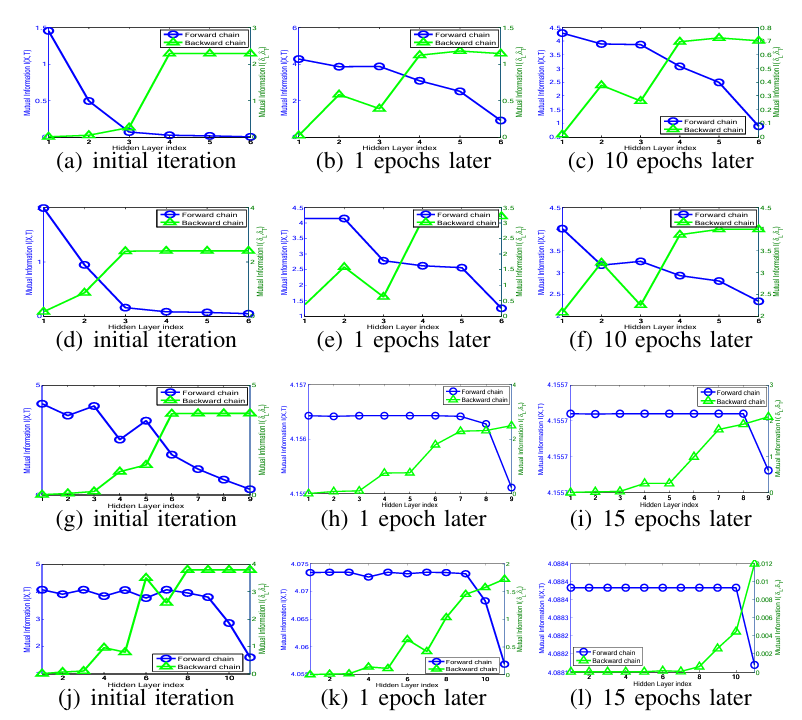
Rényi α-entropy estimator가 기본 속성인 DPI를 잘 보존함을 경험적으로 검증
- LeNet-5 on MNIST
- LeNet-5 on Fashion-MNIST
- 소형 AlexNet on HASYv2
- 소형 AlexNet on Fruits 360



B. Redundancy and Synergy in Layer Representations
