
컬렉션
컬렉션이란?
이전 배열에서 예시를 든 것과 같이 분류통에 비유하면 참조형 분류통이라고 할 수 있겠다. 참조형 변수만을 저장함으로써 여러기능을 제공한다.
크기 자동조정/ 추가/ 수정/ 삭제/ 반복/ 순회/ 필터/ 포함확인 등 기능이 다양하다.
배열에서 크기를 지정해서 생성을 해야했는데 길이를 모를 때 컬렉션을 사용하면 해결된다.
또한 컬렉션을 사용하면 반복, 순회, 필터 부분도 배열에 비해 더욱 편리해진다.
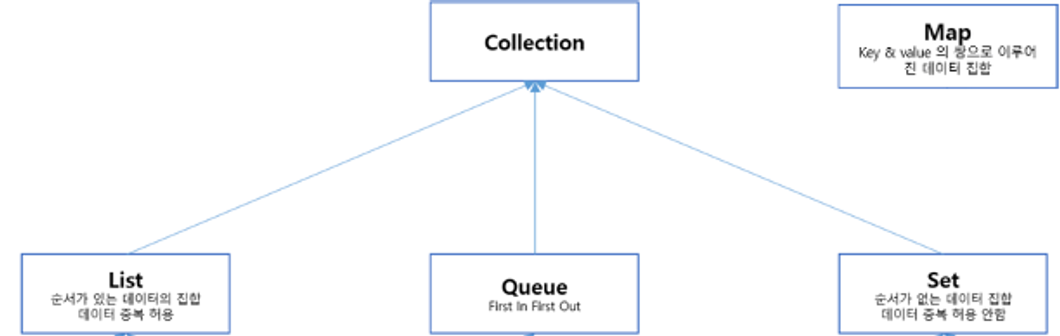
컬렉션 종류
- List(리스트)
순서가 있으며, 데이터 중복을 허용한다.(배열과 비슷하다) - Queue(큐)
순서가 있고, 빨대처럼 한쪽에서 데이터를 넣고 반대쪽에서 데이터를 뺄 수 있는 집합이다.(FIFO: First In First Out 구조) - Set(셋)
순서가 없고 데이터 중복을 허용하지 않는 배열이다. - Map(맵)
순서가 없고 Key:Value pair로 이루어진 데이터의 집합이다.
또한, Key값은 중복을 허용하지않는 unique한 값이다.
List
ArrayList
배열처럼 크기가 정해져있지않고 필요할때마다 크기가 점점 늘어나는 특징을 가지고 있다.
Array는 정적배열, ArrayList는 동적배열이라고 부른다.
더 자세히 설명하자면,
Array는 실제값을 저장하는 기본형 변수로 저장하며, ArrayList는 작은 공간에 참조형 변수들을 담아놓고 값이 추가될때 더 큰 공간이 필요하면 더 큰 공간을 받아 저장한다.
- 기능
- 선언 :
ArrayList<Integer> intList - 생성 :
new ArrayList<Integer>(); - 초기화 : 사이즈를 지정하지 않으므로 초기화하지않아도 된다.
- 값 추가 :
intList.add({추가할 값}) - 값 수정 :
intList.set({수정할 순번}, {수정할 값}) - 값 삭제 :
intList.remove({삭제할 순번}) - 전체 출력 :
intList.toString() - 전체 제거 :
intList.clear()
- 선언 :
LinkedList
기본적 기능은 ArrayList와 동일하지만 LinkedList는 값을 여기저기에 나누어 저장하기 때문에 조회하는 속도가 느리다.
대신, 값을 중간에 추가하거나 삭제할 때는 속도가 빠르다.
(ArrayList는 중간에 추가는 안되고 수정만 가능하다.)
- 기능
- 선언 :LinkedList<Integer> linkedList
- 생성 :new LinkedList<Integer>();.
- 초기화 : ArrayList와 같이 초기화할 필요없다.
- 값 추가 :linkedList.add({추가할 순번}, {추가할 값})순번을 생략하면 마지막에 추가된다.
- 값 수정 :linkedList.set({수정할 순번}, {수정할 값})
- 값 삭제 :linkedList.remove({삭제할 순번})
- 전체 출력 :linkedList.toString()
- 전체 제거 :linkedList.clear()
전체적으로 ArrayList와 같지만 선언과 생성, 값추가 방식은 조금 다르다.
Stack
stack은 queue와 다르게 바구니에 담고 빼는 것과 같이 나중에 들어간 것이 처음으로 나온다.(LIFO: Last In First Out)
최근 저장된 데이터를 나열하고 싶거나, 데이터의 중복처리를 막고 싶을 때 사용한다.
- 기능
- 선언 :
Stack<Integer> intStack - 생성 :
new Stack<Integer>(); - 추가 :
intStack.push({추가할 값}) - 조회 :
intStack.peek()조회시 삭제는 되지않는다. - 꺼내기 :
intStack.pop()꺼내면 삭제된다.
- 선언 :
Queue
위에 말한대로 FIFO구조이며, 생성자가 없는 껍데기인 인터페이스이다.
new키워드로 만들 수 없다는 것을 의미하며, 인터페이스 관련해선 다음에 강의를 들을 예정이다!
(정리되면 여기에 링크띄울거라는 표시..)
그러므로 생성자가 존재하는 클래스인 LinkedList를 사용해서 Queue를 생성할 것이다.
- 기능
- 선언 :
Queue<Integer> intQueue - 생성 :
new LinkedList<Integer>(); - 추가 :
intQueue.add({추가할 값})맨 위에 추가된다. - 조회 :
intQueue.peek()맨 아래 값 조회 뒤 삭제X - 꺼내기 :
intQueue.poll()맨 아래 값 꺼낸 뒤 삭제
- 선언 :
Set
순서가 보장되지않는 대신 중복을 허용하지 않도록 유지할 수 있으며, Queue와 마찬가지로 인터페이스이다.
이는 HashSet, Treeset, LinkedHashSet을 사용해서 표현할 수 있다.
- 선언 :
Set<Integer> intSet - 생성 :
new HashSet<Integer>();(트리, 링크도 이와같음) - 추가 :
intSet.add({추가할 값})맨위에 추가 - 삭제 :
intSet.remove({삭제할 값})삭제할 값을 지정! - 포함 확인 :
intSet.contains({포함 확인 할 값})// boolean값
여기서 잠깐!
HashSet, Treeset, LinkedHashSet 차이점을 알아보자.
HashSet: 가장 빠르며 순서를 전혀 예측할 수 없음
TreeSet: 정렬된 순서대로 보관하며 정렬 방법을 지정할 수 있음
LinkedHashSet: 추가된 순서, 또는 가장 최근에 접근한 순서대로 접근 가능
보통HashSet을 쓰며, 순서가 필요하면LinkedHashSet
Map
순번으로 조회하지않고 Queue,set과 마찬가지로 인터페이스이다.
이는 HashMap, TreeMap등으로 응용하여 생성한다.
Key:Value 쌍으로 저장하며, Key는 고유한 값으로 이를 통해 조회가 가능하다.(Value는 중복될 수 있다.)
- 기능
- 선언 :
Map<String, Integer> intMapKey, value타입을 각각 정한다. - 생성 :
newHashMap<>(); - 추가 :
intMap.put({추가할 Key값},{추가할 Value값}) - 조회 :
intMap.get({조회할 Key값}) - 전체 key 조회 :
intMap.keySet() - 전체 value 조회 :
intMap.values() - 삭제 :
intMap.remove({삭제할 Key값})
- 선언 :
여기서 잠깐!
HashMap, TreeMap의 차이를 알아보자.
HashMap: 중복X, 순서X / key와 value에 null값 가능.TreeMap: key 값을 기준으로 정렬가능. 다만, 저장 시 정렬(오름차순)을 하기 때문에 저장시간이 다소 오래 걸림
내 기준에선 Map이 가장 어렵다고 느껴져 Map을 예시코드를 통해 정리해보도록 하겠다.
//ex)
Map<String, int> intMap = new HashMap<>(); //선언 + 생성
intMap.put("사과",100);
intMap.put("포도",500);//추가
intMap.put("사과",1000);//key값이 같으면 value는 덮어쓰기 됨
System.out.print(intMap.get("사과")); //1000이 출력
for(String key : intMap.keySet()){
System.out.println(key); //사과, 포도 출력
}
for (Integer val : intMap.values()){
System.out.oruntln(val); //1000, 500 출력
}