논문 링크: https://arxiv.org/abs/2212.08051
깃허브 링크: https://github.com/allenai/objaverse-xl
[2D-vision]
- LVIS
- ImageNet
- MS COCO
- YFCC100M
- OpenImages
- Conceptual Captions
- WIT
- LAION
[3D-vision]
- Objaverse
- KIT
- YCB
- BigBIRD
- IKEA
- Pix3D
- EGAD
Introduction
그간 컴퓨터 비전 모델 학습을 위한 데이터는 갈 수록 다양해지고, 큰 규모를 가지게 되었다. 그러나 이 같은 데이터셋의 증대 현상은 2D images에만 국한되었다. 2D에 비해 3D model들을 제공하는 데이터셋들은 scale, diversity, realism 면에서 다소 퀄리티가 낮은 것이 실정이었다. 이에 이러한 문제점을 개선하고자 제작된 데이터셋이 바로 objaverse이다. 본 논문에서 소개된 objaverse 1.0의 경우, 800K개가 넘는 데이터들을 가지고 있으며, 가장 최근에 공개된 objaverse-XL의 경우는 10M개 이상의 데이터를 제공하고 있다. objaverse는 다양하고 큰 규모의 3D 데이터셋을 제공할 뿐만 아니라, embodied-AI의 학습, segmentation task의 long-tail problem 개선, vision 모델의 robustness를 평가하는 새로운 벤치마크의 제안, 3D 생성 모델의 성능 개선 등 다양한 측면에서 3D vision 모델 발전에 기여하고 있다.
About Objaverse

1. 데이터셋 구성
-
objaverse는 Sketchfab에서 제공하는 object들로 구성되어 있으며, 초기 annotation 및 metadata 또한 Sketchfab에서 상속한다. 이 metadata에는 객체명, 카테고리들, 형식 제한이 없는 태그들, 자연어 설명 등이 포함된다. 하지만 이는 18개의 카테고리에만 제한되어 있고, 모호성이 크기 때문에 다른 task에 활용하기는 어렵다. 때문에 objaverse는 다음과 같은 라벨링 방식을 활용한다.
1) LVIS (Large Vocabulary Instance Segmentation) 데이터셋의 카테고리 중 1,156개 가량을 활용한다.
2) 범주화의 경우, 각 카테고리 당 CLIP 모델을 통한 분류 및 메타데이터 내 단어 추측으로 500개의 후보 object들을 선별한 뒤, crowdworker의 검증으로 최종 범주화를 진행한다. -
objaverse는 animated objects, rigged characters, articulated objects (기존 object를 분리하여 각각 새로운 object로 사용, ex: 의자 -> 의자 손잡이, 의자 등받이 등등), Exteriors and Interiors 등 다양한 종류와 형태의 object들을 제공한다. 동일한 객체이더라도 style을 달리한 객체들을 여러 개 생성하여 다양성을 제고하고 있다.

2. 응용 분야
3D Generative Modeling
- OBJAVERSE는 ShapeNet과 같은 기존 데이터셋을 넘어 더 방대한 3D 학습 데이터를 제공하여 모델이 더 다양한 객체를 생성할 수 있도록 한다.

참고: 3D Generative Model
- GET3D 모델: NVIDIA에서 개발한 3D 생성 모델로, 2D 이미지나 영상으로부터 3D 모델을 실시간 생성 및 조작하는데 쓰이는 기술이다. GET3D는 기하학적 특징과 텍스처 특징을 추출하는 두 개의 입력 벡터를 사용한다. 두 입력 벡터는 Mapping Network (MLP)를 통해 고차원의 latent vector로 변환된다. 이후 하나의 벡터는 DMTet을 통해 3D Tetrahedral 메쉬로 변환하고, 나머지 하나는 텍스처 생성기를 거쳐 형상에 따라 RGB 값이 매칭된다. 그리고 합쳐진 3D 모델을 미분 가능한 renderer를 통해 2D 이미지로 렌더링한다. 이 과정은 GAN 기술을 통해 최적화 된다.
Instance Segmentation with 3DCP
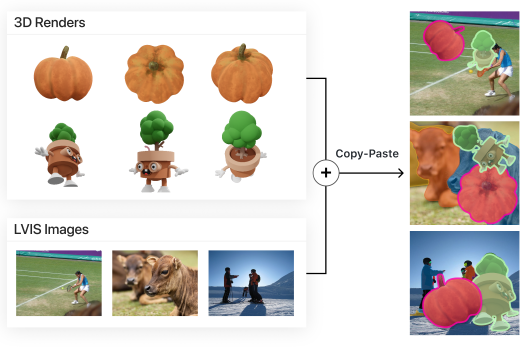
- objaverse는 Multi-view rendering을 통해 하나의 3D 객체에서 여러 개의 2D 객체들을 생성할 수 있다. 이때 rendering된 2D 이미지를 기존의 LVIS 데이터에 붙여 넣기만 하면 자연스럽게 image augmentation의 효과를 얻게 된다. 이를 저자들은 3DCP (3D copy-and-paste) 방법이라 명명하였다.
- LVIS 데이터셋은 고질적으로 long tail 문제를 갖고 있다. 이는 이미지 클래스가 불균형하게 분포되어 있을 때 발생하는 문제로, 3DCP를 통한 데이터 증강으로 간단하게 해결할 수 있다.
- 실제로 해당 방식으로 증강한 데이터셋에 대해 ResNet-50 Mask-RCNN 모델을 fine-tuning하여 segmentation task를 수행한 결과, AP 등의 metrics가 개선된 모습을 보였다.
Open-Vocabulary ObjectNav
- objaverse는 embodied AI의 학습 시나리오 생성에도 사용될 수 있다. 본 논문에서 제안된 Open-Vocabulary ObjectNav task는 agent로 하여금 주어진 text instruction을 기반으로 목표 객체로 이동하게 만드는 것이다. 해당 task가 기존 object navigation task와 다른 점은 agent가 사전 정의된 객체 범주에 국한되지 않는다는 점이다. 즉, Open-Vocabulary라는 명칭에 맞게 다양한 text instruction을 기반으로 목표 객체를 탐색할 수 있도록 한다는 점에서 궤를 달리한다.
- ProcTHOR을 통해 10K개 가량의 집 내부 모델링을 진행한 뒤, 해당 공간을 objaverse에서 제공하는 object들로 채운다.
- 그리고 agent에게 "a {name} {category}"의 템플릿에 맞게 instruction을 주면, agent는 RGB egocentric view에서 시각적 입력들을 관찰하여 freezed된 ResNet-50 CLIP 모델의 인코더로 임베딩한다.
- text instruction 또한 CLIP의 텍스트 인코더로 임베딩한 뒤, 시각적 임베딩과의 cosine similarity를 계산하여 해당 물체를 식별하도록 한다.
- 훈련 과정에서는 강화학습 방법론인 DD-PPO(Decentralized Distributed Proximal Policy Optimization)를 사용하였다. 이를 통해 random policy를 채택한 agent보다 15% 개선된 성공률을 달성하는데 성공하였다.

Analyzing Robustness
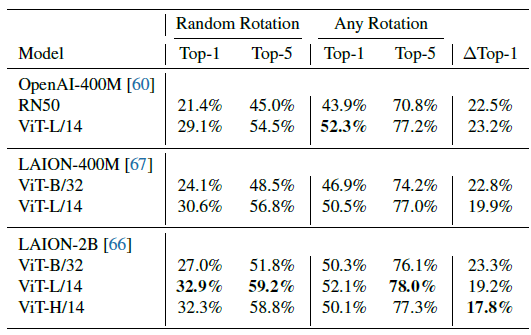
- ImageNet 등을 포함한 기존 벤치마크들은 canonical하고 forward-facing하지 않은 이미지들에 대해서는 robustness가 떨어진다는 문제점을 갖는다.
- objaverse를 활용할 경우, Multi-view rendering을 통해 다양한 각도에서 추출한 이미지들을 모델 학습에 활용할 수 있기 때문에 모델의 robustness를 평가하는 새로운 벤치마크로 기능할 수 있다.
- 대표적인 metrics로는 Top-k Random Rotation (무작위 회전 각도에서 이미지가 상위 k개 내에 올바르게 분류된 빈도수)와 Top-k Any Rotation (12개의 고정된 회전 각도에서 이미지가 상위 k개 내에 올바르게 분류된 빈도수) 등이 있다.
Conclusion
objaverse는 스케일과 다양성 측면에서 빈약했던 기존의 3D 데이터셋의 단점을 크게 개선한 데이터셋이다. 또한 단순히 3D vision 모델 학습에만 쓰이는 것이 아니라, RL, 2D segmentation 등 다양한 방면에 응용될 수 있기에, 그 활용도가 높다고 볼 수 있다.
