문제
The steps of the insertion sort algorithm:
- Insertion sort iterates, consuming one input element each repetition and growing a sorted output list.
- At each iteration, insertion sort removes one element from the input data, finds the location it belongs within the sorted list and inserts it there.
- It repeats until no input elements remain.
The following is a graphical example of the insertion sort algorithm. The partially sorted list (black) initially contains only the first element in the list. One element (red) is removed from the input data and inserted in-place into the sorted list with each iteration.
Example 1:
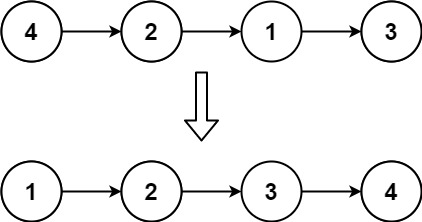
Input: head = [4,2,1,3] Output: [1,2,3,4]
삽입정렬 학습 간에 위와 같은 문제를 맞닥뜨리게 되었다.
요약하면 LinkedList 의 노드들을 오름차순으로 정렬 시키는 문제였다.
이외 같은 유형의 문제는 처음 접하기에 30분 넘게 끙끙 앓다가 그냥 GPT 선생님께 답을 여쭤보고, 해당 답을 이해하는 방향으로 틀었다.
답안
public static ListNode solution(ListNode head) {
if (head == null) {
return head;
}
ListNode dummy = new ListNode(0);
ListNode curr = head;
while (curr != null) {
ListNode prev = dummy; --- [1]
ListNode next = curr.next; --- [2]
while (prev.next != null && prev.next.val < curr.val) { --- [3]
prev = prev.next; --- [4]
}
curr.next = prev.next; --- [5]
prev.next = curr; --- [6]
curr = next; --- [7]
}
return dummy.next;
}이와 같이 문제에 대한 답을 도출하는 GPT 선생님이었다.
이제는 해당 코드를 분석하고 이해하는 일만 남았다.
그런데 이 과정에서 문제가 발생한다.
하나하나 값들을 대입해보며 코드를 이해해보고자 했는데, 도저히 이해가 안가는 것이다.
초기값
dummy = 0 -> null
curr = 4 -> 2 -> 1 -> 3 -> null첫 번째 반복
[1] prev = 0 -> null
[2] next = 2 -> 1 -> 3 -> null
[3] prev.next = null -> fail
[4] skip
[5] curr.next = null
curr = 4 -> null
[6] prev.next = curr
prev = 0 -> 4 -> null
[7] curr = 2 -> 1 -> 3 -> null두 번째 반복
curr = 2 -> 1 -> 3 -> null
[1] prev = 0 -> 4 -> null
[2] next = 1 -> 3 -> null
[3] prev.next.val = 4 < curr.val = 2 => false
[4] skip
[5] curr.next = 4 -> null
curr = 2 -> 4 -> null
[6] prev.next = curr
prev = 0 -> 2 -> 4 -> null
[7] curr = 1 -> 3 -> null세 번째 반복
curr = 1 -> 3 -> null
[1] prev = 0 -> 2 -> 4 -> null
[2] next = 3 -> null
[3] prev.next.val = 2 < curr.val = 1 => false
[4] skip
[5] curr.next = 2 -> 4 -> null
curr = 1 -> 2 -> 4 -> null
[6] prev.next = curr
prev = 0 -> 1 -> 2 -> 4 -> null
[7] curr = 3 -> null네 번째 반복
curr = 3 -> null
[1] prev = 0 -> 1 -> 2 -> 4 -> null
[2] next = null
[3] prev.next.val = 1 < curr.val = 3 => true
[4-1] prev = 1 -> 2 -> 4 -> null
[4-2] prev.next.val = 2 < curr.val = 3 => true
[4-3] prev = 2 -> 4 -> null
[4-4] prev.next.val = 4 < curr.val = 3 => false
[4-5] skip
[5] curr.next = 4 -> null
curr = 3 -> 4 -> null
[6] prev.next = curr
prev = 2 -> 3 -> 4 -> null
[7] curr = null위와 같이 네 번의 반복 끝에
return dummy.next;더미를 반환하게 된다.
이때 데이터는 다음과 같다.
expected - 내가 예상한 값
: 3 -> 4
actually - 실제 값
: 1 -> 2 -> 3 -> 4아니 분면 네 번째 반복 과정의 [6] 에서 prev = 2 -> 3 -> 4 -> null 이 되었지 않은가.
0 -> 1 해당 노드는 대체 어디서 생겨나서 dummy.next 를 하면 1 -> 2 -> 3-> 4 노드가 나오는 것인가 도통 이해가 안갔다.
해결
위 물음에 대한 대답은 dummy 에 있었다.
ListNode dummy = new ListNode(0); --- dummy : MainListNode@417
ListNode curr = head;
while (curr != null) { --- curr : MainListNode@415
ListNode prev = dummy; --- dummy : MainListNode@417 prev : MainListNode@417
ListNode next = curr.next;
while (prev.next != null && prev.next.val < curr.val) {
prev = prev.next;
}
curr.next = prev.next; --- curr : MainListNode@415 prev : MainListNode@417
prev.next = curr; --- curr : MainListNode@415 prev : MainListNode@417
curr = next; --- next : MainListNode@418
}디버깅을 하면 위와 같이 주소값들이 할당되는 것을 볼 수 있다.
1 ~ 3 번째 반복을 위와 같이 수행하면 dummy(0) 은 1 -> 2 -> 4 를 참조하는 LinkedList 가 형성되는 것이다.
while (prev.next != null && prev.next.val < curr.val) {
prev = prev.next;
}내가 헷갈렸던 문제의 코드는 이 부분이었다.
prev = 1 -> 2 -> 4 -> null
prev = 2 -> 4 -> null이런식으로 prev 의 변화가 dummy 내의 노드들에 영향을 준다고 생각했던 것이다.
하지만 이런 생각은 잘못된 것이었고, 위 변화는 prev 라는 커서의 위치가 변한 것일 뿐이다.
즉, prev 가 가리키는 대상이 최초 1 에서 2 로 변화했다 이런 말인 것이다.
다시 말해서
prev = 2 -> 4 -> null => dummy = 2 -> 4 -> null위 과정이 아니라는 것이다.
dummy 는 그저 0 이라는 헤드노드를 가지고 있을 뿐이고, 해당 헤드노드 0 은 1 을 여전히 참조하고 있다.
1 은 여전히 2 를 참조하고 있기도 한 것이다.
이에 이후에
[5] curr.next = 4 -> null
curr = 3 -> 4 -> null
[6] prev.next = curr
prev = 2 -> 3 -> 4 -> nullprev 의 헤드, 2 가 3 -> 4 -> null 을 참조하게 변경된 것이다.
이후에 dummy 를 반환하게 되면,
dummy 의 헤드는 0 이니까 0 은 현재 1 을 참조하고 있고, 1 은 2 를 참조하고 있으며, 앞서 언급했던 거처럼 2 는 3 -> 4 -> null 를 참조하고 있으니
최종적으로 dummy = 0 -> 1 -> 2 -> 3 -> 4 -> null 과 같은 LinkedList 를 구현하개 되는 것이다.
정리하자면, 위 코드는 dummy 노드를 활용해 각 노드를 정렬된 위치에 삽입하여 연결 리스트를 오름차순으로 정렬하는 코드인 것이다.
알게된 점
이번 문제를 통해 LinkedList 자료구조에 대해 더 깊이 이해할 수 있었다.
단순히 개념만 알고 있었던 LinkedList 를 실제 코드로 구현하고 다뤄보며, 리스트의 동작 원리와 참조 관계에 대해 명확히 알게 되었다.
특히, 포인터(참조값)의 개념에서 혼란을 겪었지만, 이번 학습을 통해 포인터가 변한다고 해서 객체 자체가 변하는 것이 아니라, 참조하는 위치만 바뀐다는 것을 이해했다.
이러한 개념이 삽입 정렬의 동작 원리를 파악하는 데 큰 도움이 되었다.
결과적으로, 삽입 정렬과 연결 리스트의 동작을 코드로 직접 다뤄보며 보다 깊이 있는 학습을 할 수 있었다.
